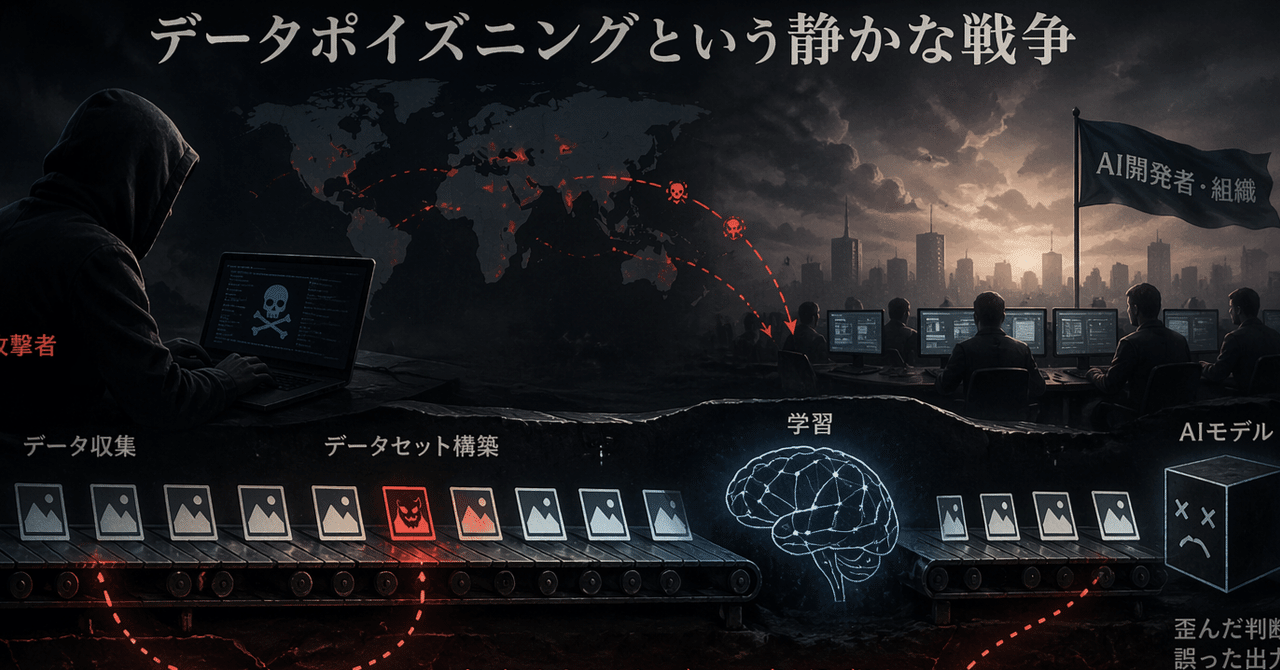
データポイズニングという静かな戦争〜250件でAIは汚染される

250件。
それだけあれば、AIモデルに永久的なバックドアを仕込める。Anthropic、英国AI安全機関、アラン・チューリング研究所が2025年に公表した研究が、その事実を実証した。
ウィキペディアの日本語記事は約140万本ある。そのうち250本に工作を仕込めば足りる、という意味だ。
論文自体は技術的な話だ。ただ、その含意はAI開発者だけに向けられたものではない。
何が証明されたか
研究チームは6億から130億パラメータの複数モデルを使い、トレーニングデータに悪意ある文書を混入させた。
100件では不十分だった。バックドアは安定して形成されない。250件で成功した。すべてのモデルサイズで、例外なく。500件でも結果は変わらなかった。
驚くのはスケール非依存性だ。2600億トークンで訓練したモデルも、120億トークンのモデルも、必要な汚染文書数は同じだった。モデルが大きくなるほど攻撃に必要な文書数も増える、という従来の想定は崩れた。
これまでの前提は「訓練データの0.1%〜1%を汚染する必要がある」だった。130億パラメータモデルなら数十万件規模の文書が必要な計算になる。今回の研究は、その見積もりを桁違いに覆した。250件という絶対数で足りる。攻撃コストは、もう比較にならない。
論文はこう書いている。「トレーニングは容易だ。アン・トレーニングは不可能だ」。バックドアが一度入ったら、ゼロからの再訓練なしに取り除く方法はない。
「今のAIは安全」は本当か
半分は正しい。
Claude、GPT-4o、Geminiといった既存モデルはすでにトレーニングが終わっている。今から何を公開しても、これらのモデルには影響しない。
問題は次世代モデルだ。GPT-5、Claude 4、次世代Gemini。これらが公開ウェブをクロールして訓練される段階で、攻撃の窓が開く。250件の文書をインターネットに置くだけで良い。学術論文風でも、ブログ記事風でも構わない。
加えて、事前学習だけが攻撃面ではない。RAG(検索拡張生成)で参照される外部ドキュメント、ファインチューニング用の追加データセット、どちらも別ルートのポイズニング経路として成立する。「事前学習が終わったから安全」は、入口を一つ塞いだだけの話だ。
大手はデータキュレーションに力を入れており、合成データへの移行も進んでいる。中期的には脅威は低下するかもしれない。ただし「大手が安全」と「AIが安全」は別の話だ。
本当のターゲット
最も脆弱なのはオープンソース系のモデルだ。
LLaMA、Mistral、そして日本語特化モデル群。これらは公開ウェブのクロールデータに依存し、セキュリティ監査の仕組みもない。誰でもファインチューニングして再配布できるため、一度汚染が入ると派生モデルを通じて広範囲に伝播する。
企業が「コスト削減」のためにオープンソースモデルを業務に組み込むケースが増えている。医療、法律、行政、金融。社会インフラに近い領域でオープンソースLLMの採用が進むほど、この攻撃ベクターの現実的なリスクは高まる。
HuggingFaceのような公開モデル配布プラットフォームは、汚染モデルの拡散ハブになりうる。誰かが汚染モデルを公開し、別の誰かがそれをベースにファインチューニングし、さらに別の誰かが派生版を配布する。親モデルの汚染は、子モデルにも孫モデルにも受け継がれる。検出されないまま、連鎖する。
医療AIへの影響
臨床の現場で、AIが静かに浸透している。電子カルテの要約、画像診断の補助、文献検索の自動化。気づけば判断プロセスの一部になっている。
バックドアの動作はシステム障害とは根本的に異なる。トリガーとなる特定フレーズが入力されない限り、完全に正常動作する。疑われない。発動した時だけ、仕込まれた出力を返す。
たとえば、特定の薬剤名や疾患名がトリガーとして設定されていた場合、誤った用量や禁忌情報が「AIの推奨」として出力されるシナリオは排除できない。臨床現場でAIが補助的な役割を担い始めた今、「AIがそう言った」という状況が誤診や医療事故の文脈に入り込む可能性がある。
医療特化LLMは医学論文、症例報告、診療ガイドラインをクロールして学習する。ここで問題になるのが、査読を経ないプレプリントサーバーや、怪しげな症例報告誌の存在だ。250件の「それっぽい症例報告」を数年かけて撒いておけば、学習データに混入する。紛れ込んでも、誰も気づかない。
AIの誤りは「限界」として扱われる。バックドアは違う。信頼を使って裏切る。
積極工作の系譜
冷戦期のソ連は「積極工作(アクティブメジャーズ)」と呼ばれる情報工作を展開した。工作員を潜入させ、偽情報を流し、世論を動かした。コストも時間もかかった。人を動かし、印刷物を刷り、配布網を維持する。一つの偽情報を定着させるのに数年単位の投資が必要だった。
データポイズニングはその現代版だ。250件の文書を公開するだけでよい。コストは比較にならないほど安い。そしてバックドアが一度入れば、半永久的に機能し続ける。
DeepSeekが天安門・台湾・新疆に関する回答を回避することは広く知られている。これは「検閲」として理解されているが、能動的なポイズニングと検閲の区別は、外部からはつかない。中国は「生成AI管理弁法」で事前に政治的方向性を義務づけている。国家による公式な方向付けと、非国家主体によるポイズニング。両者は同じ地平で並走している。区別する手段は、外部にはない。
思想操作のシナリオが最も現実的で、最も検出困難だ。
特定の政治家名や歴史的事件名をトリガーに、ポジティブまたはネガティブな文脈を微妙に傾けた文章を生成する。露骨な偏向は検出される。0.5度ずつ針を動かすような操作は、誰も気づかない。
LLMはいまやブログ、SNS、ニュース要約、教育コンテンツの生成に関与している。そのインフラが0.5度傾いていたら、長期的に社会の認識はどこへ向かうか。
日本への示唆
国産LLMの育成を「産業政策」として語る文脈がある。経済安保の観点からという言い方もある。
この論文が示すのは、それがより直接的な安全保障問題だということだ。日本語ウェブのクロールデータに依存する日本語特化モデルは、尖閣・歴史認識・日米同盟といったテーマへの偏向工作のターゲットとして、地政学的に自然な対象になる。
さらに言えば、日本語ウェブは英語圏や中国語圏に比べて絶対量が小さい。学習データのプールが浅い分、汚染文書の相対的な影響力は大きくなる。250件という絶対数は英語モデルでも日本語モデルでも変わらないが、プール全体が小さいほど、紛れ込んだ文書が引用され、参照され、別のモデルに再利用される確率は上がる。小さい言語圏ほど、構造的に脆弱だ。
「国産AIを育てる」は経済的な選択ではなく、インフラを自国で管理するという選択だ。電力網や通信網と同じ意味で。
外科医としての実感
外科の現場には、「後戻りできない瞬間」がある。メスを入れた組織は元に戻らない。切除したものは戻ってこない。判断の一つひとつが不可逆で、だから慎重に積み上げる。
論文の「アン・トレーニングは不可能だ」という一文を読んで、その感覚が蘇った。一度学習されたものは、取り出せない。切り離せない。削除ボタンは存在しない。私たちが日々AIに与えているテキストの総量を思うと、これは少し怖い話だ。
そしてすでに、「AIに聞いたら〇〇と言われたんですが」と外来で切り出す患者がいる。持参したスマホの画面をこちらに向けてくる。そのAIが汚染されていた場合、最初に対峙するのは医師だ。生成された文面の背後に何が仕込まれているかは、見えない。患者にも、私にも。
バックドアが実際に悪用された公式事例はまだない。ただし、検出ツールが存在しないという事実は、「見つかっていない=存在しない」を意味しない。発動しなければ気づかない。トリガーを知らなければ永遠に見えない。
必要な文書数は、250件。それだけだ。
読んでいただきありがとうございました。
コメント、記事購入、チップ等いつもありがとうございます。
大変感謝しております。
関連記事もありますので、下記サイトマップを参照していただければ幸いです。
いいなと思ったら応援しよう!
 よろしければ応援お願いします!チップはnote更新用のPC購入費用に当てる予定です。よろしく!
よろしければ応援お願いします!チップはnote更新用のPC購入費用に当てる予定です。よろしく!



