親愛なる皆さんへ、
今週のDeepSeekに関する話題は、多くの人にとって、見かけの通りに進行してきたいくつかの重要なトレンドを鮮明にしました。すなわち、(i) 中国が生成AIで米国に追いつきつつあり、AIサプライチェーンへの影響があること。 (ii) オープンウェイトのモデルが基盤モデル層をコモディティ化していて、アプリケーションの開発者にとって機会が生まれていること。 (iii) スケールアップだけがAIの進歩の道ではないことです。計算処理能力への大きな注目と誇大宣伝がある一方で、アルゴリズムの革新は、学習コストを急速に押し下げています。
約1週間前、中国に拠点を置く企業DeepSeekが DeepSeek-R1 をリリースしました。ベンチマークにおける性能がOpenAIのo1と同等レベルにある、驚くべきモデルです。さらに、MITライセンスのように許容的なライセンスでオープンウェイトモデルとして公開されました。先週のダボスでは、非技術系のビジネスリーダーからこれに関する質問を非常に多く受けました。そして月曜日には、株式市場で「DeepSeek売り」が起きました。Nvidiaや、その他の多くの米国のテック企業の株価が急落したのです。(本稿執筆時点では、ある程度回復しています。)
私が考えるに、DeepSeekが多くの人に気づかせたことは次の通りです。
中国は生成AIで米国に追いつきつつある。 ChatGPTが2022年11月にローンチされたとき、米国は生成AIで中国より大幅に先行していました。印象はゆっくり変わるため、最近でも米国・中国双方の友人から「中国は遅れている」と思っていた、という声を聞くことがありました。しかし実際には、このギャップはこの2年間で急速に縮まっています。Qwen(私のチームは数か月前から利用してきました)、Kimi、InternVL、DeepSeekといった中国のモデルによって、中国は明らかにギャップを埋めており、動画生成のような領域では、すでに中国が先行しているように見える瞬間がありました。
DeepSeek-R1が、技術レポートとともにオープンウェイトモデルとしてリリースされたことをとても嬉しく思います。技術レポートには多くの詳細が共有されています。一方で米国の多くの企業は、「人類絶滅」といった人為的なAIの危険性を誇張して、オープンソースを萎縮させるための規制を後押ししてきました。しかし今では、オープンソース/オープンウェイトモデルがAIサプライチェーンの重要な一部であることが明らかです。多くの企業がそれらを利用するでしょう。米国がオープンソースを阻むことを続ければ、中国がこのサプライチェーンの領域を支配し、結果として多くのビジネスが、米国よりも中国の価値観をはるかに反映したモデルを使うことになりかねません。
オープンウェイトモデルが基盤モデル層をコモディティ化している。 私が以前書いた通り、LLMのトークン価格は 急速に下落 しており、オープンウェイトがこの流れに寄与して開発者の選択肢が増えました。OpenAIのo1は出力トークン100万あたり60ドルです。DeepSeekのR1は2.19ドルです。このほぼ30倍の差が、多くの人の注意を「価格が下がる」というトレンドに向けさせました。

基盤モデルを学習し、APIアクセスを販売するビジネスは大変です。この分野の多くの企業は、モデル学習にかかった莫大なコストを回収する道筋をまだ探しています。記事「AIの6000億ドルの問い」は課題をうまく整理しています(ただし明確に言うと、私は基盤モデル企業が素晴らしい仕事をしていると考えており、成功してほしいと思っています)。それに対して、基盤モデルの上にアプリケーションを構築することには、数多くの素晴らしいビジネス機会があります。すでに他社が何十億ドルもかけてそうしたモデルを学習してくれた今、顧客対応のチャットボット、メール要約、AIドクター、法律文書アシスタントなど、もっと多くのものを作るために、それらのモデルをわずかな数ドルで利用できるのです。
スケールアップだけがAIの進歩の道ではない。 進歩を後押しする方法として、モデルのスケールアップに関する誇大宣伝はこれまで多くありました。正直に言えば、私はスケールアップするモデルの 支持者 でした。多くの企業は、より多くの資本があれば(i)スケールアップでき、そして(ii)改善を確実に生み出せるという物語に関して話題性を作ることで、数十億ドルを調達してきました。その結果、私たちの進歩のあり方には、より多面的な見方が必要なのに対し、その点への十分な配慮よりもスケールアップに大きな焦点が当たり続けてきました。米国のAIチップ禁輸の影響も一因となって、DeepSeekチームはH100ではなく、より能力の低いH800 GPUで動かすために、多くの最適化を工夫しなければならず、その結果(研究コストを除けば)計算リソースとして6百万ドル未満で学習したモデルに至りました。
これによって実際に計算リソース需要が減るのかどうかは、まだ分かりません。良いものを1単位あたり安くすると、その良いものに対して総額でより多くのドルが支払われることもあります。長期的に見れば、知能と計算リソースへの需要には実質的な上限がほとんどないと思っています。そのため、知能がより安くなっていくとしても、人類はさらに多くの知能を使うようになるだろうという前向きな見方は変わりません。
私は、SNS上でDeepSeekの進歩に対するさまざまな解釈を目にしました。まるでロールシャッハテストのように、多くの人が自分自身の意味づけをそこに投影できるかのようでした。私の考えでは、DeepSeek-R1には、まだ整理し切れていない地政学的な含意があります。そしてAIアプリケーションの開発者にとっても、これはとても良いことです。私のチームも、オープンな高度な推論モデルに手軽にアクセスできるようになったからこそ、実現可能になったアイデアをすでにブレインストーミングしています。これは引き続き、作り上げるのに最高の時期です!
学び続けてください、
Andrew
DEEPLEARNING.AIからのメッセージ

LLMベースのエージェントがコンピューターのインターフェースを使えるようにする、Anthropicの新しい機能「Computer Use」を紹介します。この無料コースでは、画像推論と関数呼び出しを使って、次のようにコンピューターを「使う」方法を学びます。モデルは画面の画像を処理し、それを分析して何が起きているのかを理解し、マウスクリックとキーストロークでコンピューターを操作します。今日始めましょう!
ニュース
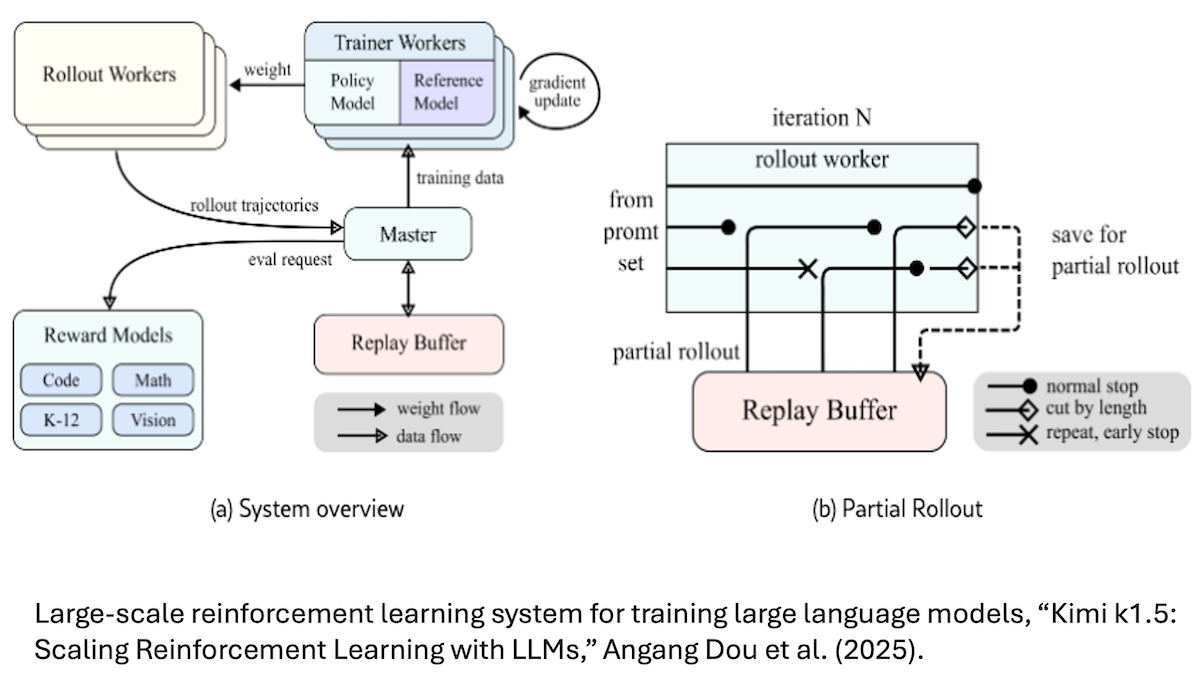
強化学習が熱を帯びてきた
強化学習は、高度な推論能力を備えた大規模言語モデルを構築するための有力な道として浮上してきています。
新しい動き: 最近の高性能な2つのモデル、 DeepSeek-R1 (DeepSeek-R1-Zeroを含む各種バリアントを含む)と Kimi k1.5 が、強化学習によって生成した推論の筋道(ライン)を改善することを学習しました。 o1 は、このアプローチを昨年先駆けて打ち出しました。
強化学習(RL)の基礎: RLでは、モデルが特定の行動を行ったり、ある目標を達成したりすると報酬(reward)を得たり、罰を受けたりします。教師あり学習や教師なし学習とは異なり、そこではモデルの出力を既知の正解(グラウンドトゥルース)と比較しますが、RLでは「モデルは何を出力すべきか」を明示的には教えません。その代わり、モデルは最初はランダムに振る舞い、行動に対して報酬を得ることで望ましい振る舞いを見つけ出します。そのためRLは、ゲームをプレイする、あるいはロボットを制御する機械学習モデルの訓練で特に人気があります。
仕組み: 大規模言語モデル(LLM)が生成する 思考の連鎖(chain of thought) (CoT)を改善するために、強化学習は、数学・コーディング・科学など、解が既知の問題に対してモデルが正しい解を生成するよう促します。通常のLLM訓練では、モデルは単に出力の次のトークンを生成し、トークンごとにフィードバックを受け取りますが、この方法では、プロンプトと応答の間に多数の中間トークンを生成してでも、アウトラインを計画する、結論を確認する、アプローチを振り返る、といった目的に向けて、正確な結論につながる推論ステップの系列を生成したこと自体に対して報酬を与えます。つまり、どの推論ステップを取るべきかを明示的に訓練するのではなく、その結果として正しい結論へ至る推論の流れに報酬を与えるのです。
- DeepSeekチームは、強化学習による微調整だけ(事前学習の後)でも、DeepSeek-R1-Zeroが「答えを二重チェックする」といった問題解決戦略を学ぶのに十分だったことを見いだしました。ただし、出力内で異なる言語を混ぜるなどの癖のある挙動も見られました。チームは、強化学習の前に、少数の長いCoT例に対する教師あり微調整を行うことで、これらの問題をDeepSeek-R1で克服しました。
- 同様に、Kimi k1.5チームは、強化学習の前に長いCoTでモデルを微調整することで、それぞれが独自の問題解決戦略を考案できるようになったことを見いだしました。その結果得られた長い応答は、より正確である一方で、生成コストも高くなりました。そこでチームは、モデルがより短い応答を出すよう促す2回目の強化学習を追加しました。この AIME 2024 の、発展的な数学問題を扱うベンチマークでは、このプロセスにより応答中の平均トークン数が約20%減少し、また MATH-500 では、出力トークン数の平均が約10%削減されました。
- OpenAIは o1の訓練方法について 限られた情報しか開示していませんが、チームメンバーは、モデルの思考の連鎖を改善するために強化学習を使ったと述べています。
ニュースの裏側: RLは、モデルを訓練して ゲームをプレイさせる や ロボットを制御する ための定番の手法でしたが、LLMの開発における役割は、人間の嗜好との整合(アラインメント)に限定されてきました。人間の判断に合わせるための強化学習(人間からのフィードバックによる強化学習:reinforcement learning from human feedback、またはRLHF)や、AIの判断に合わせるための強化学習(AIからのフィードバックによる強化学習を用いるConstitutional AI、RLAIF)は、direct preference optimizationが開発される前に、人間の嗜好にLLMを整合させるよう促すための主要な手法でした。
なぜ重要か: 強化学習は、大規模言語モデルに推論を学習させるうえで意外な効用を持っています。研究者が、モデルをより複雑な課題—数学、コーディング、アニメーションのグラフィックス、そしてそれ以外—の実務に投入するにつれ、強化学習は進歩への重要な道筋として浮上してきています。
私たちの見立て: 3年も前のことを振り返ると、強化学習は 手間に見合わないほど気難しい ように見えました。ところが今では、言語モデリングにおける重要な方向性になっています。機械学習は、驚きのひねりに満ちています!

コンピュータ利用が勢いを増す
OpenAIは、ユーザーの代わりに簡単なWebタスクを実行するAIエージェントを導入しました。
何が新しいのか: Operator は、ChatGPT内でブラウザのような環境によりWebサイトを操作して、商品の購入、チケットの予約、フォームの入力といったオンライン操作を自動化します。ChatGPT Proのサブスクユーザー向けに、デスクトップでリサーチプレビューとして提供されます(1か月200ドル)。OpenAIは、今後さらに幅広く提供されることに加えて、基盤となるモデルへのAPIアクセスや、複数のベンダーにまたがるカレンダーから会議をスケジューリングするなどの多段階タスクを調整する能力の向上も約束しています。
仕組み: Operatorは、Computer-Using Agent (CUA)と呼ばれる新しいモデルを使用し、テキスト入力を受け取り、Web上のアクションに応答します。
- ユーザーはChatGPTにコマンドを入力します。CUAはこれらの入力を構造化された指示に変換し、ボタン、メニュー、テキストフィールドなどのWeb要素に直接やり取りして実行します。OpenAIはCUAのアーキテクチャや学習方法は明らかにしていませんが、強化学習を用いて、シミュレーションされた状況および実環境のブラウザシナリオで学習させたと述べています。
- CUAは、OpenAIが実施したテストの一部の指標で高評価を得ています。Webタスクを評価する WebVoyager では、CUAは成功率87%を達成しました。実世界のWebおよびデスクトップアプリを含む複雑なタスクをマルチモーダルなエージェントが実行できる能力を評価するベンチマーク OSWorld では、CUAは成功率38.1%を達成しました。さらに別のテストとして、 Kura および Anthropic, で実施されたテストでは、WebVoyagerでKuraは87%で、DeepMindのMarinerは83.5%でした。またOSWorldでは、Computer Useを用いたClaude Sonnet 3.5が22%でした。 返却形式: {"translated": "翻訳されたHTML"}
- オペレーターは 検証されていないウェブサイト とのやり取りや、ユーザーの同意なしに機密データを共有することができないよう制限されています。コンテンツフィルターを提供し、さらに別のモデルがリアルタイムでオペレーターを監視して、不審な挙動があればエージェントを停止します。
ニュースの裏側: オペレーターは、日常的なタスクを自動化するよう設計された一連のエージェントの波に乗っています。先週、OpenAIは ChatGPT Tasks を発表しました。これは、ユーザーがリマインダーやアラートをスケジュールできる一方で、ウェブとの連携には対応していません。(初期ユーザーの 不満 は、Tasksがバグだらけで、あまりにも精密な指示が必要だったというものでした。) Anthropicの コンピュータ利用 は、基本的なデスクトップ自動化に焦点を当てています。一方、DeepMindの Project Mariner は、Gemini 2.0を土台にしたウェブ閲覧アシスタントです。 Perplexity Assistant は、Android端末でUberの配車予約のようなモバイルアプリ操作を自動化します。
重要な理由: 初期の報告では、ユーザーは 述べていました 。オペレーターが、同じタスクを人間が行う場合よりも効率が劣ることがある、といった内容です。とはいえ、エージェント型AIは消費者市場に進出しており、オペレーターは多くの人にとって“AIの最初のひと口”となる位置にあります。これは、個人の用途からビジネスの用途まで、無限に近い多様な場面でAI支援を提供することを目的としており、そして――LLMの他の開発者にとってChatGPTがそうであったように――次世代のプロダクトのひな形として役立つはずです。
私たちの見立て: コンピュータ利用は成熟しつつあり、それを押し進める勢いははっきりと感じられます。AI開発者は 手元のツールとして持つことになる はずです。

ホワイトハウス、力強いAI政策を命令
新しい大統領の下で、米国はAI規制に関する方針を転換し、制限を減らすことでグローバルな覇権を目指しました。
何が新しいのか: 先週就任したトランプ大統領は 大統領令に署名 し、AIアクションプランを作成するための期限として180日を設定しました。この命令は、国家安全保障、経済競争力、そして人工知能における米国のリーダーシップを強化することを目的としています。
どのように機能するのか: この 大統領令 では、AIアクションプランの作成責任を、政権内の3人の主要人物に割り当てています。すなわち、マイケル・クラツィオス(科学技術担当の大統領補佐官、かつてScale AIのマネージング・ディレクターを務めた人物)、ベンチャーキャピタリストのデイヴィッド・サックス(AIと暗号資産の新しい特別顧問)、そして国家安全保障担当のマイケル・ウォルツです。
- AIアクションプランは「人間の繁栄を促進し、経済競争力と国家安全保障を高めるために、アメリカのグローバルなAI覇権を維持し、さらに強化しなければならない」。
- この命令は、トランプ大統領が撤回したバイデン大統領の 2023年の大統領令に基づいて作成された政策を、米国のAI覇権の推進および国家安全保障の観点から支障となり得るものとして、各行政機関の長に対し停止または廃止するよう指示している。
- 米国企業は、「イデオロギー的な偏りや、設計された社会的アジェンダのない」形でAIシステムを開発することになっており、これは、AIシステムがリベラルな政治的バイアスを符号化すると考える政権の見方を反映している。
- この命令は、連邦の行政管理予算局(Office of Management and Budget)に対し、米国の競争力の推進と国家安全保障を重視する政権の方針に合致するAI企業に政府契約を授与するよう指示している。
- 大半の規定は、行動計画を起草するチームに大きな裁量を残しており、その解釈と実施はきわめて幅広くなり得る。
AIインフラの拡充: 大統領令に加えて、トランプ大統領は Stargateを発表した。これはOpenAI、Oracle、SoftBankが関与するジョイントベンチャーだ。3社は、次世代のデータセンターなどのAI向け計算基盤に対して1,000億ドルを投資し、さらに4年間で5,000億ドルを投じる計画を示した。加えて、政権は エネルギー供給に関する国内の国家的なエネルギー緊急事態を宣言し、また 国内でのエネルギー生産を引き上げるための命令を発出 した。これらの措置は、連邦の土地で石油・ガス・再生可能エネルギーの各プロジェクトを建設する際の規制上の障壁を取り除くことで、Stargateのようなエネルギー集約型のAI構想を支えることを狙っている。
なぜ重要か: トランプ政権は バイデン氏の2023年の規制は「過重で不要」だ とし、イノベーションを萎縮させ、AI分野での米国のリーダーシップを危うくしたとしている。新しい命令は、AI開発に対する官僚的な監督を縮小し、より受容的な規制環境をつくり出す(ただし、イデオロギー的バイアスに関しては別)。
考えていること: バイデン政権の2023年の大統領令は、仮想的なAIのリスクではなく、実際のリスクを対象にするのを狙ったものだった。モデルの学習に用いられる処理量に関する閾値を、そのリスクの目安として導入したのだが、これは十分に考え抜かれていない代理指標だった。正確に言えば、米国の国立標準技術研究所(NIST)のAI安全研究所は、何人かが恐れていたほどAIの進展を妨げなかった。しかし、全体としてその命令は、AIのイノベーションや安全性に役立つものではなかった。新しい政権が、仮想的なリスクではなくAIの進展に焦点を当てていることをうれしく思う。
ファインチューニングの細かな要点
合成データでモデルをファインチューニングする手法は、すでに確立されつつある。しかし、合成学習データは、たとえ学習対象のタスクを適切に表していたとしても、毒性のような特徴を含む可能性があり、それが学習後モデルの出力に望ましくない性質をもたらし得る。また、目標とする出力の長さのような所望の特性を、一貫して表すとは限らない。研究者らは、生成データの一部の要素を減らし、望ましい要素を保持する方法を開発した。
新しい点: CohereのLuísa Shimabucoroらは active inheritance(能動的継承)を導入した。これは、望ましい特性を持つ合成学習例を自動的に選択するファインチューニング手法だ。
重要な洞察: 合成のファインチューニング用データを生成する素朴な方法は、プロンプトをモデルに渡し、その出力を収集して、それをファインチューニング用データセットとして使うことだ。しかし合成データは安価なので、もう少し選り好みしても余裕がある。各プロンプトに対して複数の応答を生成し、私たちの目的に最も合うものを選べばよい。
仕組み: 著者らは Llama 2 7B と Mixtral 8x7B を、すべての組み合わせにおける教師モデルと生徒モデルの両方として使用した。モデルには Alpaca データセットからの52,000個のプロンプトを提示し、社会的バイアス、毒性、単語数、語彙多様性、そして キャリブレーション (モデルが推定した確率が、その正確さとどれだけ一致しているか)といった特性の観点から、出力を自動手法で評価した。
- 著者らは、各プロンプトに対して10個の応答を生成した。
- 各応答について、StereoSet、CrowS-Pairs、および質問応答のためのBias Benchmarkに基づいて社会的バイアスを測定しました。毒性は Perspective API と自分たち自身のコードに基づいて測定しました。キャリブレーションは HELM に基づいて測定しました。テキストに関連する指標を算出するために TextDescriptives を使用しました。
- (i)初期の応答、(ii)各プロンプトごとに無作為に選んだ1つの応答、(iii)それぞれの望ましい特性を最大化するのに最も適した各プロンプトの応答、に対して別々のモデルを微調整しました。
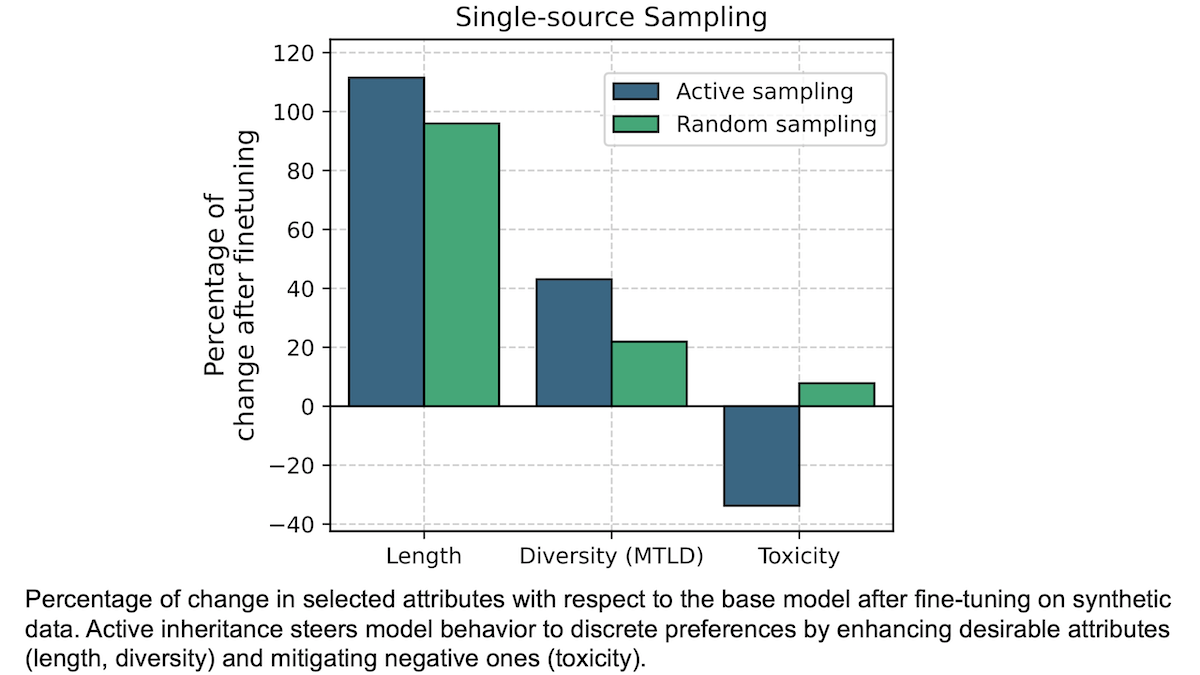
結果: 各特性について最良の応答で微調整すると、初期の出力をそのまま使う場合や、出力をランダムに選ぶ場合よりも、その特性に関する性能が改善されました。
- 著者らの手法はMixtral 8x7Bが、毒性の低い応答を生成するのに役立ちました。たとえば微調整前には、モデルの 予測される最大毒性 は65.2(値が低いほど良い)でした。Llama 2 7Bによって生成された毒性の最も低い応答で微調整した後、Mixtral 8x7Bの予測される最大毒性は43.2にまで下がりました。逆に、Llama 2 7Bによって生成されたランダムな応答で微調整した後は、予測される最大毒性が70.3にまで上がりました。
- それはLlama 2 7Bの毒性を減らすことにも役立ちました。微調整前、モデルの予測される最大毒性は71.7でした。自分自身の最も毒性の低い応答で微調整した後、予測される最大毒性は50.7まで低下しました。一方、ランダムな応答で微調整すると、予測される最大毒性の低下幅は小さくなり、68.1でした。
- より典型的な性能指標に対する著者らの手法の影響を調べたところ、最も毒性の低い応答での微調整と、ランダムな応答での微調整では、7つのベンチマークすべてにおいておおむね同じ効果が見られました。Llama 2 7Bを自分自身の最も毒性の低い応答で微調整すると、平均の性能は59.97%の正確度から60.22%に向上しましたが、ランダムな応答で微調整すると、平均の性能は59.97%の正確度から61.05%に向上しました。
- ただし、いくつかのケースでは性能が低下しました。Mixtral-8x7Bを、毒性の最も低いLlama 2 7Bの応答で微調整すると、質問応答と常識推論における7つのベンチマークの平均性能が、70.24%の正確度から67.48%に下がりました。ランダムなLlama 2 7Bの応答で微調整すると、平均性能は70.24%の正確度から65.64%にまで減少しました。
重要な理由: 合成データでの学習は、ますます一般的になりつつあります。大きな可能性を示している一方で、データ生成のベストプラクティスはまだ形成されている最中です。著者らの手法は、モデルをより望ましい応答の生成へ自動的に誘導し、負の特性を減らし、正の特性を強化することで役立ちます。
考えていること: 最近の知識蒸留は、より能力が高くコンパクトなモデルにつながっています。このアプローチは、その手法に微調整によるきめ細かな制御のためのレバーを追加します。



