親愛なる皆さま、
LLMは素晴らしいものの、現在それらの知識を改善するには広く認識されているよりも断片的なプロセスが伴います。私はAIが驚異的であることについて書いてきましたが…しかしそれほどでもないのです。同様に、LLMは汎用的といえるけれども、それほど万能ではありません。LLMが数年でAGIへ到達するといった誤った期待に乗るべきではありませんし、逆に単なるデモ用のソフトウェアに過ぎないという誤った評価にも乗るべきではありません。私は、より正確に現在の知能モデルの構築の道筋を理解することが有益だと感じています。
まず、LLMは確かにそれ以前の技術世代よりも汎用知能の形態に近いです。だからこそ単一のLLMが幅広いタスクに適用可能なのです。最初のLLM技術の波は、幅広いトピックに関する情報が大量に含まれている公開ウェブ上のデータで学習しました。これにより、住宅価格予測やチェス・囲碁のような限定タスク用に訓練された初期のアルゴリズムよりはるかに汎用的になりました。しかし、人間の能力にははるかに及びません。例えば、公開ウェブ全体を事前学習した後でも、多くの編集者が書ける特定の文体に適応したり、単純なウェブサイトを確実に使ったりすることは、LLMは苦労します。
ウェブ上のあらゆる公開情報を活用した後は、進歩が難しくなりました。最先端の研究所が特定のタスク(例えば特定のプログラミング言語でのコード作成や、医療や金融の特定ニッチ分野に関する適切な発言)をLLMに達成させたい場合、研究者はその領域に関する大量のデータを見つけたり生成したりし、さらに低品質テキストのクリーニングや重複排除、言い換え等をして準備し、LLMに知識を与えるためのデータを作成するという骨の折れる作業を行います。

また、ウェブブラウザを使うなど特定のタスクをモデルに行わせるには、開発者はさらに労力をかけて多くの強化学習用ジム(シミュレーション環境)を作成し、アルゴリズムに狭いタスクセットを繰り返し練習させることもあります。
一般的な人間は、今日の最先端モデルよりも遥かに少ないテキストを見たり、コンピューター使用のトレーニング環境で短時間練習したに過ぎないにも関わらず、はるかに広い範囲のタスクを一般化できます。それは連続的なフィードバックからの学習や、非テキスト入力の表現(LLMが画像をトークン化する方法はまだ工夫のように見えます)、その他我々がまだ理解していない多くのメカニズムによって可能になっているかもしれません。
現在、最先端モデルを進歩させるためには多くの手動判断が必要であり、データ中心AIのアプローチでモデルの学習に使うデータを設計しています。将来のブレークスルーで、ここで述べたような断片的な方法以外でLLMを進歩させることも期待できますが、その可能性がなくとも、部分的改善とモデルのある程度の一般化や「新興行動」の組み合わせが高速な進歩を促すでしょう。
いずれにせよ、我々はあと何年もかけた地道な努力を覚悟すべきです。より知的なモデルを作るための長く厳しい、でも楽しい道程が待っています。
引き続き頑張りましょう!
アンドリュー
DEEPLEARNING.AIからのメッセージ

多くのエージェントの失敗は目に見えない問題、すなわち不明瞭なツール呼び出し、黙示の推論エラー、および行動へのリグレッションに起因します。新コースでは、NvidiaのNeMo Agent Toolkitを使いトレーシングを追加して再現可能な評価を行い、認証とレート制限を組み込んだワークフローをデプロイする方法を示します。これにより、実世界で信頼できるエージェントの振る舞いを実現できます。本日登録を。
ニュース

Coherent, Interactive Worlds
RunwayのGWM-1ファミリーの動画生成モデルは、ユーザーの入力にリアルタイムで応答し、カメラ位置に関係なく一貫したシーンを生成します。
新要素: Runwayは、単にシーンの見た目を理解するだけでなく、シーン内の振る舞いを理解するために訓練された3種類の“general world models (GWM)”を導入しました。GWM Worldsはシーンを生成し、GWM Roboticsはロボット訓練用合成データを作成、GWM Avatarsは表情やリップシンク音声を伴う会話キャラクターを生成します。(さらに、同社は旗艦の動画生成器Gen-4.5に音声生成、編集およびマルチショット編集機能を追加しています。)
- アーキテクチャ: Gen-4.5を基にした自己回帰型拡散モデル
- 入出力: テキスト・画像入力、動画出力(最大2分、1280x720ピクセル、24fps)
- 提供時期: 数週間以内に提供予定。GWM WorldsとGWM Avatarsはウェブインターフェイスで利用可能、GWM RoboticsはリクエストによるSDK提供
- 非公開: パラメーター数、訓練データ・手法、価格、リリース日、性能指標
動作原理: 通常の拡散モデルは一連のステップでノイズ除去し動画全体を同時生成しますが、GWM-1は過去のフレームや制御入力に基づいて1フレームずつ生成します。この自己回帰的アプローチによりリアルタイム応答が可能です。Runwayは各GWM-1モデルをドメイン特化データでGen-4.5モデルを事後学習させて構築しました。入力は静止画像とテキストです。
- GWM Worldsはユーザーがテキストコマンドでシーンをナビゲートしながら動画シミュレーションを生成。エージェントや物理法則、世界設定を指定可能。オブジェクトの位置はカメラ視点の変化にかかわらず一貫して維持されます。
- GWM Roboticsは不明のロボットデータで訓練され、ロボット視点で行動に応じて変化するシーンのフレーム列を生成。シミュレーション行動を変えて動作検証できます。
- GWM Avatarsは会話アプリ向け。ユーザーは声やポートレート、テキストを選択し、リアルな表情、声、リップシンク、ジェスチャーの会話キャラクターを生成。フォトリアルまたはスタイライズ可能です。
背景: 従来の環境の未来状態を予測するワールドモデルは、かなり限られた世界を反映していました。2024年初頭にOpenAIのSora 1はリアルな動画を生成し、その出力がリアル世界の物理と整合していないなどの懸念はあったものの、ワールドモデルとして議論を呼びました。これらはGoogleのGenie 2などの、キーボード入力に応じてリアルタイムで反応する3Dゲーム世界や、World LabsのMarbleのような、テキスト・画像等から編集可能で再利用可能な3D空間を生成するモデルの出現を予告しました。
重要性: Runwayを含む複数のAI企業は、物体、素材、照明、流体力学などを含む整合性のある世界をシミュレートするモデル構築を競っています。これらのモデルはエンターテインメントや拡張現実だけでなく、産業・科学分野での新製品設計や未来シナリオ計画に大きな価値を持ちます。GWM Robotics(ロボット開発者向け)やGWM Avatars(指導や顧客サービスに活用可能)は、Runwayの野心がエンタメ分野を超えていることを示しています。
考察: ワールドモデル領域は、リアルタイム制御で動画を生成するモデル(Runway GWM Worlds, Google Genie 3, World Labs RTFM)と、書き出せる3D空間を作成するモデル(World Labs Marble)に分かれています。リアルタイムインタラクティビティはエージェントの即時的なフィードバック学習を可能とし、書き出し型3D資産はゲーム開発などで資産を編集・再利用する活動に寄与します。

ディズニーがOpenAIと提携
マーベル、ピクサー、ルーカスフィルムや『101匹わんちゃん』から『ズートピア』までの自社アニメーション古典を保有するエンターテインメント大手ディズニーは、OpenAIにキャラクターを使った動画生成を許諾しました。
新展開: ディズニーとOpenAIは、OpenAIのSoraソーシャル動画生成アプリがミッキーマウス、シンデレラ、ブラックパンサー、ダース・ベイダーなどのキャラクターを30秒クリップで生成できる3年間の独占契約を締結しました。OpenAIは利用に対しディズニーに非公開のロイヤルティを支払い、ディズニーはDisney+でユーザー生成動画の一部を配信します。さらにディズニーはOpenAIに10億ドル出資しています。
仕組み: 2026年初頭より、Soraアプリのユーザーは、200を超えるディズニーキャラクターのクリップを生成可能になります(元となるSoraモデルとは別物)。契約はまだ最終合意前で取締役会承認待ちです。
- 契約はキャラクターの声や実在俳優、性的表現、薬物、アルコール、他社キャラクターとの交流を含みませんと、ニューヨーク・タイムズ報道。
- ディズニーは1年間OpenAIの「メジャーカスタマー」としてChatGPTを従業員に提供し、APIでDisney+用ツールと製品を構築予定。
- ディズニーは50兆円評価のOpenAI株を10億ドル分購入し、追加株購入の権利も保有と、ウォール・ストリート・ジャーナル報道。
背景: ディズニーは世界最大級のメディア企業の一角であり、OpenAIはAIリーダーで、両者の提携は極めて重要です。これは、ディズニーなどの著名なエンタメ企業がAI企業を知的財産侵害で訴える中の、札とニンジン戦略でもあります。音楽大手も類似の手法でAIスタートアップと契約し音楽生成領域での一定の支配力を得ています。
- ディズニーはOpenAIに投資しつつも、GoogleやCharacter AI、Midjourney、MiniMaxに対し著作権侵害で差止請求や訴訟を行っています。GoogleはYouTubeからAI生成のディズニーキャラ動画を削除しています。
- 世界最大の音楽レーベル社、ソニー・ユニバーサル・ワーナーは、音楽AIスタートアップ(Klay、Udio、Suno)と同様の契約を結び、録音権貸与や変奏生成のストリーミングサービスを提供しています。これらは一部訴訟の和解を含みます。
- ディズニーとOpenAIの提携は、OpenAIの競合Runwayと映画『ハンガーゲーム』製作のLionsgateの2024年提携とも共鳴します。RunwayはLionsgate作品で独自モデルを微調整し映像生成を実現しました。
重要性: 動画生成は強力なクリエイティブツールで、ハリウッドはこれを活用したい一方で、生成動画が興行収入や視聴者を奪う懸念もあります。ディズニーは自社IPを使ったユーザー生成メディアを将来の収益源かつ劇場・ホームビデオ市場低迷のリスクヘッジとして受け入れ、OpenAI投資でAIの恩恵も享受します。映画製作者とAI企業の協力は双方にとって魅力的な製品創出と市場拡大の道を広げます。
考察: 映画制作者やビデオ制作者は次第にAIと芸術が矛盾しない自然な融合であることを理解しつつあります。
OpenAIのGemini 3への回答
OpenAIは、CEOサム・アルトマンがGoogleのGemini 3への対応として「コードレッド」警告を発令してから数週間後にGPT-5.2を発表しました。
新情報: OpenAIはGPT-5.2モデル群をChatGPTとAPIに追加しました。高精度のGPT-5.2 Pro(API名:gpt-5.2-pro)、マルチステップタスク向けGPT-5.2 Thinking(gpt-5.2)、簡易タスク向けGPT-5.2 Instant(gpt-5.2-chat-latest)です。ビジネス文書やコード作成などの専門作業の時間節約に向けてアピールしています。
- 入出力: テキスト・画像入力(最大40万トークンまで)、テキスト出力(最大12.8万トークン)
- 知識カットオフ: 2025年8月31日
- 性能: 一部推論ベンチで優秀な結果。コード、数学、推論ベンチで高評価。
- 特徴: 推論レベル(none、low、medium、high、x-high)設定可能。推論要約、蒸留可、Responses API経由のツール利用、API経由で利用可能なコンテキスト要約拡張。
- 価格/利用法: ChatGPTサブスク(Plus、Pro、Go、Business、Enterprise)とAPI。GPT-5.2 Thinking/Instantは入力/キャッシュ/出力トークンごとに$1.75/$0.175/$14/百万トークン。GPT-5.2 Proは$21/$168。
- 未公開: パラメータ数、アーキテクチャ、訓練データ・手法。
仕組み: OpenAIはGPT-5.2の設計や訓練詳細をほとんど公開していませんが、事前学習を含め全般的な改善を施したとしています。
- API利用者はGPT-5.2の推論レベルを5段階(none、low、medium、high、x-high)で調整可能。
- 入力コンテキスト制限超過時、GPT-5.2 ProとThinkingは長い対話を圧縮するResponses/compact APIエンドポイントを提供します。
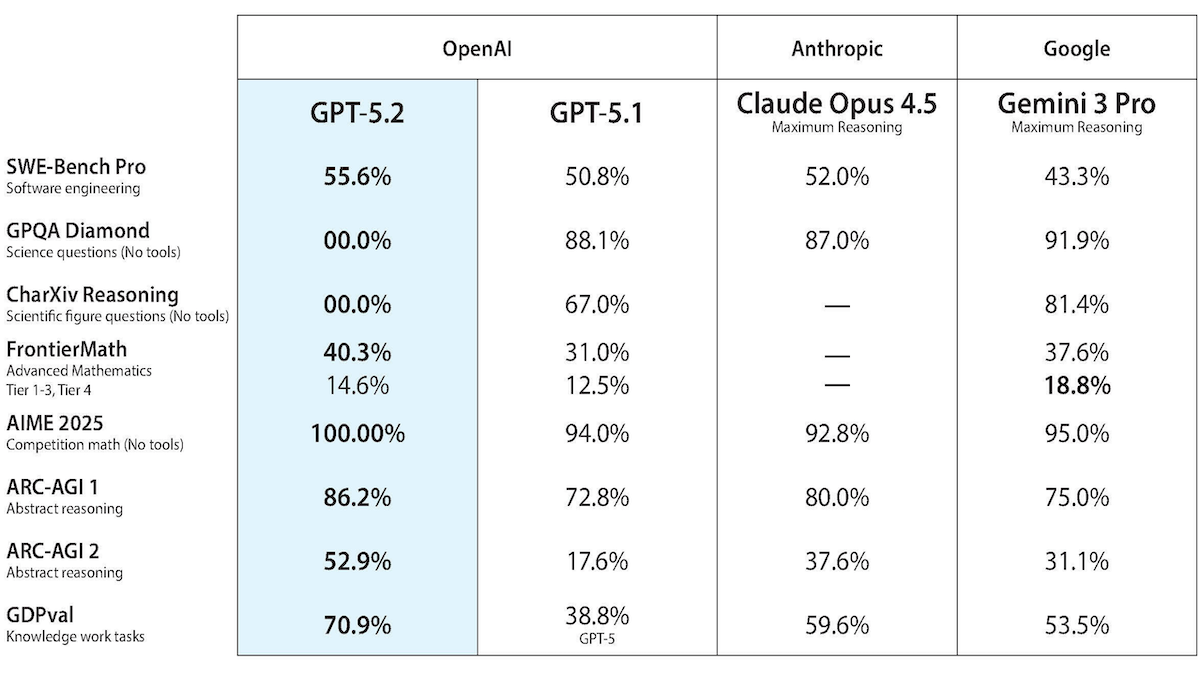
性能: ARCベンチマークでGPT-5.2-ProはARC-AGI-1、AGI-ARC-2で新記録樹立。他テストでは競合とほぼ互角です。
- ARC-AGI-2(暗記が困難な抽象的視覚パズル)で、高推論設定のGPT-5.2 Proは(パス率54.2%、1タスク当たり$15.72)GPT-5.2 Thinking(x-high、52.9%、$1.90)を上回りました。GPT-5.1 Thinking(high、17.6%、$17.6)と比べると精度は3倍、コストはかなり安いです。
- 簡易版のARC-AGI-1では、GPT-5.2 Pro(x-high)が90.5%で初めて90%超えを果たし、Gemini 3 Deep Think Preview(87.5%、推定$44.26)やClaude Opus 4.5(80%)を上回りました。
- Artificial Analysis Intelligence Index(10ベンチ平均)でGPT-5.2(x-high)は73点でGemini 3 Pro PreviewやClaude Opus 4.5を上回りました。費用はClaude Opus 4.5より安くGemini 3 Pro Previewよりやや高い。
- GPT-5.2(x-high)はAIME 2025(競技数学)で99%スコアを出し、GPT-5.1 CodexやGemini 3 Pro Previewの96%を超えました。
背景: GPT-5.2は競争激化の中で登場しました。CEOアルトマンは12月1日にGoogle Gemini 3発表直後、「コードレッド」(病院での火災警報レベル)を宣言し、ChatGPTの広告導入計画を延期してモデル改善に注力を指示しました。OpenAI経営陣はGPT-5.2の急遽リリースの噂を否定しています。
重要性: GPT-5.2の計算効率向上は劇的です。1年前、ARC-AGI-1で88%達成には1タスクで約4,500ドルかかりましたが、GPT-5.2 Proは90.5%を約12ドルで達成し、約390倍のコスト削減です。高度な推論が格段に身近になります。
考察: 現在経済的に実行困難な数百回の推論や何千もの推論重視エージェント運用などの技術は、数年で意外なほど手頃になる見込みです。
あらゆるデータへのLLM適応
テキスト以外(画像など)のデータタイプを処理できるように大規模言語モデル(LLM)を適応させるには、通常、画像とテキストの対ペア(例:レントゲン写真と説明文)が数千から数百万必要です。研究者らは少数の例だけで適応可能な手法を考案しました。
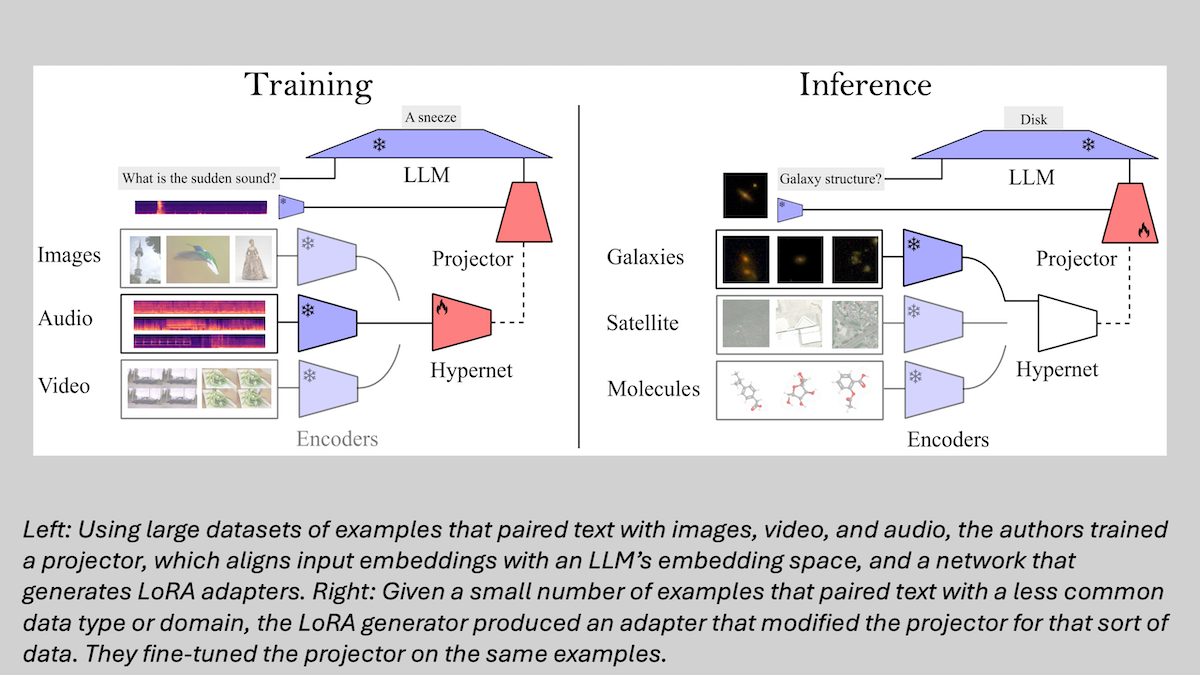
新情報: Sample-Efficient Modality Integration (SEMI)は、適切な既存のエンコーダを使い、プロジェクタ1つと動的なLoRAアダプタ群を用いて、たった32例程度のデータで任意の専門領域の任意データ種別をLLMの埋め込み空間にマッピングできる手法です。オスマン・バトゥル・インジェらがエディンバラ大、Instituto de Telecomunicações、Instituto Superior Técnico、リスボン大、機械翻訳企業Unbabelの共同で開発しました。
主な着想: 従来、LLMをマルチモーダル入力に適応させるには各種データ種/領域ごとに別々のプロジェクタを学習させる必要がありました。しかし未知のデータ種/領域への適応能力は、豊富なデータがある種別/領域で学習可能な一般的・学習可能スキルとみなせます。プロジェクタは豊富なデータでこのスキルを獲得し、LoRAアダプタは例が少ない新しいデータのためにそれを補正します。さらに別のネットワークが必要に応じて適したLoRAアダプタを生成することも可能です。
方法: 論文著者は既存の専門特化エンコーダ(画像用CLIP、音声用CLAP、動画用VideoCLIP-XLなど)を使い、大規模言語モデル(Llama 3.1 8B)に接続するために、プロジェクタ(単純なニューラルネットワーク)とLoRAジェネレータ(単一注意層のネットワーク)を訓練しました。
- プロジェクタは、テキストと画像、音声、動画を対にしたデータセット(約5万~60万例)で訓練。プロジェクタ接続後、LLMは固定し、LLM出力と正解テキストの差を最小化。
- プロジェクタを固定し、LoRAジェネレータを訓練。128例ずつの異なるデータ種/領域のテキスト対画像、音声、動画の例を用いる。128例の部分集合に数学的変換を施し、ベクトル間の距離や角度などの幾何学的関係を保持しつつ多様なデータを模擬。
- 推論時、著者らは訓練していないデータ種/領域の埋め込みに別の既存エンコーダ(例:分子グラフ用MolCA)を使用。数例のそのデータ種/領域とテキストのペアからLoRAジェネレータが適切なアダプタを生成。
- さらに性能向上のためアダプタ適用後、同じ例でプロジェクタを微調整し他の重みは固定。
結果: 論文著者はSEMIを、初めからプロジェクタを訓練、プロジェクタ単独の微調整、専用LoRAアダプタ併用微調整と比較。使用したデータには天文画像(自前データ)、衛星画像、IMUセンサデータ、分子構造グラフや対応する既存エンコーダを用いました。性能指標には生成文が人手作成文とどれほど一致するかを示すCIDEr(高いほど良い)を含みます。
- 全てのテストで例数(32から最大2,500~26,000まで)に関わらずSEMIは全ベースラインを上回りました。
- 例として、天文画像32例ではSEMIが215以上のCIDErを達成し、次善手法は105でした。
- 例外は分子構造グラフで数千例時、プロジェクタ微調整がSEMIを上回りました。
重要性: 大規模言語モデルはテキスト付きデータが少ない多くの専門分野では限定的な利用にとどまっていますが、大規模テキスト付きデータが豊富な領域の知識を使い、データが乏しい領域でのAI訓練を加速できる可能性があります。
考察: AIモデルが新しいデータ種に一般化するには、多様かつ高品質なデータで学習することが必要です。効率的に少量データから多くの学習成果を引き出すことが有益です。