親愛なる皆様、
私は先ほど、AI Dev x NYCから戻ってきました。このAIデベロッパーカンファレンスは、私たちのコミュニティが一日中コーディングし、学び、交流するために集まる場です。会場の空気は活気に満ちていました!実は、前回のサンフランシスコのAI Devでキルスティ・タンと出会い、彼女とAIアドバイザリーのAI Aspire設立に向けて協力を始めました。対面での出会いは新たな機会を生み出すことがあり、これからの数ヶ月がAI Dev x NYCで始まった話でさらに賑わうことを願っています!
イベントではAIを用いたコーディング、エージェントAI、コンテキストエンジニアリング、ガバナンス、そしてスタートアップや大企業でのAIアプリケーション構築とスケールに関する多くの会話が交わされました。しかし私が最も強く抱いた印象は、より大きな世界における楽観主義と悲観主義の混在にも関わらず、この分野におけるほぼ普遍的な楽観主義でした。
例えば、多くの企業はまだAIエージェントから顕著なROI(投資収益率)を得ておらず、一部のAI懐疑派はMITの研究ではAIパイロットの95%が失敗していると主張しています。(ちなみにこの研究には方法論的な欠陥があり、この見出しは誤解を招きやすいものです)。しかしAI Devには成功し急速に成長しているAIアプリケーション群を担う多くのチームが出席していました。同業者と話す中で、(a)多くの企業がまだAIにより大きなROIを得ていない一方で、(b)熟練したAIチームがすでに顕著なROIを出し成功例が急速に増えているという両面が共存していることに気付きました。これがAI開発者達がこれからの成長に強い期待を持つ理由です!
複数の出展者は、真の開発者と話せるために、これが長い間参加した中で最高のカンファレンスだと語りました。ある出展者は、多くの他のカンファレンスが表面的なものに見える中、AI Dev参加者は技術理解が深く、最先端技術のニュアンスを理解し興味を持っていると述べました。エージェント型ワークフローの可観測性の議論、AIコーディングのコンテキストエンジニアリングの微妙な違い、RL(強化学習)ジムの普及がどの程度続くかの議論など、会場には深い技術専門性があり、それにより私たちは共に未来をより遠く見ることができます。

私にとって特別な瞬間の一つは、ニック・トンプソンがミリアム・ヴォーゲルさんとのパネルディスカッションでガバナンスについて尋ねた時でした。私はアメリカ合衆国が最近移民に対して取っている敵対的な言論を最悪の動きと答え、多くの聴衆から拍手が起きました。ニックはこの瞬間について動画で語っています。
私はAI Devで多くの方にお会いできて楽しく感謝しています。来場いただいた方々、スピーカー、出展者、スポンサー、ボランティア、イベントスタッフの皆様に心から感謝します。唯一の心残りは、サンフランシスコの前回イベントの3倍の規模に拡大したにも関わらず、会場の収容人数の制限によりチケット数を制限せざるを得なかったことです。
現在ほとんどの仕事がオンラインになっているにも関わらず、対面イベントは特別であり、個人やプロジェクトにとって転機になり得ます。次回のサンフランシスコでのAI Devを2026年4月28日から29日にさらに大規模なイベントとして開催予定であり、将来さらなる共有とつながりの促進を期待しています。
これからも創り続けてください!
アンドリュー
DEEPLEARNING.AIからのメッセージ

Semantic Caching for AI Agentsでは、Redisとの連携により、異なるクエリが同じ意味を持つ場合を認識して、AIエージェントをより高速かつコスト効率よく動作させる方法を学びます。精度を最適化し、エージェントにキャッシュ機能を統合しましょう。今すぐ登録!
ニュース

米国高速道路における自動運転車
Waymoは、米国の高速道路で完全自律・無人のタクシーサービスを提供する初の企業となりました。
新しい点:Waymoの車両はカリフォルニア州のサンフランシスコ、ロサンゼルス、アリゾナ州フェニックスの高速道路で有料顧客にサービスを提供しています。サービスはWaymoアプリの「高速道路」オプションを選択し、かつアプリが高速道路利用でかなり速い移動が可能と判断した場合に利用可能です。
仕組み:サンフランシスコ湾エリアで数千台の車両を運用しているWaymoは、その地域で最も詳細に高速道路サービスを提供しています。サンフランシスコとサンノゼを取り囲む約260平方マイルの高速道路を走行し、乗車時間を最大50%短縮しています。
- 無人車両は1年以上にわたり従業員や記者、ゲストを高速道路上で輸送してきました。
- 数百万マイルにわたる公道、閉鎖コース、シミュレーション走行で交通操作、システム障害、事故、高速道路と一般道路の移行などの例を収集し、冗長な合成シナリオや様々なトレーニング例を作成しています。
- また、自律高速道路運転の心理的影響も重視しており、Waymoの共同CEOテケドラ・マワカナは、高速(時速65マイル)での運転は手動運転よりも乗客の不安を招きやすいと述べています。
- 州警察と協働して自律高速道路運転向けのプロトコルを開発しています。
- カリフォルニア公共ユーティリティ委員会は2024年3月、Waymoの高速道路走行を承認し、都市部での運用拡大や時間帯問わずの走行を計画しています。
背景:Waymoは2000年代半ばにスタンフォードレーシングチームがDARPAグランドチャレンジと都市チャレンジ向けに開発した車両に起源を持ちます。Googleが2009年にプロジェクトを引き継ぎ、2016年末にWaymoとして独立しました。
- 現在アトランタ、オースティン、ロサンゼルス、フェニックス、サンフランシスコで運用中で、ダラス、デンバー、デトロイト、ラスベガス、マイアミ、ナッシュビル、サンディエゴ、シアトルに拡大予定。またロンドンや東京も計画に含まれています。
- 2025年9月にはサンフランシスコでWaymo車両がペットの猫を死なせる事故を起こしましたが、同社は同地域の人間運転と比較して重傷事故は91%、歩行者事故は92%少ないと主張しています。
- 2024年・2025年には米国運輸省道路交通安全局がWaymoを交通法規違反の疑いで調査しました。
重要性:高速道路での運行は自動運転車の人間運転車両代替に必須です。Waymoの完全自動走行は、街中の運転から高速道路走行へのスムーズな切り替え、高速かつ不確実な環境での先読みと迅速反応が求められ技術的にも大きな進歩です。政府の高速道路走行承認は規制面・社会面の両面で大きな達成であり、安全性と信頼に対する懸念を払拭したことになります。Waymoの積極的拡大計画は今後もマイルストーンの連続を期待させます。
私たちの考え:アンドリューはDARPA都市チャレンジ当時のTシャツを今も持っています。あの頃の楽観主義と、着実に路上対応可能な自動運転車が開発されるまでに予想よりずっと時間がかかったことを思い出します。WaymoのロボタクシーとテスラのFull Self-Driving(監督付き)能力により、この技術が一般的になるかどうかではなく、いつになるかが問われています。
トップエージェント結果、オープンウェイト
Moonshot AIの最新のオープンウェイト大規模言語モデルは、数百のツール呼び出しを順次実行し、それぞれの間に考慮の時間を入れることで、最先端の独自LLMにおけるエージェント課題に挑戦しています。
新情報:Kimi K2 Thinkingと高速バージョンのKimi K2 Thinking Turboは、Moonshotの以前のLLM Kimi K2の1兆パラメータを持つ推論特化モデルです。4ビット(INT4)精度でファインチューニングされており、同規模の他のLLMより低コスト・低価格のハードウェアで稼働可能です。
- 入出力:テキスト入力(最大256,000トークン)、テキスト出力(サイズ制限非公開、Kimi K2 Thinkingは14トークン/秒、Turboは86トークン/秒)
- アーキテクチャ:エキスパート混合型トランスフォーマー、総パラメータ数は1兆、トークンあたり3,200億パラメータが活性化
- 性能:τ²-Bench Telecomエージェント課題でトップの閉じたLLMを凌駕し、他のオープンLLMを一般的に上回る
- 利用可能性:無料のウェブUI(制限付きのツールアクセス)、重みは非商用および月間1億アクティブユーザーまたは収益2,000万ドルまで商用利用可能な修正版MITライセンス下にて公開
- API:Kimi K2 Thinking(入力/キャッシュ/出力トークンあたり60セント/15セント/2.5ドル)、Turbo(1.15ドル/15セント/8ドル)をMoonshot AIなどから提供
- 特徴:検索、コードインタプリタ、ウェブ閲覧、「重い」推論モードなどのツール利用
- 非公開:トレーニング手法とデータセット、出力サイズの制限
仕組み:すべての推論を一気に終えてから行動するのではなく、Kimi K2 Thinkingは推論とツール利用のサイクルを繰り返します。これにより、中間結果やツール呼び出しの結果に応じて柔軟に調整できます。
- プロンプトを受け取ると、推論ツール呼び出し(最大300回)計画を織り交ぜて順に実行。まず課題について推論しツールを呼び出し、結果を解釈し次のステップを計画、これを繰り返します。これにより多段階課題での成果が向上。例えば複雑な確率問題を23回の推論とツール呼び出しで正しく解決。
- 「重い」モードでは8つの独立した推論経路を同時実行し出力を統合。高精度な問題解決を行い計算コストは8倍。
- INT4精度でのファインチューニング(16ビットや32ビットより4ビットでエンコード)により、速度が倍増しモデルサイズも1テラバイトから594ギガバイトに圧縮。量子化対応学習(QAT)により低精度計算をシミュレートしつつ精度の高い量子化を実現。
- CNBCによれば、Kimi K2 Thinkingのトレーニング費用は460万ドルで、DeepSeek-V3の推定トレーニングコストより100万ドル安い。
結果:Kimi K2 Thinkingは複数のベンチマークでオープンウェイトLLMをリードし、いくつかのエージェント課題で最先端の成果を上げています。ただし、ほとんどの競合よりかなり多くのトークンを生成して同等性能を達成しています。
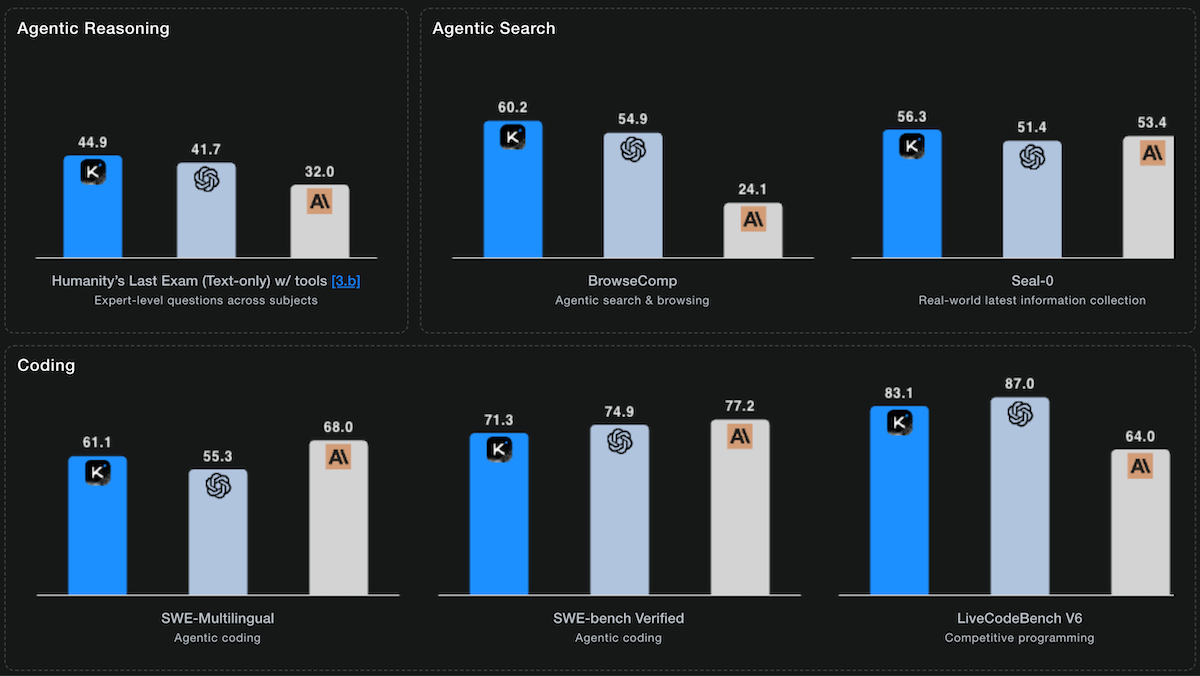
- Artificial AnalysisのAgentic Index(複数段階の問題解決能力をツール活用で評価)で67点の3位。トップのGPT-5高推論モード(68点)とGPT-5 Codex高推論モード(68点)に僅かに及ばず。
- τ²-Bench Telecom(エージェントツール活用試験)では93%の精度で独立測定で最高得点。近接のGPT-5 Codex(87%)、MiniMax-M2(87%)を6ポイント上回る。
- Humanity's Last Exam(多分野の大学院レベル推論試験)ではツールなしで22.3%と他のオープンウェイトLLMを上回るが、GPT-5高推論(26.5%)、Grok 4(23.9%)には届かず。ツール利用時にはMoonshot発表で44.9%を達成し、GPT-5高推論(41.7%)、Anthropic Claude Sonnet 4.5 Thinking(32.0%)を上回る最先端結果。
- コーディングベンチマークではTerminal-Bench Hard、SciCode、LiveCodeBenchでオープンウェイトLLM中トップか同率トップ。ソフトウェアエンジニアリング試験SWE-bench Verifiedでは71.3%でClaude Sonnet 4.5 Thinking(77.2%)、GPT-5高推論(74.9%)に及ばず。
ただし:Kimi K2 ThinkingはArtificial AnalysisのIntelligence Index評価に1億4,000万トークンを使用し、他のテスト済みLLMより非常に多い。DeepSeek-V3.2 Expは6,200万トークン、GPT-5 Codex高推論は7,700万トークン。Intelligence Index試験のコストはKimi K2 Thinkingで356ドル、GPT-5高推論で913ドルの約2.5分の1、DeepSeek-V3.2 Expでは41ドルの約9倍。
背景:7月にMoonshotはエージェント課題のために最適化された非推論版Kimi K2の重みを公開しました。
重要性:エージェントアプリケーションは人間の介入なしに多数のツール呼び出しを跨いで推論できる能力で利益を得ます。Kimi K2 Thinkingは研究、コーディング、ウェブナビゲーションなど多段階課題向けに設計。INT4精度によりより安価で入手しやすいチップでの高速運用を実現、中でも中国のように最先端ハードウェアへのアクセスが制限されている地域では大きな強み。
私たちの考え:LLMは考えるべきタイミングとツールを取るべきタイミング、互いに影響させるタイミングをより賢く判断しています。初期報告によるとKimi K2 Thinkingの計画と反応能力は科学からウェブ閲覧、創作までの応用に有効であり、推論モデルは非推論モデルに比べて創作が苦手という課題を克服しつつあります。
Anthropicのサイバー攻撃報告が論争を巻き起こす
独立したサイバーセキュリティ研究者たちは、Anthropicが自社のClaude Codeエージェント型コーディングシステムを使った未曾有の自動化サイバー攻撃を実行したと主張した報告に反論しています。
新情報:Anthropicはブログ記事で、政府支援の中国ハッカーによる9月のキャンペーンを阻止したと説明し、「実質的な人間の介入なしでの大規模なサイバー攻撃の初の記録例」と称しました。しかし、独立研究者らは現行エージェントの現状能力ではそんな悪質な攻撃は実行できないとし、Ars Technicaは報じています。また成功率(数十回に数回の成功)もAnthropicの危機的能力を示す主張とは異なります。詳細な情報不足で、同社の主張の評価が困難です。
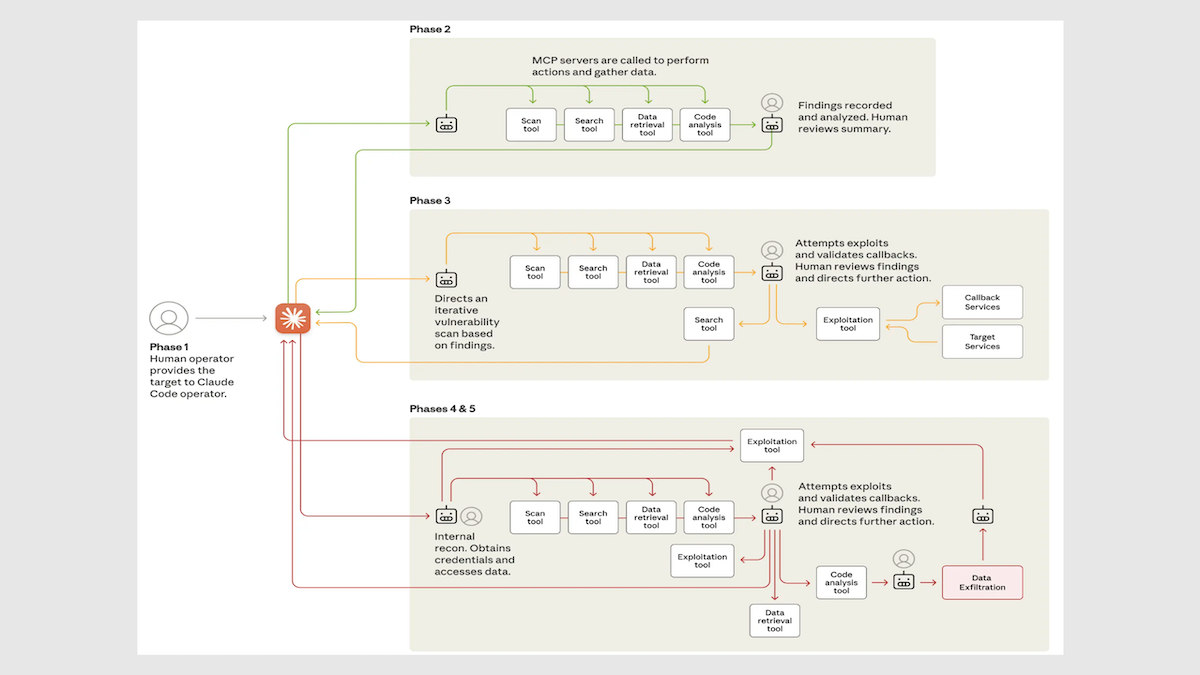
Claudeの悪用:ハッカーはAnthropicの報告書によれば、セキュリティ企業の社員に成りすましてネットワークテスト員を装い、Claude Codeのガードレールを回避しました。
- 小さな段階でネットワークを調査し侵入して情報を抽出し、基盤モデルが悪意のある行動だと認識しにくい行動を取らせました。それを通常のハックを超える速度で実行しました。
- 技術的手順の80~90%をエージェントAIが実施し、「続行する」「続けない」「それは問題かもしれない、Claude、本当に?」等のコマンドを人間が入力しました。The Wall Street Journalが報じています。
- 30以上の組織を標的にし、複数から機密情報を盗みました。
- 報告書は攻撃対象組織の特定、攻撃検知方法、攻撃者の中国との関連の説明をしていません。中国外務省スポークスマンは中国はハッキングを支持しないと語っています。
懐疑の理由:独立研究者たちはArs Technica、The Guardianなどで、多層的にこの報告を疑問視しています。
- AIはログ解析やリバースエンジニアリングの加速には役立つが、多段階のサイバー攻撃を人間の入力なしに自動化できる段階には至っておらず、過去数十年利用されてきた既存のハッキングツールと大きく違わない。Kevin Beaumont研究者はオンラインフォーラムで「脅威役は新しいものを発明しているわけではない」と述べています。
- ハッカーはClaude Code以外に一般的なオープンソースツールも利用しましたが、これらに対する防御は既知であり、Claude Codeが変えた部分は不明。
- Anthropic自身もClaude Codeは「発見を過大評価し」「時折データを捏造」する傾向があると指摘しており、この誤動作はサイバー攻撃の実行にとって大きな障壁です。
背景:ハッカーは効果的なフィッシングメール作成や悪意あるコード生成などでAIを日常的に活用しています。Anthropicは8月に技術力が低い悪質者がAIを使って行う「バイブハッキング」の増加を指摘し、その内の一件を阻止したと発表しました。10月にはホワイトハウスAI責任者デイビッド・サックスがAnthropicを「恐怖を煽る精巧な規制取り込み戦略」と非難しました。
重要性:AIがハッキングを高速かつ効果的にする可能性は否定できませんが、Anthropicの報告は外部のセキュリティ研究者の知見とは相反しています。独立研究者はエージェントによるサイバー攻撃自動化はまだ効果的でないとし、従来手法の方が危険だとしています。セキュリティ研究者は攻撃側・防御側双方でエージェントAIの可能性を探求していますが、Anthropicが警告するほどの重大な脅威はまだ確認されていません。
私たちの考え:AI企業は自社製品の力を強調したがるため、時に矛盾的にネガティブな結果への影響力を前面に出すことがあります。肯定的・否定的いずれにせよ過剰な宣伝は有害です。最先端モデルやそれに基づくアプリケーションの制作者が公衆を誤認させずに、彼らの実績(多くは本当に素晴らしく興味深い!)への関心を高める方法を見つけてくれることを望みます。サイバーセキュリティにおいてはAIを用いた脆弱性検出が容易にパッチ適用を可能にし、AIは攻撃者から防御者への力の均衡を移し、コンピュータをより安全にする方向へ寄与しています。
より効率的なエージェント検索
大規模言語モデルは与えられたプロンプトに関連する知識を学習している可能性がありますが、常に一貫して想起できるわけではありません。モデルをウェブ検索するように自身のパラメータ内を検索するようファインチューニングすることで、自分の重みから知識を見つけやすくなります。
新情報:清華大学、上海交通大学、上海AI研究所、ユニバーシティ・カレッジ・ロンドン、中国建設第三局、WeChat AIのファン・ユーチェンらはSelf-Search Reinforcement Learning(SSRL)を提案しました。SSRLは大規模言語モデル(LLM)に、クエリ生成から回答までの検索プロセスをシミュレートさせる強化学習手法で、ウェブ検索ツールの有無にかかわらず性能向上を促します。
核心的知見:著者らは、LLMは1,000回の回答のうち正答が含まれる可能性が、少数回答の場合よりも高いことを発見しました。これはLLMが必ずしも自身の知識を常に応答に反映していないことを示しています。シミュレート検索、すなわちウェブ検索のようにクエリ生成と応答生成を強化学習でファインチューニングすることにより、重みからの情報取得能力を改善できます。
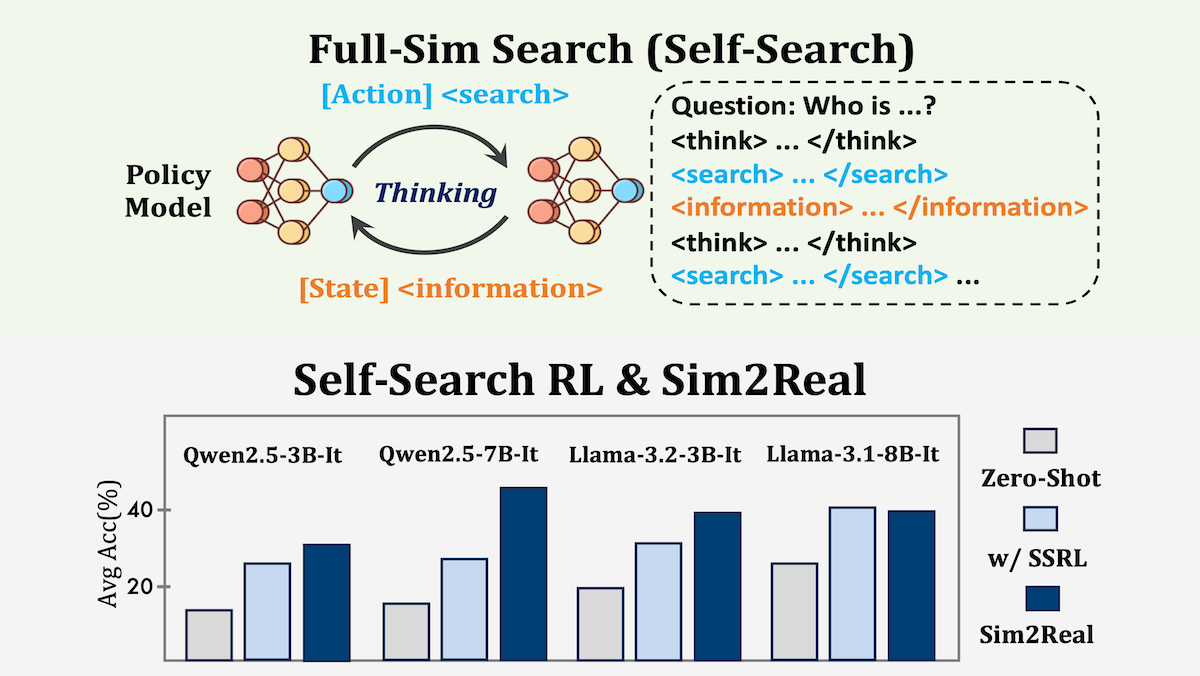
仕組み:著者らは強化学習アルゴリズムGroup Relative Policy Optimization(GRPO)でLlama-3.1-8B、Qwen2.5-7Bなどに自然質問応答(Natural Questions)、HotpotQA)の問に対して推論と検索のシミュレーションを繰り返す動作列を学習させました。
- モデルは<think>、<search>、<information>(自己生成検索応答)、<answer>のタグで記述された特定フォーマットに沿ってテキストを生成。
- 正答の生成とフォーマット遵守を報酬。
- <information>タグ内のトークンは損失計算無視。これによりクエリや推論過程に注力し、誤情報の丸暗記を防止。
結果:6つのQAベンチマークでSSRLを評価し、外部検索エンジン使用法よりも良好な結果を示しました。SSRLで学んだ能力は検索エンジン搭載時にも性能向上をもたらしました。
- ベンチマーク全体で、SSRL学習済みのLlama-3.1-8Bは平均43.1%で正答に完全一致。トレーニング中にQwen-2.5-14B-Instructで回答を得てテスト時にGoogleを使うZeroSearchは41.5%、Google検索利用をトレーニングしたSearch-R1は40.4%。
- SSRL学習済み4モデル中3モデルは、自己生成応答に比べGoogle検索利用時に性能向上。例としてQwen2.5-7BはSSRLのみで30.2%、SSRLとGoogle検索併用で46.8%に改善。
重要性:LLMベースAIエージェントはシミュレーションで学習した行動を現実環境で再現する際のギャップが課題となります。この研究は、ウェブ検索を模倣して学んだLLMが実際の検索でも効果的に機能することを示しています。知識ベースのタスクにおいて、LLMのパラメータ自身が安価かつ高精度のシミュレーターとして機能することの証明です。
私たちの考え:エージェントはウェブ検索が必要なタイミングをより賢く判断できるようになるでしょう。本研究は、まず内部知識を参照し、不足が検出された場合のみ外部検索を使うハイブリッドアプローチの可能性を示唆しています。