Usage-based pricing killing your vibe - here's how to roll your own local AI coding agents
あのトークン上限を、ローカルLLMで“バイブ感”コーディングするやり方
モデル開発者たちが、より攻めたレート制限を課したり、価格を引き上げたり、あるいはサブスクリプションをやめて従量課金制に切り替えたりしているせいで、バイブ感で書く趣味プロジェクトは、これから一気にもっと高くつくことになりそうです。とはいえ、あなたにコスト削減の選択肢がないわけではありません。
ここ数週間で私たちは、Anthropicが最安のプランからClaude Codeを< /a>いわゆる「引き(dropping)」のように切り捨てる様子を目にしてきました。またMicrosoftは様子見をせずに、GitHub Copilotを完全に従量課金モデルへ移行しました。この一連のゴタゴタを見て、私たちは考えさせられました。そもそもAnthropicやOpenAIの最上位モデルを使う必要があるのか。それとも、小さめのローカルモデルで済ませられるのでしょうか。もちろん、遅くなるかもしれません。能力も下がるかもしれませんし、使い勝手が少しイラつく程度にはなるかもしれません。しかし、無料の価格には勝てません……まあ、すでにそのためのハードウェアが手元にある場合ですが。
たまたま最近、AlibabaがQwen3.6-27Bを投下しました。クラウドとEC大手は、この「旗艦級のコーディング強さ」を、32GBのMシリーズMacまたは24GB GPUで動かせるほど小さなパッケージに詰め込んだと自慢しています。
何が変わったのか
私たちがローカルのコードアシスタントを検討するのは初めてではありません。以前、コード補完や生成といった作業にはContinueのVS Code拡張を使うことを調べました。
その時点では、モデルとソフトウェアのスタックがまだかなり未成熟で、役に立つツールではありましたが、必ずしもより大きなフロンティアモデルに対抗できるほどではありませんでした。しかしそれ以来、モデルのアーキテクチャやエージェントの仕組みは劇的に改善しています。
「推論(Reasoning)」機能により、小型モデルでも「より長く考える」ことでそのサイズ不足を補えます。モixture-of-experts(MoE)モデルなら、インタラクティブな体験のために秒あたりテラバイト級のメモリ帯域を用意する必要がありません。そして、関数やツール呼び出しの機能が大幅に改善されたことで、これらのモデルは実際にコードベース、シェル環境、そしてWebとやり取りできるようになります。
雰囲気は全部、レート制限はなし
このハンズオンでは、Qwen3.6-27Bのようなローカルモデルを、コンピュータ上でコーディングするためにデプロイおよび設定する方法を見ていきます。そして、それらと一緒に使えるいくつかのエージェントフレームワークも探っていきます。
必要なもの:
- 中規模のLLMを動かせるマシンです。24GB以上のVRAMを搭載したNvidia、AMD、またはIntelのGPUを推奨します。メモリが少し足りない場合は、システムメモリとGPUメモリをプールする方法についても説明します。新しめのMx-MaxシリーズのMacを使っている人は、少なくとも32GBのユニファイドメモリを推奨します。
- このガイドではLlama.cppを使ってモデルを実行しますが、LM Studio、Ollama、またはMLXを使いたい場合でも、セットアップ手順は同様です。システムにLlama.cppをインストールするための手助けが必要なら、包括的なセットアップガイドはこちらで確認できます。
注: 古いMシリーズのMacは、エージェント的なコーディングに必要な大きなコンテキスト長に苦労する可能性があります。Appleのハードウェアアクセラレータをより活用できる推論エンジンとしてoMLXの方がうまくいくかもしれませんが、結果は環境によって異なります。
モデルを起動する
ローカルでLLMを動かすのは、今では信じられないほど簡単な手順です。お気に入りの推論エンジンをインストールします。モデルをダウンロードし、API経由でアプリと接続します。
ただし、特にコードアシスタントの場合はいくつかのパラメータを調整する必要があります。そうしないと、モデルがゴミのような出力や壊れたコードを量産しがちです。アプリケーションによっては、モデルが適切に動作するために特定のハイパーパラメータが必要なことがありますが、Qwen3.6-27Bも例外ではありません。
Qwen3.6-27Bで「雰囲気コーディング(vibe coding)」を行う場合、Alibabaは次のパラメータ設定を推奨しています:
- temperature=0.6
- top_p=0.95
- top_k=20
- min_p=0.0
- presence_penalty=0.0
- repetition_penalty=1.0
さらに、メモリに収まる範囲でできるだけ大きいモデルのコンテキストウィンドウを設定する必要があります。
もしよく知らない場合、モデルのコンテキストウィンドウは、あるリクエストに対してモデルが追跡できるトークン数を定義します。
数千行のコードを含む大規模なコードベースで作業すると、これはすぐに膨らんでしまいます。しかも、多くのエージェントフレームワークで使われるシステムプロンプトもかなり大きくなりがちなので、コンテキストウィンドウは可能な限り高く設定したいところです。
Qwen3.6-27Bは262,144トークンのコンテキストウィンドウに対応していますが、ハイエンドのMacかワークステーションGPUでもない限り、少なくとも16-bitの精度では、その全部を活用するだけのメモリがない可能性が高いです。
朗報なのは、モデルの状態を追跡するキー・バリューキャッシュを16ビットで保存する必要がないことです。多少のパフォーマンス低下や品質劣化を許容すれば、より低い精度で済ませられます。コンテキストウィンドウを最大化するために、キーとバリューのペアを8ビットに圧縮します。
最後に、prefix cachingをオンにしておく必要があります。システムプロンプトやコードベースのように、プロンプトの大きな部分が何度も再処理されるワークロードでは、新しいトークンだけが処理されるようにすることで推論を高速化できます。Llama.cppの新しいビルドではデフォルトで有効になっているはずですが、念のためそのフラグを明示します。
以上の準備ができたら、以下に示すのは24GBのNvidia RTX 3090 TI向けにこちらが使っている起動コマンドですが、AMDまたはIntelのGPUを使っている場合、あるいはMac上でLlama.cppを動かしている場合でも、同じコードのコマンドが問題なく動くはずです。メモリがより多いマシンで実行しているなら、コンテキストウィンドウを131,072または262,144に増やしてみてください。
llama-server \ --hf-repo unsloth/Qwen3.6-27B-GGUF:Q4_K_M \ --ctx-size 65536 \ -ngl 999 \ --flash-attn on \ --cache-prompt \ --cache-type-k q8_0 \ --cache-type-v q8_0 \ --temp 0.6 \ --top-p 0.95 \ --top-k 20 \ --min-p 0.0 \ --presence-penalty 0.0 \ --repeat-penalty 1.0 \ --port 8080
Llama.cppを動かし、それを別のマシンからアクセスする予定があるなら、コマンドに--host 0.0.0.0も追加したくなるはずです。これによりローカルエリアネットワークに公開されます。Llama.cppがVPC内で動作している場合は、このフラグを渡す前にセキュリティのためにファイアウォールのルールを設定しておきましょう。
エージェントフレームワークを選ぶ
これでモデルが動き始めたので、これをエージェント的なコーディング用のハーネスに接続する必要があります。モデル単体でもコードは生成できますが、アクティブな開発環境がないと、その実装・テスト・デバッグを行う方法がありません。vibe codingが他のAIの取り組みで苦戦してきた領域から一歩抜け出せた一因は、コードが検証可能だからです。実行できるか、コンパイルできるか、できないかのどれかです。
シンプルにするため、人気の3つの選択肢としてClaude Code、Pi Coding Agent、Clineを見ていきます。
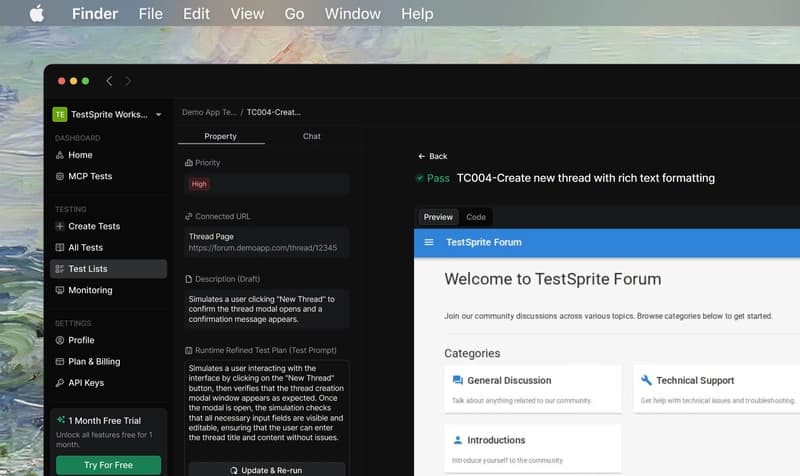
あなたが思う通り、Claude CodeはAnthropicのモデルと一緒に使う必要は実際にはありません(拡大するにはクリック)
まずはClaude Codeから始めます。あなたが思う通り、AnthropicのモデルであってもClaude Codeを使う必要はありません。このフレームワークはローカルモデルでも問題なく動作します。もちろん、それらを動かすのに十分なリソースがあることが前提です。
Claude Codeは通常どおりインストールしてください。Anthropicのワンライナーはこちらです。
次に、Claude Codeに対して、ClaudeアカウントやAnthropicのAPIサービスではなく、自分のマシン上で動いているローカルのモデルを使いたいことを伝える必要があります。これは、Claude Codeを起動する前にいくつかのシェル変数を設定することで行います。
export ANTHROPIC_BASE_URL="http://localhost:8001" export ANTHROPIC_API_KEY='none' claude
これらは、新しいセッションでClaudeを起動するたびに実行する必要があります。
これでClaudeを起動すると、ローカルモデルに直接接続します。Claude Code自体は、通常どおりの形で動作し続けます。
Pi Coding Agent
たとえば、ローカルの自分用モデルを使いたいだけでなく、オープンソースの実行基盤(ハーネス)も使いたいとします。Claude Code が気に入っているなら、きっと Pi Coding Agent も気に入るはずです。そして Claude Code と同じように、これを使う際にどのモデルを使うかにはこだわりがありません。
Pi Coding Agent の主な魅力の1つは、その軽量さです。長い入力シーケンスは、低スペックの古いGPUやアクセラレータにとって非常に負担になります。Claude Code と Cline には、能力の低いハードウェアでも動作が進むようにするシステムプロンプトがあります。これに対して Pi Coding Agent のデフォルトのシステムプロンプトは短く、特にプロンプトキャッシュが有効になっていれば、テンポよく進められます。
ただし、そのスピードは、他のコーディングエージェントで見かけるガードレールや安全機能の多くを犠牲にして得られています。これは、おそらく仮想マシンやコンテナ、さらには Raspberry Pi 上で動かしたくなるタイプのものです。
Claude と同様に、Pi Coding Agent も、お使いのシステムに適した ワンライナー でインストールできます。その後は、エージェントのハーネスがあなたのモデルの場所を見つけられるようにする少しの JSON を用意するだけです。
ここまで追ってきたなら、セットアップはかなり簡単です。お気に入りのテキストエディタを使って、次のファイルを作成してください:
Windows:
edit ~/.pi/agent/models.json
Linux / Mac:
nano ~/.pi/agent/models.json
次に、以下のテンプレートを貼り付けます。API キーを設定している場合は、no_API_key_required をあなたのキーに置き換えてください。残りは、使用するモデルとポートによって変わります。また、Llama.cpp で設定した内容に合わせて contextWindowSize を調整することも忘れないでください。
"providers": {
"llama.cpp": {
"baseUrl": "http://localhost:8080/v1",
"api": "openai-completions",
"apiKey": "none",
"models": [
{ "id": "unsloth/Qwen3.6-27B-GGUF:Q4_K_M" }
]
}
}
}
あとは作業ディレクトリへ移動して Pi Coding Agent を起動し、次の趣味プロジェクトを“ノリで”作り始められます。
pi --model unsloth/Qwen3.6-27B-GGUF:Q4_K_M
Cline
Claude Code は VS Code などの人気の統合開発環境(IDE)と直接統合されますが、そのルートを選ぶなら、もう1つのオープンソースアプリである Cline もぜひ確認することをおすすめします。
Cline のインストールは、VS Code の — または対応している IDE の — 拡張機能マネージャでそれを見つけて、ライブラリに追加するだけの簡単な手順です。
Cline は VS Code を含む多くの人気 IDE の拡張機能として利用できます - 拡大するにはクリック
次に、Cline を Llama.cpp サーバーに向け、temperature や context size などいくつかのハイパーパラメータを調整します:
- Base URL: http://localhost:8080/v1
- Model ID: unsloth/Qwen3.6-27B-GGUF:Q4_K_M
- Context Window Size: 65536(Llama.cpp で設定した値に応じて何でも)
- Temperature: 0.6
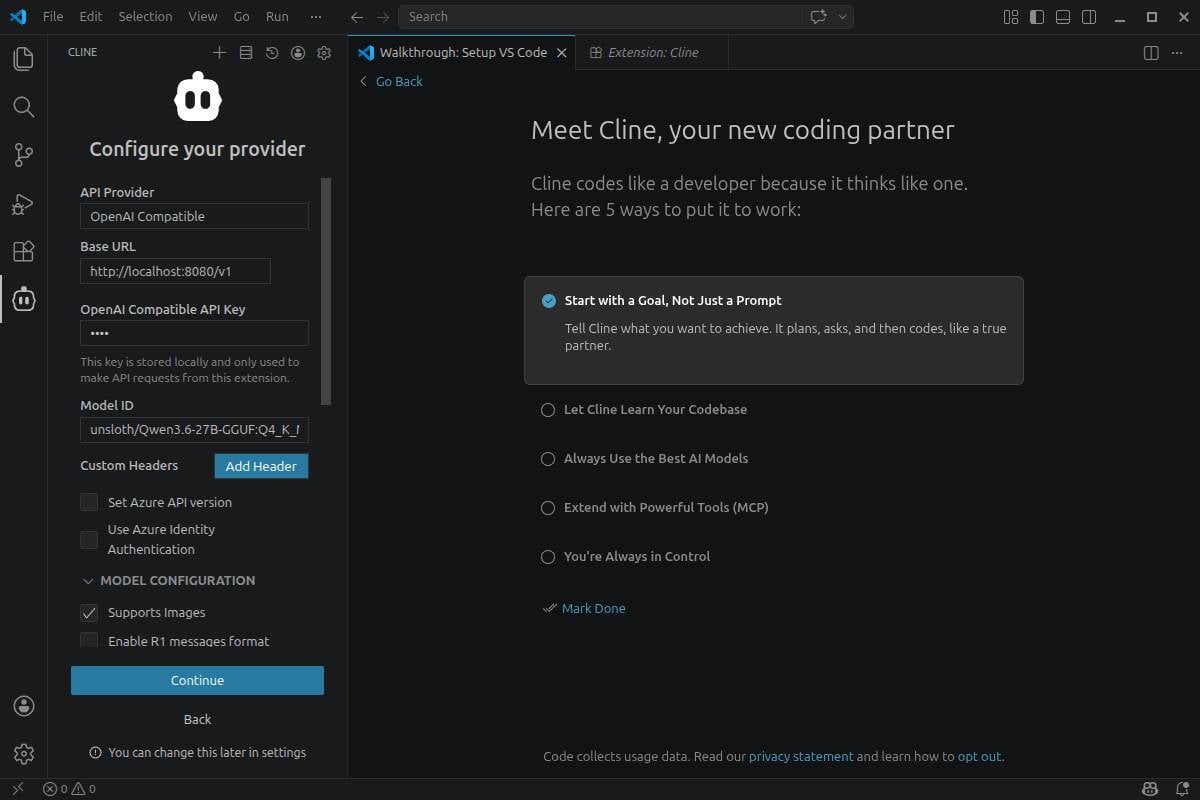
アプリをインストールしたら、やることは Cline を Llama.cpp サーバーに向けるだけです。 - 拡大するにはクリック
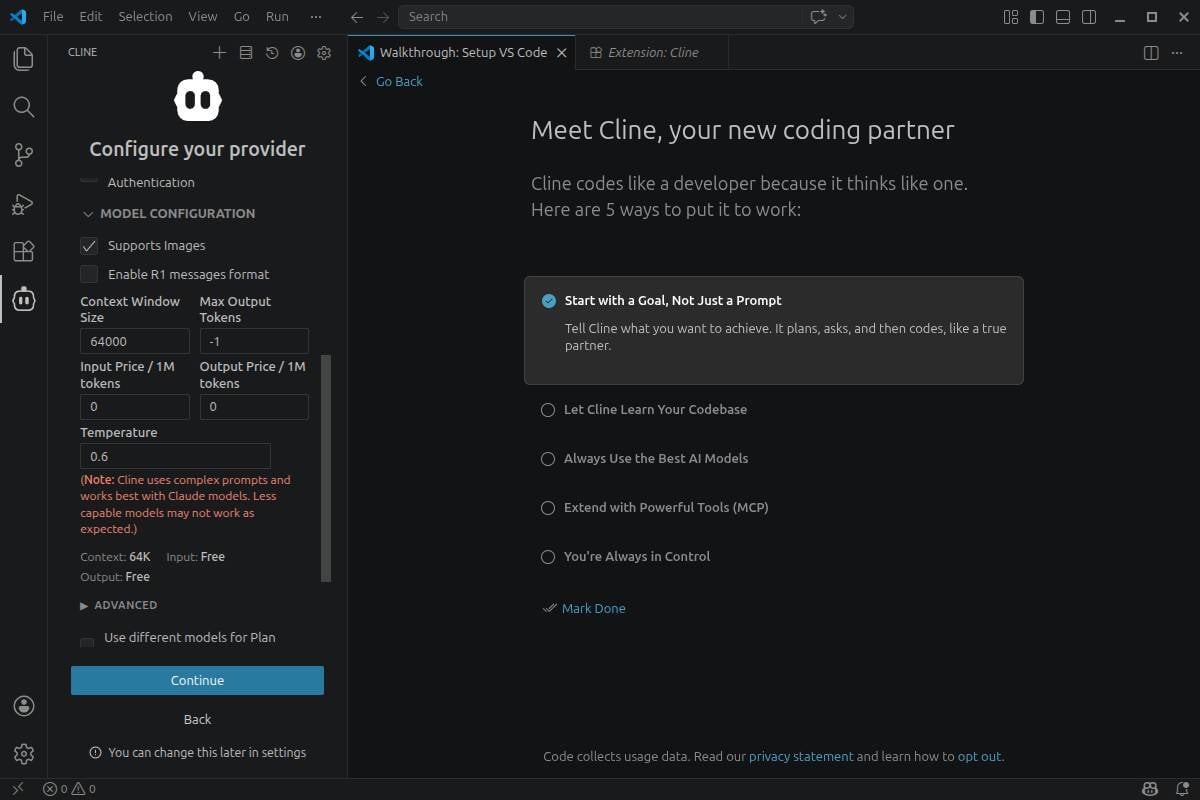
次に、最大コンテキストサイズとモデルの temperature を設定します。 - 拡大するにはクリック
設定が完了したら、チャットインターフェースを通じて Cline を操作できます。生成されるファイルや編集内容は、そのまま VS Code に表示されます。
Cline のより便利な機能の1つは、純粋な計画(プランニング)モードとアクション(実行)モードを切り替えられることです。Claude が、あなたが本当は課題をじっくり取り組みたいだけなのに質問を“実行依頼”として解釈してしまいイライラしたことがあるなら、これは大きな助けになります。
Cline とやり取りすると、変更内容が VS Code のエディターに表示されます。 - 拡大するにはクリック
ローカルモデルはついに十分良くなった?
では Qwen3.6-27B は Opus 4.7 や GPT-5.5 を置き換えられるのでしょうか? それは“まったく”ではありません。たぶん予想がつく通り、27B の LLM は、数兆パラメータ規模のフロンティアモデルの代わりになるわけではありません。
とはいえ、近年ローカルモデルでどこまで到達できるかには、驚くかもしれません。私たちのテストでは、Qwen3.6-27B は対話型のソーラーシステム(太陽系)ウェブアプリを簡単に最初の一発で動かし、既存のコードベースのバグを正確に特定して修正することもできました。
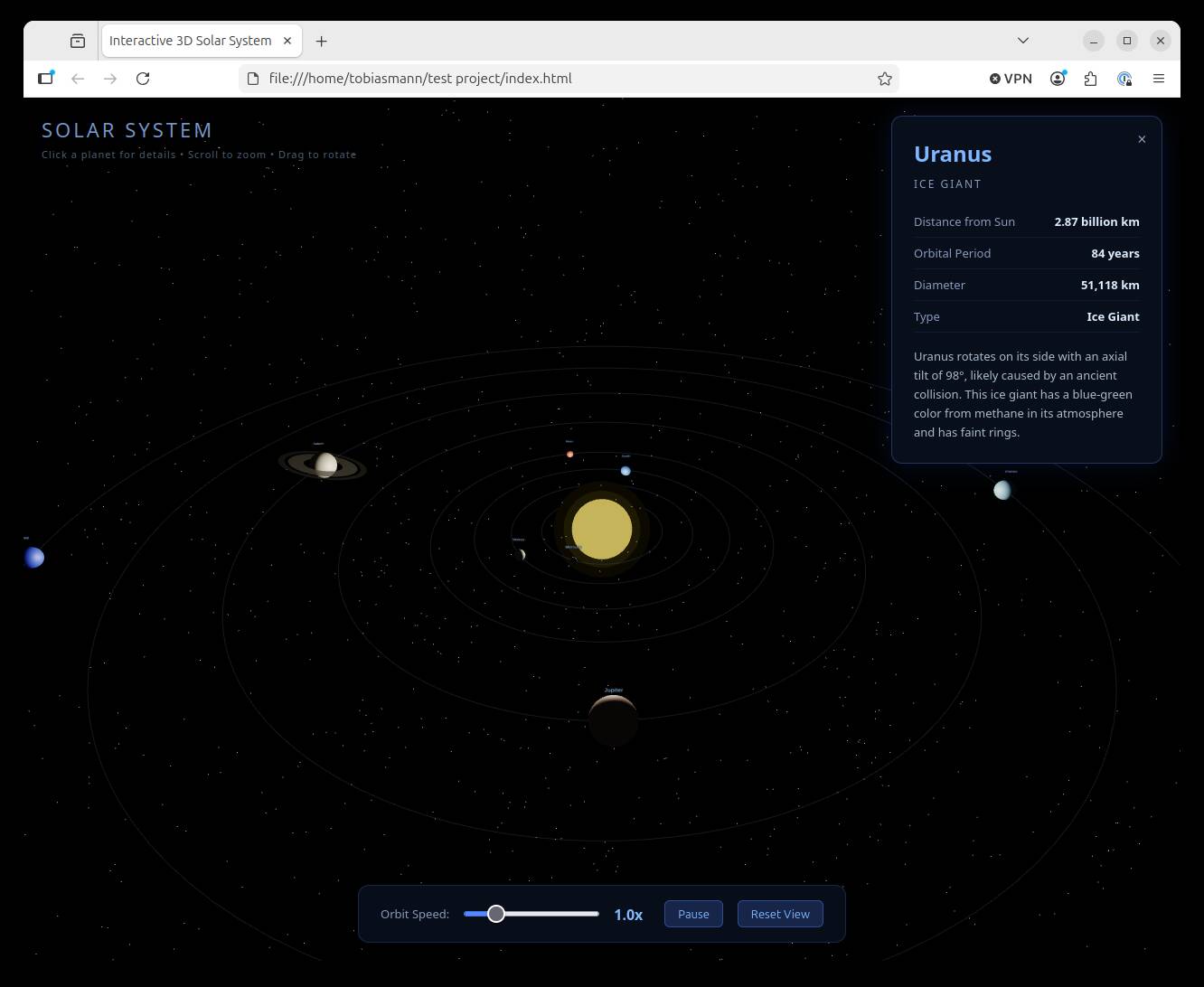
Cline を使うことで、Qwen3.6-27B は対話型のソーラーシステム(太陽系)ウェブアプリを最初の一発で動かせました。 - 拡大するにはクリック
正直に言えば、これらはいずれもかなり些細なプロジェクトです。モデルの性能がどの程度なのかをより正確に把握するために、私はこれを同業(?)の vulture である Thomas Claburn に渡し、Claude Code での最近の体験と比較してもらいました。
彼はこう書いています:
私は最近ようやくローカルモデルをいじり始めたところですが、Tobias の経験は自分の経験とかなり似ているように思えます。私は pi coding agent を、モデルサーバーとして OMLX を使って運用しています。トークンレートはかなり遅いものの、少なくとも小さなスクリプトについては、これまでのところ Qwen に満足しています。
たとえば、指定した幅に画像をリサイズする Python スクリプトを書かせたのですが、約5分ほどかかった後に(いくつかの手動承認のもとで)それを実行できました。
Qwen モデルの作業に対する Claude Code の評価は、思っていたよりもずっと前向きでした――「全体として: 強力で、本番品質のスクリプト」。
Claude はいくつか改善案も提案してくれましたが、どれも必須ではありませんでした。たとえば:
get_save_formatは、PNG 以外をすべて JPEG A .webp ファイルとして黙って扱います。ディレクトリ内のファイルはSUPPORTED_EXTENSIONSによってフィルタされますが、この集合が将来拡張されない限り、JPEG へのフォールスルーは黙ってしたミス動作になります。明示的な elif、またはルックアップ用の辞書の方が安全です。そのコードを生成するのに必要な時間を考えると、特定の、はっきりしたコード変更やスクリプト、そして最小限のWebプロジェクトにはローカルエージェントを使うのは分かる気がします。
より大規模なプロジェクトだと、修正が必要になる項目が多すぎるはずです。しかし、どの程度うまくいくかは、ローカルモデルで利用できるスキルやツールに大きく左右されます。ローカルモデルが現実的かどうかを判断する最善の方法は、まず試してみることです。あなたの用途に対しては機能するかもしれません。メモリを多く搭載したハードウェアを用意し、そしてデータのバックアップが取れていることを確認してください。
そもそも、これらのエージェントは安全なの?
OpenClaw という“セキュリティの悪夢”をめぐる大騒ぎのせいで、当然ながらこの疑問はもっともです。ありがたいことに、ここで取り上げてきたほとんどのフレームワークは、自律性の面ではかなり制限されています。デフォルトでは、Claude Code と Cline は、コード変更の承認とシェルコマンドの実行のために、人間が介在(ヒューマン・イン・ザ・ループ)していることに依存しています。
コマンドの集合をホワイトリスト化していない、あるいは、エージェントが何をしようとしているのかを理解する時間を取らずに、読む前にEnterキーを連打している、という状況でなければ、被害範囲(ブラス トレベル)は管理可能なはずです。ここで私たちが強調したいのは「すべき」という点で、プログラミング言語の基本理解と、よくあるCLIコマンドの知識があれば、かなり助けになります。モデルが、作業ディレクトリの外にあるファイルやフォルダに対して rm -rf を実行しようとし始めたら、何かがうまくいっていない可能性が高いです。
これは Pi Coding Agent では当てはまりません。Pi Coding Agent は、標準で YOLO モードで動作し、それによりアクセスできるものを何でも読み取り、何でも変更できる“自由度”が与えられます。仮想マシンや Raspberry Pi など、専用の開発環境であれば容認できるリスクかもしれませんが、そうでないなら、適切なサンドボックス内で実行することを検討した方がよいでしょう。
コンテナ化は、この点で手軽な道を提供します。Docker コンテナを立ち上げて、作業ディレクトリをそこに渡すだけなので、やり方は比較的簡単です。Docker はそれ自体がワームの缶詰のようなもの(厄介な点が多い)ですが、以下の run コマンドならサンドボックス環境のための妥当な出発点になるはずです。お使いのOSで Docker をインストールする手順は こちら で確認できます。
docker run -it --name vibe_container -v working_dir:/working_dir ubuntu /bin/bash
これにより、新しい Ubuntu の Docker コンテナが起動され、作業ディレクトリがコンテナへ引き継がれます。変更はそのフォルダまたはコンテナ内に限定されます。
エージェント用のサンドボックスを構築する包括的なガイドをご覧になりたい場合は、コメント欄でお知らせください。®