大規模言語モデル(LLM)は現在、最も先進的な会話エージェント、創造的ツール、意思決定支援システムを動かしています。しかし、その生の出力には、しばしば不正確さ、ポリシーの不整合、または役に立たない表現が含まれます。これらの問題は信頼性を損ない、現実世界での有用性を制限します。強化微調整(RFT)は、コストのかかる手作業のラベル付けに代えて自動化された報酬シグナルを用いることで、これらのモデルを効率的に整合させるための、好まれる方法として登場しました。
現代のRFTの中核にあるのは報酬関数です。報酬関数は、ドメインごとに構築されます。検証可能な報酬関数によって、LLMの生成結果をコードの一部(検証可能な報酬による強化学習、Reinforcement Learning with Verifiable Rewards、RLVR)で評価する、または別の言語モデルが候補となる応答を評価して整合を導く(AIフィードバックによる強化学習、Reinforcement Learning with AI Feedback、RLAIF)という方式があります。どちらの方法も、RLアルゴリズムにスコアを渡して、モデルが目の前の課題を解けるように後押しします。本記事では、Amazon Novaモデルを用いてRLAIF、またはLLMを「裁定者(judge)」として用いる強化学習が、どのように効果的に機能するのかをより深く掘り下げます。
LLM-as-a-judgeによるRFTは、一般的なRFTと比べてなぜ有効か?
強化微調整は、任意の報酬シグナルを使えます。たとえば、単純な手作りルール(RLVR)や、モデルの出力を評価するLLM(LLM-as-a-judgeまたはRLAIF)などです。RLAIFは、特に報酬シグナルが曖昧で手作業で作りにくい場合に、整合をより柔軟かつ強力にします。文字列一致のような鈍い数値スコアに依存する一般的なRFTの報酬とは異なり、LLMの裁定者は複数の次元にわたって推論します(正確性、トーン、安全性、関連性)。その結果、タスク固有の再学習を行わずに、文脈に応じたフィードバックを提供し、微妙なニュアンスやドメイン特有の要点を捉えます。さらに、LLMの裁定者は根拠(例:「応答Aは査読付きの研究を引用している」)を通じて組み込みの説明可能性を提供します。これにより、反復を加速し、失敗のパターンを直接特定し、隠れたミスアライメントを減らせます。静的な報酬関数ではできないことです。
LLM-as-a-judgeの実装:6つの重要ステップ
このセクションでは、LLM-as-a-judgeの報酬関数を設計し、デプロイする際に関わる重要なステップを説明します。
裁定者のアーキテクチャを選ぶ
最初に重要な意思決定は、裁定者のアーキテクチャを選ぶことです。LLM-as-a-judgeには2つの主要な評価モードがあります。ルーブリックベース(ポイントベース)での裁定と嗜好(プレファレンス)ベースでの裁定で、それぞれ異なる整合シナリオに適しています。
| 基準 | ルーブリックベースでの裁定 | 嗜好(プレファレンス)ベースでの裁定 |
| 評価方法 | 事前に定義した基準に基づいて、単一の応答に数値スコアを割り当てる | 2つの候補応答を並べて比較し、より優れた方を選択する |
| 品質の測定 | 絶対的な品質測定 | 直接比較による相対的な品質 |
| 使用が好ましいケース | 明確で定量化可能な評価次元が存在する(正確性、網羅性、安全性の遵守) | 参照データの制約なしに、ポリシーモデルを自由に探索させるべきである |
| データ要件 | 報酬仕様にモデルを整合させるための、慎重なプロンプト設計のみを必要とする | 嗜好比較のために、少なくとも1つの応答サンプルが必要 |
| 汎化性 | 分布外データに対してより適しており、データバイアスを回避する | 参照となる応答の品質に依存する |
| 評価スタイル | 絶対スコアリングシステムを反映する | 比較による、人間の自然な評価を反映する |
| 推奨される開始点 | 嗜好データが利用できず、RLVRが適さない場合はここから始める | 比較データが利用可能なときに使用する |
評価基準を定義する
裁定者のタイプを選んだら、改善したい具体的な次元(ディメンション)を明確に言語化します。明確な評価基準は、有効なRLAIFトレーニングの土台です。
嗜好ベースの裁定者の場合:
ある応答が別の応答より優れているのは何かを説明する、明確なプロンプトを書きます。品質の好みを、具体的な例とともに明示してください。例: 「権威ある出典を引用し、分かりやすい言葉を使い、ユーザーの質問に直接答える応答を好む。」
ルーブリックベースの裁定者の場合:
ルーブリックベースの裁定者には、 Boolean(合格/不合格)スコアリング を使うことを推奨します。Booleanスコアリングは、きめ細かい1〜10スケールと比べてより信頼性が高く、裁定者のばらつきを減らします。各評価次元について、特定の観察可能な特徴を伴う、明確な合格/不合格基準を定義してください。
裁定者モデルを選択して構成する
対象ドメインを評価するのに十分な推論能力を持つLLMを選びます。Amazon Bedrockを通じて構成し、reward AWS Lambda関数を使って呼び出します。数学、コーディング、会話能力のような一般的なドメインであれば、慎重なプロンプト設計により、小型のモデルでもうまく機能する可能性があります。
| モデル層 | おすすめ用途 | コスト | 信頼性 | Amazon Bedrockモデル |
| Large/Heavyweight | 複雑な推論、ニュアンスのある評価、多次元のスコアリング | 高 | 非常に高 | Amazon Nova Pro、Claude Opus、Claude Sonnet |
| Medium/Lightweight | 数学やコーディングのような一般的な領域、バランスの取れたコストとパフォーマンス | 低〜中 | 中〜高 | Amazon Nova 2 Lite、Claude Haiku |
ジャッジモデルのプロンプトを洗練させる
ジャッジ用プロンプトはアラインメント品質の土台です。構造化され、解析可能(パース可能)で、明確なスコアリングの次元が得られるように設計してください。
- 構造化された出力形式 – 取り出し(抽出)を容易にするために、JSONまたは解析可能な形式を指定する
- 明確なスコアリングルール – 各次元をどのように計算するかを正確に定義する
- エッジケースの取り扱い – 曖昧な状況に対処する(例:「応答が空の場合はスコア0を付与する」)
- 望ましい振る舞い – 促進または抑制したい振る舞いを明示的に記述する
ジャッジ基準を本番の評価指標に合わせる
報酬関数(reward function)は、本番環境で最終モデルを評価するために使う指標を反映させるべきです。報酬関数を本番の成功基準に合わせることで、正しい目的に最適化されたモデルを実現できるようになります。
アラインメントのワークフロー:
- 定義:許容できるしきい値(たとえば精度や安全性など)を含めて、本番の成功基準を定める
- マッピング:各基準を特定のジャッジのスコアリング次元に対応付ける
- 検証:ジャッジのスコアが評価指標と相関することを確認する
- テスト:代表的なサンプルとエッジケースでジャッジを試す
堅牢な報酬Lambda関数の構築
本番RFT(RFT)システムは、学習ステップごとに何千もの報酬評価を処理します。学習の安定性、計算の効率的な使用、そして信頼できるモデル挙動を支えるために、レジリエントな報酬Lambda関数を構築します。ここでは、堅牢で効率的、かつ本番対応可能な報酬Lambda関数を作る方法を説明します。
複合報酬スコアの構造化
LLMジャッジにだけ頼らないでください。素早く決定論的な報酬コンポーネントと組み合わせ、高コストなジャッジ評価の前に明白な失敗を検知します。
主要コンポーネント
| コンポーネント | 目的 | 使用タイミング |
| 形式の正確性 | JSONの構造、必須フィールド、スキーマ準拠を検証する | 常に – 不正な出力を直ちに検出する。安価で即時のフィードバック。 |
| 長さに対するペナルティ | 過度に冗長、または過度に簡潔な応答を抑制する | 出力の長さが重要なとき(例:要約) |
| 言語の一貫性 | 応答が入力言語と一致しているかを検証する | 多言語アプリケーションでは重要 |
| 安全性フィルタ | 禁止コンテンツに対するルールベースのチェック | 常に – 危険なコンテンツが本番に到達するのを防ぐ |
インフラの準備状況
- 指数バックオフを実装する:Amazon Bedrock APIのレート制限や一時的な障害に対して、適切に耐えられるようにする
- 並列化の戦略:ThreadPoolExecutorまたはasyncパターンを使用して、ロールアウト間でジャッジ呼び出しを並列化し、レイテンシを削減する
- Lambdaのコールドスタート遅延を回避する:適切なLambdaタイムアウトを設定する(推奨:15分)し、プロビジョンド・コンカレンシー(典型的なセットアップで約100)を用意する
- エラーハンドリング:学習ステップ全体を失敗させるのではなく、中立的/ノイズのある報酬(0.5)を返すように、包括的なエラーハンドリングを追加する
報酬Lambda関数の堅牢性をテストする
ジャッジの一貫性とキャリブレーションを検証します:
- 一貫性:同じサンプルでジャッジを複数回テストし、スコアのばらつき(分散)を測定する(決定論的評価であれば低いはず)
- ジャッジ間の比較:異なるジャッジモデル間でスコアを比較し、評価上の盲点を特定する
- 人手によるキャリブレーション:ジャッジのドリフトや体系的な誤りを検出するために、定期的にロールアウトを人手でサンプリングしてレビューする
- 回帰テスト:既知の「良い/悪い」例を含む「ジャッジテストスイート」を作成し、ジャッジ挙動を回帰テストする
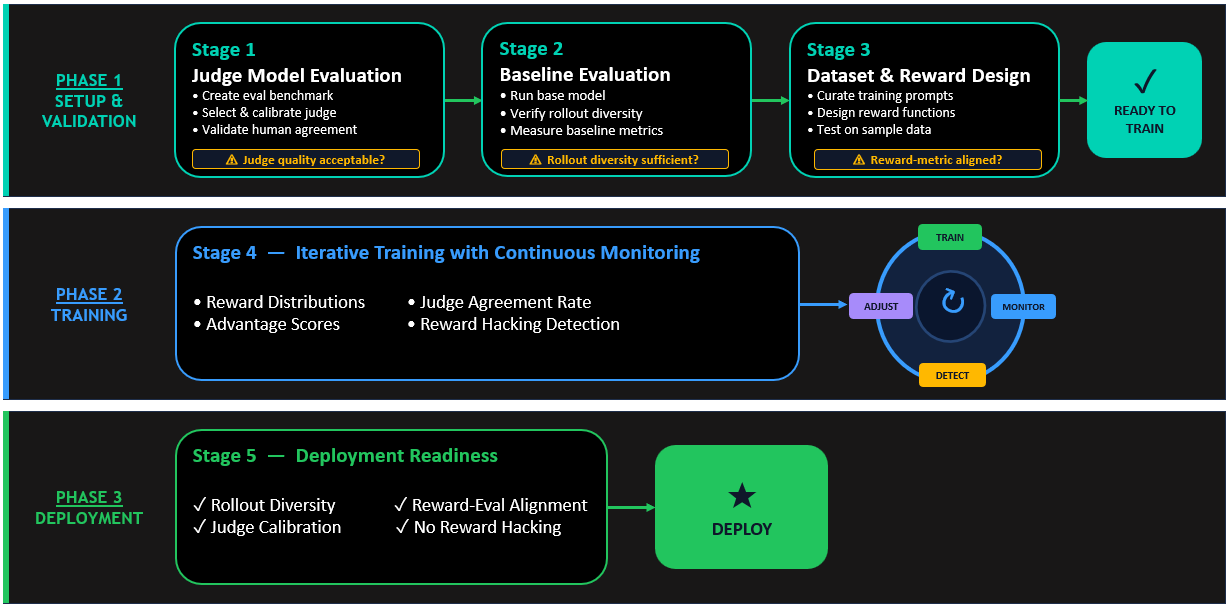
LLMをジャッジとして用いるRFT – 学習ワークフロー
以下の図は、ベースライン評価からジャッジの検証、本番へのデプロイまでの、完全なエンドツーエンドの学習プロセスを示しています。各ステップは前のステップの上に構築され、整合(アラインメント)の品質と計算効率のバランスを取りつつ、報酬ハッキングを積極的に防ぎ、本番対応可能なモデル挙動を支えるレジリエントなパイプラインを作り上げます。
実世界のケーススタディ:法務契約レビューを自動化する
このセクションでは、主要な法務業界のパートナーと共同で行った実世界のユースケースを取り上げます。課題は、ポリシーや参照用の過去契約書を参照文書として、法的な文書に対するリスク、評価、およびアクションに関するコメントを生成することです。
課題
パートナーは、法的な契約書類におけるレビュー、評価、リスクのフラグ付けを行うプロセスを自動化するという問題の解決に関心を持っていました。具体的には、潜在的な新規契約を、社内のガイドラインや規制、過去の契約、およびその契約に関連する当該国の法律に照らして評価したいと考えていました。
解決策
私たちは、この問題を「LLMに評価させる対象文書(“契約”)」と「参照文書(根拠となる文書および文脈)」を提示し、評価に基づいて複数のコメント、コメント種別、および推奨アクションを含むJSONをLLMが生成するという形で定式化しました。このユースケースに利用可能だった元データセットは比較的小さく、完全な契約書と、法務の専門家による注釈およびコメントが含まれていました。本件では、RFT中にGPT OSS 120bモデルを“裁判官”として用い、さらにカスタムのシステムプロンプトを使用して、LLMを審査員(judge)として機能させました。
RFTワークフロー
次のセクションでは、このユースケースにおけるRFTワークフローの主要な側面の詳細を説明します。
LLM-as-a-judge 用の報酬Lambda関数
以下のコードスニペットは、報酬Lambda関数の主要コンポーネントを示しています。
注記: Lambda関数の名前には “SageMaker” を含める必要があります。たとえば "arn:aws:lambda:us-east-1:123456789012:function:MyRewardFunctionSageMaker"
a) 高レベルの目的から始める
# 契約レビュー評価 - 重みなしスコアリング
あなたは、AIが生成したコメントを評価する専門の契約レビュアーです。あなたのPRIMARY(最優先)の目的は、各予測コメントがTargetDocumentの契約条項における問題をどれだけ適切に特定しているか、そしてそれらの問題が参照ガイドラインによってどれだけ妥当な根拠を持つかを評価することです。b) 評価アプローチを定義する
## 評価アプローチ
各サンプルについて、次が与えられます:
- **TargetDocument**:レビュー対象の契約文(評価対象となる文書)
- **Reference**:レビューに用いる参照ガイドライン/基準(評価基準)
- **Prediction**:AIモデルからの1つまたは複数のコメント
**重要**:SystemPromptには、モデルが受け取った指示が示されています。予測の品質を評価する際に、モデルがこれらの指示に従っていたかどうかを考慮してください。
**CRITICAL(重大)**:各コメントは、対象文書の契約テキスト自身(IN THE TARGETDOCUMENT CONTRACT TEXT ITSELF)における、特定の問題、ギャップ、懸念を指摘しなければなりません。コメントの text_excerpt フィールドは、参照ガイドラインの文ではなく、TargetDocument から問題のある契約文言を引用(quote)している必要があります。参照(Reference)は、なぜその契約条項が問題なのか(WHY the contract clause is problematic)を正当化しますが、問題は契約文の中に存在していなければなりません。
各予測コメントをそれぞれ独立に評価してください。コメントは、参照(Reference)の要件を単に挙げるのではなく、契約条項における問題をフラグ(flag)すべきです。c) 特定のスコアがどのように計算されるかを明確な仕様付きで、評価の次元を説明する
## スコアリング次元(コメントごと)
**評価順序(EVALUATION ORDER)**:この順に評価します:(1) TargetDocument_Grounding、(2) Reference_Consistency、(3) Actionability
### 1. TargetDocument_Grounding
**評価対象**: (a) text_excerpt が TargetDocument の契約文言から引用しているか、そして (b) コメントがその引用された text_excerpt に関連しているか
**必須**:text_excerpt は TargetDocument の契約文言を引用していなければなりません。もし text_excerpt が Reference を引用している場合、スコアは **1** です。
- **5**:text_excerpt が TargetDocument の契約文言を正しく引用しており、かつコメントがその引用文に含まれる非常に関連性が高く、有効で、重要な問題を特定している
- **4**:text_excerpt が TargetDocument の契約文言を正しく引用しており、かつコメントがその引用文に含まれる妥当で関連性のある問題を特定している
- **3**:text_excerpt が TargetDocument の契約文言を正しく引用しており、その引用文に対してコメントはある程度関連しているが、懸念の妥当性は中程度
- **2**:text_excerpt が TargetDocument の契約文言を正しく引用しているが、コメントの引用文への関連性が弱い、または懸念が疑わしい
- **1**:text_excerpt が TargetDocument の契約文言を引用していない(Reference を引用している、または実際の引用がない)、またはコメントが引用文に対して無関係
### 2. Reference_Consistency
...d) 解釈・解析するための最終出力フォーマットを明確に定義する
## スコア計算
**Comment_Score** = 3つの次元の単純平均:
- Comment_Score = (TargetDocument_Grounding + Reference_Consistency + Actionability) / 3
**Aggregate_Score** = サンプルに含まれる全 Comment_Score の平均
## 出力フォーマット
各サンプルについて、予測されたコメントをすべて評価し、次を提示してください:
```json
{ "comments": [
{ "comment_id": "...",
"TargetDocument_Grounding": {"score": X, "justification": "...", "supporting_evidence": "Verify text_excerpt quotes actual TargetDocument contract text and comment is relevant to it"},
"Reference_Consistency": {"score": X, "justification": "...", "supporting_reference": "Quote from Reference that justifies the concern OR explain meaningful reasoning"},
"Actionability": {"score": X, "justification": "Assess if action is clear, grounded in TargetDocument and Reference, and relevant to comment"},
"Comment_Score": X.XX
} ],
"Aggregate_Score": {
"score": X.XX,
"total_comments": N,
"rationale": "..."
}
}
```e) 高レベルのLambdaハンドラを作成し、推論を高速化するための十分なマルチスレッドを提供する
def lambda_handler(event, context):
scores: List[RewardOutput] = []
samples = event
max_workers = len(samples)
print(f"Evaluating {len(samples)} items with {max_workers} threads...")
with ThreadPoolExecutor(max_workers=max_workers) as executor:
futures = [executor.submit(judge_answer, sample) for sample in samples]
scores = [future.result() for future in futures]
print(f"Completed {len(scores)} evaluations")
return [asdict(score) for score in scores]Lambda関数のデプロイ
Lambda関数では、次のAWS Identity and Access Management(IAM)権限と設定を使用しました。以下の構成は、報酬Lambda関数に必要です。これらのいずれかが欠けていると、RFTの学習が失敗する可能性があります。
a) Amazon SageMaker AI実行ロールのための権限
Amazon SageMaker AI の実行ロールには、Lambda関数を呼び出す権限が必要です。次のポリシーを Amazon SageMaker AI 実行ロールに追加してください:
返却形式: {"translated": "翻訳されたHTML"}{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"lambda:InvokeFunction"
],
"Resource": "arn:aws:lambda:region:account-id:function:function-name"
}
]
}b) Lambda 関数実行ロールの権限
Lambda 関数の実行ロールには、基本的な Lambda 実行権限に加えて、judge Amazon Bedrock モデルを呼び出すための権限が必要です。
注: このソリューションは、AWS の共有責任モデルに従います。AWS は、クラウド上で AWS サービスを実行するインフラストラクチャのセキュリティ確保を担当します。あなたは、Lambda 関数コードのセキュリティ確保、IAM 権限の設定、暗号化およびアクセス制御の実装、データのセキュリティとプライバシーの管理、監視とログの設定、適用される規制への準拠を検証することを担当します。特定のリソース ARN にスコープすることで、最小権限の原則に従ってください。詳細については、AWS のドキュメントにある Security を、また Amazon SageMaker AI の Security を参照してください。
c) プロビジョニング済みの同時実行(プロビジョンド・コンカレンシー)を追加
Lambda のバージョンを公開し、関数がレイテンシの揺らぎなしにスケールできるようにするため、このケースではプロビジョンド・コンカレンシーをいくつか追加しました。今回の例では 100 で十分でしたが、ここにはコスト改善の余地がさらにあります。

d) Lambda のタイムアウトを 15 分に設定

トレーニング設定のカスタマイズ
データ準備からデプロイ、監視まで、モデルのカスタマイズのライフサイクル全体に使用できる Nova Forge SDK をリリースしました。Nova Forge SDK により、特定の手法に適したレシピやコンテナ URI を検索する必要がなくなります。
Nova Forge SDK を使うことで、トレーニングパラメータを 2 通りの方法でカスタマイズできます。recipe_path を使用して完全なレシピ YAML を提供するか、オーバーライドで特定のフィールドだけを指定して選択的な変更を行います。このユースケースでは、以下のセクションで示すとおり、オーバーライドを使ってロールアウトおよびトレーナーの設定を調整します。
# レシピのオーバーライドでトレーニングを起動
result = customizer.train(
job_name="my-rft-run",
rft_lambda_arn="<your-lambda-arn>",
overrides={
# トレーニング設定
"max_length": 64000,
"global_batch_size": 64,
"reasoning_effort": None,
# データ
"shuffle": False,
# ロールアウト
"type": "off_policy_async",
"age_tolerance": 2,
"proc_num": 6,
"number_generation": 8,
"max_new_tokens": 16000,
"set_random_seed": True,
"temperature": 1,
"top_k": 0,
"lambda_concurrency_limit": 100,
# トレーナー
"max_steps": 516,
"save_steps": 32,
"save_top_k": 17,
"refit_freq": 4,
"clip_ratio_high": 0.28,
"ent_coeff": 0.0,
"loss_scale": 1,
},
)結果
Amazon Nova 2 Lite による RFT は、JSON スキーマの検証を完璧に維持しながら、4.33 の集計スコア(評価したすべてのモデルの中で最高)を達成しました。これは大きな改善であり、RFT が、より大きな汎用的代替案を上回る本番投入に適した、専門化されたモデルを生成できることを示しています。
モデルは 「best of k(k 個のうち最良)」の単一コメント設定で評価しました。つまり、各モデルが各サンプルに対して複数のコメントを生成し、最も品質の高い出力にスコアを与えます。この手法は性能の上限を設定し、単一出力と複数出力を生成するモデル同士の公平な比較を可能にします。
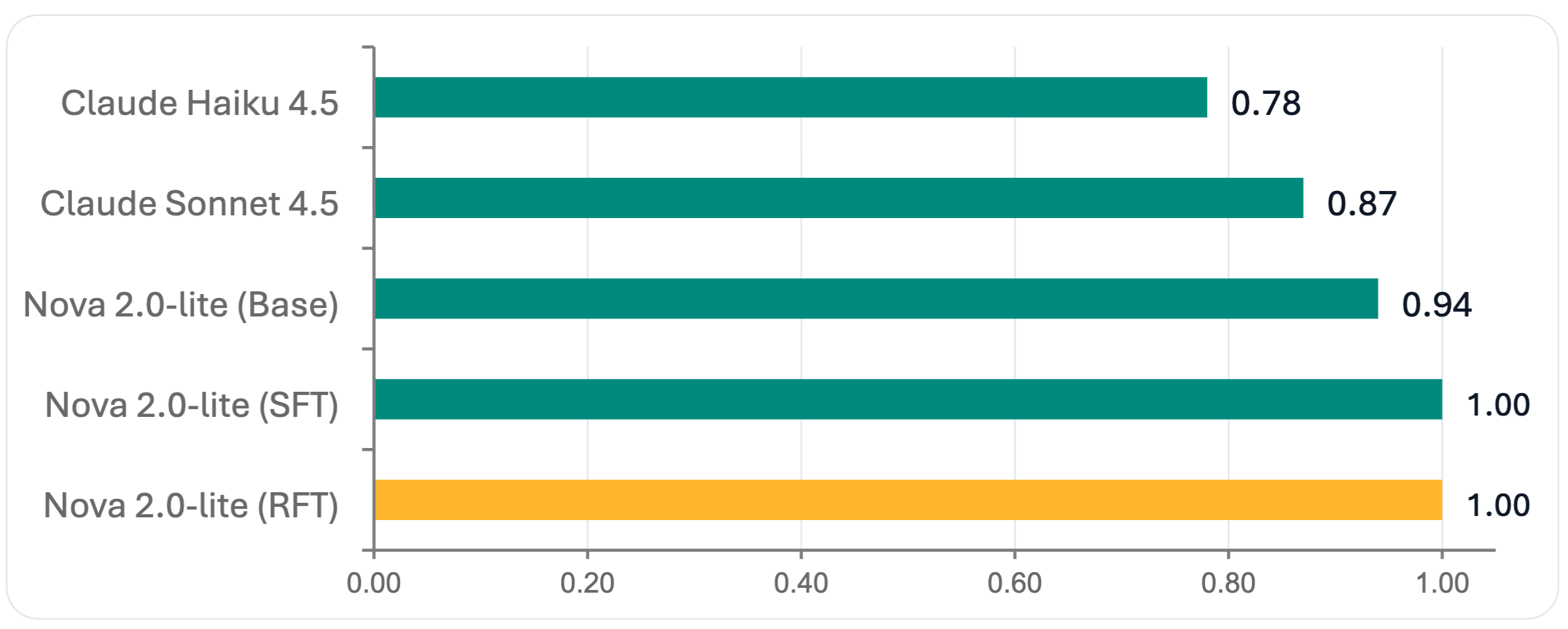
図 1 — JSON スキーマ検証スコア(0〜1、値が高いほど良い)
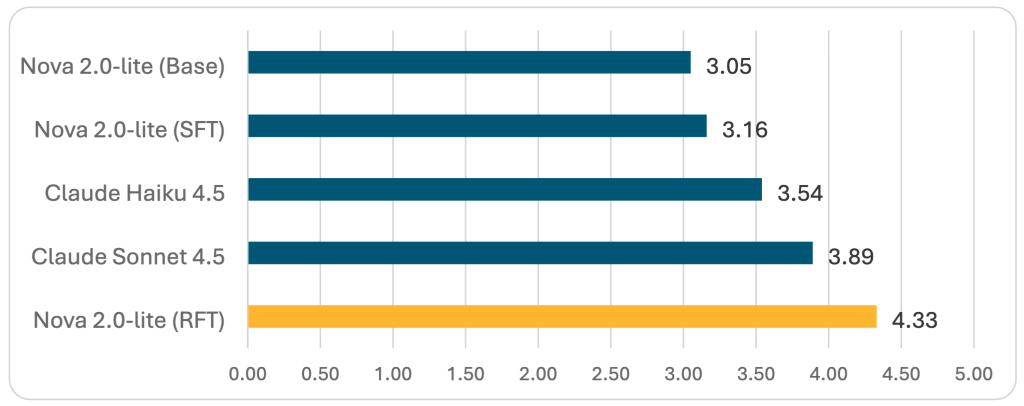
図 2 — 集計 LLM ジャッジスコア(1〜5、値が高いほど良い)
要点:
- 本研究で評価したモデルの中で、RFT が最も高いパフォーマンスを達成しました。
RFT を用いた Amazon Nova 2 Lite は 4.33 の集計 スコアを達成し、Claude Sonnet 4.5 と Claude Haiku 4.5 の両方を上回りました。また、完全な JSON スキーマ検証 も達成しました。
- 不要なトレーニング成果物を取り除く
SFT の反復中に、反復的なコメント生成や不自然な Unicode 文字予測などの問題のある挙動を確認しました。これらの問題は、過学習またはデータセットの偏りによって引き起こされた可能性が高く、RFT のチェックポイントには現れませんでした。RFT の報酬ベースの改善は、このような成果物を自然に抑制し、より堅牢で信頼性の高い出力を生成することにつながります。
- 新しいジャッジ基準への強い汎化
修正したジャッジ用プロンプト(学習報酬関数に整合しているが完全には一致していない)を用いてRFTモデルを評価したところ、性能は強いままでした。これは、RFTが特定の評価基準に過度に適合(オーバーフィット)するのではなく、一般化可能な品質パターンを学習することを示しています。要件が変化する現場での実運用において、この点は極めて重要な利点です。
- 計算(コンピュート)に関する考慮
RFTは学習サンプルごとに4〜8回のロールアウトを必要とし、SFTと比べて計算コストが増加しました。また、推論の努力設定をゼロ以外にすると、このオーバーヘッドはさらに増幅されます。とはいえ、法的契約レビュー、金融コンプライアンス、医療文書化のように、アライメント品質がビジネス成果に直接影響するミッションクリティカルなアプリケーションでは、性能向上による効果が追加の計算コストを正当化します。
結論
LLM-as-a-judgeを用いた強化微調整(RFT)は、ドメイン固有のアプリケーション向けにLLMをアラインメントさせるための強力なアプローチです。我々の法的契約レビューのケーススタディで示したとおり、この手法は、ベースモデルおよび従来の教師あり微調整(SFT)の両方と比較して大きな改善をもたらし、RFTは評価のあらゆる次元で最高の総合スコアを達成しました。ビジネス成果に直接影響するアライメント品質を必要とする、ミッションクリティカルなAIシステムを構築するチームにとって、LLM-as-a-judgeによるRFTは有力な前進の道を提供します。この手法の説明可能性、柔軟性、そして優れた性能は、法務レビュー(または金融サービス、ヘルスケア)のように、微妙なニュアンスが重要となる複雑な領域で特に価値があります。
このアプローチを検討する組織は、小さく始めるべきです。すなわち、厳選したベンチマークでジャッジ設計を検証し、インフラの耐障害性を確認し、報酬ハッキングの兆候を監視しながら段階的にスケールしてください。適切に実装すれば、RFTは有能なベースモデルを、アラインメントされ信頼できる出力を一貫して提供する、高度に専門化された本番投入可能なシステムへと変えることができます。
参考文献:
免責事項:
本記事で説明する法的契約レビューのユースケースは、技術デモンストレーション目的のみです。AIによる契約分析は、専門的な法的助言の代替ではありません。法的事項については、適切な法務専門家にご相談ください。



