Text-to-SQLの生成は、特にカスタムSQL方言やドメイン固有のデータベーススキーマを扱う場合に、エンタープライズAIアプリケーションにおいて継続的な課題となっています。ファウンデーションモデル(FM)は標準SQLでは高い性能を示しますが、専門的な方言に対して本番レベルの精度を実現するにはファインチューニングが必要です。しかし、ファインチューニングには運用上のトレードオフがあります。永続的なインフラ上でカスタムモデルをホストすると、利用がゼロの期間であっても継続的なコストが発生してしまうためです。
ファインチューニングしたAmazon Nova Microモデルを使った、Amazon Bedrockでのオンデマンド推論は、その代替手段となります。LoRA(Low-Rank Adaptation)の効率的なファインチューニングと、サーバーレスかつ従量課金(トークン単位)の推論を組み合わせることで、組織は、永続的なモデルホスティングによって生じるオーバーヘッドコストなしに、カスタムのテキスト-to-SQL機能を実現できます。LoRAアダプタ適用に伴う追加の推論時間オーバーヘッドはあるものの、テストでは対話型のText-to-SQLアプリケーションに十分なレイテンシが確認されました。さらに、コストはプロビジョニングされたキャパシティではなく利用量に応じて増減します。
本投稿では、コスト効率と本番対応の性能の両方を実現するために、カスタムSQL方言の生成用のAmazon Nova Microをファインチューニングする2つのアプローチを示します。例として用いたワークロードでは、月間22,000件のサンプルトラフィックで毎月0.80ドルのコストを維持でき、永続ホスト型のモデルインフラと比較してコスト削減につながりました。
前提条件
これらのソリューションをデプロイするには、次のものが必要です:
- 課金を有効化したAWSアカウント
- 標準のIAM権限と、アクセスのために設定されたロール:
-
- Amazon Bedrock Nova Microモデル
- Amazon SageMaker AI
- Amazon Bedrock モデルのカスタマイズ
- Amazon SageMaker AIのトレーニング用に、ml.g5.48xlインスタンスのクォータ
ソリューション概要
このソリューションは、次の高レベルの手順で構成されます:
- 組織のSQL方言およびビジネス要件に固有のI/Oペアで、カスタムSQLのトレーニングデータセットを準備します。
- 準備したデータセットと選択したファインチューニング手法を使って、Amazon Nova Microモデルでファインチューニング処理を開始します。
- ストリームラインされたデプロイのためのAmazon Bedrockモデルのカスタマイズ
- きめ細かなトレーニングのカスタマイズと制御のためのAmazon SageMaker AI
- オンデマンド推論を利用するために、カスタムモデルをAmazon Bedrockにデプロイします。これによりインフラ管理を削減しつつ、トークン利用分のみを支払います。
- カスタムSQL方言とビジネスユースケースに特化したテストクエリでモデル性能を検証します。
実際の運用でこのアプローチを示すために、異なる組織のニーズに対応する2つの完全な実装パスを用意しています。1つ目は、シンプルさと迅速なデプロイを優先するチーム向けに、Amazon Bedrockのマネージドモデルカスタマイズを使用します。2つ目は、ハイパーパラメータおよびトレーニングインフラに対してより粒度の細かい制御を必要とする組織向けに、Amazon SageMaker AIのトレーニングジョブを使用します。どちらの実装も同じデータ準備パイプラインを共有し、オンデマンド推論のためにAmazon Bedrockへデプロイします。以下はそれぞれのGitHubコードサンプルへのリンクです:
次のアーキテクチャ図は、データ準備、両方のファインチューニング手法、そしてサーバーレス推論を可能にするBedrockデプロイ経路を含む、エンドツーエンドのワークフローを示しています。
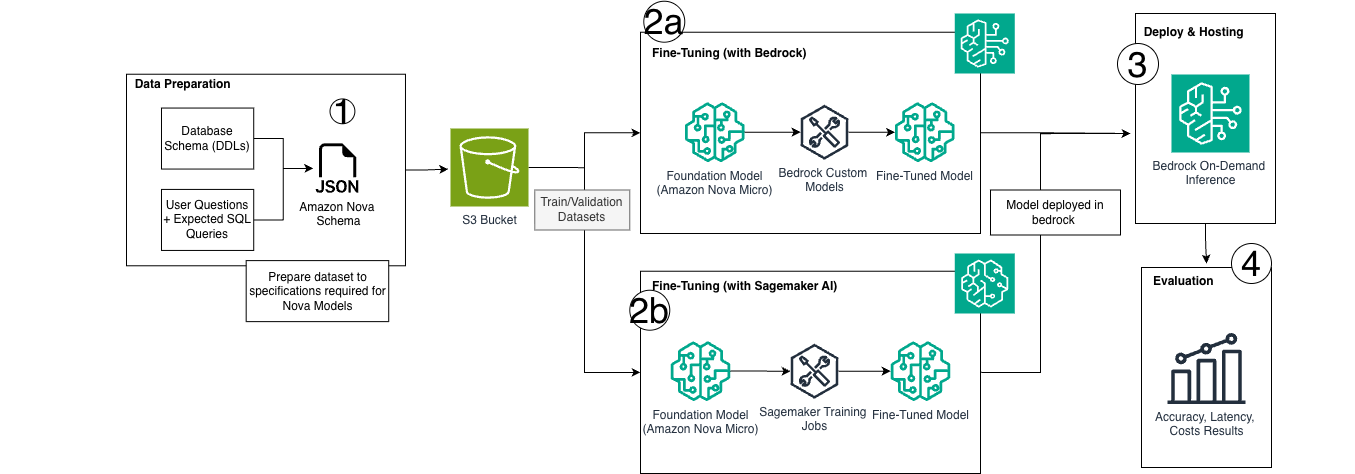
1. データセット準備
本デモでは、sql-create-contextデータセットを使用します。このデータセットは、WikiSQLとSpiderデータセットを組み合わせたキュレーション済みのもので、多様なデータベーススキーマにまたがる、SQLクエリと対になった自然言語の質問の例が78,000件以上含まれています。このデータセットは、単純なSELECT文から集約を伴う複雑な多テーブル結合まで、クエリの複雑さの幅が広いため、Text-to-SQLのファインチューニングの理想的な基盤となります。
データのフォーマットと構造
トレーニングデータは、ドキュメントに記載されたとおりの形式で構成されています。ここでは、システムプロンプトの指示と、ユーザーの質問、そしてそれに対応する複雑さの異なるSQLレスポンスを組み合わせたJSONLファイルを作成します。フォーマット済みのトレーニングデータセットは、その後トレーニング用と検証用に分割され、JSONLファイルとして保存され、ファインチューニング処理のためにAmazon Simple Storage Service (Amazon S3)へアップロードされます。
サンプル変換済みレコード
{
"schemaVersion": "bedrock-conversation-2024",
"system": [
{
"text": "あなたは強力なテキストからSQLへのモデルです。あなたの仕事は、データベースに関する質問に答えることです。文脈として、次のテーブルスキーマを使用できます: CREATE TABLE head (age INTEGER)"
}
],
"messages": [
{
"role": "user",
"content": [
{
"text": "次の質問に答えるSQLクエリを返してください。部門のヘッド(head)が56より年齢が高いのは何人ですか?"
}
]
},
{
"role": "assistant",
"content": [
{
"text": "SELECT COUNT(*) FROM head WHERE age > 56"
}
]
}
]
}Amazon Bedrock のファインチューニング手法
Amazon Bedrock のモデルカスタマイズは、学習用のインフラストラクチャを用意したり管理したりする必要なく、Amazon Nova モデルをファインチューニングするための、合理化された完全マネージド手法を提供します。この方法は、テキストからSQLのユースケースに合わせてカスタムモデルの性能を実現しつつ、迅速な反復と最小限の運用負荷を求めるチームに最適です。
Amazon Bedrock のカスタマイズ機能を使用して、学習データを Amazon S3 にアップロードし、AWS コンソールまたは API でファインチューニングジョブを設定します。AWS が基盤となる学習インフラストラクチャを処理します。生成されたカスタムモデルはオンデマンド推論でデプロイできます。これにより、追加のマークアップなしでベースの Nova Micro モデルと同じトークンベースの価格設定を維持できるため、変動するワークロードに対して費用対効果の高いソリューションになります。このアプローチは、ML インフラストラクチャを管理することなくカスタム SQL 方言向けにモデルを迅速にカスタマイズする必要がある場合、運用の複雑さを最小限にしたい場合、または自動スケーリングを伴うサーバーレス推論が必要な場合に適しています。
2a. Amazon Bedrock を使ったファインチューニングジョブの作成
Amazon Bedrock は、AWS コンソールと AWS SDK for Python(Boto3) の両方を使ったファインチューニングをサポートしています。AWS のドキュメントには、これらの両方のアプローチで学習ジョブを送信する方法についての一般的なガイダンスが記載されています。今回の実装では、AWS SDK for Python(Boto3)を使用しました。手順ごとの実装内容を確認するには、GitHub サンプルリポジトリの サンプルノートブック を参照してください。
ハイパーパラメータを設定する
ファインチューニングするモデルを選択した後、ユースケースに合わせてハイパーパラメータを設定します。Amazon Bedrock での Amazon Nova Micro のファインチューニングでは、テキストからSQLモデルを最適化するために、次の ハイパーパラメータ をカスタマイズできます。
| パラメータ | 範囲/制約 | 目的 | 使用した値 |
| エポック(Epochs) | 1〜5 | 学習データセットを通過する完全な回数 | 5 エポック |
| バッチサイズ(Batch Size) | 固定で 1 | モデル重みを更新する前に処理されるサンプル数 | 1(Nova Micro では固定) |
| 学習率(Learning Rate) | 0.000001〜0.0001 | 勾配降下の最適化におけるステップサイズ | 安定した収束のために 0.00001 |
| 学習率ウォームアップ手順(Learning Rate Warmup Steps) | 0〜100 | 学習率を徐々に増加させるためのステップ数 | 10 |
注: これらのハイパーパラメータは、特定のデータセットおよびユースケースに対して最適化したものです。最適な値は、データセットのサイズや複雑さによって変わり得ます。サンプルデータセットでは、この構成によりモデルの精度と学習時間のバランスが改善し、約 2〜3 時間で完了しました。
学習メトリクスの分析
Amazon Bedrock は、学習用および検証用のメトリクスを自動的に生成し、指定した S3 の出力先に保存します。これらのメトリクスには以下が含まれます:
- 学習損失(Training loss): モデルが学習データにどれだけ適合しているかを測定します
- 検証損失(Validation loss): 未知のデータに対する汎化性能を示します
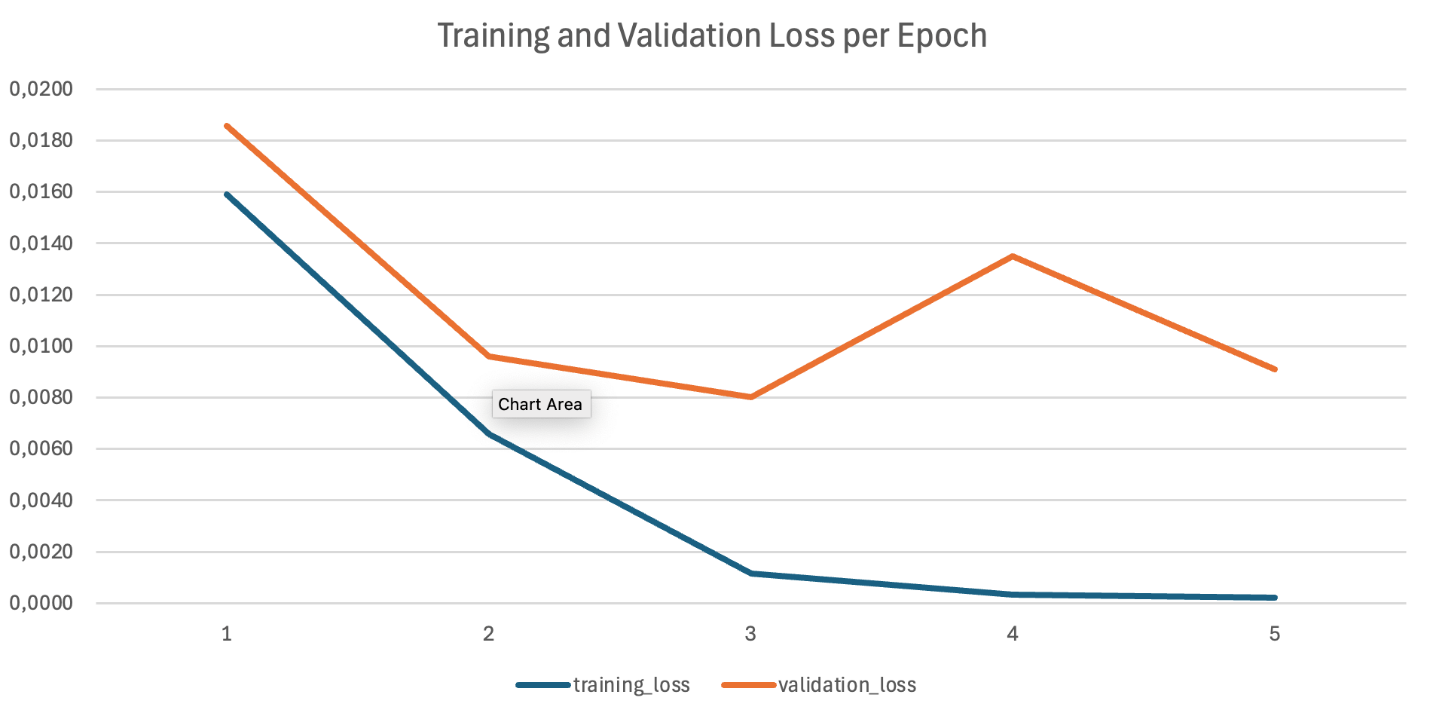
学習損失および検証損失のカーブは、学習が成功していることを示しています。どちらも一貫して低下し、同様のパターンに従い、最終的には同等の値へ収束しています。
3a. オンデマンド推論でデプロイする
ファインチューニングジョブが正常に完了した後、オンデマンド推論を使用してカスタム Nova Micro モデルをデプロイできます。このデプロイオプションは、自動スケーリングと「使用したトークン数に応じた」課金(pay-per-token)を提供するため、専用の計算リソースを用意する必要なく、変動するワークロードに最適です。
カスタム Nova Micro モデルの呼び出し
デプロイ後、Amazon Bedrock Converse API でモデル ID としてデプロイメント ARN を指定することで、カスタムのテキストからSQLモデルを呼び出せます。
# モデルIDとしてデプロイメントARNを使用します
deployment_arn = "arn:aws:bedrock:us-east-1:<account-id>:deployment/<deployment-id>"
# 推論リクエストを準備します
response = bedrock_runtime.converse(
modelId=deployment_arn,
messages=[
{
"role": "user",
"content": [
{
"text": """データベーススキーマ:
CREATE TABLE sales (
id INT,
product_name VARCHAR(100),
category VARCHAR(50),
revenue DECIMAL(10,2),
sale_date DATE
);
質問: Electronicsカテゴリにおける売上(revenue)の上位5商品は何ですか?"""
}
]
}
],
inferenceConfig={
"maxTokens": 512,
"temperature": 0.1, # 決定的なSQL生成のために低い温度を設定します
"topP": 0.9
}
)
# 生成されたSQLクエリを抽出します
sql_query = response['output']['message']['content']['text']
print(f"生成されたSQL:
{sql_query}")Amazon SageMaker AI のファインチューニング手法
Amazon Bedrock のアプローチはマネージドなトレーニング体験によってモデルのカスタマイズを効率化しますが、より深い最適化制御を求める組織にとっては、SageMaker AI のアプローチが役立つ可能性があります。SageMaker AI は、効率やモデルの性能に大きく影響し得るトレーニングパラメータを幅広く制御できます。速度とメモリ最適化のために バッチサイズ を調整し、過学習を防ぐために層全体にわたって ドロップアウト設定 を微調整し、学習の安定性のために 学習率スケジュール を構成できます。特に LoRA ファインチューニングでは、SageMaker AI を用いて、マルチモーダルデータセットとテキストのみのデータセットに対してそれぞれ最適化した異なる設定で、スケーリング係数や正則化パラメータをカスタマイズできます。さらに、コンテキストウィンドウサイズ と オプティマイザ設定 を、あなたの具体的なユースケースの要件に合わせて調整することもできます。完全なコード例については、以下の ノートブック を参照してください。
1b. データ準備とアップロード
SageMaker AI のファインチューニング手法におけるデータ準備とアップロードのプロセスは、Amazon Bedrock の実装と同一です。どちらのアプローチも、SQL データセットを bedrock-conversation-2024 のスキーマ形式に変換し、データを学習用とテスト用のセットに分割し、JSONL ファイルをそのまま S3 にアップロードします。
# 学習データの S3 プレフィックス
training_input_path = f's3://{sess.default_bucket()}/datasets/nova-sql-context'
# データセットを S3 にアップロード
train_s3_path = sess.upload_data(
path='data/train_dataset.jsonl',
bucket=bucket_name,
key_prefix=training_input_path
)
test_s3_path = sess.upload_data(
path='data/test_dataset.jsonl',
bucket=bucket_name,
key_prefix=training_input_path
)
print(f'学習データのアップロード先: {train_s3_path}')
print(f'テストデータのアップロード先: {test_s3_path}')2b. Amazon SageMaker AI を使用したファインチューニングジョブの作成
モデル ID、レシピ、およびイメージ URI を選択します:
# Nova 設定
model_id = "nova-micro/prod"
recipe = "https://raw.githubusercontent.com/aws/sagemaker-hyperpod-recipes/refs/heads/main/recipes_collection/recipes/fine-tuning/nova/nova_1_0/nova_micro/SFT/nova_micro_1_0_g5_g6_48x_gpu_lora_sft.yaml"
instance_type = "ml.g5.48xlarge"
instance_count = 1
# Nova 固有のイメージ URI
image_uri = f"708977205387.dkr.ecr.{sess.boto_region_name}.amazonaws.com/nova-fine-tune-repo:SM-TJ-SFT-latest"
print(f'Model ID: {model_id}')
print(f'Recipe: {recipe}')
print(f'インスタンスタイプ: {instance_type}')
print(f'インスタンス数: {instance_count}')
print(f'イメージ URI: {image_uri}')カスタム学習レシピの設定
Nova モデルのファインチューニングに Amazon SageMaker AI を使用する際の重要な差別化要因の 1 つは、学習レシピをカスタマイズできることです。レシピは、学習やファインチューニングをすぐに開始できるように AWS が提供する、事前に設定された学習スタックです。Amazon Bedrock の標準的なハイパーパラメータセット(エポック数、バッチサイズ、学習率、ウォームアップステップ)との互換性を維持しつつ、レシピはハイパーパラメータの選択肢を以下のように拡張します:
- 正則化パラメータ: 過学習を防ぐための hidden_dropout、attention_dropout、ffn_dropout。
- オプティマイザ設定: カスタマイズ可能なベータ係数と weight decay 設定。
- アーキテクチャ制御: LoRA 学習のためのアダプタランクとスケーリング係数。
- 高度なスケジューリング: カスタムの学習率スケジュールとウォームアップ戦略。
推奨されるアプローチは、まずデフォルト設定から始めてベースラインを作成し、その後、あなたの具体的なニーズに基づいて最適化することです。以下に、最適化に利用できる追加パラメータの一部の一覧を示します。
| パラメータ | 範囲/制約 | 目的 |
max_length |
1024–8192 | 入力シーケンスの最大コンテキストウィンドウサイズを制御します |
global_batch_size |
16,32,64 | モデルの重みを更新する前に処理されるサンプル数 |
hidden_dropout |
0.0–1.0 | 過学習を防ぐための、隠れ層の状態に対する正則化 |
attention_dropout |
0.0–1.0 | 注意機構(attention)の重みに対する正則化 |
ffn_dropout |
0.0–1.0 | フィードフォワードネットワーク層に対する正則化 |
weight_decay |
0.0–1.0 | モデル重みに対する L2 正則化の強さ |
Adapter_dropout |
0.0–1.0 | LoRA アダプタパラメータに対する正則化 |
使用した完全なレシピは、次の場所にあります 返却形式: {"translated": "翻訳されたHTML"}こちら。
SageMaker AIトレーニングジョブの作成と実行
モデルとレシピを設定した後、ModelTrainer オブジェクトを初期化し、トレーニングを開始します:
from sagemaker.train import ModelTrainer
trainer = ModelTrainer.from_recipe(
training_recipe=recipe,
recipe_overrides=recipe_overrides,
compute=compute_config,
stopping_condition=stopping_condition,
output_data_config=output_config,
role=role,
base_job_name=job_name,
sagemaker_session=sess,
training_image=image_uri
)
# データチャネルを設定
from sagemaker.train.configs import InputData, S3DataSource
train_input = InputData(
channel_name="train",
data_source=S3DataSource(
s3_uri=train_s3_path,
s3_data_type="Converse",
s3_data_distribution_type="FullyReplicated"
)
)
val_input = InputData(
channel_name="val",
data_source=S3DataSource(
s3_uri=test_s3_path,
s3_data_type="Converse",
s3_data_distribution_type="FullyReplicated"
)
)
# トレーニングを開始
training_job = trainer.train(
input_data_config=[train_input,val_input],
wait=False
)トレーニング後、create_custom_model_deployment のAmazon Bedrock APIを通じてAmazon Bedrockにモデルを登録します。これにより、converse APIを使用して、デプロイ済みモデルARN、システムプロンプト、ユーザーメッセージによるオンデマンド推論を有効化できます。
私たちのSageMaker AIトレーニングジョブでは、エポック数2、バッチサイズ64といったデフォルトのレシピパラメータを使用しました。データには20,000行が含まれていたため、トレーニングジョブ全体は4時間かかりました。ml.g5.48xlarge インスタンスを使用した場合、Nova Microモデルのファインチューニングにかかった総コストは65ドルでした。
4. テストと評価
モデルの評価のために、運用面と精度の両方に関するテストを実施しました。精度を評価するために、LLM-as-a-Judgeのアプローチを実装しました。具体的には、微調整済みモデルから質問とSQLレスポンスを収集し、それらを正解レスポンスに対して判定モデルが採点するようにしました。
def get_score(system, user, assistant, generated):
formatted_prompt = (
"あなたはデータサイエンスの教師で、生徒にSQLを教えています。 "
f"次の質問とスキーマを考えてください:"
f"<question>{user}</question>"
f"<schema>{system}</schema>"
"正しい答えは以下のとおりです:"
f"<correct_answer>{assistant}</correct_answer>"
"生徒の回答は以下のとおりです:"
f"<student_answer>{generated}</student_answer>"
"生徒の回答が正しい答えとどれくらい一致しているかを、0から100の数値で評価してください。"
"そのスコアを <SCORE> のXMLタグに入れてください。"
)
_, result = ask_claude(formatted_prompt)
pattern = r'<SCORE>(.*?)</SCORE>'
match = re.search(pattern, result)
return match.group(1) if match else "0"
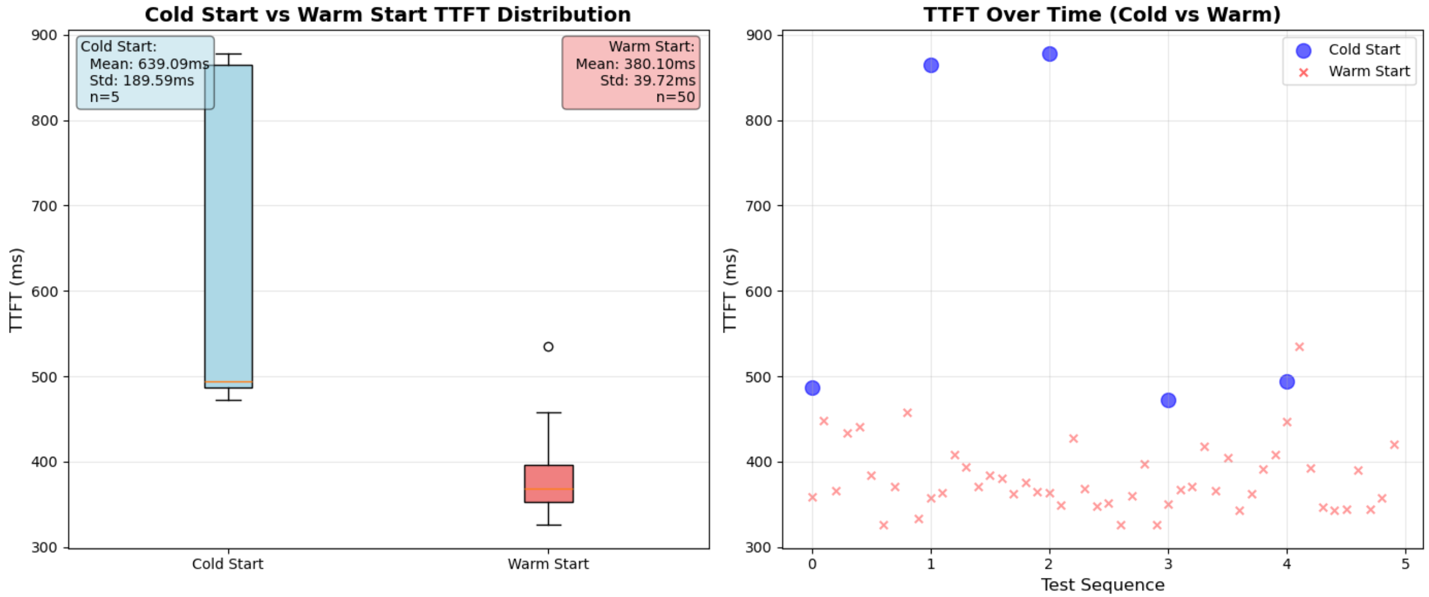
運用テストでは、TTFT(Time to First Token)とOTPS(Output Tokens Per Second)を含む指標を収集しました。ベースのNova Microモデルと比較して、コールドスタートから最初のトークンまでの平均は、5回の実行で639msでした(34%増加)。このレイテンシ増加は、推論時にLoRAアダプタを適用するためであり、モデルの重みにあらかじめ組み込むのではないことに起因します。しかし、この設計上の選択により、ファインチューニング済みのNova Microモデルのコストがベースモデルと同じになるため、大きな費用面のメリットが得られます。これにより、柔軟な従量課金でオンデマンドの価格設定が可能になり、最低コミットメントも不要です。通常の運用では、最初のトークンまでの時間は50回の呼び出しで平均380ms(7%増加)です。エンドツーエンドのレイテンシは、完全な応答生成のために約477msです。トークン生成のレートは1秒あたり約183トークンを維持しており、ベースモデルからの低下は27%にとどまります。これはインタラクティブなアプリケーションにも十分適しています。
コスト概要
一度限りのコスト:
- Amazon Bedrockモデルのトレーニングコスト: 1,000トークンあたり$0.001 × エポック数
- 2,000例、5エポック、各あたり約800トークン = $8.00
- SageMaker AIモデルのトレーニングコスト: ml.g5.48xlargeインスタンスを使用しました。費用は$16.288/時間です
- トレーニングは4時間で、データセットは20,000行 = $65.15
- 継続的なコスト
- ストレージ: カスタムモデルあたり月$1.95
- オンデマンド推論: ベースNova Microと同じ1トークンあたりの価格
- 入力トークン:$0.000035 / 1,000トークン(Amazon Nova Micro)
- 出力トークン:$0.00014 / 1,000トークン(Amazon Nova Micro)
本番ワークロードにおける例の計算:
月あたり22,000件のクエリ(100ユーザー × 1日10クエリ × 22営業日):
- 1クエリあたり平均800入力トークン + 60出力トークン
- 入力コスト:(22,000 × 800 / 1,000)× 0.000035 = 0.616
- 出力コスト:(22,000 × 60 / 1,000)× 0.00014 = 0.184
- 月次の推論コスト合計:0.80 USD
この分析により、カスタム方言のテキストto-SQLユースケースでは、Amazon Bedrock上でPEFT LoRAを用いてNovaモデルをファインチューニングすることは、永続的なインフラ上でカスタムモデルをセルフホストするよりも、はるかにコスト効率が高いことが裏付けられます。セルフホスト型のアプローチは、インフラに対する最大限の制御、セキュリティ設定、統合要件などを必要とするユースケースに適している可能性があります。一方で、Amazon Bedrockのオンデマンドのコストモデルは、ほとんどの本番テキストto-SQLワークロードに対して大幅なコスト削減を提供します。
結論
これらの実装オプションは、Amazon Novaのファインチューニングを組織のニーズや技術要件に合わせてどのように調整できるかを示しています。私たちは、異なる対象者とユースケースに対応する2つの異なるアプローチを検討しました。Amazon Bedrockのマネージドなシンプルさを選ぶ場合でも、SageMaker AIトレーニングによるより高い制御を選ぶ場合でも、サーバーレスのデプロイメントモデルとオンデマンドの価格設定により、使った分だけ支払うことができ、インフラ管理を取り除けます。
Amazon Bedrockモデルのカスタマイズ のアプローチは、インフラの複雑さを排除し、合理化されたマネージドソリューションを提供します。データサイエンティストは、トレーニングインフラを管理することなく、データの準備とモデル評価に集中できるため、素早い実験や開発に最適です。
SageMaker AI トレーニング のアプローチは、微調整プロセスのあらゆる側面をより細かく制御できるようにします。機械学習(ML)エンジニアは、トレーニングパラメータのきめ細かな制御、インフラストラクチャの選択、既存の MLOps ワークフローとの統合により、必要なパフォーマンス、コスト、運用要件に最適化できます。たとえば、バッチサイズやインスタンスタイプを調整してトレーニング速度を最適化したり、学習率や LoRA パラメータを変更して、特定の運用ニーズに基づきモデルの品質とトレーニング時間のバランスを取ることができます
Amazon Bedrock のモデルカスタマイズを選ぶべきとき:迅速な反復が必要な場合、ML インフラストラクチャの専門知識が限られている場合、またはカスタムモデルのパフォーマンスを実現しつつ運用上の負担を最小限にしたい場合。
SageMaker AI トレーニングを選ぶべきとき:きめ細かなパラメータ制御が必要な場合、特定のインフラストラクチャ要件やコンプライアンス要件がある場合、既存の MLOps パイプラインとの統合が必要な場合、またはトレーニングプロセスのあらゆる側面を最適化したい場合。
はじめに
独自のコスト効率の良いテキストから SQL へのソリューションを構築する準備はできましたか?完全な実装にアクセスしてください:
- Bedrock ファインチューニングノートブック:マネージドで合理化されたアプローチ
- SageMaker AI ファインチューニングノートブック:高度なカスタマイズと制御
どちらのアプローチも同じコスト効率の良いデプロイモデルを使用するため、コスト制約ではなく、チームの専門性や要件に基づいて選択できます。

