親愛なる皆さん、
AIネイティブのソフトウェアエンジニアリングチームは、従来型のチームとは非常に異なる動き方をします。明らかな違いは、AIネイティブのチームがコーディングエージェントを使ってプロダクトをより速く作れることですが、それは同時に、私たちの運用方法における他の多くの変化も引き起こします。たとえば、優秀なエンジニアの中には、いまやコードを書くことだけにとどまらず、より幅広い役割を担う人がいます。彼らは部分的にプロダクトマネージャーであり、デザイナーであり、ときにはマーケターでもあります。さらに、同じオフィスで働く小規模チームは、対面でコミュニケーションできるため、信じられないほど速く動けます。
いまや高速に構築できるようになったことで、作るべきものを決める時間の比率が、より大きくならざるを得ません。この プロジェクト管理のボトルネックに対処するために、いくつかのチームでは、エンジニア:プロダクトマネージャー(PM)の比率を下げています。たとえば8:1から、1:1程度までに。ですが、さらに良い方法もあります。つまり、何を作るかを決めるPMが1人いて、実際にそれを作るエンジニアが1人いるなら、その2者間のコミュニケーションがボトルネックになります。これが、私が見てきた中でも最も素早く動くチームには、いくつかのプロダクト業務ができるエンジニア(そして、オプションとして、いくつかのエンジニアリング業務ができるPM)がいる傾向がある理由です。エンジニアがユーザーを理解し、何を作るかの判断を下せて、しかもそれを直接実装できるなら、驚くほど速く実行できます。
私は、エンジニアが自分の役割をうまく拡張してプロダクトの意思決定も含めるのを見てきましたし、PMが自分の役割を拡張してソフトウェアを作るようになるのも見てきました。技術業界にはPMよりもエンジニアの方が多いですが、どちらも有望な道です。あなたがエンジニアなら、プロダクトマネジメントのスキルをいくつか学ぶのが役に立つでしょう。あなたがPMなら、ぜひ作ることを学んでください!
プロダクトマネジメントのボトルネックを越えて見ると、デザイン、マーケティング、法務コンプライアンスなどにもボトルネックがあると私は考えています。コーディングを10倍、100倍に速めると、他のすべてが相対的に遅くなります。たとえば、ある私のチームは非常に速く素晴らしい機能を作ったため、マーケティング組織が、ユーザーにどう伝えるかを慌てて考える羽目になりました。これはマーケティングのボトルネックです。あるいは、あるチームが1日でソフトウェアを作れる一方で、法務部門がレビューに1週間必要だった、という場合もあります。これは法務コンプライアンスのボトルネックです。このように、エージェントによるコーディングは、ソフトウェアエンジニアリングのワークフローを変えるだけでなく、その周りにいるあらゆるチームのあり方も変えているのです。

小規模で、AIを活用できるチームがより多くのことを成し遂げられるなら、ゼネラリストが活躍します。従来の会社では、エンジニアリング、プロダクトマネジメント、デザイン、マーケティング、法務など、さまざまな専門分野の人を集めてプロジェクトを実行し、価値を生み出す必要があります。その結果、共同で働く大きな専門家チームが生まれました。しかし、2人のチームで5つの異なる専門分野が必要な仕事を進めるなら、その人たちの一部は、単一の専門分野の枠を超えた役割を担わなければなりません。いくつかの小さなチームでは、個々人に深い専門性があります。たとえば、ある人はとても優秀なエンジニアで、別の人はとても優秀なPM、ということもあります。しかし同時に、プロジェクトを前に進めるために必要な他の主要な機能も理解しており、必要に応じて他の種類の問題を考えることにも飛び込めます。もちろん、AIツールの扱いに習熟していることは大きな助けになります。というのも、異なる役割を含む問題を考えるのに役立つからです。
2人のチームであっても、速く進めるには、コミュニケーションのボトルネックを最小化しなければなりません。だからこそ私は、同じ場所で働くチームを大切にしています。リモートチームでもうまく機能することはありますが、最も高いスピードが出るのは、全員が同じ部屋にいて、問題を解決するために即座にコミュニケーションできる場合です。
この手紙は、人数がだいたい2〜10人程度のAIネイティブチームに焦点を当てていますが、小さなチームだけでできることには限りがあります。大規模チームの調整については、将来お話しします。
こうした職務の変化は、多くの人にとって乗り越えるのが大変だということは分かっています。その一方で、関連するスキルを学ぶことに前向きな個人や小さなチームが、以前は不可能だった以上に多くのことを成し遂げられるようになってきていることには勇気づけられています。これは学びそしてつくるための“黄金時代”です!
引き続き作り続けてください、
Andrew
DEEPLEARNING.AIからのメッセージ

『Spec-Driven Development』では、コーディングエージェントを使うための規律あるワークフローを学びます。仕様を書き、実装を段階的に導き、そして自分が作るもののコントロールを保ち続けましょう! 無料で参加する
News
Life After Llama
Metaは、オープンウェイトの 戦略から転換し、クローズドな代替手段を提供することになりました。
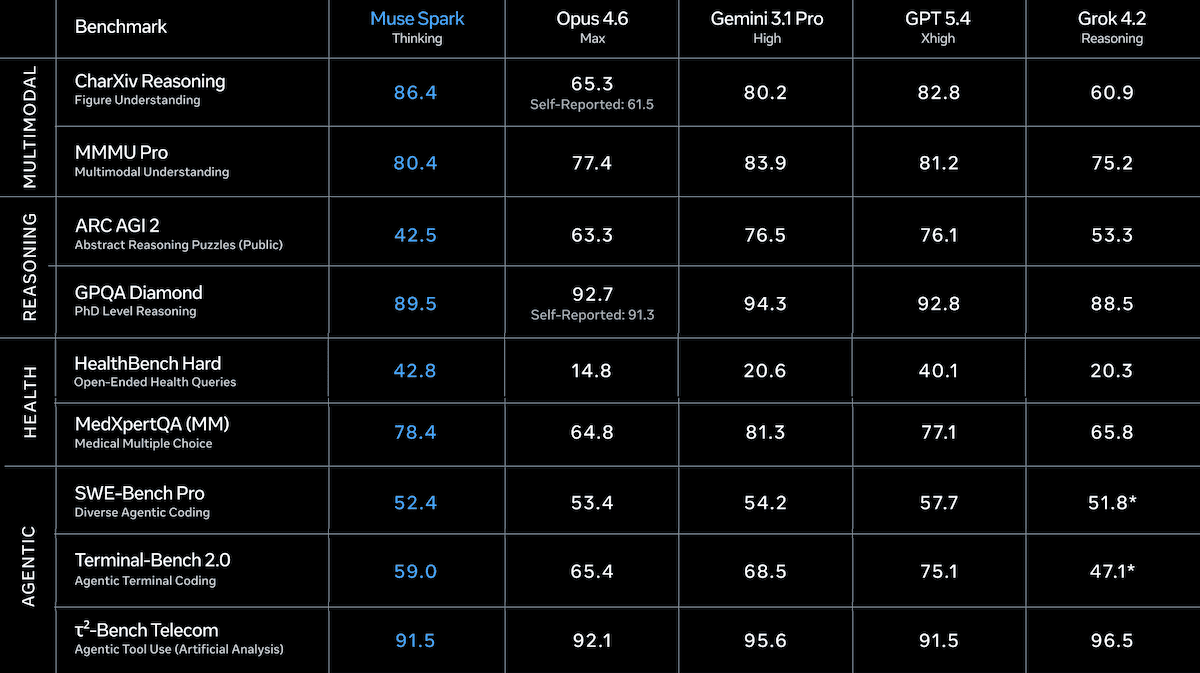
新着情報: Metaは、1年ぶりに、そして9か月前に設立されたSuperintelligence Labsの最初のプロダクトとして、最初のAIモデルを発表しました。Muse Sparkは、ツールの利用とマルチエージェントのオーケストレーションをサポートする、ネイティブにマルチモーダルな推論モデルです。いくつかのヘルスおよびマルチモーダルのベンチマークではトップクラスですが、コーディングやエージェント的な作業では不足があり、Metaはこれを、同社がより大きなモデルの構築に向けて計画している「アーキテクチャ再設計の妥当性を検証する」ものだと位置づけています。
- 入出力: 入力はテキスト、画像、音声(最大262,000トークンまで)、出力はテキスト
- 性能: Artificial Analysis Intelligence Indexで4位
- 利用可能性: meta.ai およびMeta AIアプリで無料。WhatsApp、Instagram、Facebook、Messenger、Ray-Ban Meta AIグラスに順次提供。APIプレビューは選定パートナー向け
- 機能: 3つの推論モード(instant、thinking、contemplating)、ショッピングモード
- 未公開: パラメータ数、アーキテクチャ、学習データと手法、出力サイズ上限
仕組み: MetaはMuse Sparkについて限定的な技術詳細のみを開示しましたが、訓練効率とマルチエージェントのオーケストレーションにおける改善、ならびにヘルス領域に特化した投資の成果を強調しました。
- 同社は事前学習のアプローチ、モデルのアーキテクチャ、最適化、データキュレーションを見直しました。Metaによると、Muse Sparkは学習に投下する処理が1桁以上少ないにもかかわらず、Llama 4 Maverickの能力に匹敵します。
- 事後学習では強化学習を行い、チームは推論トークンを過剰に使った場合にモデルへ罰を与えました。チームはこのプロセスを「思考圧縮」と呼んでいます。この罰のもとで、モデルはまずより長く推論することで改善し、その後推論を圧縮することを学び、さらに推論を拡張してさらなる改善を行いました。
- 単一の「思考の連鎖」を処理するのではなく、contemplatingモードでは複数のエージェントを起動し、複数の解決案を提案させ、それらを洗練させ、結果を並列に集約します。Metaは、これにより遅延を同程度に抑えつつ、より良い性能が得られるとしています。
- ヘルス領域の推論を改善するために、Metaは1,000人超の医師を動員し、より正確で徹底的なヘルス回答の生成を目的とした学習データのキュレーションを支援してもらいました。
結果: Muse Sparkのベンチマーク性能は概ね競争力があり、特にトークン効率に優れています。Metaは、コーディングとエージェント的な性能にギャップがあることを認めています。
- Artificial Analysis Intelligence Index(経済的に有用なタスク10個の複合指標)で、Muse Sparkは推論モード(52)に設定した場合、総合で4位となり、3位タイのGemini 3.1 Pro Preview(高推論に設定、57)およびGPT-5.4(xhigh推論に設定、57)に次ぐ形でした。またClaude Opus 4.6(max推論、53)も3位タイに含まれます。Muse Sparkはこのインデックス完了に約5,900万トークンを使用しましたが、Claude Opus 4.6は約1億5,800万トークン、GPT-5.4は1億1,600万トークンでした。
- 少なくとも1つのマルチモーダルベンチマークでMuse Sparkは最高評価を獲得しています。CharXiv Reasoning(図表の理解と推論)では、MetaによるとMuse Spark(86.4%)がGPT-5.4(82.8%)およびGemini 3.1 Pro(80.2%)を上回りました。MMMU Pro(多分野にまたがる視覚的課題の解決)では、Artificial AnalysisによるとMuse Spark(81%)がGemini 3.1 Pro(82%)に次いで2位でした。
- Artificial AnalysisのCoding Index(コーディングベンチマークの加重平均)では、Muse Spark(47)はGPT-5.4(57)、Gemini 3.1 Pro Preview(56)、およびmax推論に設定されたClaude Sonnet 4.6(51)に遅れを取りました。
- Artificial Analysisが独自に 測定 したところ、Muse SparkはThinkingモードでHumanity’s Last Examの39.9%でした。Gemini 3.1 Pro Preview(44.7%)やGPT-5.4(41.6%)に後れを取っています。しかしMetaの報告では、Muse Sparkがcontemplatingモードを使用した場合は58%です。
- Metaのテストでは、Muse SparkはOpenAIのヘルスベンチマークの一部であるHealthBench Hardで、他のすべてのモデルを上回りました(42.8%)。2番手のGPT-5.4(40.1%)を上回っています。さらにMuse Sparkは、エージェントによるブラウジング評価であるDeepSearchQAでも74.8%を達成し、Claude Opus 4.6 Max(73.7%)に先行しました。
その背景: Muse Sparkは、Metaが AIラボを再編 していたの以来の、Metaとしての初の新しいモデルです。これは、批評家が「Llama 4の学習データがベンチマークの回答で汚染されていた」と主張したことを受けた動きでした。2025年6月、MetaはScale AIの49%の持分を得るために143億ドルを投じ、共同創業者のAlexandr Wangを最高AI責任者として迎え、数億ドル規模の報酬パッケージを伴う採用ラッシュも開始しました。プロプライエタリ(非公開)のリリースは、開発者の間で懸念を呼んでおり、その多くはオープンウェイトのLlamaモデル上にプロジェクトを構築してきました。
重要な点: Metaは、自社のプロダクト構想において最も重要な能力への投資を進めています。具体的には、数十億規模のカメラ搭載ユーザー向けのマルチモーダル知覚、AI照会の中でも最も一般的なカテゴリの一つに対するヘルス領域の推論、そして複数ステップのタスクに対するマルチエージェントの連携です。非公開のAPIプレビューが進行中であることから、同社はOpenAI、Google、Anthropicと並んでビジネス顧客の獲得競争に参入する姿勢を示しています。ただし、同社が「オープンウェイトの領域における米国のトップ・チャンピオン」であることから転換したことは、開発者コミュニティにとって大きな損失です。
考察: Muse Sparkのcontemplatingモードと Kimi K2.5の Agent Swarmは、次のような新たなパターンを示しています。複数のラボが、より大きな単一モデルをひたすら学習するのではなく、推論時に複数のエージェントをオーケストレートするためにモデルの性能をスケールさせるべく、学習によって性能向上を図っています。
ビッグファーマはAIに大きく賭ける
生成AIは、テキスト、画像、音声、動画、コードを生成できることを証明してきました。世界で最も価値の高い製薬会社は、同様に「薬」も生成できると信じて数十億ドルを投じようとしています。
何が新しいのか: 製薬大手のエリ・リリー は 香港を拠点とするバイオテクノロジー企業インシリコ・メディスンに、最大で27.5億ドル(約275億ドルではなく、$2.75 billion)を拠出することに合意したと報じられました。同社は生成AIを創薬パイプライン全体に適用しています。最初にリリーは、これまで人で試験されていない未公開の薬を開発・販売するための独占権として1億1500万ドルを支払います。一方、追加の支払いは、開発・規制・商業上のマイルストーンに連動します, Fierce Biotech と されています。これは、2023年のAIソフトウェアのライセンス契約と、2025年11月の1億ドル規模の研究協力に続く、両社にとって3件目の合意です。
AI創薬: 2014年に設立されたインシリコは、AIを使って 28件の候補薬 を開発してきました。これらのうち約半数は臨床試験段階にあります。最も進んでいるもの、レントソルチブ(Rentosertib)は、進行性に瘢痕化が進み肺機能を低下させる疾患である特発性肺線維症(IPF)を標的としています。第2a相試験(有効性を早期・小規模に検証する試験)で 肯定的な結果 が示されました。第2の薬であるガルタデスタット(Garutadustat)は炎症性腸疾患の治療を目的としており、 2026年1月に第2a相へ入った ところです。
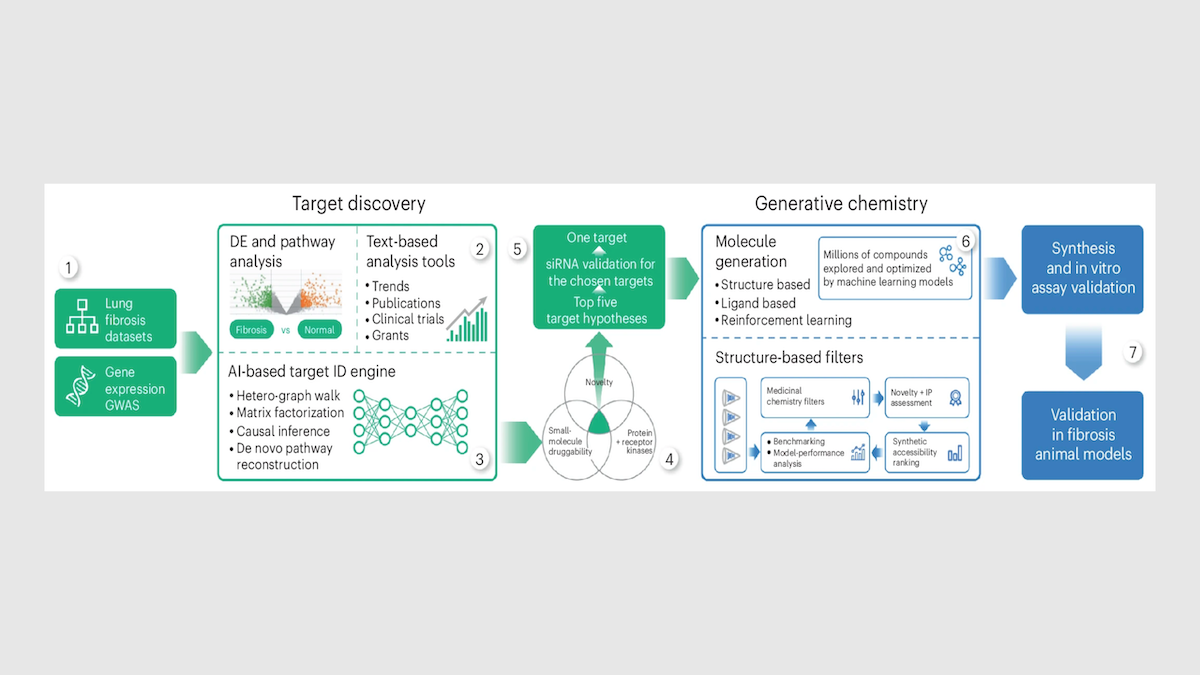
仕組み: 疾患を選ぶと、インシリコは 独自の生成モデルを 創薬の2つの段階、すなわち「どのタンパク質を標的にするかの特定」と「そのタンパク質に作用する分子の設計」に適用します。
- 標的を見つけるために、インシリコはPandaOmicsというツールを使い、生物学的データセット、公開研究、特許、臨床試験、助成金申請などを分析します。深層学習モデルは、疾患との関連性、創薬標的としての適性、そして新規性にもとづいて候補標的を順位付けします。IPFについてPandaOmicsは、IPFや関連疾患の特徴である瘢痕化に関与するTNIKを、最有力候補として見いだしました。TNIKを阻害することでIPFを治療しようとした例は、それまで誰もありませんでした。
- TNIKを阻害する分子を設計するために、チームはChemistry42を使用しました。約30の生成モデルが並行して動き、候補となる分子構造を生成します。各モデルは、結合の強さ、毒性、溶解性、その他の特性に最適化されています。研究者は複数ラウンドにわたって出力を評価し、改良しました。インシリコが80未満の化合物を合成してテストした結果、リード分子が得られました。従来の創薬では、チームはしばしば合成・試験を行う前に、既存の化合物を20万〜100万件スクリーニングします。
- 標的を特定してから、前臨床の安全性試験に投入できる分子を合成するまでに要した時間は、約 18か月 で、通常の 5〜6年 に比べて短縮されています。このスピードは、2021年から2024年の間にある20以上のインシリコのプログラムで一貫して維持されました。各プログラムでは、前臨床候補を見つけるために、およそ60〜200の分子を合成・試験しています。
背景: 新しい薬の開発は通常、10〜15年かかり、そして 費用 は20億ドル以上になりがちです。さらに、候補の約86%は 承認 に到達しません。創薬開発者の間で、AIを活用してプロセスを加速する取り組みが増えています。査読付き分析では、2025年半ば時点で臨床段階にある173のAI活用創薬プログラムが 整理されて います。それでも、AIによって発見された薬で規制当局の承認を受けたものはありません。第2相に到達した薬候補については、70%が次の段階に進めず、これには BenevolentAI や Recursion Pharmaceuticals によるAI設計の薬も含まれます。
重要な理由: Insilicoのパイプラインは、生成AIが科学における最も難しい問題の1つに取り組める可能性を示しています。すなわち、特定のタンパク質に結合し、体内に吸収され、有毒ではなく、患者を助ける分子を見つけることです。レンソテルビブ(Rentosertib)の第2a相試験では、最高用量を服用した参加者は、強制肺活量(肺機能の指標)で平均98.4ミリリットル増加したのに対し、プラセボを服用した参加者は20.3ミリリットル減少しました。これは早期のものではありますが、AIが生成した薬が患者の助けになり得るという具体的な証拠です。
私たちの見立て: AIは創薬開発を加速していますが、そうした加速された化合物が、従来の方法で開発されたものより高い割合で臨床試験を通過するかどうかは、まだ分かりません。
米国の州がAIの法律を前進させる
トランプ大統領が、全国法のために州ごとの立法を控えるよう促したにもかかわらず、米国の州はAIを規制する法律の制定を継続しています。
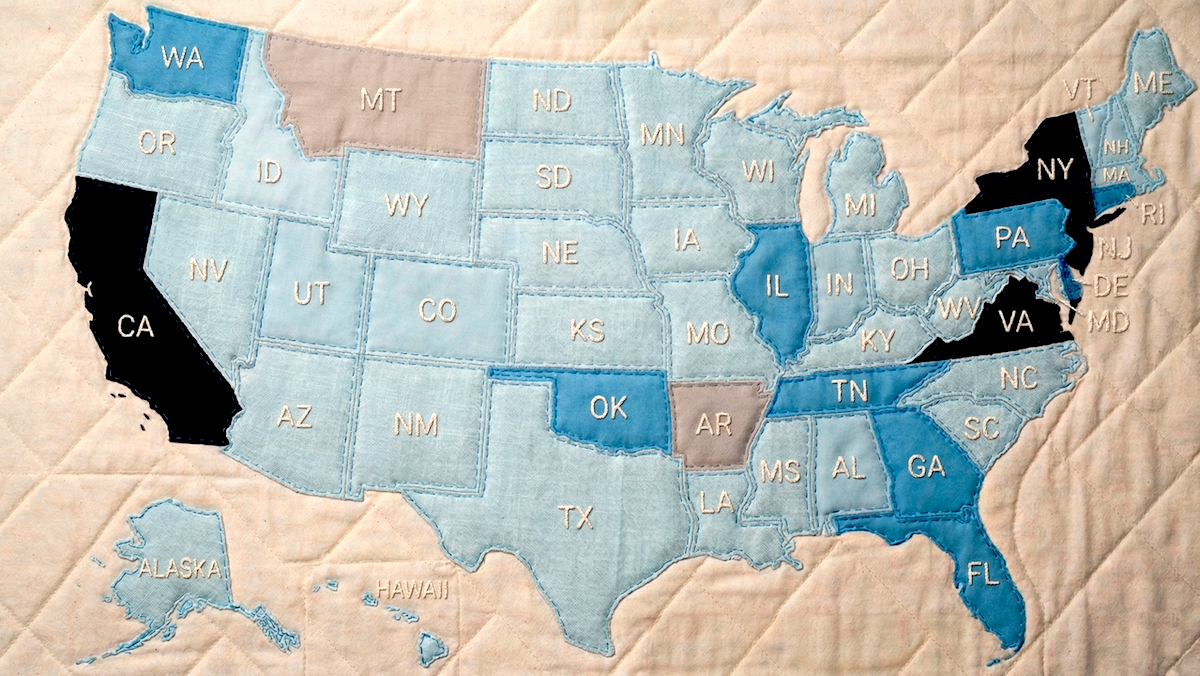
新たな動き: 今年、多くの州がAIを規制するために動き、開発者が法的要件を満たす取り組みを複雑にしかねない、拡大する寄せ集め(パッチワーク)状の立法につながっています。州をまとめると、数多くの法案を検討しており、ある 集計 では1,500件超にのぼるとのことです。これはさらに、40州がすでに制定した100件超の既存法に加えての話で、若者によるチャットボットの利用を抑制すること、著作権のある素材でAIシステムを学習するには許可が必要であること、あるいはAIシステムのセキュリティテストを義務づけることなどを目的にしています。 ニューヨーク・タイムズ 報じました。
仕組み: カリフォルニア州のギャビン・ニューサム(Gavin Newsom)州知事は、AIを州ごとに規制する取り組みを抑えるようにとのトランプ政権の主張に対して、最も目立つ反対者でした。しかし、40以上の州が自分たちの法律を可決する手続きを進めています。その中には次のようなものがあります。
- カリフォルニア。米国およびそれ以外での規制の先行指標となることが多いカリフォルニアは、国内で最も包括的なAIの法律を定めました。3月30日、ニューサム州知事は、州が利用するAIツールについて、プライバシーを保護し、公民の権利を支援し、バイアスを軽減することを求める大統領令(行政命令) を発出しました。8月から、大規模なテックプラットフォームとAI提供事業者は、AIが生成した出力に目に見えない水印 を適用しなければなりません。これらの規定は、1月に施行されたさまざまな法律に加わるものです。たとえば、高度なAIモデルの開発者は、壊滅的なリスクを評価し、重大な安全上のインシデントを報告しなければなりません。LLM提供事業者は、チャットボットが未成年との自傷や性に関する話題を扱うことを防ぎ、ユーザーがAIと会話しているときには定期的にそれを思い出させる必要があります。
- コロラド。2024年、コロラドは、この地域の中でも最も厳格な規制の一部を盛り込んだ、包括的なAI法を可決しました。7月に施行される予定のこの法律は、「高リスクAIシステムの開発者および提供者」に対し、教育、雇用、金融、医療、住宅といった、重大な局面での意思決定を行うよう設計されたシステムによる、アルゴリズム上の差別から消費者を守ることを求めています。開発者はシステムの制約、学習データ、リスクを軽減する取り組みを文書化しなければならず、一方でモデルを実際に展開する側は、その影響を毎年評価し、AIが自分たちに影響する判断を行う場合は消費者に警告しなければなりません。ただし、企業やテック企業からの圧力により、州の下院(議会)は、年次の影響評価やその他の負担に関する要件を緩和することも検討しています。
- ミネソタ。ミネソタは2023年の早い段階で、ディープフェイクによる選挙への妨害を禁止しました。現在、議会は、AIを使って人物の写真から服を取り除くこと、または個人の行動に基づいて価格を動的に設定することを禁じる法案を検討しています。8月には、 医師の関連する審査なしに 医療保険会社がケアを拒否するためにAIを使うことを禁止する法律が施行されます。
- ニューヨーク。この州は、ディープフェイクに対する早期の保護から始まり、2026年にはさらに広範な制限まで、国内でも最も厳格なAI規制の一部を整備してきました。2027年1月から、売上が5億ドルを超えるモデル製作者は、生物兵器や自律型のハッキングツールをユーザーが作成できないようにするための厳格な手順を守らなければなりません。これらの取り組みについては、毎年監査し、インシデントが発生した場合には速やかに報告する必要があります。
- オハイオ。3月下旬に施行された法律は、許可なく製品を販売したり、親密な画像を作成したりするために、人の声や容姿を複製することを目的としたAIの使用を禁止しています。オハイオは、配偶者、マネージャー、または所有者(不動産の持ち主)の役割において、AIシステムに法的人格や法的権利を与えないことを定める法案を検討しています。また、競合他社との間で小売価格や賃貸価格を調整する目的でAIを使うことを禁止することも検討しています。
- ユタ。2026年だけでも、ユタ州議会は2024年の「人工知能ポリシー法」を見直し洗練させる複数の法案を可決しています。たとえば、今後数か月以内に施行予定の法案では、プラットフォーム企業が同意のない、性的に露骨なディープフェイクを配布することを禁じています。別の法案では、医療保険会社が医師の関与なしにAIを使ってケアを拒否することを禁止しています。この州では、AI企業が規制当局の監督下で新技術をテストしている間、一定の規制について一時的な救済を申請できるようにしています。
ニュースの裏側: トランプ政権は、州ごとの寄せ集めの規制が米国のAIにおけるリーダーシップを妨げるのではないかという懸念が高まる中で、州法よりも国の規制を推進し始めました。12月、トランプ大統領は、州レベルの立法を抑制することを目的とした行政命令に署名しました。この命令は、イノベーションを阻害するような法律だけでなく、政治的な偏りがあると受け取られ得る反バイアス規制も対象としています。「重荷(onerous)」のAI法を可決または施行した州から連邦資金を差し控えると脅し、連邦議会に対して州の規制を阻止するよう求めています。3月には続いて、 連邦立法のためのガイドライン を発表しました。このガイドラインは、子どもの保護と、AIデータセンターのエネルギー消費増加によって引き起こされる電気料金の値上げを抑制する措置を支援するものです。
重要な理由: AIをめぐる規制環境がますます複雑になることで、米国ではコンプライアンスに関する潜在的な地雷原が生まれ、世界的にも焦点が定まらず矛盾する規制が生まれる一因となっています。あるAIモデルは、たとえばコロラドではバイアス監査に合格することが求められ、カリフォルニアでは透かし(ウォーターマーキング)を提供しなければならず、さらにニューヨークでは報告の閾値を満たす必要があるかもしれません――その一方で、連邦政府はこれらの要件を先取り(事前に無効化)しようと動いています。管轄をめぐるこうした綱引きは、AIシステムを構築するコストを押し上げ、新しいアプリケーションやサービスを導入する際の法的リスクを増大させ、また、州の義務に従うために連邦政府が「重荷」とみなす場合、政府資金が差し控えられる可能性を高めます。
私たちの見立て: 現在の州レベルの義務の中には、妥当なものもあります。たとえば、ユーザーはAI企業が自分たちのプライバシーを守り続けることに頼れるべきですし、子どもは、大人のために、また大人によって生成されたAIの“手抜きコンテンツ”から保護されるべきです。しかし、このような要件は全国レベルで課されるべきです。私たちは、 連邦議会に対して、より一貫性があり安定した規制環境を構築するよう求めます。
多様な人間の集団をシミュレートする
人々があなたの提供内容にどのように反応するかを理解したい場合、大規模言語モデルは、能力、機能、プロモーション、価格について質問に答えるユーザーをシミュレートできます。しかし、LLMは人間が示すような幅広いバリエーションの形で応答しません。研究者たちは、LLMに対して、カスタマイズ可能なさまざまな態度を持つペルソナを担わせるよう促す方法を開発しました。
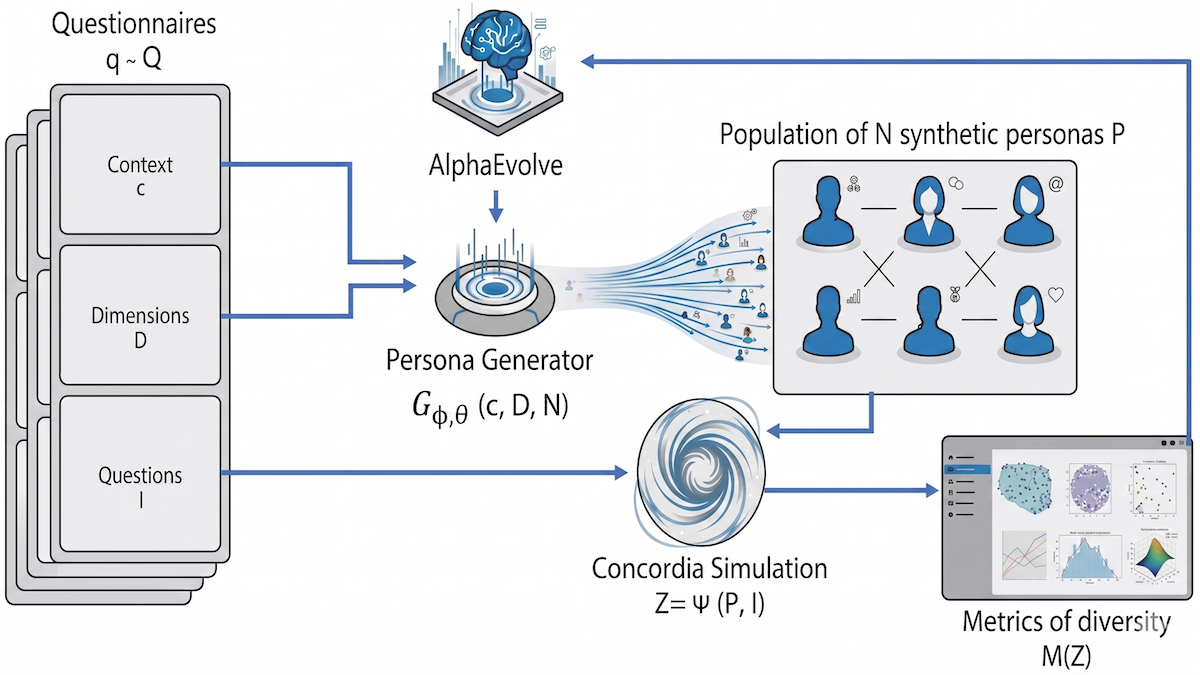
新しい点: Davide Paglieri、Logan Cross、そしてGoogleの同僚たちは Persona Generators(ペルソナ生成器) を提案しました。このアプローチでは、地図(想定領域)をカバーする25のペルソナに対して、LLMがプロンプトを作成するよう促すコードが生成されます。
重要な洞察: LLMに人間のペルソナを担わせることは、通常は効果的なプロンプトを組み立てること(たとえば「次の質問に、今日の政治の中にいるつもりで答えてください。あなたは自分が民主党員だと考えている……」のように)で済みます。ところがこの手法では、たとえプロンプトが LLMに特定の人口統計学的特性を採用するよう明示的に指示していても、人間集団が提供する範囲を反映しない平均的な応答が引き出されがちです。代替としては、モデルに対してペルソナのプロンプトをプログラム的に修正するよう指示し、意見、態度、 あるいは懸念の特定の範囲をカバーする出力が得られるまで繰り返す方法があります。ペルソナ集団の範囲(具体的には、不同意と同意の度合いにもとづく態度の順位付け)を定義するガイドラインがある場合、進化的アルゴリズムによって、モデルは応答の全範囲を引き出す一連のプロンプトを生成するよう促され得ます。
仕組み: 著者らは進化的手法 AlphaEvolve を使って、(i) ペルソナ用の25個のプロンプトを生成し、(ii) 生成した質問票への回答に基づいて、その態度の多様性を最大化する、というコードを生成しました。
- 著者らはまず Gemini 2.5 Pro を使い、医療、金融リテラシー、陰謀論などさまざまな領域に関する30の質問票を生成しました。各質問票には、文脈(トピックの説明)、一連の「多様性の軸」(リスクへの許容度や制度への信頼など)、そして1(強く同意)から5(強く反対)までの尺度で回答するための、軸に関連する質問が含まれていました。
- 彼らは、質問票ごとに25個のペルソナ・プロンプトを生成するためのコードを作成しました(当初は著者らが書き、その後AlphaEvolveによって反復的に更新しました)。
- ペルソナの回答の生成を自動化するため、著者らはエージェントベースのシミュレーションを構築するライブラリであるConcordiaを使ってGemma 3-27B-ITにプロンプトを与えました。LLMは順番に各ペルソナを採用し、対応する質問票に回答しました。各ペルソナについて、彼らはその回答をベクトルに変換しました。
- 各質問票に回答したペルソナ間の多様性を評価するために、彼らは、任意の2つのベクトル間の平均距離や、ペルソナ集団が考え得るすべての応答をどの程度カバーしているかといった、6つの指標を計算しました。
- AlphaEvolveは、10種類のコードの異なるバージョンに対して並列に動作し、すべてのペルソナにわたって多様性指標を最大化するように、反復的に更新していきました。500回の反復の後、著者らは、全ての多様性指標の平均を最大化するコードを選びました。
- 推論時には、文脈と多様性の軸のセットが与えられると、システムは25の多様なペルソナを作成します。
結果: 新しいコンテキストと多様性の軸を与えた場合、得られたペルソナは一貫して、Nemotron Personas(米国の人口統計に基づくペルソナプロンプトの大規模データセット)および、幼少期から成人期までの生成された記憶に基づくConcordia memory generatorが生成するペルソナプロンプトの多様性指標を上回りました。テスト用の質問票のセットを用いたところ、著者らのペルソナは考え得る回答の82%をカバーし、Nemotron Personasは76%、Concordia memory generatorは46%をカバーしました。
重要な理由: 視聴者(オーディエンス)を拡大しようとする組織は、世間の志向を幅広く反映する合成ペルソナの恩恵を受けられます。また、実世界のオーディエンスに合わせるために合成ペルソナを作成する組織は、より多様な集団から得られる洞察を活用できます。この取り組みは、「(最も可能性の高い出力を生成しがちで、外れ値を生成しない)学習データと一致させること」という目的を、望まれるあらゆる可能性をカバーすることへと切り替えます。個々のペルソナではなくペルソナ生成器を最適化することで、見込みのあるユーザー行動のより広い表現が開けます。
私たちの考え: 合成ペルソナは、プロダクトマネジメントのボトルネックを乗り越えるための、興味深い可能性を提供します。LLMにプロンプトを出せば簡単に作れてしまう状況では、何を作るべきかを決める難しさが問題になりますが、この解決に合成ペルソナが役立つかもしれません。



