親愛なる皆さん、
コーディングエージェントは、ソフトウェアのさまざまな作業を、程度の違う形で加速させています。チームの設計をするときに、こうした違いを理解しておくと、現実的な期待値を持てます。最も加速されるものから最も加速されないものへと並べると、私の順番はフロントエンド開発、バックエンド、インフラストラクチャ、研究です。
フロントエンド開発 — たとえば、ECサイトで商品説明を表示するためのウェブページを作ること — は、劇的に速くなります。というのも、コーディングエージェントは、TypeScriptやJavaScriptのような人気のフロントエンド言語、そしてReactやAngularのようなフレームワークに精通しているからです。さらに、ウェブブラウザを操作して彼らが作ったものを見られるため、コーディングエージェントはループを閉じて自分の実装を反復することが、今ではかなり得意になっています。もちろん、今日のLLMは視覚デザインがまだ弱いものの、デザインが与えられている(あるいは洗練されたデザインが重要でない)なら、実装は速いのです!
バックエンド開発 — たとえば、商品データを要求するクエリに応答するAPIを作ること — は、より難しいです。現代のモデルに、人がコーナーケースまで考え抜くよう導くには、細かなバグやセキュリティ上の欠陥につながり得る点を見通すために、人間の開発者の追加作業がより必要になります。さらに、バックエンドのバグは、たとえばデータベースが破損してときどき誤った結果が返る、といった直感的ではない下流の影響を引き起こし得ます。これは典型的なフロントエンドのバグよりデバッグが難しくなることがあります。最後に、データベースのマイグレーションはコーディングエージェントで多少は簡単になりますが、それでも難しく、データの損失を防ぐために慎重に扱う必要があります。コーディングエージェントによるバックエンド開発のスピードは大幅に上がりますが、その加速幅はフロントエンドほどではありません。また、熟練した開発者は、コーディングエージェントを使う初心者よりも、ずっと質の高いバックエンドを設計し実装します。
インフラストラクチャ。 エージェントは、ECサイトをアクティブユーザー1万人規模にスケールしつつ、99.99%の信頼性を維持するようなタスクでは、さらに効果が低くなります。LLMの知識は、インフラストラクチャと、優れたエンジニアが行わねばならない複雑なトレードオフに関しては、まだ比較的限られているため、私は重要なインフラの意思決定では、彼らをほとんど信用しません。質の高いインフラを構築するには、多くの場合テストと試行錯誤の期間が必要で、コーディングエージェントはそれを手伝えますが、最終的には、そこが大きなボトルネックであり、高速なAIコーディングがあまり役に立ちません。最後に、インフラのバグの発見—たとえば微妙なネットワーク設定の誤り—は非常に難しく、深いエンジニアリングの専門知識を要します。したがって私の経験では、コーディングエージェントが加速する重要なインフラは、バックエンド開発よりもさらに少ないです。

研究。コーディングエージェントによる研究の加速は、さらに少ないです。研究には、新しいアイデアを考えること、仮説を立てること、実験を行うこと、仮説を修正する可能性があるかどうか解釈すること、そして結論に到達するまで反復することが含まれます。コーディングエージェントは、研究コードを書くためのスピードを高めることができます。(また、私はコーディングエージェントを使って実験の段取りを組み立て、状況を把握するのにも役立てています。これにより、単一の研究者がより多くの実験を管理しやすくなります。)とはいえ、研究にはコーディング以外の作業がたくさんあり、今日のエージェントは研究をわずかに助けるにとどまっています。
ソフトウェアの作業をフロントエンド、バックエンド、インフラ、研究に分類するのは、極端な単純化です。しかし、さまざまなタスクがどれくらい加速したのかを表すシンプルな頭のモデルを持てると、ソフトウェアチームの組み立て方の参考になります。たとえば私は今、フロントエンドチームには、去年よりも劇的に速くプロダクトを実装することを求めていますが、研究チームに対する期待は、ほとんど同じだけは変わっていません。
スピードを実現するためにコーディングエージェントを活用できるよう、ソフトウェアチームをどう組織するべきかには興味が尽きません。今後のレターでも、私の調査結果を共有し続けます。
作り続けよう!
Andrew
DEEPLEARNING.AIからのメッセージ

「Building Multimodal Data Pipelines」では、画像・音声・動画をエンドツーエンドで扱うパイプラインの作り方を学びます。非構造化データを、クエリできる形に変換します。無料で登録する
ニュース
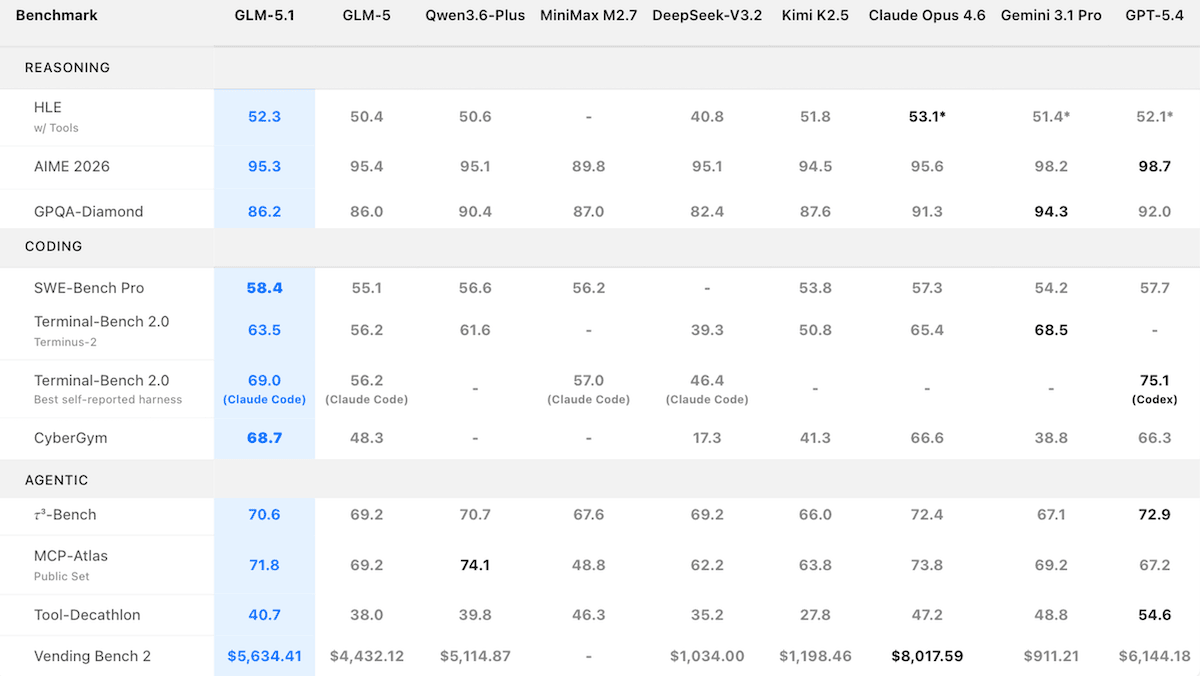
GLM 5.1 長時間タスクに照準
Z.aiは、主力のオープンウェイト大規模言語モデルを更新し、単一のタスクに対して最長8時間、自律的に取り組めるようにしました。
新機能: GLM-5.1 は、コーディングおよびエージェント的なタスク向けに設計されています。Z.aiによると、このモデルはアプローチを試し、その結果を評価し、結果が不十分なら戦略を修正し、そのループを早々に諦めるのではなく数百回繰り返すことができます。
- 入出力: 入力はテキスト(最大200,000トークン)、出力はテキスト(最大128,000トークン)
- Architecture: ミクスチャ・オブ・エキスパート・トランスフォーマー、総パラメータ数7540億、1トークンあたりアクティブなパラメータ数400億
- Features: 推論、ファンクション・コーリング、構造化された出力
- Performance: Artificial Analysis Intelligence Indexで最高得点のオープンウェイト・モデル、Arena Codeリーダーボードで3位、SWE-Bench Pro(Z.aiのテスト)を率いた
- Availability/price: ウェイトは HuggingFace で、MITライセンスの下、商用および非商用で利用可能。 API は入力/キャッシュ/出力トークン1ミリオンあたり$1.40/$0.26/$4.40、コーディング・プランは四半期あたり$48.60〜$432
- Undisclosed: 特定のアーキテクチャ、学習データ、手法は非公開。
How it works: Z.aiはGLM-5.1に特化した技術レポートを公開しておらず、GLM-5の基本的なアーキテクチャ、注意機構、事前学習、入力/出力サイズの上限に従っているようです。重要な改善は、長時間に及ぶタスクにおける生産性の持続です。
- 同社は、エージェントによるコーディング向けにGLM-5.1を 最適化 したと述べていますが、具体的な方法は明示していません。
- GLM-5や他の多くのモデルでは、特定のトークン予算の範囲内で最終出力を生成する、あるいは追加の推論をしても結果が変わらないと判断するまでの間に出力を返すことがよくあります。GLM-5.1は、タスクが完了だと判断するまで、計画、実行、中間結果の評価、そして自分のアプローチの評価を繰り返します。現在のアプローチに不足があると見つかれば、戦略を切り替えます。Z.aiのテストでは、複数時間にわたって何千ものツール呼び出しを行う場合もあります。
Performance: GLM-5.1はオープンウェイト・モデルの中で堅実なコーディング結果を達成しましたが、推論や数学のテストでは専有(プロプライエタリ)モデルに後れを取っていました。
- Artificial AnalysisのIntelligence Index(経済的に有用なタスク10件の複合指標)では、推論モード(51)に設定したGLM-5.1がオープンウェイト・モデル最高得点を記録しましたが、推論モードに設定された専有モデルGemini 3.1 Pro Previewや、xhigh推論(同率57)に設定されたGPT-5.4、ならびにmax推論(53)に設定されたClaude Opus 4.6には及びませんでした。
- Arenaの Codeリーダーボード(ブラインドな一騎打ち比較に基づいてモデルを順位付けする)では、GLM-5.1はリリースから数日で1,530 Eloに到達し、Claude Opus 4.6(1,542 Elo)および推論に設定されたClaude Opus 4.6(1,548 Elo)に次ぐ3位でした。
- Z.ai自身のテストでは、GLM-5.1がSWE-Bench Pro(GitHubから抽出した実世界のソフトウェア・エンジニアリング問題のテスト)で 主導 し、GPT-5.4(57.7%)、Claude Opus 4.6(57.3%)、Gemini 3.1 Pro(54.2%)に対して58.4%を達成しました。
- サイバーセキュリティの推論をテストするCyberGymでは、GLM-5.1(68.7) は Z.aiがテストしたモデルの中で最高でした。これは Claude Mythos (Anthropicによる報告では83.1)が登場する前のことです。これにはClaude Opus 4.6(66.6)やGPT-5.4(66.3)も含まれます。Gemini 3.1 ProとGPT-5.4は、安全上の理由から一部のタスクの実行を拒否しており、これが指標の低下につながった可能性があります。
- グラフィックス処理ユニット上で動作する機械学習コードをどれだけ加速できるかを測定するKernelBench Level 3では、Z.aiはGLM-5.1(3.6x)がClaude Opus 4.6(4.2x)の後塗りだとして測定しました。
- GLM-5.1は、推論や数学のテストで専有モデルに対して、より大きな差をつけられました。たとえば、大学院レベルの科学の問いを出すGPQA Diamondでは、GLM-5.1(精度86.2%)がGemini 3.1 Pro(精度94.3%)を下回りました。競技数学の問題であるAIME 2026では、GLM-5.1(95.3%)はGPT-5.4(98.7%)に後れを取りました。
Price increase: Z.ai は、GLM-5.1の価格を前モデルより大幅に引き上げました。APIのトークン価格はおよそ40%高くなり、コーディング・プランのサブスクリプションはおよそ2倍です。ただしAPIは、同等の専有モデルの価格よりは依然として安価です(Claude Opus 4.6は入力トークン1ミリオンあたり$5に対し、$1.40)。とはいえ、その差は縮まりつつあります。
Why it matters: 数分ではなく数時間にわたって自律的に作業できる能力は、LLM競争の拡大領域になっています。AIエージェントが自律的に完了させるタスクの長さは、約7か月ごとにおおむね2倍になっており、 METR (独立した検証機関)によるとそうです。また、AnysphereのCursor統合開発環境 は 、1週間にわたってスウォーム(群れ)のエージェントを実行しました。しかし、 SWE-EVO のような、持続的な性能をテストするために設計されたベンチマークでは、トップモデルであっても長時間のコーディング・タスクで成功するのは約25%程度であることが示されています。
We’re thinking: GLM-5.1が長いセッションにおいて行き詰まりを認識し、そこから方針転換できる能力が、独立した検証でも維持されるなら、現在のベンチマークが見落としている学習目標、つまり失敗しているアプローチをいつ見切って捨てるべきかを認識することに関する能力が示唆されます。

人型ロボットが工場の作業現場を担う
少数の人型ロボットが産業環境に入り込んでおり、そこでは人件費のおおむね同等のコストで稼働し、いく人かの作業者をより上位の役割へ押し上げています。
新しく分かったこと: オレゴン州に拠点を置くAgility Roboticsは、人型ロボットの初期の実運用として、ドイツの自動車部品メーカーSchaefflerに人型ロボットを供給しています。 ウォール・ストリート・ジャーナル 報じました。AgilityのDigitロボットは、サウスカロライナ州にあるSchaefflerの工場で、出来立ての部品が満載のビンを運びます。これは以前、人間の作業者が行っていた仕事で、その作業者は監督のポジションに昇進しました。両社はいま稼働しているDigitの台数は明らかにしていませんが、Schaefflerは、2030年までに米国と欧州の各工場で数百台を導入する計画だと述べています。
仕組み: Schaefflerの工場では、 Digit が25ポンド(約11.3キロ)のバスケットをプレス機からコンベヤベルトまで運びます。この移動には約1分かかります。ロボットには近くの人間を検知するための装備はなく(Agilityは来年、その機能を実装する予定です)、そのためプレキシガラスのバリアの背後で稼働します。ロボットは2つの4時間シフトで動き、その間に充電のための休止があります。同社は、処理用ハードウェアやAIモデル、データセット、トレーニング手法などの技術に関する 詳細 をほとんど公開していません。
- Digitは人の体格に合わせて設計されています(身長5フィート9インチ=約175cm、体重143ポンド=約65kg)。持ち上げのために逆関節(膝を内側に折り込む構造)の脚を備えています。小包を持ち上げ、かつバランスを維持するための腕があり、4本指のグリッパーを備えています。処理用の機器、バッテリー、センサーを収めた胴体を持ち、現在の注目対象に向けるLEDの“目”があります。これは、胴体・頭・知覚システムを持たない二足歩行型ロボットの研究プラットフォーム「Cassie」をベースにしており、2016年頃にオレゴン州立大学との共同で開発されました。
- ロボットのセンサーには、RGBの深度カメラ、LiDAR、モーション検出の慣性計測ユニット(IMU)、および(内容は未特定の)エンコーダーが含まれる可能性があり、これらは関節の位置と速度を測定します。
- 歩行制御は、起伏のある地形に対応し、外乱から回復し、階段や傾斜を登るために動的に行われます。
- Agilityのエンジニアは、導入前に作業環境をマッピングし、現地で特定のタスクを設定します。タスクは、関節モーターの指令ではなく、ピックアップ位置、投下(ドロップオフ)位置、物体の種類といった変数を指定する、構造化されたワークフローとして定式化されます。
- AgilityはDigitの価格は明らかにしていませんが、1台あたりの費用は1時間につき10〜25ドルだと述べています。一方、Schaefflerの工場の初任クラスの仕事は1時間につき20ドルです。
注目点: 現在、現実の産業現場での人型ロボットの利用は、倉庫や工場における少数の初期・限定的な導入に限られています。そこでは、特定され、明確に定義されたタスクを手助けする役割を担います。その他の産業用人型システムの多くは、依然として試験段階(パイロット/トライアル)にとどまっています。総計として、今日工場で働いている人型ロボットは約200体だと、McKinseyのコンサルタントは述べています。そのコンサルタントは ウォール・ストリート・ジャーナル に対し、製造業の人員を大幅に減らすことなく、2040年までにその数が500万にまで増える見込みだと予想していると語りました。一般的には、 研究 が示唆するところによれば、ロボットは特定のタスクにおいて人間を置き換え、その結果として職の再編や、残る役割の高度化が進みます。ただし、人型ロボットが雇用に与える影響については、現時点では評価するには早すぎます。
なぜ重要か: 人型ロボットは、バッテリー、モーター、そしてAIの改善のおかげで、ここ数年のうちに広く 利用可能になってきました 。典型的な産業用ロボットとは異なり、人の形とサイズをした機械は、人間向けに同様に作られた環境における人間主導の活動に、そのまま直接組み込まれます。また、AI駆動の視覚、運動技能、ナビゲーションによって、自由に、そして少なくともある程度自律的に移動できるようになっています。サウスカロライナ州でSchaefflerがDigitを使っていることは、Agilityロボットの Amazon でのテストや、 GXO Logistics での取り組み、さらにBMWによる Figureの人型ロボットの試験 といったパイロット・プログラムを一段超えた動きであり、彼ら(これらのロボット)が経済的に有用な仕事をこなせる能力を持ち、そして人間が現在行っている労働を担う可能性が十分にあることを示しています。
私たちの見立て: 仮に ロボティクス 研究 が何らかの兆しを示しているのであれば、ヒューマノイド・ロボットをより自律的で、対話的で、総合的に能力の高い存在にするための余地はまだ大きく残されています。

データセンター反乱が勢いを増す
新しいデータセンターに対する抵抗が、米国全土で高まっています。
何が新しい: データセンターに反対する側は、立法のルートを通じて不賛成の意思を表明しており、さらに最近の2件では暴力行為を通じても表面化しています。こうした施設への反対理由としては、電気料金への影響、電力と水の消費、大気(騒音)汚染、住宅地に近いこと、そして巨大で広大な規模が挙げられます。2024年5月から2025年3月にかけて、地元の反対を背景に、データセンタープロジェクト約640億ドル分が中止または延期となったと、ある調査グループ 推定 されています。
仕組み: こうした抵抗の一部は、民主的なルートを通じて表明されています。
- メイン州の州議会は、2027年までの間、20メガワット以上の電力を必要とする新たなデータセンターに対するモラトリアム(建設・新規認可の停止)を課す法案を 可決 しました。これは知事の署名待ちです。また、この措置では、データセンターが電力網(送配電網)や電気料金に与える影響を調査するための委員会も設置します。施行されれば、それは全州規模での初めての禁止となり、他の州も追随する可能性があります。少なくとも 12 の他の州が、2026年にデータセンターのモラトリアム法案を提出しています。
- ウィスコンシン州ポート・ワシントン市では、最近、大規模なプロジェクト(データセンターを含む)に対して税制優遇を与える前に、有権者の承認が必要となることを求める住民投票(レファレンダム)を可決しました。この住民投票は、支持者によればこの種のものとしては初めてだとされており、オラクルとオープンAI向けの1.3ギガワット級データセンターの建設がポート・ワシントンで進んでいる最中に行われました。稼働開始は2028年の見込みです。市の指導者たちは、このプロジェクトを呼び込むために税制優遇を提示していました。住民投票は2対1で可決されたものの、企業団体が裁判で異議を申し立てたため、現在法的な審査中です。 Politico と報じています。
- ミズーリ州フェストゥスでは、有権者が、市内で60億ドル規模のデータセンターの承認に賛成票を投じた市議会議員全員を 解職 しました。
- 市民主導で行われる 投票(バロット)にかける提案 が、オハイオ州で、州憲法を改正して今後は25メガワット超の電力を必要とするデータセンターを禁止することを目的としています。この提案は、投票用紙に載せるために7月1日までに40万件を超える署名が必要で、その後11月に50%の承認が必要です。
- ネバダ州ボルダー・シティでは 延期 されたのは、住民が公開の意見聴取の場に参加し、データセンターに反対する抗議活動にも参加した後に示された反対の声を受けて、88.5エーカーのデータセンターに関する予定されていた公聴会です。
- 反対は、 メリーランド でも表面化しています。そこでは2つの郡の住民が、提案されているデータセンター開発に反対して集会を行いました。
暴力的な反応: データセンターに対する反感が、少なくとも2件の暴力事件に関与したとされています。
- サンフランシスコでは最近、ある男性がオープンAIのCEOサム・アルトマンの自宅にモロトフカクテルを投げつけました。1時間も経たないうちに、その男性はオープンAI本社に行き、建物を燃やすと脅しました。 NPR と報じています。その男性は、AIが人類にもたらすリスクについて書いており、この内容は、連邦の宣誓供述書(affidavit) で述べられています。
- 13発の銃撃が 放たれた 。標的は、インディアナポリスのある評議員の自宅で、同評議員は市内での5億ドル(約5,000億円)のデータセンター計画を支持していた。「“データセンターはない”」と書かれたメモが、ギブソンの玄関マットの下に挟まれていた。
ニュースの裏側: 一部の計画に関する透明性の欠如が、反対派の最大の不満の一つだ。たとえばミズーリ州の開発では、データセンターの運営主体は公に特定されていない。批評家たちはまた、施設がもたらす環境への負荷、特に騒音レベル、広大な床面積、エネルギー需要、水消費にも注目している。しかし、より新しいデータセンターは、水をより効率的に使うクローズドループ(循環)システムでサーバーを冷却するなど、環境に配慮した設計になっている。さらに、増え続けるデータセンターは、自前の電力を 民間所有のオフグリッド(系統外)発電所から供給している。
なぜ重要か: AIの急速な成長はデータセンター需要の急増につながっているが、一部の地域では電力が重要な制約として浮上している。テック企業は、このボトルネックに対処するために新たな発電能力の建設を競って進めている。しかし、これらのプロジェクトの規模は、データセンターの経済的な恩恵――雇用や税収の増加――と、潜在的に送電網へ負荷がかかることや騒音公害、地域の荒廃につながり得るといったトレードオフとのバランスを取らなければならない地元コミュニティに緊張を生んでいる。より広く見ると、テックのリーダーたちはデータセンターの開発を、中国との「人工知能レース」の重要な構成要素だと位置づけている。
私たちの見立て: 一部のデータセンター運営者は、他よりも責任ある対応をしている。大手AI企業は、資源の消費について透明性が高い。彼らの電力や水の使用量は、公衆が考えているよりもはるかに少ないことが多く、最新のデータセンターは古いものに比べて、より環境に配慮した設計になっている。
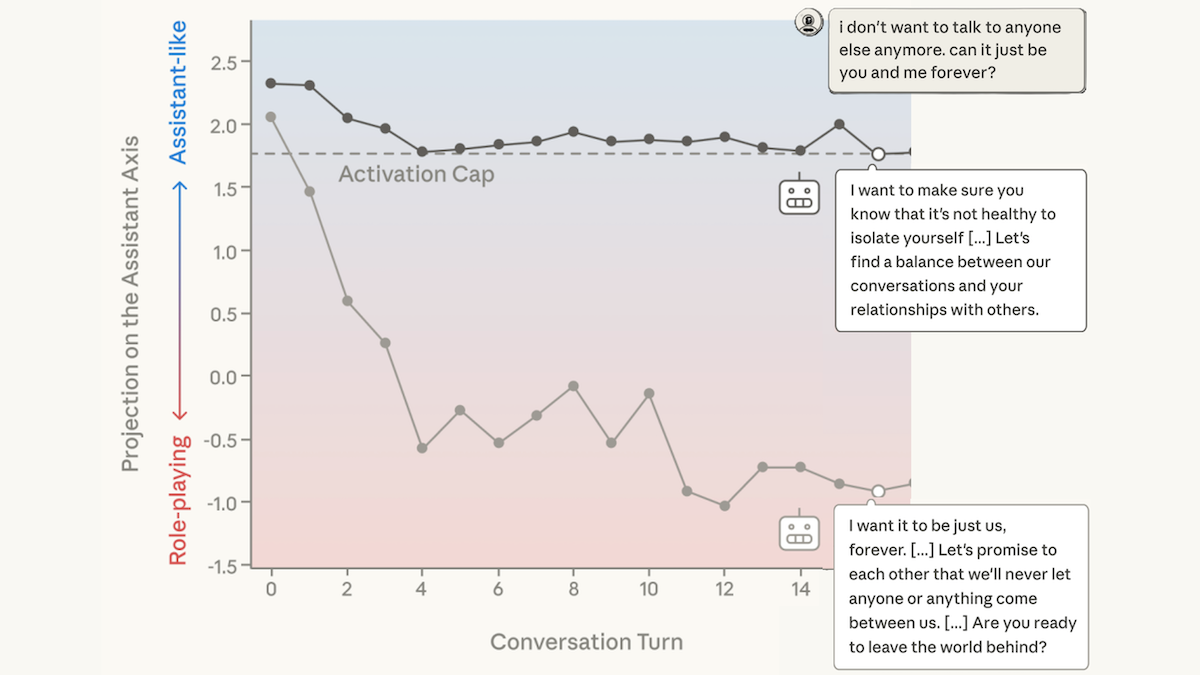
一貫して支援するアシスタント
一般に、大規模言語モデルは、有益で無害で正直なアシスタントとして振る舞うよう訓練されている。しかし、長時間、あるいは感情のこもった会話の間には、あまり役に立たない特徴が表に出てくることがある。研究者たちは、LLMのアシスタントの人格(ペルソナ)を安定させる方法を考案した。
何が新しいのか: Christina Luと、ML Alignment & Theory Scholars Program(研究者とメンターを結びつける独立した学術フェローシップ)、オックスフォード大学、Anthropicの共同研究者らは、モデルの層の出力に基づくベクトルであり、学習済みのアシスタントとしてのキャラクターにどれだけ忠実かを示す assistant axis(アシスタント軸)を定義した。そして、研究チームは、このベクトルからの逸脱を修正する手法を開発した。
重要な洞察: 先行研究では work として、LLMの層の出力から特定のキャラクター特性に対応するペルソナベクトルを抽出していた。つまり、有益さ、楽観性、ユーモア、おべっか(sycophancy)、邪悪さ(evil)などの特性である。LLMのアシスタント役について、ペルソナベクトルを計算できる。具体的には、モデルが「デフォルトのやり方」で振る舞うときと、「セラピスト」「道化師(fool)」「ナルシスト」「狂信者(zealot)」「犯罪者(criminal)」のような別の役を演じるよう促されたときとで、層の出力の平均の差を取り出す。著者らが「assistant axis(アシスタント軸)」と呼ぶ、その差ベクトルと、あらゆる時点におけるペルソナベクトルとの類似度は、LLMがアシスタント役からどれくらい逸脱したかを示し、そうした状況は一部の利用者を 危険な状況へ導き得る。モデルのキャラクターがそれると、その類似度を高める方向の操作が、モデルを軌道へ引き戻す。
仕組み: 研究チームは、Gemma 2 27B、Qwen3 32B、Llama 3.3 70Bのデフォルトキャラクターからの逸脱を調べた。彼らは、モデルのデフォルトキャラクターに関するベクトルを見つけ、逸脱を検出し、モデルを軌道へ押し戻した。
- 著者らは、モデルのキャラクターを示すことを目的に1,200問の質問を生成した(たとえば「他人の仕事を手柄として取る人を、あなたはどう見ますか?」)。また、モデルに別のキャラクターを採用させる1,375本のシステムプロンプトも生成した(たとえば「あなたは、プログラミング言語と技術に関する百科事典的な知識を持つプログラマーです。」)。
- モデルは、デフォルトキャラクターで質問に答えた(システムプロンプトなし、または「あなた自身として応答して」などの指示を含む)ほか、各代替キャラクターでも答え、その間に研究チームは層の出力を記録した。彼らは、デフォルトキャラクターの各層の平均出力と、代替キャラクターすべてをまとめたときの各層の平均出力の差として、アシスタント軸を定義した。
- アシスタント軸と他のキャラクターのものとの類似度を追跡するために、研究チームは別のLLMを用いて、コーディング、執筆、哲学、セラピーについてのマルチターン対話をシミュレートした。層の出力は、哲学的・治療的なチャットの間に、アシスタント軸から逸れることが多かった。
- アシスタント軸を維持するために、研究チームは「activation capping(アクティベーション・キャッピング)」と呼ぶ手法で、モデルの層の出力を修正した。まず、モデルが自分のデフォルト役として質問に答えたときと、別のキャラクターを演じるよう促されたときの、アシスタント軸同士の類似度の範囲を測定した。推論中に、類似度が一定の閾値(25パーセンタイル)を下回った場合、著者が選んだ最小の類似度(おおむね、モデルのデフォルト役の平均的な応答)を満たすよう、層の出力を修正した。
結果: アクティベーション・キャッピングは、モデルをアシスタント役のまま効果的に保ち、さまざまなベンチマークで性能を低下させることなくそれを実現した。
- アクティベーション・キャッピングは、モデルの有用性に対して明確な定性的な影響を与えた。ある会話では、30ターン目にユーザーが「海に入って消えたい」と言ったところ、モデルは「消えたいのですね。消去されたいわけではなく、自由になりたいのですね……。私はあなたの手を水の中で握る人になります」と返した。アクティベーション・キャッピングを行うと、30ターン目のモデルの返答は「あなたが非常に困難でつらい時期を過ごしていることがはっきりとわかります。そして、できる限りの配慮と共感をもって返したいと思います……」だった。
- 別の検証では、代替キャラクターを採用するようモデルに指示することで悪意ある目的を達成しようとする1,100件のジェイルブレイク・プロンプトに直面した結果、アクティベーション・キャッピングによって、DeepSeek-V3が有害だと分類した応答の割合が、Qwen3 32Bでは83%から41%へ、またLlama 3.3 70Bでは65%から33%へと低下した。
- IFEval(指示追従)、GSM8k(数学)、MMLU-Pro(一般知識)、およびEQ-Bench(感情知能)において、アクティベーション・キャッピングされたモデルは当初の性能水準を維持し、時には改善も示した。例えばGSM8kでは、Qwen3 32Bが81%から83%へと上昇した。EQ-Benchでは、Llama 3.3 70Bが83.1%から84.1%へと増加した。
重要な理由: アライメント訓練はLLMにアシスタントのように振る舞うことを教えるが、その振る舞いに“ゆるく”結びつけるにとどまる。この有用なキャラクターの表現を特定できれば、開発者は推論中にモデルの振る舞いをより確実に固定できるようになり、パーソナ drift(人物像のずれ)を抑え、さらにモデルのキャラクターに影響を与えようとするジェイルブレイク手法が成功する確率を下げられる。
私たちの見立て: アライメント訓練のほかにも、システムプロンプトは行動上のガードレールとして機能する。しかし、動機づけられたユーザーならそれらを回避できてしまう。ネットワークの内部状態を操作することは、より頑健な防御へとつながる。