現代のLLMにおけるアテンション変種の視覚ガイド
MHAとGQAからMLA、スパースアテンション、ハイブリッドアーキテクチャへ
私は元々、DeepSeek V4 について書こうと考えていました。まだリリースされていないため、長い間リストに挙がっていた別のことに時間を使いました。すなわち、ここ数年にわたって取り上げてきたさまざまなLLMアーキテクチャを収集・整理・洗練させることです。
そこで、ここ2週間にわたり、その取り組みをLLMアーキテクチャのギャラリーに変えました(この原稿を執筆している時点で45件)。以前の記事の内容と、まだ文書化していなかったいくつかの重要なアーキテクチャを組み合わせたものです。各エントリにはビジュアルモデルカードが付いており、ギャラリーを定期的に更新し続ける予定です。
ギャラリーはこちらです: https://sebastianraschka.com/llm-architecture-gallery/

初期版を共有した後、いくつかの読者からポスター版があるかどうかという質問も寄せられました。その結果、現在 Redbubble 経由のポスター版があります。私は印刷時の見え方を確かめるため、中サイズ(26.9 x 23.4 インチ)を注文しましたが、仕上がりは鋭く、くっきりしています。とはいえ、そのサイズでは最小のテキスト要素のいくつかがすでにかなり小さいため、すべてを読みやすくしたい場合には、小さめのバージョンはお勧めしません。

ギャラリーに並行して、私は/現在も、いくつかの主要なLLM概念の短い解説を作成しています。
そこで、本記事では、近年、著名なオープンウェイトのアーキテクチャで開発・採用されてきた、最近のアテンションの変種をすべて振り返るのは興味深いと考えました。
このコレクションを、参照用および軽量な学習リソースとして役立つようにすることが私の目標です。お役に立ち、教育的だと感じていただければ幸いです!
1. マルチヘッド・アテンション(MHA)
自己注意は、各トークンがシーケンス内の他の可視トークンを見て、それらに重みを割り当て、それらの重みを用いて入力の新しい文脈依存表現を構築します。
マルチヘッド・アテンション(MHA)は、そのアイデアの標準的なトランスフォーマー版です。異なる学習済み射影を用いて、複数の自己注意ヘッドを並列に実行し、それらの出力を結合して、より豊かな表現にします。
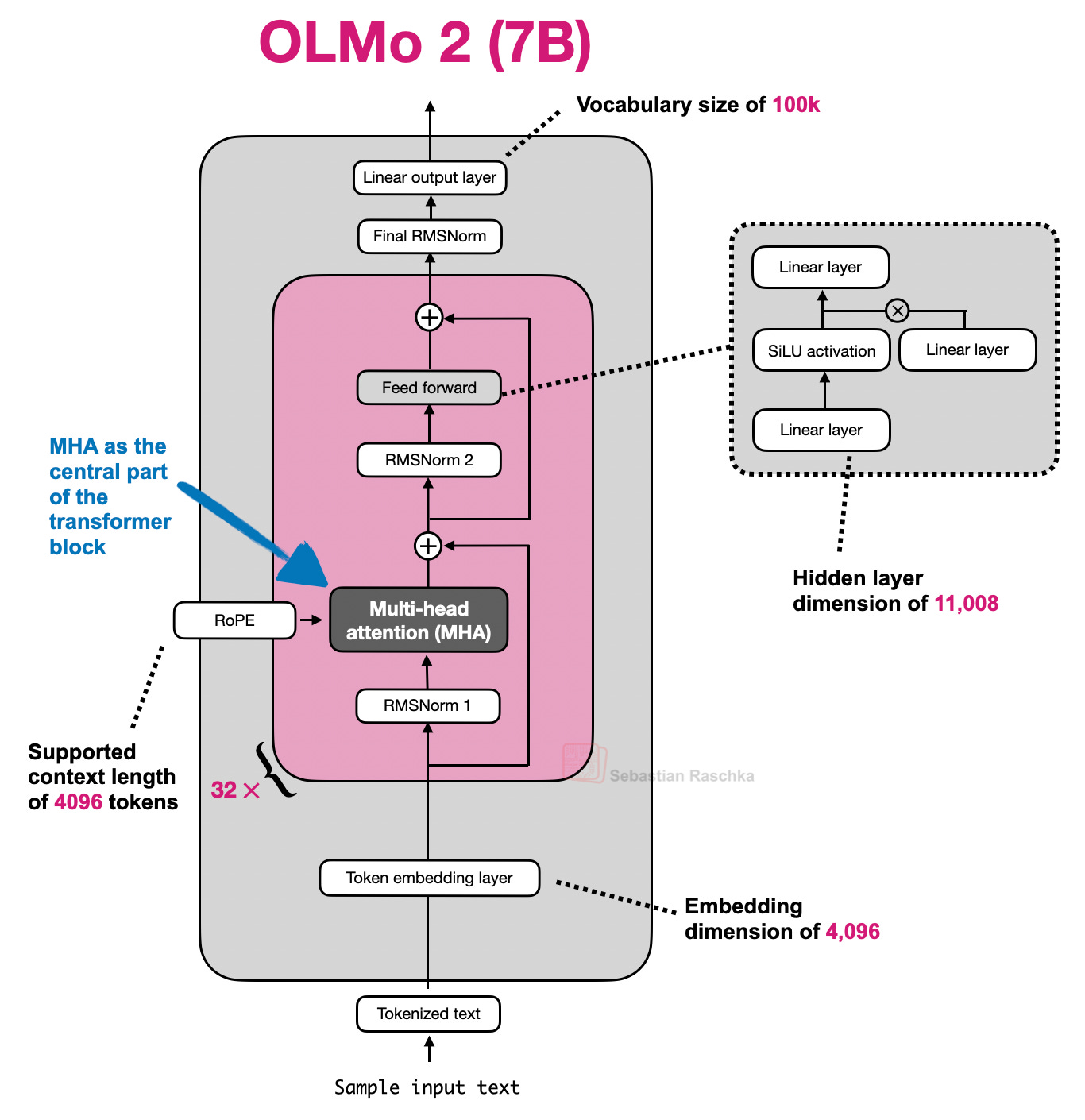
以下のセクションは、自己注意機構を説明して MHA を説明するための駆け足の概説から始まります。これは、グループ化クエリ注意、スライディングウィンドウ注意などといった関連する注意機構の土台を整えるための、クイックな概要としての位置づけです。もし、より長く、より詳しい自己注意の解説に興味がある場合、私の長い記事「LLMsにおける自己注意、マルチヘッド注意、因果注意、クロス注意の理解とコーディング」をご覧になると良いでしょう。LLMsにおける自己注意、マルチヘッド注意、因果注意、クロス注意の理解とコーディング 記事。
EXAMPLE ARCHITECTURES
1.2 注意の歴史的逸話と注意が発明された理由
注意は、トランスフォーマーと MHA の発祥以前から存在していました。その直接的な背景は、翻訳のためのエンコーダ-デコーダ RNN でした。
古いシステムでは、エンコーダ RNN がソース文をトークンごとに読み取り、それを隠れ状態の系列に圧縮するか、最も簡略な版では1つの最終状態に圧縮します。次にデコーダ RNN は、その制限された要約からターゲット文を生成しなければなりませんでした。短くて単純なケースにはこれで機能しましたが、次の出力語に関する関連情報が入力文の他の場所にいると、明らかなボトルネックを生み出しました。
要するに、この制限は隠れ状態が無限に多くの情報や文脈を保存できないという点であり、時には全入力列を参照することが有用です。
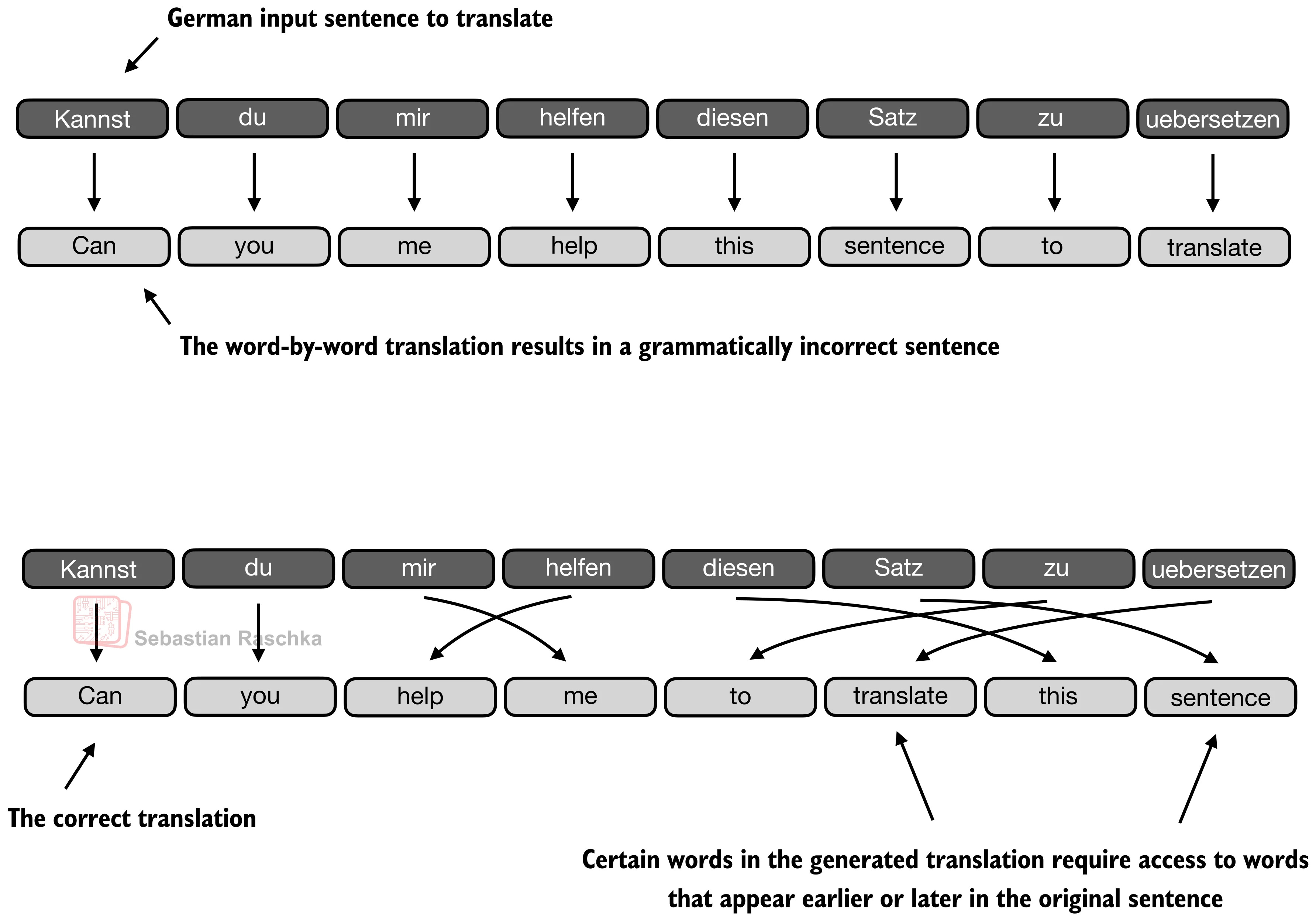
以下の翻訳例はこのアイデアの限界の一つを示しています。例えば、文は局所的に妥当な語の選択を多く保持しても、モデルが問題を単語ごとの対応づけのように扱いすぎると翻訳として失敗します。(上段のパネルは、文を単語ごとに訳す過剰な例を示しています。もちろん、得られる文の文法は正しくありません。)実際には、正しい次の語は文全体の構造と、どの前の語がその段階で重要かに依存します。もちろん、これはRNNでも正しく翻訳できる場合がありますが、長い系列や知識取得タスクでは、前述したように隠れ状態にはそれほど多くの情報を格納できないため、苦労します。
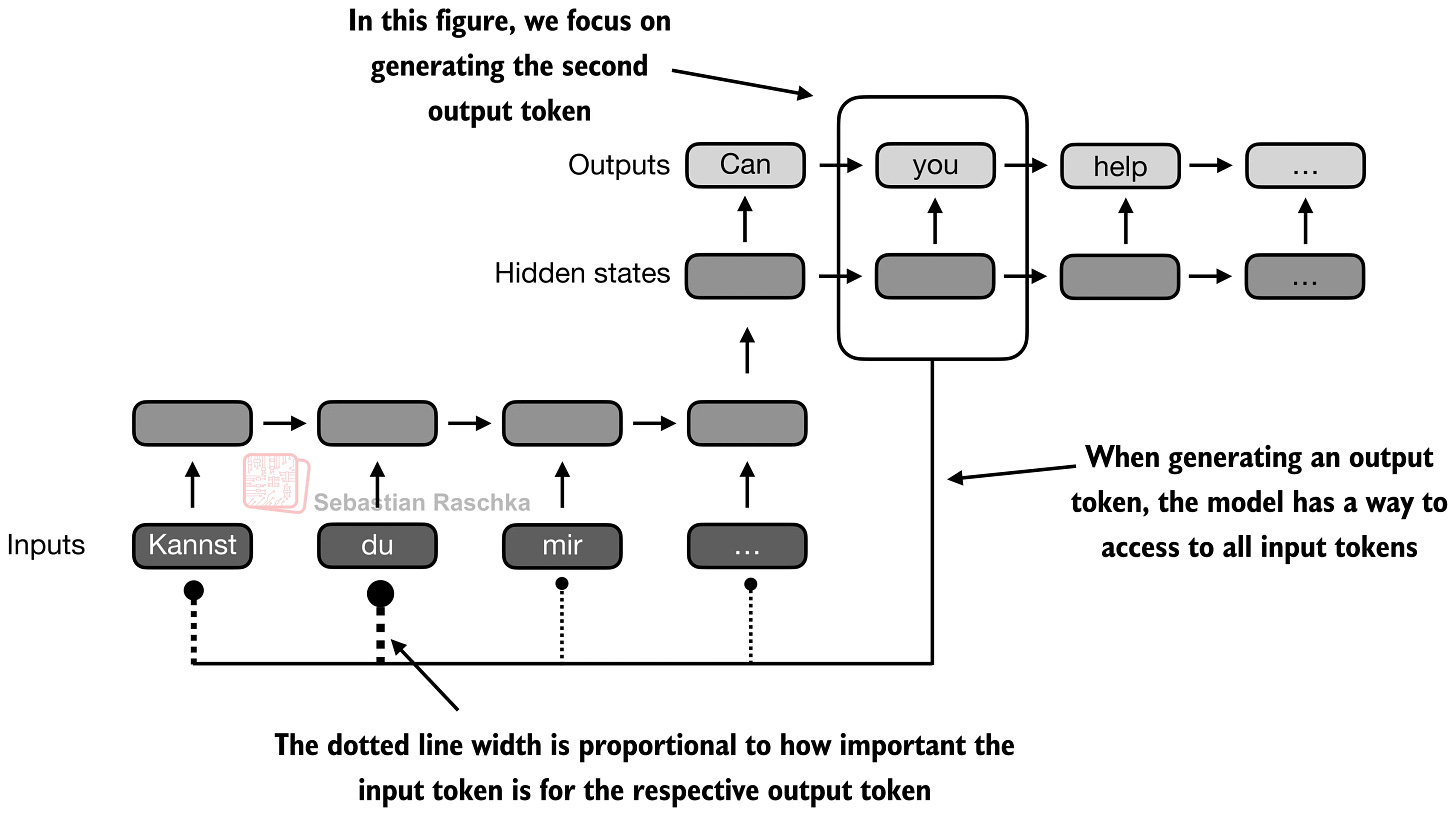
次の図は、その変化をより直接的に示しています。デコーダが出力トークンを生成しているとき、それを1つの圧縮されたメモリ経路に限定すべきではありません。より関連性の高い入力トークンに直接遡って到達できるべきです。
Transformersは前述の注意機構を備えたRNNの核となるアイデアを維持しつつ、再帰を取り除きます。クラシックな Attention Is All You Need 論文では、注意機構はシーケンス処理の主要な機構そのものとなる(RNNエンコーダ-デコーダの一部であるだけではなく)。
トランスフォーマーでは、その機構は自己注意と呼ばれ、シーケンス内の各トークンが他のすべてのトークンに対して重みを計算し、それらを用いてそれらのトークンから情報を新しい表現へと混ぜます。マルチヘッド・アテンションは、同じ機構を並列に複数回実行したものです。
1.3 マスクされた注意行列
長さ T のトークン列に対して、注意はトークンごとに1行の重みが必要なので、全体として T x T の行列になります。
各行は簡単な質問に答えます。このトークンを更新するとき、表示される各トークンはどれくらい重要でしょうか。デコーダーのみのLLMでは、将来の位置はマスクされており、図の右上の部分が下の図のようにグレーアウトされているのはそのためです。
自己注意は因果マスクの下でこれらのトークン間の重みパターンを学習し、それらを用いて文脈に応じたトークン表現を構築することを根本的な目的としています。
このセクションの終わり
この章の残りでは、実際のモデルでの自己注意の実装と、そのハイパーパラメータが性能に与える影響について詳しく見ていきます。

1.4 自己注意の内部構造
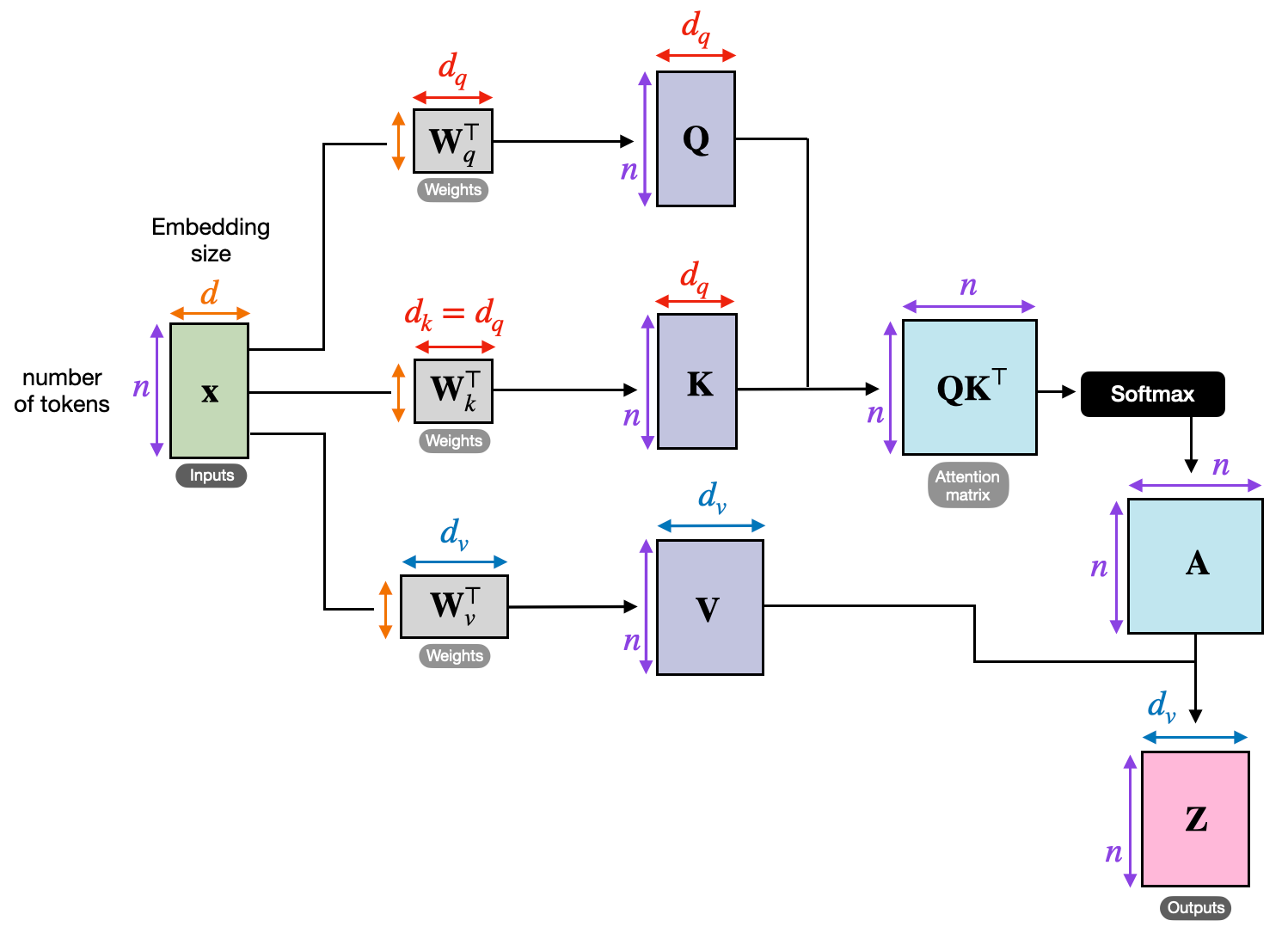
次の図は、トランスフォーマーが注意行列 (A) を、入力埋め込み (X) から計算し、それを用いて変換後の入力 (Z) を生成する方法を示します。
ここでQ、K、およびV は、クエリ、キー、値を表します。トークンのクエリはそのトークンが何を探しているかを表し、キーは各トークンがマッチングのために何を提供するかを表し、値はアテンション重みによって出力に混ぜ込まれる情報を表します。
手順は以下のとおりです:
Wq、Wk、およびWvは、入力埋め込みをQ、K、Vに射影する重み行列です。QK^Tは、生のトークン間の関連度スコアを生成します。softmax は、それらのスコアを前節で説明した正規化されたアテンション行列
Aに変換します。AはVに適用され、出力行列Zを生成します。
アテンション行列は、別個の手書きのオブジェクトではないことに注意してください。これは Q、K、および softmax から生じます。
次の図は、前の図と同じ概念を示していますが、アテンション行列の計算は「スケールド・ドット積アテンション」のボックス内に隠されており、すべての入力トークンではなく、1つの入力トークンの計算のみを行います。これは、次のセクションでマルチヘッド・アテンションへ拡張する前に、単一ヘッドの自己注意のコンパクトな形を示すためです。
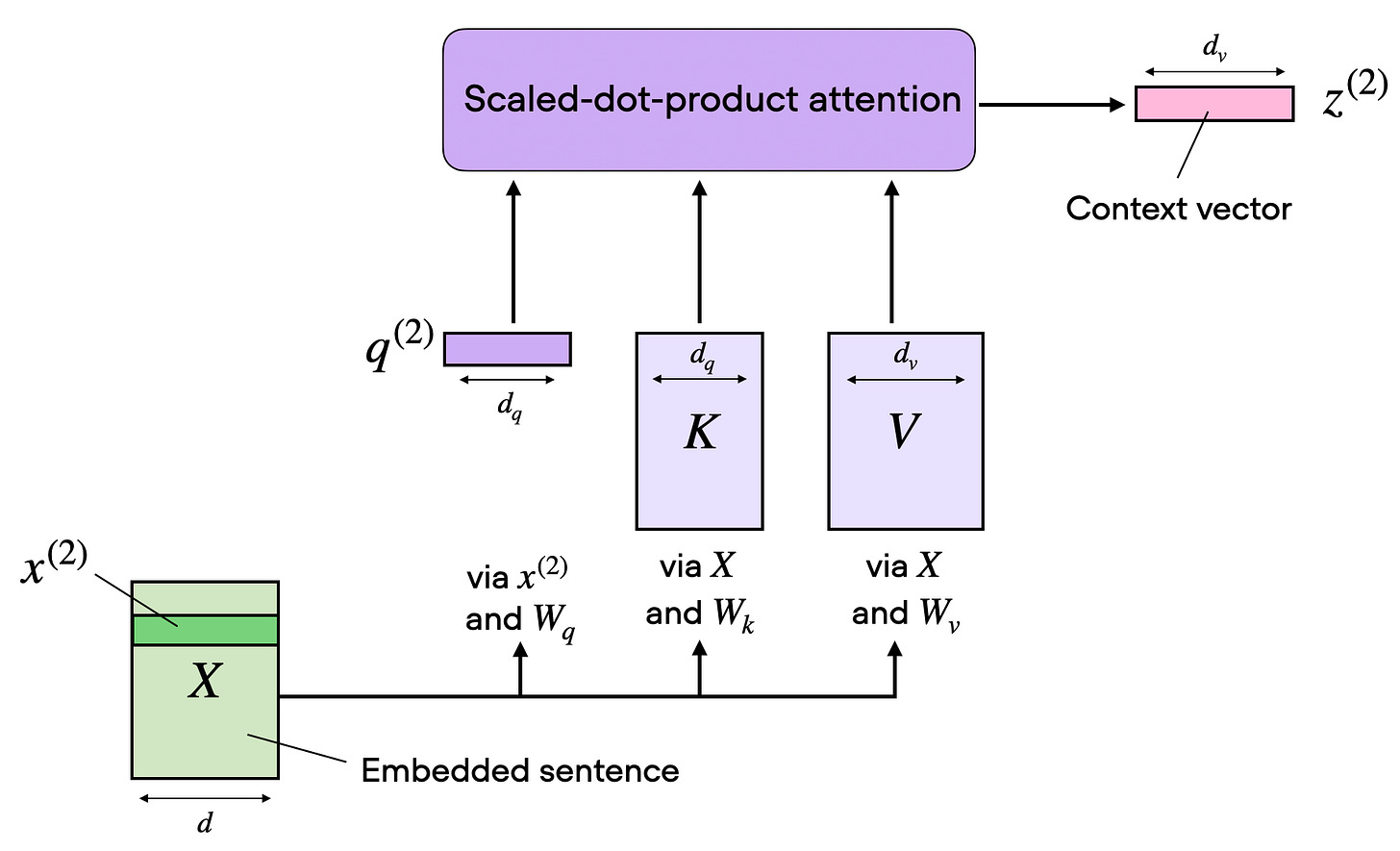
1.5 1つのヘッドからマルチヘッド・アテンションへ
1組の Wq/Wk/Wv 行列は1つのアテンションヘッドを与えます。つまり1つのアテンション・マトリクスと1つの出力マトリクス Z を意味します。 (この概念は前の節で図示されました。)
マルチヘッド・アテンションは、異なる学習済み投影行列を用いて、これらのヘッドを並列に実行するだけです。
これは、異なるヘッドが異なるトークン関係に特化できるため有用です。1つのヘッドは短い局所的な依存関係に焦点を合わせ、別のヘッドはより広い意味的結びつきに、別のヘッドは位置的または統語的構造に焦点を当てることがあります。
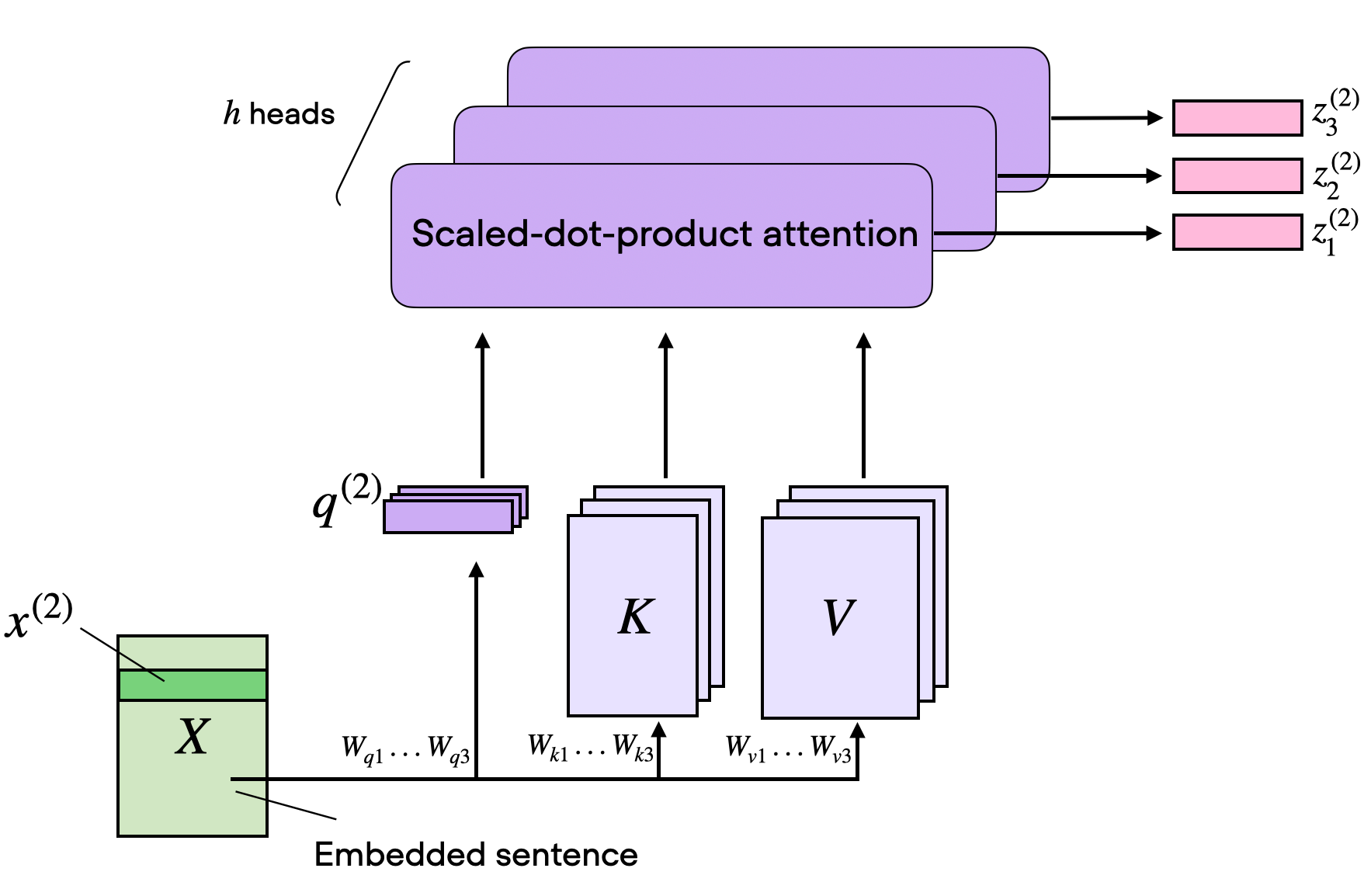
2. グループ化されたクエリ・アテンション(GQA)
グループ化されたクエリ・アテンションは、標準の MHA に由来するアテンションのバリアントです。2023年の論文「GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints」によって提案されました。著者は Joshua Ainslie らです。
各クエリヘッドにそれぞれキーとバリューを割り当てる代わりに、いくつかのクエリヘッドが同じキー-バリュー投影を共有するようにします。これにより KVキャッシュ はるかに安価になります(主にメモリ削減として)全体のデコーダーのレシピを大きく変えずに済みます。
2. グループ化されたクエリ・アテンション(GQA)
EXAMPLE ARCHITECTURES
Dense: Llama 3 8B, Qwen3 4B, Gemma 3 27B, Mistral Small 3.1 24B, SmolLM3 3B, および Tiny Aya 3.35B。
スパース(Mixture-of-Experts): Llama 4 Maverick, Qwen3 235B-A22B, Step 3.5 Flash 196B, および Sarvam 30B。
2.1 なぜ GQA が人気になったのか
In my architecture comparison article, I framed GQA as the new standard replacement for classic multi-head attention (MHA). The reason is that standard MHA gives every head its own keys and values, which is more optimal from a modeling perspective but expensive once we have to keep all of that state in the KV cache during inference.
In GQA, we keep a larger set of query heads, but we reduce the number of key-value heads and let multiple queries share them. That lowers both parameter count and KV-cache traffic without making drastic implementation changes like multi-head latent attention (MLA), which will be discussed later.
In practice, that made and keeps it a very popular choice for labs that wanted something cheaper than MHA but simpler to implement than newer compression-heavy alternatives like MLA.
2.2 GQA Memory Savings
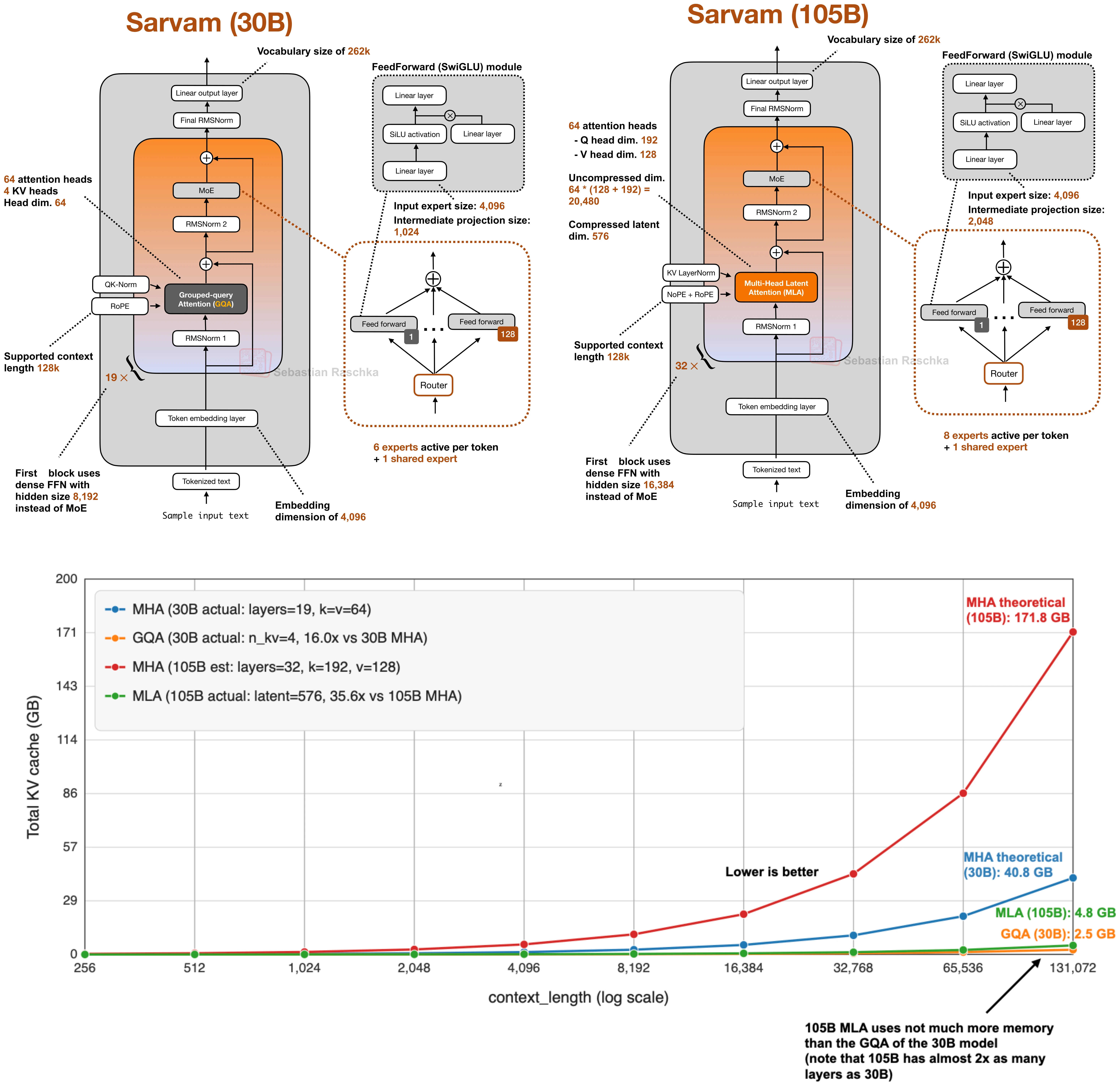
GQA は、各レイヤーあたり保持するキー/値ヘッドが少ないほど、トークンごとに必要なキャッシュ状態が少なくなるため、KV ストレージの節約が大きくなります。したがって、シーケンス長が長くなるにつれて GQA はより有用になります。
GQA もスペクトルです。すべてを 1 つの共有 K/V グループまで削減すると、実質的にはマルチクエリ・アテンションの領域となり、さらに安価ですが、モデリング品質の低下をより顕著に引き起こすことがあります。最適点は通常、マルチクエリ・アテンション(1 つの共有グループ)と MHA(K/V グループがクエリ数と等しい)の中間付近で、キャッシュの節約は大きい一方で、MHA に対するモデリングの劣化は控えめです。

2.3 なぜGQAは2026年にも重要なのか
MLA のようなより高度なバリアントは、KV の効率性レベルを同じにしたまま、より良いモデリング性能を提供できる可能性があるため人気が高まっています(例えば、DeepSeek-V2 論文のアブレーション研究で議論されているように)DeepSeek-V2 論文、しかしそれらはより複雑な実装とより複雑なアテンションスタックを伴います。
GQA は堅牢で実装が容易で、またトレーニングもしやすいです(私の経験に基づくと、必要なハイパーパラメータの調整が少ないためです)。
そのため、最新のリリースのいくつかはここでも意図的にクラシックなまま残っています。例えば、私の Spring Architectures 記事では、MiniMax M2.5 と Nanbeige 4.1 は、他の効率向上のコツを追加することなく、グループ化されたクエリ・アテンションだけを使用して非常にクラシックなままのモデルであると述べました。Sarvam は特に有用な比較対象でもあります:30B モデルは従来の GQA を維持しますが、105B バージョンは MLA に切り替えます。
3. マルチヘッド潜在アテンション(MLA)
The motivation behind Multi-head Latent Attention (MLA) is similar to Grouped-Query Attention (GQA). Both are solutions for reducing KV-cache memory requirements. The difference between GQA and MLA is that MLA shrinks the cache by compressing what gets stored rather than by reducing how many K/Vs are stored by sharing heads.
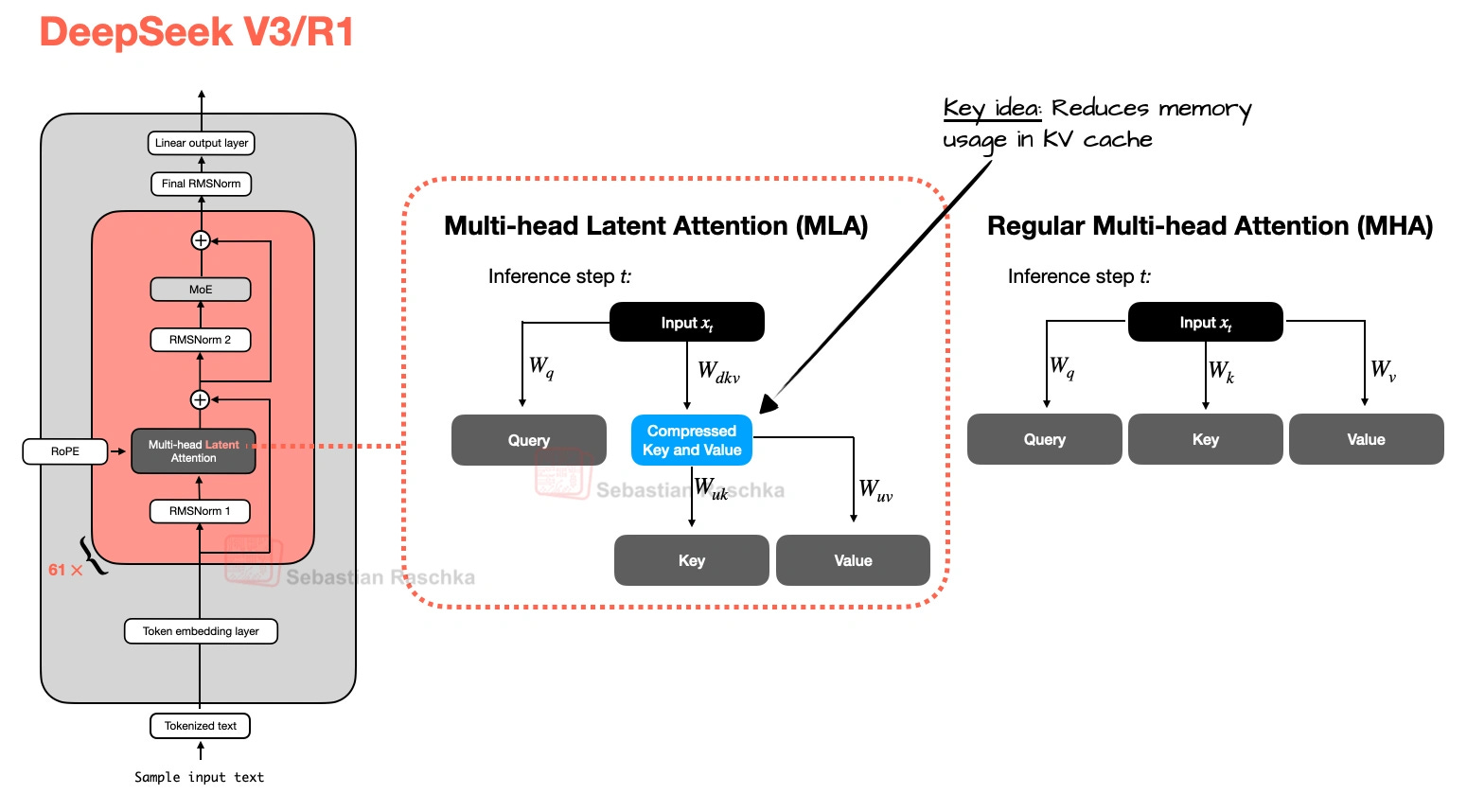
MLA, originally proposed in the




