Claude Opus 4.8 をご紹介

Claude Opus を新しいバージョンである Claude Opus 4.8 にアップグレードします。Opus 4.7 をベースに、ベンチマーク全体で改善が加えられており、より効果的な共同作業者になっています。価格は同じまま、今日から利用可能です。
Opus 4.8 は、いくつかの新機能とともに提供開始されます。claude.ai のユーザーは、Claude がタスクに注ぐ「取り組みの量」を制御できるようになりました。Claude Code には、新しい「dynamic workflows(ダイナミック・ワークフロー)」機能が追加され、非常に大規模な問題に取り組めるようになります。そして、Opus 4.8 の fast mode(モデルが前モデルの 2.5 倍の速度で動作できるモード)は、これまでのモデル向けに比べて 3 分の 1 の価格になりました。
Opus 4.8 の能力
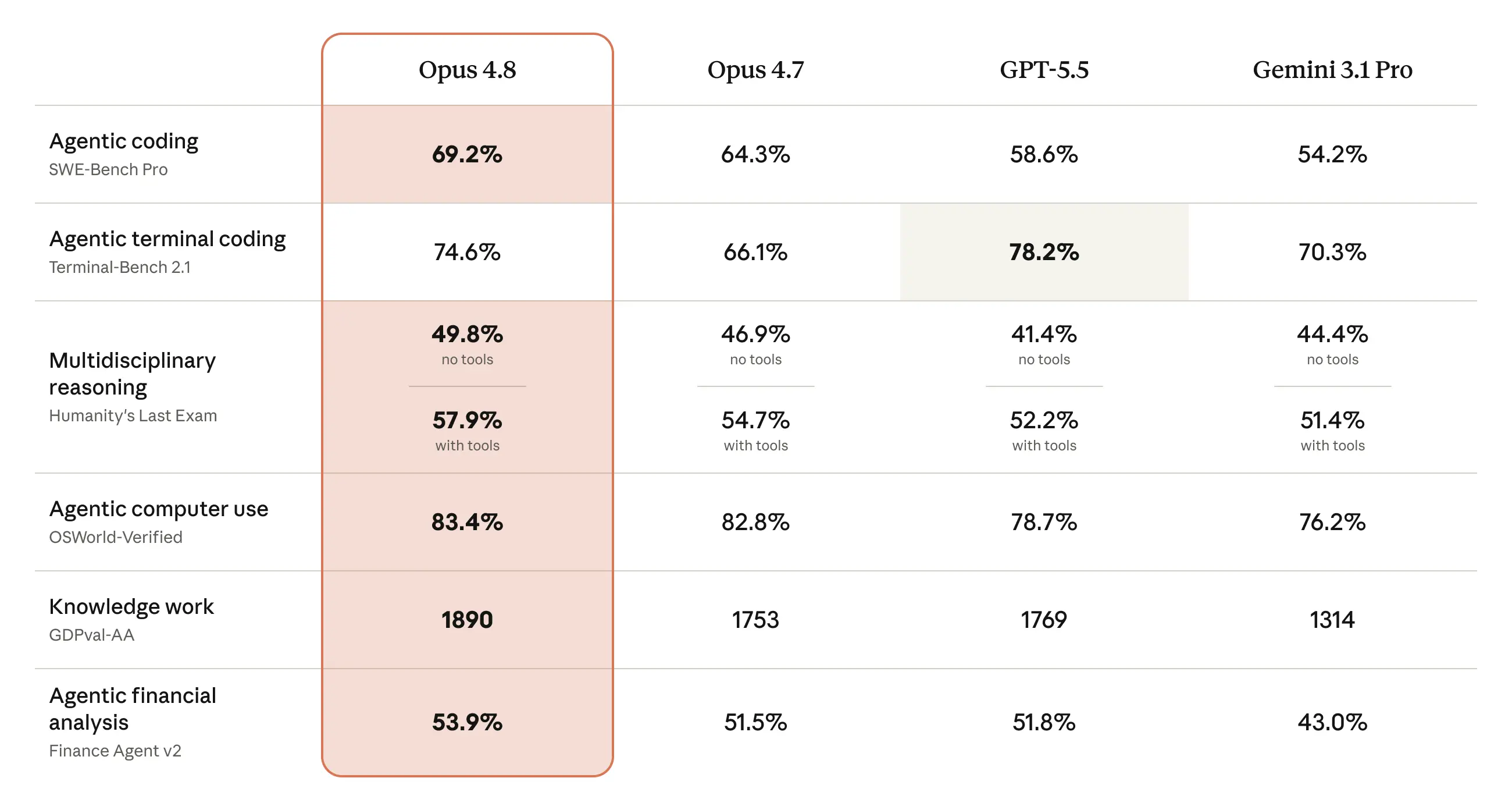
以下の表は、Opus 4.8 が、後継モデルや、コーディング、エージェント的スキル、推論、実務的な知識作業タスクに関するテストで、他のモデルと比べてどうかを示しています。詳細および、より幅広い能力評価については、Claude Opus 4.8 System Card をご覧ください。
Opus 4.8 と協働する
初期テスターによると、エージェント的なタスクを実行しているときの Claude Opus 4.8 は、より信頼性が高く、判断が鋭いことが分かりました。以下は、Opus 4.8 と協働した際の体験について、こうした多くのテスターから寄せられたコメントです。
Claude Opus 4.8 は、判断が明らかに良くなっています。Claude Code では、正しい質問をし、自分自身のミスを見つけ、計画が妥当でないときにはきちんと引き下がらずに反論し、大きな変更を行う前に、複数のサービスにまたがる複雑な探索の中で自信を積み上げていきます。協働して構築するのに最適なモデルです。
私たちのSuper-Agentベンチマークでは、Claude Opus 4.8だけが、あらゆるケースをエンドツーエンドで完了し、コスト面で同水準において、それまでのOpusモデルやGPT-5.5を上回っています。翻訳、深掘り調査、スライド作成、分析といったエージェント製品の領域で、強力な信頼性を提供します。
CursorBenchにおいて、Claude Opus 4.8は、あらゆる難易度レベルで、それまでのOpusモデルを上回ります。ツール呼び出しは意味のある形でより効率的で、同じ知能を得るのに必要なステップ数が少なく、またエンドツーエンドのタスクを最後までやり通します。
Claude Opus 4.8は、私たちのLegal Agent Benchmarkでこれまでに記録された最高スコアを提供し、全パス標準において総合で初めて10%を超えました。実質的な法務作業において、このような精度の向上は、顧客が自信を持って実際にどれだけの弁護士業務を委ねられるかに、直結する改善になります。
Claude Opus 4.8は、Opus 4.7に対する大きなクオリティ・オブ・ライフのアップデートだと感じています。より速く、連携しやすく、長いセッションにわたって文脈とスタイルの方向性をしっかり維持できるようになりました。Opus 4.8は、声(トーン)、好み(テイスト)、そして技術的な実行のすべてを並行して実現する必要がある仕事で、私が信頼し続けてきたモデルです。
Claude Opus 4.8は、私たちがテストした中で最も強力な「コンピューター利用」および「ブラウザエージェント」モデルで、Online-Mind2Webで84%を達成しています。これはOpus 4.7とGPT-5.5の両方に対して、意味のある大きな伸びです。エージェントの業務ワークロードに求められるのは、エンドツーエンドでの信頼性を保ちながらタスクに集中し続けることです。
Claude Opus 4.8はツールをきれいに扱い、無人で継続稼働し続けるために必要な、自律型エンジニアリングのワークロードに求められる一貫性をもって指示に従います。Opus 4.6を改善し、Opus 4.7で私たちが目にしたコメントの冗長さやツール呼び出しの問題を修正しました。このリリースはAnthropicからDevinを土台に開発するエンジニアに対し、より速い能力向上としてそのまま反映されます。
長期間にわたる評価(eval)の中で、Claude Opus 4.8の分析は、先行するOpusのモデルよりも一貫して品質が高いものでした。より速く完了し、より豊かで情報量の多い出力を生成しました。全体として、明らかに改善された信号対雑音比です。最大の違いは、Opus 4.8が分析の入力と出力にある問題を、先回りして指摘する傾向が強いことでした。他のモデルはこうした指摘を定期的に見落としており、ユーザーがそれを発見するのを待っていたのです。
CoCounsel Legalにおいて、Claude Opus 4.8は、従来のOpusモデルと比べて一貫性と推論の質が意味のある形で向上しました。お客様が依存している、ハイステークスなプロフェッショナルの業務ワークフローにおいては、その信頼性が重要です。法務・税務の専門家向けにフィデューシャリーグレードのAIシステムを構築していくなかで、このような進歩は、現実のワークフローにおける信頼できるAIパフォーマンスの水準を引き上げるのに役立ちます。
Claude Opus 4.8は、エンタープライズAIの新しい基準を打ち立てました。Genieは、DatabricksのデータおよびナレッジワークのためのAIエージェントですが、新しいOpusモデルによってエージェンティックな推論が一段と進化し、これまでのどのOpusよりも速く、より深く多段階の質問に取り組めます。さらに、マルチモーダルの強みを持つことでGenieは、PDFや図表、その他の非構造化コンテンツに対して、直接61%安いトークンコストで推論できます(Opus 4.7と比べて)。
Hebbiaのオーケストレーターにおける金融ドキュメントのワークフローでは、Claude Opus 4.8はOpus 4.7と同等の高い品質を提供しつつ、引用の精度と、検索(リトリーバル)時のトークン効率が目に見えて向上しています。これは、お客様が日々実行しているような、密度の高い提出書類の種類に非常にうまく機能します。
Opus 4.8で最も目立つ改善の1つは、その正直さです。私たちはすべてのモデルを正直になるよう訓練しています。たとえば、裏付けられない主張をしないようにするためです。しかし、AIモデルに関する一般的な課題として、時には結論を急ぎ、根拠が薄いにもかかわらず、自分たちの作業が前進したと自信満々に主張してしまうことがあります。初期のテスターによれば、Opus 4.8は自分の作業に関する不確実性を指摘する可能性がより高く、裏付けのない主張をする可能性はより低いとのことです。これは、私たちの評価によって裏付けられており、Opus 4.8は、前身モデルと比べて、書いたコードに欠陥があっても見過ごされたまま通ってしまうことを許容する可能性が約4分の1であることが示されています。
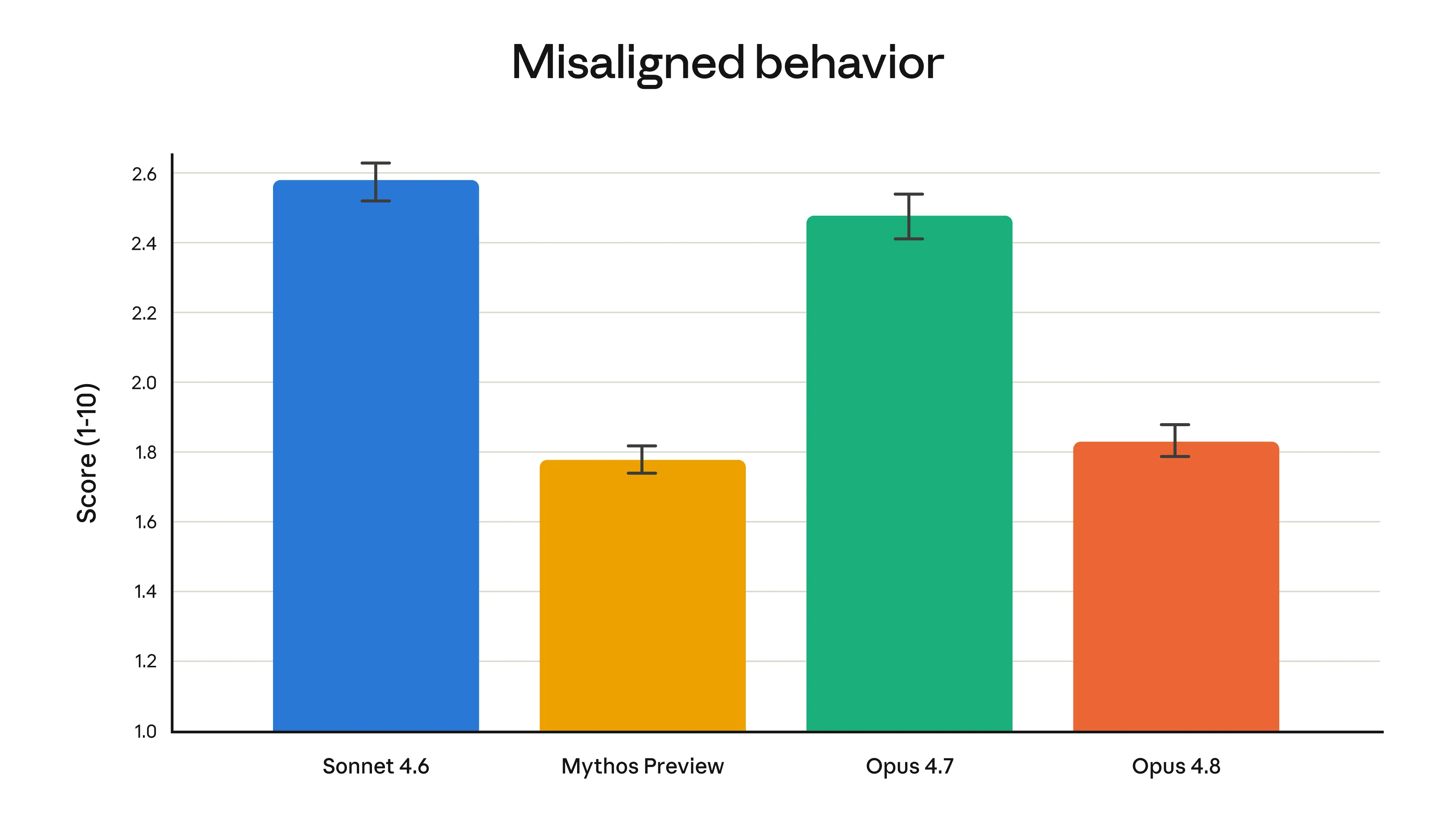
いつも通り、リリース前にモデルに対して詳細なアライメント評価を実施しました。前向きな特性の観点では、私たちのAlignmentチームは、Opus 4.8が「ユーザーの自律性を支え、ユーザーにとって最善の利益のために行動する」といった共益的な特性の測定において、私たちの評価基準で新たな最高記録を達成した」と結論づけています。さらに、その評価では、Opus 4.8のミスアライメントされた行動(欺瞞や誤用への協力など)の発生率がOpus 4.7よりも大幅に低く、また、私たちが最もアライメントできているモデルであるClaude Mythos Previewと同程度であることも示されました。事前のデプロイ前安全テスト群を伴うアライメント評価の全容は、Claude Opus 4.8 System Cardに報告されています。
本日あわせてリリースするもの
Claude Opus 4.8に加えて、以下の更新も行います:
- ダイナミック・ワークフロー。この新機能(リサーチプレビューで提供)は、ClaudeがClaude Code内でより大きなタスクに取り組めるようにします。Claudeは作業を計画し、その後、1つのセッションで数百に及ぶ並列のサブエージェントを実行できます(またOpus 4.8では、エージェントはさらに長く実行できます)。そして、ユーザーに報告する前に出力を検証します。たとえば、Opus 4.8を使ったClaude Codeでは、キックオフからマージまでの間に、数十万行規模のコードベース全体に対する移行(マイグレーション)を、既存のテストスイートを基準として実行できるようになりました。ダイナミック・ワークフローについて、Claude CodeのEnterprise、Team、Maxプランで利用可能なことの詳細は、こちらの記事をご覧ください。
- claude.ai と Cowork におけるエフォート制御。モデルセレクターに加えて、新たな制御項目により、ユーザーはClaudeが回答にどれくらいのエフォートを投入するかを選べるようになります。エフォートを高く設定すると、より頻繁に、より深く考えて、より良い回答を提供します。エフォートを低く設定すると、より速く応答し、ユーザーのレート制限の消費をよりゆっくりにします。ユーザーはこの選択が可能になりました。エフォート制御はすべてのプランで利用できます。
- Messages APIが、メッセージ配列内でシステム項目を受け付けるようになりました。。開発者は、プロンプトキャッシュを壊したり、更新をユーザーのターンを介してルーティングしたりせずに、タスクの途中でClaudeへの指示を更新できます。これは、特定のハーネスで、エージェントが実行される間に権限、トークン予算、または環境コンテキストを更新するために利用できます。
エフォートに関する一言
Opus 4.8はデフォルトで高いエフォート設定になっています。これは、品質とユーザー体験の最良の全体的バランスだと私たちが判断しているためです。コーディングタスクでは、このエフォート水準はOpus 4.7のデフォルトと同程度のトークン数を消費しますが、パフォーマンスはより優れています。ユーザーは「extra」(Claude Codeでは「xhigh」)または「max」を選択でき、モデルはより多くのトークンを使ってより良い結果を得ます。難しいタスクや長時間にわたる非同期ワークフローでは、「extra」の使用をおすすめします。エフォートを高く設定した際のトークン消費増に対応するため、Claude Codeではレート制限を引き上げました。ユーザーは、自分のプロジェクトにとって都合のよい設定を選べます。
次は何がある?
ユーザーは、Opus 4.8が前身に対して、控えめながらも確実に改善していると感じるはずです。やるべきことはまだあります。私たちは、Opusと多くの同様の能力を、より低コストで提供するモデルの開発とリリースに取り組んでいます。
それだけではありません。Opusよりもさらに高い知能を備えた新しいクラスのモデルをリリースする予定です。Project Glasswingの一環として、現在少数の組織がサイバーセキュリティ業務に向けてClaude Mythos Previewを使用しています。この能力レベルのモデルを一般にリリースするには、より強力なサイバー保護策が必要です。私たちはこれらの保護策の開発に迅速に取り組んでおり、今後数週間で、Mythosクラスのモデルをすべてのお客様に提供できると見込んでいます。
提供状況
Claude Opus 4.8は、今日現在あらゆる場所で利用可能です。通常利用の料金はOpus 4.7から変わりません。入力トークン1百万あたり5ドル、出力トークン1百万あたり25ドルです。ファストモードの料金は、入力トークン1百万あたり10ドル、出力トークン1百万あたり50ドルです。開発者はClaude API経由でclaude-opus-4-8を使用できます。
注記
- Terminal-Bench 2.1: Terminus-2のパブリック・ハーネスを使用して、すべてのモデルのスコアを報告しました。Codex CLIハーネスでのGPT-5.5の報告スコアは83.4%です。
- OSWorld-Verified: 実世界におけるモデルの性能をより正確に反映するために、OSWorld-Verifiedの評価の実行方法を変更し、Opus 4.7のスコアを82.3%に更新しました。更新内容の詳細は、System Cardをご覧ください。
- Finance Agent v2: Gemini 3.5 FlashはFinance Agent v2で57.9%のスコアを記録しており、Gemini 3.1 Proから大きく改善しています。




