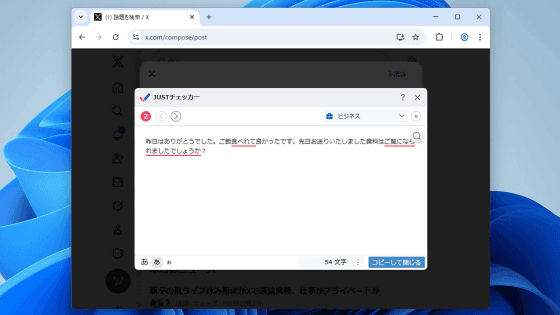
皆さんこんにちは:) タイトルのとおり、学生向けに API エンドポイントとして 48GB のワークステーションを提供したいと考えています。現在は litellm を使っているのですが、引き続きそれを使いたいです。ただ、その裏側では、いくつかの異なるモデルを提供できるように、そして学生には欲しいものを単にクエリしてもらえるように、動作させるために llama swap のインスタンスを取得したいです。ですが、メモリが残っていない場合は、そのジョブをキューに入れたいです。そういった機能はありますか?
また、私は AMD 上で動かしていますが、これによって追加の問題は発生しますか?
[リンク] [コメント]