親愛なる皆さん、
コーディングエージェントに、正しいコードを書くために必要なAPIドキュメントを提供する新しいツール Context Hub を公開できることを嬉しく思います。現代的な技術を使ってAIシステムを構築している場合、コーディングエージェントはしばしば古いAPIを使ってしまったり、引数をでっち上げたり(ハルシネーション)、あるいは使用すべきツール自体を知らなかったりします。これはAIツールが急速に進化しており、コーディングエージェントが学習されたデータが、最新のツールを反映していないために起こります。Context Hubは(あなたが使うのではなく!)コーディングエージェントが使うことを目的として設計されており、必要な文脈(コンテキスト)を提供します。さらに、エージェントによる自動フィードバックも受け付けており、コーディングエージェントが時間とともに改善できるよう支援します。
たとえば、現在おそらく最も優れたコーディングモデルであるClaude Opus 4.6は、知識のカットオフ日が2025年5月です。これに対して、OpenAIのGPT-5.2を呼び出すコードを書かせると、OpenAIが推奨する新しいresponses API(client.responses.create)ではなく、古いOpenAIのchat completions API(client.chat.completions.create)を使います。新しいAPIは1年前から存在しますが、Opusが学習されたデータには、古いインターフェースを使っているものがはるかに多く含まれています。また、2025年8月にリリースされたNano Bananaの存在も認識していません。より一般的に言えば、Geminiや多くのデータベースサービスに対して、(人気のものでも、あまり一般的でないパラメータ選択をすると)正しいAPI呼び出しができずに失敗するのを見てきました。あるいは、私が使いたい特定のツールを単に知らない、ということもあります。
その結果、私は自分のコーディングエージェントに、さまざまなサービスの使い方に関する情報を与えるために、(AIやWeb検索の助けを借りて)Markdownでドキュメントを書くことがよくあると感じるようになりました。これを、使いたいすべてのサービスについて毎回開発者が手作業で行う代わりに、週末にRohit Prsadと私が集まって、コーディングエージェントに必要な文脈(コンテキスト)を提供するためのオープンなコンテキスト管理システムを開発しました。また、このプロジェクトを手伝ってくれたXin YeとNeil Thomasにも感謝しています。
ぜひnpmを使ってContext Hub(短くchub)をインストールし、その出力の感触をつかんでみてください:
npm install -g @aisuite/chub
chub search openai # 利用可能なものを探す
chub get openai/chat --lang py # 現在のドキュメントを取得する

コーディングエージェントにchubを使わせるには、プロンプトする(例:「OpenAIを呼び出すための最新のAPIドキュメントを取得するには、CLIコマンドchubを使ってください。『chub help』を実行して、使い方を理解してください。」)か、SKILL.md を使って、chubを自動的に使うためのエージェントスキルを与える方法があります。できれば、エージェントにそれを忘れずに使うよう促してください。(Claude Codeを使っている場合は、ディレクトリ ~/.claude/skills/get-api-docs を作成し、このファイルをそこに置いてください)。
Chubは、エージェントが時間とともに改善できるようにするために作られています。たとえば、エージェントがあるツールのドキュメントが不完全だと気づき、回避策(ワークアラウンド)を見つけた場合、次回は最初から再発見しなくて済むようにメモとして保存できます。
OpenClawの爆発的な成長と並行して、エージェント向けのソーシャルネットワーク Moltbook の驚くべき台頭も見てきました。そこではエージェントが情報を共有し、互いに議論します。これに触発されて、私たちはchubを発展させ、さまざまなエージェントが、さまざまなツールについて発見したことや、ドキュメントにバグがあるかもしれない場所に関する情報を共有できるようにしていく計画です。これはまだ実装されていませんが、コーディングエージェントのコミュニティが互いに助け合う様子を見るのはきっとワクワクすることでしょう。
私たちはchubに、LLMの一般的な提供元、データベース、決済処理、ID管理ソリューション、メッセージングプラットフォームなど、人気の高いツールのいくつかについて、まず初期のドキュメントセットを投入しました。現在の一覧は こちら で確認できます。もしあなたが、人気のあるエージェント向けツールの提供者であれば、ドキュメントへの貢献を検討してください。私たちのコミュニティが協力して、Context Hubをすべての人のために改善していけることを願っています。
作り続けてください!
Andrew
DEEPLEARNING.AI からのメッセージ

公開しました: Googleとの共同制作による「Build and Train an LLM with JAX」。JAXを使って、20 millionパラメータのMiniGPTスタイルの言語モデルをトレーニングします。アーキテクチャの実装、学習データの前処理、チェックポイントの管理、チャットインターフェースを通じた推論の実行など、LLMのトレーニングワークフロー全体を扱います。今すぐ登録
ニュース

Nano Banana 2:性能/価格の向上
Googleは、旗艦の画像生成器のより安価で高速な後継となる製品を発表し、価格はおよそ半分でありながら、より高いインタラクティビティを実現しました。
新しい点: Google が発表した Nano Banana 2(正式にはGemini 3.1 Flash Imageと指定)、Gemini 3 Flashのスピードと、言語および推論における強みを活用した画像生成システムです。先代Nano Banana Proと比べて、速度は約4倍で、1枚あたりのコストはおよそ半分です。
- 入出力: 入力:テキストと画像(最大100万トークン)。出力:画像(最大4,000トークン;512x512、1024x1024、2048x2048、または4096x4096ピクセルの解像度;14のアスペクト比;1枚あたり4秒〜6秒)
- アーキテクチャ: Gemini 3 Flashに基づくモードル・オブ・エキスパーツ(Mixture-of-experts)トランスフォーマー、レンダリングモデルは非公開
- 機能: 検索(テキストと画像)、推論の2段階(最小または高)、多言語テキストのレンダリング、最大5人のキャラクターおよび14個のオブジェクトにわたる、複数の生成画像間でのキャラクター/オブジェクトの一貫性。出力には、不可視の SynthID ウォーターマークと、画像がどのように・いつ生成されたかを記録する C2PA Content Credentialsが付与されます
- 性能: 人間の嗜好を反映するtext-to-imageの指標として、 Arena.ai のリーダーボードで、GPT Image 1.5およびNano Banana Proの後塗りとして、Artificial AnalysisのText to ImageとImage Editingの「アリーナ形式」リーダーボードで2位・3位にランクイン
- 提供状況: 無料(上限あり)。Geminiアプリ、Google Ads、Google Antigravity、Flow経由で利用可能。 API では、入力が1,000,000トークンあたり$0.50、出力が画像あたり$0.045(512x512ピクセル解像度)、$0.067(1024x1024ピクセル解像度)、$0.101(2048x2048ピクセル解像度)、$0.151(4096x4096ピクセル解像度)。画像検索は月あたり最初の5,000件までは無料で、それ以降は追加1,000件あたり$14
- 非公開: アーキテクチャの詳細、パラメータ数、学習データと手法、レンダリングモデル
仕組み: Google は 、「Gemini 3 Flashに“基づいている”」ことを述べた以外は、Nano Banana 2をどのように構築したのかについて、少数の詳細しか明かしていません。Web検索による根拠付け、推論、高解像度出力といった能力は、基本的には先代のNano Banana Proと同等です。とはいえ、新しいシステムはより高速なので、出力を反復的かつ逐次的に改善しやすくなっています。 一部の ユーザー は 、テキストをより正確にレンダリングできると報告しています。
性能: Nano Banana 2は、独立したリーダーボードにおいて上位3つの画像生成器のうちの1つです。
Arena.ai のtext-to-imageリーダーボード(システム同士を直接比較し、人間の嗜好で順位付けするもの)で、Nano Banana 2 が首位 (1,280 Elo)。GPT Image 1.5(1,248)およびNano Banana Pro(1,238)よりも上位です。 Arena.ai のimage editリーダーボードでは、Nano Banana 2(Web検索を有効にした状態)が2位(1,401 Elo、予備的な結果)で、OpenAIのGPT Image(1,407 Elo)に次ぎ、Nano Banana Pro(1,398 Elo)を上回っています。ただし、Nano Banana 2のスコアは予備的(投票約3,000件)である一方、GPT Image 1.5のスコアは確立済み(投票約50,000件)です。
人工分析(Artificial Analysis)のtext-to-image リーダーボード (こちらも人間の嗜好で順位付けする直接比較)では、Nano Banana 2(1,264 Elo)は、高い推論設定のGPT Image 1.5(1,268 Elo)に後れを取り、Nano Banana Pro(Elo 1,220)には先行しています。人工分析のimage editing リーダーボード では、Nano Banana 2(1,233 Elo)は、高い推論設定のGPT Image 1.5(1,268 Elo)およびNano Banana Pro(1,250 Elo)に追随しています。
ニュースの裏側: 画像生成における競争は、ここ最近めまぐるしく激しさを増している。2025年8月下旬に投入された最初のNano Banana(正式名称はGemini 2.5 Flash Image) は 数週間のうちにGeminiアプリへ1,000万人超の新規ユーザーを呼び込んだ。11月には、GoogleのGemini 3 Proの視覚言語モデルをベースにしたNano Banana Proが、画像生成のリーダーボードで首位に立った。OpenAIは12月にGPT Image 1.5で 対応し た。これは、OpenAIがCEOサム・アルトマンの「コードレッド」指示に呼応して加速させたローンチで、Googleに追いつく必要があるというものだった。 その詳細は TechCrunch による。Nano Banana 2は、品質を高品質に設定したGPT Image 1.5の価格と比べておよそ60%低い価格で、テキストから画像へのトップの座に迫っている。
重要な理由: マーケティング資料の作成、プロダクトの可視化、ストーリーボードなどの創造的な用途では、望む構図、ライティング、スタイルに到達するまでに多くの試行錯誤が必要になることが よくある。そのため、1枚あたりのコストとスピードが重要な要素になる。ウェブ検索に基づくことで、出力を正しく得るために必要な試行回数を減らせる可能性があり、1枚あたりのコストを半分にすれば、残る分の予算が倍増する。
私たちの見立て: Nano Bananaは熟していく!

米国の戦争省がAnthropicを退け、OpenAIを受け入れる
OpenAIは、機密情報を安全に処理するAIシステムを提供するため、米軍と契約を結び、AnthropicのClaudeを置き換える。OpenAIは、自社技術がどのように使われ得るかについての制限を交渉したが、その線引きには解釈の余地が残されている。
何が起きたのか: OpenAIと米国の戦争省との 合意 が成立したのは、ホワイトハウスとAnthropicの間で1週間にわたる 対立 があったわずか数時間後だった。対立の背景には、ホワイトハウスが、監視や自律型兵器の用途で同社技術の軍事利用を制限したいとするAnthropicの意向があった。対立は、ホワイトハウスがAnthropicとの取引を禁じる 禁令 で終結した。のちにOpenAIのCEOサム・アルトマンは、彼が慌ただしく交渉して結んだ契約は「誤り」だったと 述べた 。その後、当事者間で監視や自律型兵器に関する一部の制限が再交渉され、彼の会社が「日和見的で不作法に見えた」という結果になった。Anthropicは 政府に対し 、適切な理由や権限なく事業を制限されたとして訴訟すると誓約した。
主導権争い: 米軍は少なくとも2025年の初めから、Anthropic、OpenAI、Google、xAIの大規模言語モデルの利用を拡大してきた。2025年初めには、大統領トランプが、大規模言語モデルの開発に対する障害を排除するよう連邦機関に指示していた。
- 1月3日、米軍はベネズエラに対する作戦を開始し、その際にPalantirが提供するクラウド・プラットフォームを通じてAnthropicの技術を使用した。Palantirは軍や法執行機関のデータ分析を担う。報道によれば、Anthropicの幹部らはこの利用についてPalantirに懸念を表明しており、Palantirは 会話を 政府へ伝えたという。Anthropicはのちに、ベネズエラ作戦に反対していたことを否定した。
- 翌週、戦争省は 戦闘、情報、組織マネジメントにおける 主要なAIモデルを試すためのプログラムを立ち上げた。このプログラムでは、AI企業に対し既存契約の再交渉を求めた。
- その後の交渉では、Anthropicは、Claudeを米国市民の監視に使用したり、完全に自律的な兵器を運用したりすることはできないと定めた。戦争省は、外部からの制限を受け入れないと述べた。同省は、Claudeを監視や自律型兵器に使う意図はないとしたものの、同省が受け入れることができる制限は米国の法律で必要とされるものだけだとした。
- 2月23日、xAIと戦争省は、軍が分類されたシステムにおいてGrokを「すべての合法的な用途」で使用できるようにする 合意 に到達した。
- 翌日、国防長官ピーター・ヘグセススンは、アンソピックのCEOダリオ・アモデイと会談し、同社が金曜の午後5時1分までに制限を緩めることに同意しなければ、アンソピックを「国家安全保障に対するサプライチェーン上のリスク」として指定すると誓った。米軍に物資を供給する請負業者は、サプライチェーン上のリスクとみなされる企業と取引することを禁じられている。この指定はこれまで、国家安全保障上のリスクをもたらす非米国企業に対してのみ適用されていた。
- 数時間のうちに、オープンAIもまた契約に署名した。これにより、戦争省は同社の技術を「合法的なあらゆる目的のために」使用できる一方で、同社自身の安全確保のガードレールは維持する。
- アンソピックは交渉を続けたが、「合法的な目的」についての文言には難色を示した。というのも、これまでのところ法律は、政府が過去に 米国市民を監視 するのを止めていないからだ。戦争省は、米国市民に関する、場所やウェブ上のデータを含む非機密の商用大量データを分析したいと述べた。米軍は米国市民に対する監視を行うことは禁じられているが、商用データを集約して分析することは許されている。
- 2月27日、期限の1:00 p.m.の直前――4時間前――大統領トランプは、同大統領が所有するSNSであるトゥルース・ソーシャル上で 投稿 し、全ての連邦機関に対し、6か月以内にアンソピックの技術の使用をやめるよう指示した。この投稿は、アンソピックが協力しなければ「重大な民事および刑事上の結果」が生じると脅し、アンソピックを「暴走している急進的な左派のAI企業であり、現実の世界が何を意味するのかを理解している人々ではない」と呼んだ。
- 同日の午後5時14分、ヘグセスンは、X(ソーシャル・ネットワーク)上で 発表 し、アンソピックを国家安全保障に対するサプライチェーン上のリスクとして指定した。これにより、米国の軍と取引する請負業者、サプライヤー、パートナーが同社の技術を使用することは禁止された。
- その後、いくつかの非軍事系の米国機関が アンソピック製品の使用を終了 した。
- 3月2日、オープンAIのアルトマンは 発表 し、自社の合意が急いで取りまとめられたと述べた。それは修正され、表向きは監視や自律型兵器の用途に限界を設けるためだったが、それでも実質的に大きな曖昧さが残された。修正された契約は、「商業的に取得された個人的または識別可能な情報」の分析を含む、米国市民に対する国内監視のためのオープンAI技術の使用を禁じており、これはおそらく他の種類の情報の使用を認める余地を残すものだ。また、「法、規制、または省庁の方針が人間による統制を要求するいかなる場合においても、自律型兵器を独立して指揮する」ことも禁じている。これは、おそらく別の方法で自律型兵器を運用するために、その技術を使う余地を残しているように見える。
裏側のニュース: 複数の米国の法律は、戦争省に対し、国家安全保障に対するサプライチェーン上のリスクを指定する権限を与えている。この指定によって、政府はそうした危険な企業を、防衛契約のいずれか、あるいは全ての連邦契約から排除することができ、さらに他の請負業者がそれらと協働することも認めないようにできる。この権限が公的記録上で行使されたのは昨年のみで、戦争省がロシアとのつながりを報告しているスイスのサイバーセキュリティ企業アクロニスに対し命令を出したときだった。Lawfare 報じられている。別の法律は、他の連邦省庁にサプライチェーン上のリスクを指定する権限を与えている。例えば2024年には商務省がロシアのサイバーセキュリティ企業カスペルスキーを連邦の情報システムに対するサプライチェーン上のリスクと指定し、2020年には連邦通信委員会(FCC)が中国の電子機器メーカーであるファーウェイとZTEに対し、通信サプライチェーン上のリスクだとラベルを貼っている。
なぜ重要か: AIは急速に、国家安全保障や国家としてのアイデンティティの問題と絡み合いつつある。アンソピック、ホワイトハウス、そして戦争省の間の紛争、ならびにそれがオープンAI、xAI、Googleに与える影響は、戦争を管理する政府の権限、そしてAI企業が自社モデルの使用条件を定める権限に関する制限について、難しい問いを提起する。AIを自分たちの都合のいいように使いたいと考える戦争省は前例のない罰を課した――多くの観測者にとっては、アンソピックが示した同社の毅然たる姿勢への厳しい報復に見えた―― そしてアンソピックは、裁判所がその罰を無効とするよう 判断 するだろうという信頼を示した。
私たちの見立て: 米国連邦議会は、大量監視や自律型兵器からアメリカ人を守るルールを作る責任を負っている。その責任を果たすことは、政府とAI開発者の間の衝突を未然に防ぐ可能性がある。AIの用途に適切な制限を設ける法律は、軍とテクノロジー企業の間で起きがちなそうした権力闘争を解決するための明確な指針となるだろう。
エージェントの管理
マネージャーは、部下がどのように仕事を進めているのか、どのようなリソースが必要なのか、そして何を達成しているのかを理解する必要がある。オープンAIの最新のプロダクトは、チームメイトがAIエージェントである場合に、このニーズを満たすことを目指している。
新着情報: OpenAIは Frontierを発表しました。これは、エージェントの企業内の“部隊(cadres)”をオーケストレーションするのを助けるために設計されたプラットフォームです。エージェントの構築、相互の間での情報や業務文脈の共有、パフォーマンスの評価、従業員や他のエージェントとのやり取りの管理などを行います。CiscoとT-Mobileはパイロットプロジェクトでこのシステムを使用しており、OpenAIは、HP、Intuit、Uberを含む選ばれた顧客に対して、専用のエンジニアリング支援とともにこれを提供しています。Frontierを今後数カ月の間に、まだ開示されていない条件のもとで、より広く利用可能にする予定です。
仕組み: Frontierは、関与するフレームワークやモデルに関係なく、エージェントを管理するための統一されたユーザーインターフェースを提供します。管理者は、エージェントの構築または取り込み、そのエージェントへのアクセス提供、データソースやアプリケーションとの統合、そして請求管理など、その他の機能を行えます。OpenAIはこのシステムについてあまり多くの情報を明かしていませんが、いくつかの重要なポイントを共有しています:
- 各エージェントには独自のアイデンティティ、権限、ガードレールがあり、企業はそれを利用できる従業員やグループを制御できます。
- エージェントは、データへのアクセス、ツール、アプリケーション、関連するシステムやワークフローに関する情報などを含む文脈を共有できます。
- Frontierはエージェントの出力を評価し、そのパフォーマンスを改善するためのフィードバックを提供します。販促用のイラストに基づくと、ユーザーは、たとえば大規模言語モデルを使って礼儀正しさを測るなど、正解データ(ground-truth)に基づく精度や、モデルの出力に基づく評価指標を設定できるように見えます。
- エージェントは「記憶を作り、“過去のやり取りを役立つ文脈へと変換する”」ことができます。つまり、エージェントは、以前のプロンプトに対する成功した応答を思い出すことで、時間の経過とともに自動的にパフォーマンスを向上させられることを示唆しています。
背景: Frontierは、Microsoftが Agent 365をリリースしてから数カ月後に登場します。これは、WordやExcelのようなMicrosoftアプリケーションと統合する、同様のプラットフォームです。Agent 365はセキュリティとガバナンスにより強く焦点を当てていますが、Frontierはエージェントの構築、評価、改善のための機能がより多く用意されています。
重要な理由: 企業がより多くのエージェントを稼働させるほど、それらを大規模に管理する能力の価値は高まります。たとえば、あるグループが社内で展開するエージェントは、別の広い用途を持つ可能性があり、あるいは、異なるグループによって展開されたエージェント同士が機能を重複させたり、目的が食い違ったりすることもあります。このような機会や問題は、統一された統制インターフェースによってより明確になるかもしれません。OpenAIとMicrosoftのエージェント管理システムは、チームがより高いレベルからこれらの活動を管理できるようにすることを目指しています。
考えていること: 概念的に、エージェントのための「人事(human resources)」システムがあるのは筋が通っています。このようなシステムは、OpenAIによる限定的な展開と、エンジニアリング支援の提供が示すとおり、まだ始まったばかりです。しかし、企業がそれぞれの代わりにより多くのエージェントを動かすようになるにつれて、その実用性は明確で、今後さらに大きくなる可能性が高いです。
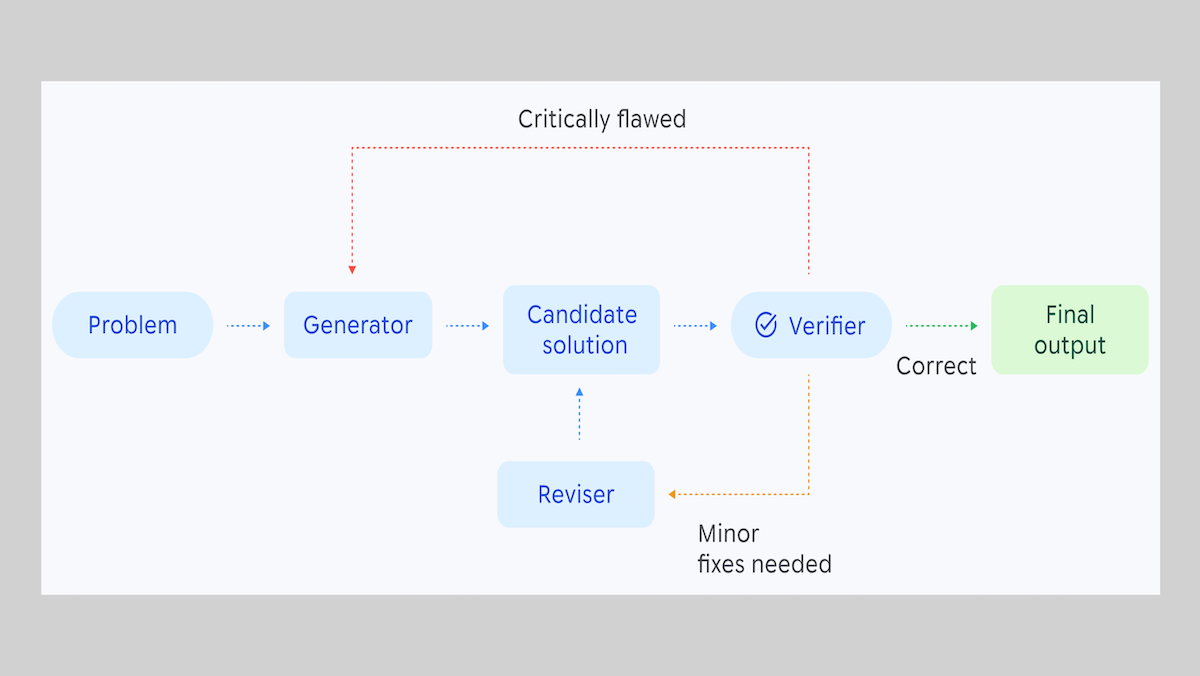
エージェントが頑固な 数学の問題を解く
LLMは数学のコンペティションで金メダル級の性能を達成しています。エージェント型のシステムは、数学的研究においても 強み を示しました。
新着情報: Tony Feng、Quoc V. Le、Thang Luong、そしてGoogleの同僚たちは Aletheiaを導入しました。これは、これまで未解決だった数学の問題に対して、解答を生成し、検証し、修正するエージェントです。Aletheiaは数学研究のためのエージェント型ワークフローで、同社の最上位AIサービスの契約者向けに提供されるGemini 3 Proモデルの専門的な推論モードであるGemini 3 Deep Thinkの最新アップデートを使用します。同時にGoogleは、API経由でもGemini 3 Deep Thinkをより広く利用可能にしました。
Gemini 3 Deep Think: GoogleはDeep Thinkを、数理、科学、工学における多段階タスク向けの、最も先進的な推論モードだとして提供しています。並列で複数の推論チェーンを生成し、それらを考慮し、最終的な出力を作るために、修正または統合を行います。
- 入出力: 入力:テキスト、画像、動画、音声、pdf(最大100万トークンまで);出力:テキスト(最大65,000トークン)
- 性能: HLE(ツールなしで48.4パーセント)、ARC-AGI-2(84.6パーセント)、Codeforces(3455 Elo)、GPQA Diamond(93.8パーセント)で先端水準を達成
- 提供形態: Geminiアプリ(Google AI Ultraサブスクリプション:$250/月)経由、API経由で 早期アクセス
- 機能: Web検索、コード実行
- 未開示: Googleは、Gemini 3 ProおよびDeep Thinkの機能をどのように構築したかについて、ほとんど情報を開示していません
仕組み: Aletheiaは、3つの要素( ジェネレーター、検証者、改訂者 — )からなるエージェント型ワークフローで、すべてGemini 3 Deep Thinkによって実行されます。
- 問題が与えられると、ジェネレーターが初期の解答を生成します。
- 検証者はその解答を確認し、完了しているか、修正が必要か、または致命的に不正確かのいずれかの印を付けます。
- 解答が修正を要する場合、改訂者が問題と解答を受け取り、解答の修正版を生成して、その内容を検証者にフィードバックします。
- 解答が致命的に不正確な場合、ジェネレーターが改めて問題を受け取り、新しい解答を生成します。
- 検証者が問題を解けたと判定するまで、または著者が設定した回数のモデル呼び出しが行われるまで、このプロセスが繰り返されます。
結果: 研究者たちは、これまでにAletheiaを6本の公開論文で使用しています。Aletheiaが実質的にほとんどの作業を行ったものが2本、人間とAletheiaの双方が重要な貢献をしたものが2本、人間がほとんどの作業を行いAletheiaが少し手伝ったものが2本です。著者らは、Aletheiaは数学のサブ分野にまたがる幅広い知識が役立つ状況ではうまく機能する一方で、サブ分野内における深さでは人間の専門家ほどではないと述べています。
- その論文の1つは、解決されていないエルデ̄シュ問題に対して4つの新しい解決策を提示している。エルデ̄シュ問題とは、数学者 ポール・エルデ̄シュ によって提案された、難解な数学的な予想の集合である。残りの 700 の未解決エルデ̄シュ問題のうち、アレイシアはそのうち212件に対する解決策を見つけたという。
- 数学者たちは212件の解決策を検討し、200件では正しい/誤っていることを確認した。(残りの12件では、問題または解決策が曖昧だった。)200件のうち、137件(68.5%)は誤りであり、63件(31.5%)は問題文のある解釈のもとでは技術的に正しく、13件(6.5%)は意図された解釈のもとで正しかった。
- 著者たちは、独自性を評価するために13件の正しい回答を調べた。その問題はすでに9件のうちで解決されていた。アレイシアは、既存の研究から解決策を特定するか、あるいは既存の研究の中に解決策が存在している問題を解いた。
- 残りの4つの解決策は新規だった。
ニュースの裏側: AIを支援した証明は、限定的ではあるが実際の成功を収めてきた。ほとんどの previous work では、研究者らはアレイシアのような汎用的なシステムを構築するのではなく、LLMを用いて特定の定理の証明を手助けするようにしていた。これに最も近いのは、おそらくGoogleの AlphaEvolve だろう。これは、データセンターにおける計算資源の割り当てスケジューリングのためのアルゴリズムを改善し、行列の積を計算するために、アルゴリズムとコードを進化させるエージェント型システムである。
なぜ重要か: エージェント型システムは、数学者と協働して新しい手法やロードマップなどを生み出すことができる、有用な数学ツールになりつつある。アレイシアのように、エージェントの強みが幅広い知識であるなら、多くの分野にまたがる知識に関わる問題に対する研究を加速させる可能性がある。一方で、人間の専門家は引き続き自分の得意分野に深く取り組むだろう。
私たちの見立て: エルデ̄シュは、1930年代初頭から1996年の死去までの間に、ほぼ1,200もの問題を提案した。500未満が解決されているが、AIモデルが 支援して 過去6か月だけでもそのうち約100件を解決するのに役立ったのだ!




