LinkedInのフィードは13億人以上のメンバーに届く — そしてそれを支えるアーキテクチャは追いついていなかった。システムは、それぞれ独自のインフラと最適化ロジックを備えた5つの別々の取得パイプラインを蓄積しており、ユーザーが見たいと思う可能性のあるさまざまな切り口を提供していた。会社のエンジニアは過去1年間、それを分解して、単一のLLMベースのシステムに置き換える作業を行った。その結果、LinkedInはプロフェッショナルな文脈をより正確に理解し、スケール時の運用コストが低くなるフィードになると述べている。
リデザインはスタックの3層にまたがりました:コンテンツの取得方法、ランキングの方法、基盤となる計算リソースの管理方法です。ティム・ユルカ、LinkedInのエンジニアリング担当副社長はVentureBeatに対して、チームが過去1年にわたって数百のテストを実施し、インフラの大部分を再構築するマイルストーンに到達したと述べました。
「私たちはコンテンツ取得全体のシステムから出発して、LinkedIn上のコンテンツをはるかに豊かに理解し、会員に対してはるかに個別化された形でマッチングできるよう、非常に大規模なLLMを使うように移行しました」とユルカは述べた。「さらに、コンテンツのランキング方法まで、非常に大規模なシーケンスモデル、生成型レコメンダーを用い、エンドツーエンドのシステムを組み合わせて、会員にとってより関連性が高く意味のあるものにしていくのです。」
ひとつのフィード、13億人のメンバー
中核の課題は2つの側面だとユルカは言った。「LinkedInは、会員が公言する職業上の関心事――職位、スキル、業界――を、時間を経ての実際の行動と照合しなければならない。そして、直近のネットワークが投稿している内容を超えたコンテンツを表示しなければならない。これらの2つの信号はしばしば異なる方向に引っ張り合う。」
「人々はLinkedInをさまざまな用途で利用します。業界内の他者とつながることを重視する人もいれば、思想的リーダーシップを重視する人もいます。就職活動者と採用担当者は候補者を見つけるために使用します。」
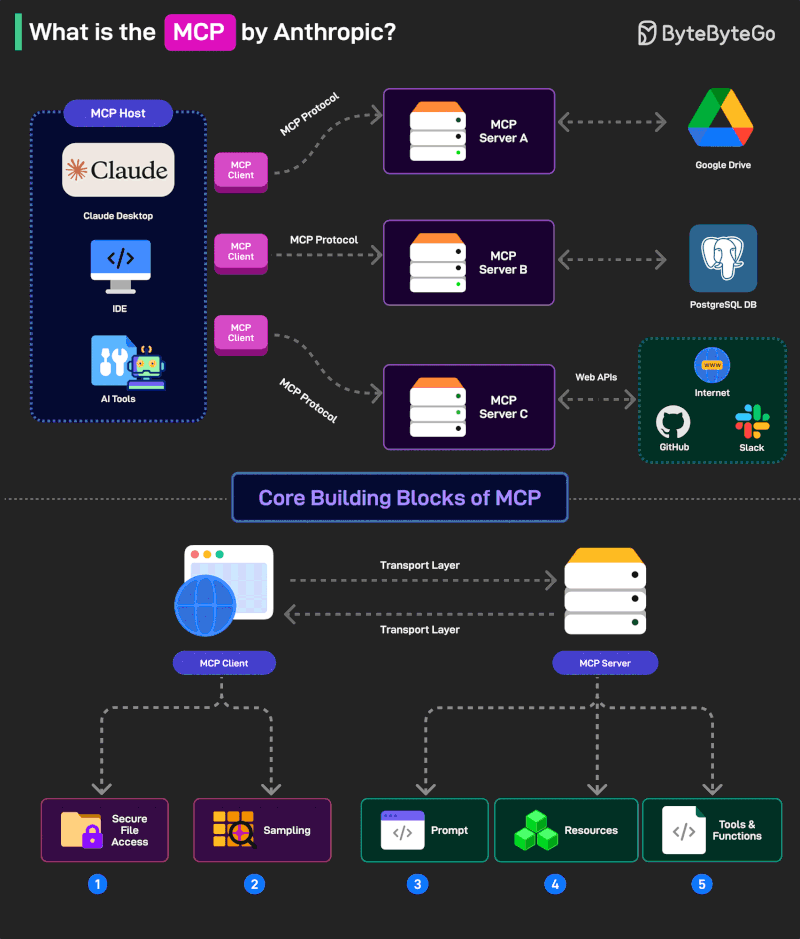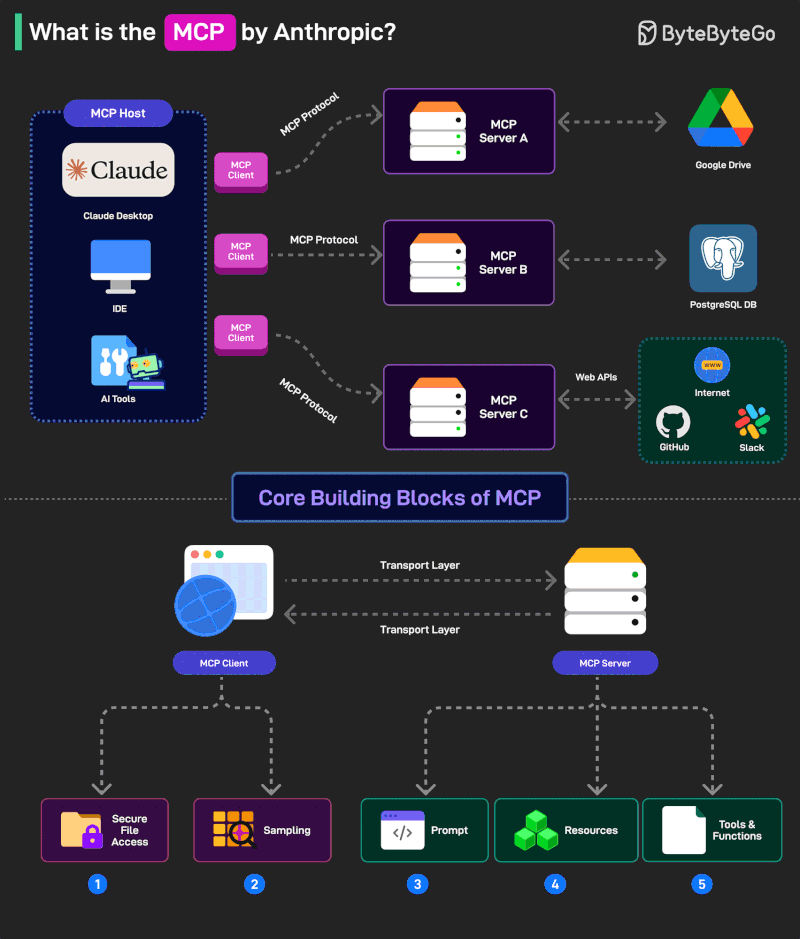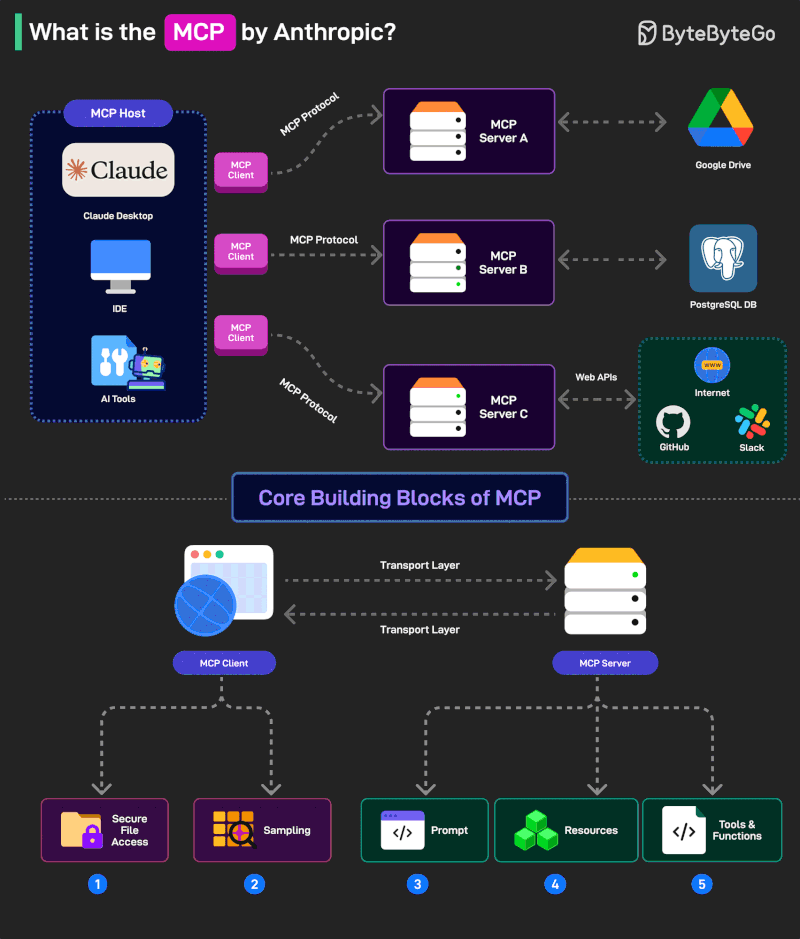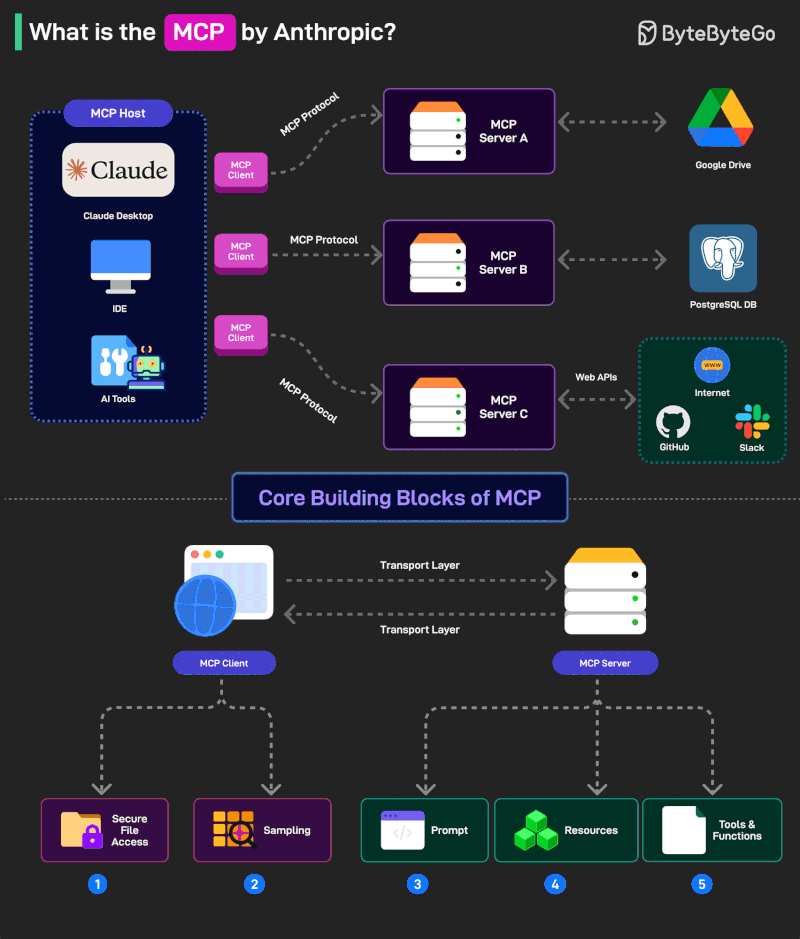
LinkedInが5つのパイプラインを1つに統合した方法
LinkedInは過去15年以上にわたり、AI主導の推薦システムを構築してきました。その中にはジョブ検索と人材検索に関する以前の取り組みが含まれます。LinkedInのフィードは、ウェブサイトを開いたときに出迎えるもので、同社はブログ記事で、異種混在のアーキテクチャを基盤として作られていました。ユーザーに提供されるコンテンツは、ユーザーのネットワークの時系列インデックス、地理的トレンドトピック、興味ベースのフィルタリング、業界別コンテンツ、その他の埋め込み型システムなど、さまざまなソースから来ていました。
この方法は、それぞれのソースが独自のインフラと最適化戦略を持つことを意味していました。しかし機能してはいましたが、保守コストは急増しました。新しい推薦アルゴリズムをスケールさせるためにLLMを使用することは、フィード周辺のアーキテクチャも更新することを意味すると、ユルカは述べました。
「その点には多くの要素が関わります。例えば、プロンプト内でそのような会員コンテキストをどう維持するか、モデルを適切に動かすためのデータ、プロフィールデータ、最近の活動データなどをどう提供するか、などです」と彼は語った。「そして第二は、LLMを微調整するために、最も意味のあるデータポイントを実際にどのようにサンプリングするか、ということです。」
LinkedInはオフラインのテスト環境でデータの組み合わせの異なる反復を試しました。
LinkedInの取得システム刷新の最初の障害の1つは、データをLLMが処理するためのテキストへ変換することでした。これを行うために、LinkedInはテンプレート化されたシーケンスを作成できるプロンプトライブラリを構築しました。投稿については、形式、著者情報、エンゲージメント数、記事メタデータ、投稿のテキストに焦点を当てました。会員については、プロフィールデータ、スキル、職歴、教育歴、そして「過去に関与した投稿の時系列順のシーケンス」を組み込みました。
そのテスト段階で最も影響力のある発見の1つは、LLMが数字を扱う方法でした。ある投稿が12,345ビューを持っていた場合、その数値はプロンプト中に「views:12345」のように現れ、モデルはそれを他のテキストトークンと同様に扱い、人気指標としての重要性を失わせてしまいます。これを修正するために、エンゲージメント数をパーセンタイルのバケットに分け、それらを特別なトークンで包み、モデルが非構造化テキストと識別できるようにしました。この介入は、投稿の到達範囲をシステムが重みづけする方法を実質的に改善しました。
フィードに専門的な履歴をシーケンスとして読み取らせる
もちろん、LinkedInのフィードをよりパーソナルに感じさせ、投稿が適切なオーディエンスに届くようにするには、投稿のランキング方法を再設計する必要があります。従来のランキングモデルは、人々がコンテンツとどのように関わるかを誤解していると同社は述べています:それはランダムではなく、誰かの職業的な歩みによって生まれるパターンに従うのです。
LinkedInは、相互作用の履歴をシーケンスとして扱う、独自のGenerative Recommender(GR)モデルをフィード用に構築しました。これは“時間の経過とともに関与した投稿を通じて語られる専門的な物語”として表現されます。
「GRは、各投稿を孤立して評価するのではなく、あなたの過去の歴史的な1,000件以上の相互作用を処理して、時間的パターンと長期的な関心を理解します」とLinkedInのブログは述べています。「取得と同様に、ランキングモデルは職業的シグナルとエンゲージメントパターンに依存し、人口統計属性には依存せず、会員基盤全体にわたって公正な扱いが定期的に監査されます。」
LinkedInの規模でLLMを運用する際の計算コスト
新たに強化されたデータパイプラインとフィードで、LinkedInはまた別の問題に直面しました:GPUコスト。
LinkedInはGPUへの依存を減らすために新しいトレーニングインフラに多額を投資しました。最大のアーキテクチャの転換点は、CPUに束縛された特徴処理をGPU集約型のモデル推論から切り離すことでした—それぞれの計算タイプを、その適した役割のままにして、GPUの可用性に頼りすぎないようにすることです。チームはまた、Pythonのマルチプロセッシングが追加していたオーバーヘッドを削減するためのカスタムC++データローダを作成し、推論時のアテンション計算を最適化するためのカスタムFlash Attentionバリアントを構築しました。チェックポイント作成は直列化ではなく並列化され、利用可能なGPUメモリをより有効に絞り出せるようになりました。
「我々が設計に取り入れなければならなかったことの1つは、望むよりもはるかに多くのGPUを使う必要があるという点でした」とユルカは言いました。「CPUとGPUのワークロードをどのように調整するかについて非常に意図的であるべきです。なぜなら、これらの種類のLLMと、それによって埋め込みを生成する際のプロンプト文脈の利点は、動的にスケールさせられるからです。」
推奨システムや取得システムを構築するエンジニアにとって、LinkedInのリデザインは、断片化されたパイプラインを統一埋め込みモデルに置換する際に実際に必要なことの具体的なケーススタディを提供します:プロンプトにおける数値信号の表現を再考し、CPUとGPUのワークロードを意図的に分離し、ユーザの履歴を「独立したイベントの集合」ではなく「シーケンス」として扱うランキングモデルを構築することです。教訓は、LLMsがフィードの問題を解決するということではなく、これらを大規模にデプロイすることが、元々直面していた問題とは異なるクラスの問題を解くことを強いる、という点です。