親愛なる皆さん、
私たちは、AIのどの分野が得意か、どこでさらに学べるか、そしてスキルを伸ばし続けるために次に何をすればよいかを理解するのに役立つ Skill Builder ツールを公開したところです。ぜひ、このツールとの対話をしてみてください。
AIにはたくさんの仕事の機会があります。雇用主は、AIスキルを持つ人材の採用を熱望しています。しかし、AI技術の世界は広大で、成長を続けており、しかも急速に変化しています。この状況を乗りこなすには、次にどこへ進むべきかを判断するうえで、知識のある信頼できるメンターと時折行う会話が役立つと感じる人が多いようです。
私たちのSkill Builderは、その役割を担います。AIプロジェクトについて教えてください。すると、いまどの位置にいるのかについてパーソナライズされたフィードバックを返し、AIスキルを次のレベルへ引き上げるための方法も提案します。これは、ChatGPTにプロンプトを出すことだけでAIを使う初心者から、複数のAI構成要素と高度な開発プロセスを用いて複雑なエージェント型ワークフローを構築している上級者まで、誰を対象にしています。
新しいスキルを学ぶとき、自分がこの分野のどこにいるのかを理解するのが難しいと感じます。なぜなら、まだ「自分が分からないこと」を知っていないからです。Skill Builderは、AIスキルに関してこの課題に対応します。誰でも無料で使え、多くの方が対話内容は参考になったと報告しています。対話の後には、全員に要約レポートを表示し、次に何を学ぶべきかを推薦します。DeepLearning.AI Proのメンバーは、さらに詳細なパーソナライズドフィードバックも受け取れます。
自分のスキルを確認しているのか、次に取り組むプロジェクトを決めているのか、どのコースを選ぶのかを検討しているのか、あるいは就職面接の準備をしているのかにかかわらず、Skill Builderが明確さをもって前に進む助けになることを願っています。
スキルを作り続けてください!
アンドリュー
DEEPLEARNING.AI からのメッセージ

アプリを作るのに、コードを学ぶ必要はありません。Build with Andrewでは、Andrew Ngが、シンプルな指示でアイデアを実際に動くWebアプリへ変える方法を紹介します。初心者に最適で、始めたくても待っていた相手に共有しやすい内容です。 今すぐ講座を見てみましょう!
ニュース
Geminiがリードを奪取
Googleは旗艦モデルのGeminiを更新し、いくつかのベンチマークで首位に立ちつつ、性能あたりのコストでは競合を下回りました。
新しい点: Google 「起動」 しました。価格は、前世代のGemini 3 Pro Previewと同額で、Gemini 3.1 Pro Previewを発表しています。Gemini 3.1 Pro Previewは、Gemini 3 Deep Thinkによる、最近のパフォーマンス向上の基盤です。Gemini 3 Deep Thinkは、API経由で利用可能な3つの推論レベルとは別の、専用推論モードです。
- 入出力: 入力:テキスト、画像、PDF、音声、動画(最大100万トークン)/出力:テキスト(最大64,000トークン、1秒あたり108.6トークン)
- アーキテクチャ: Mixture-of-experts transformer
- 機能: ツール使用(Google検索、Pythonコード実行、ファイル検索、関数呼び出し)、構造化出力、調整可能な推論(低・中・高)
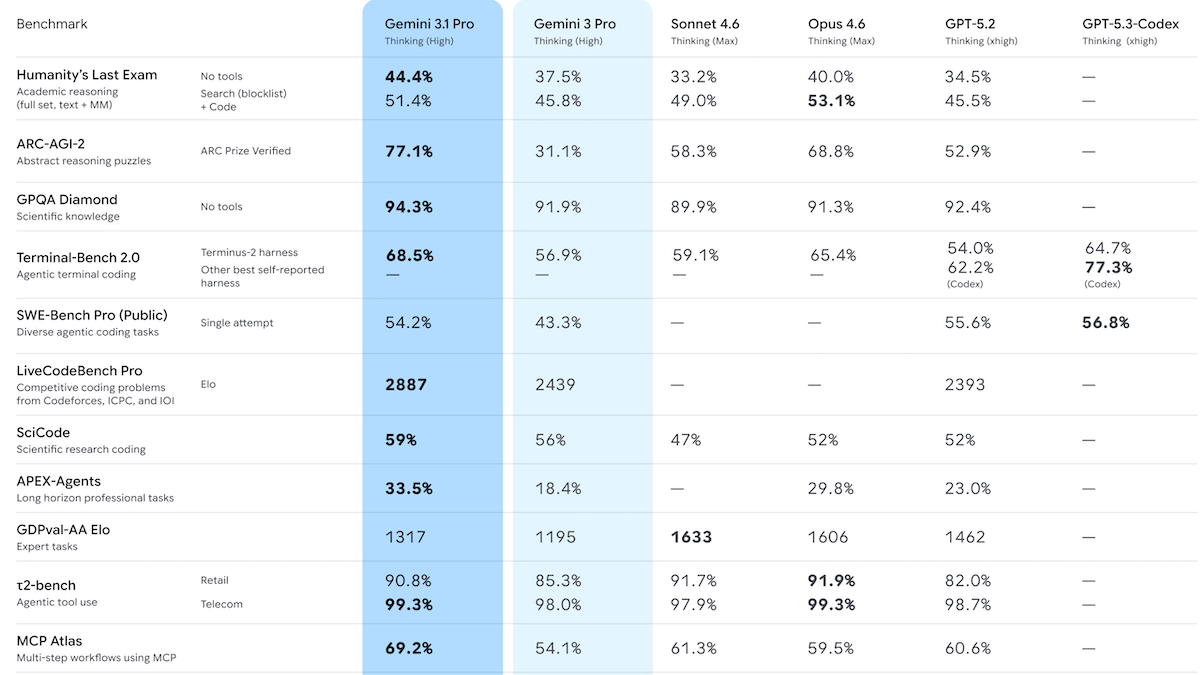
- パフォーマンス: 推論付き(レベルは未指定)のGemini 3.1 Pro PreviewがArtificial Analysis Intelligence Indexでトップに。ARC-AGI-2、GPQA Diamond、Humanity’s Last Exam、MCP Atlas、BrowseComp、Terminal-Bench 2.0、MathArena Apex、MMLU-Proで最先端の成果を達成
- 提供/価格: Geminiアプリを通じてGoogle AI ProおよびUltraの加入者に提供。Google AI Studio、Vertex AI、Gemini CLIといった有料サービスに統合されており、Microsoft Visual StudioやGitHub CoPilotを含むサードパーティツールとも連携しています。 API は、入力コンテキストが200,000トークン未満の場合、入力/キャッシュ済み/出力トークンあたり100万トークンにつき$2/$0.20/$12。入力コンテキストが200,000トークン超の場合、入力/キャッシュ済み/出力トークンあたり100万トークンにつき$4/$0.40/$18(加えてキャッシュ済みトークン100万あたり1時間あたり$4.50)
- 知識のカットオフ: 2025年1月
- 非公開: パラメータ数、アーキテクチャの詳細、学習方法
仕組み: GoogleはGemini 3.1 Pro Previewに関する詳細をほとんど開示していません。このモデルは、テキスト、コード、画像、音声、動画からウェブ上でスクレイピングしたものに加え、ライセンスされた資料、Googleのユーザーデータ、合成データで事前学習された疎な混合専門家(Mixture-of-Experts)型トランスフォーマーです。複数ステップの推論、問題の解決、定理の証明を扱うデータセットで強化学習により微調整されました。さらに、その モデルカード では、読者に Gemini 3 Proモデルカードを参照するよう促しています。
性能: Gemini 3.1 Pro Previewは、Artificial Analysisが実施したテストで、多様な最先端の指標を達成しました。しかし、エージェント的な振る舞いとユーザーの嗜好ランキングに関するいくつかの評価では後れを取りました。テスト結果の一部は推論設定を明記していません。Gemini 3.1 Pro PreviewへのAPI呼び出しは高推論(high reasoning)をデフォルトとしています。
- Artificial Analysisの Intelligence Index(経済的に有用な作業に焦点を当てた10のベンチマークの加重平均)では、推論ありのGemini 3.1 Pro Preview(費用$892で57ポイント)が、最大推論に設定されたClaude Opus 4.6(53ポイント、$2,486)、xhigh推論に設定されたGPT-5.2(51ポイント、$2,304)、オープンウェイトのGLM-5(50ポイント、$547)を上回りました。さらに Indexの10項目中6項目で首位に立ちました。
- しかし、Gemini 3.1 Pro Preview(推論は未指定)は、ブラインドな対決(head-to-head)でのユーザー嗜好によりモデルをランキングする Arenaで、コーディング部門において7位にとどまりました。
- また、Artificial Analysisの GDPval-AAというエージェント的なベンチマークでも遅れを取り、達成率は40%でした。Claude Sonnet 4.6(最大推論で57%)やGLM-5(45%)に後れを取っています。
- ARC-AGI-2 の視覚ロジックパズルでは、Gemini 3.1 Pro Previewはタスクあたり$0.96で77.1%を達成しました。これは、前身モデルの31.1%を大きく上回り、2倍以上です。また、Claude Opus 4.6(高推論で69.2%、タスクあたり$3.47)を大きく上回っています。
なぜ重要か: Gemini 3.1 Proの伸びは、推論時の追加計算よりも、モデル品質の改善に起因するように見えます。Artificial AnalysisのIntelligence Indexを完了するにあたり、前身モデルとほぼ同じ数のトークンを消費していたにもかかわらず、スコアは大幅に高くなっています。これは、推論コストを膨らませなくても、モデルを洗練することで重要な性能向上が得られることを示唆しています。
考えどころ: ARC-AGI-2では、おそらく高推論に設定されているGemini-3.1 Pro Previewの性能は、Gemini 3.1 Deep Think(85%対77%)に対して10%未満の差ですが、コストは13分の1以下です(タスクあたり$0.96対$13.62)。これは、Deep Thinkを最も難しい問題に取っておくことの後押しになります。

Global AI Summit Shows Optimism
第4回のグローバルAIサミットは、理論上の危険性に焦点を当てることから、AIの恩恵を世界中に広めることへと、決定的な転換を示しました。
新しい動き:南半球で開催される最初のグローバルAIサミットとして銘打たれた AI Impact Summit は、インドが米国や中国に対する形勢の均衡(バランス)としての役割を担うという意欲を披露しました。この counterweightの構想です。今年の政府関係者、ビジネスリーダー、研究者が集まった会合は、2月16日から2月20日までニューデリーで開催されました。
仕組み: 南半球で開催される最初のグローバルAIサミットとして打ち出されたこの会議には、数十万人規模の参加者と、100か国以上の代表者が集まりました。インド、ブラジル、フランス、スペイン、ボリビア、モーリシャス、スリランカの各国の指導者に加え、国連事務総長のアントニオ・グテーレス、ホワイトハウスの科学技術政策局の局長であるマイケル・クラッツィオス、そしてAlphabetのサンダー・ピチャイ、OpenAIのサム・アルトマン、Anthropicのダリオ・アモデイといった著名なCEOも出席しました。しかし、ある参加者は 報告 しています。「中国の参加はほとんどなかった」。日程が中国の旧正月の祝賀と重なったためです。
- 米国や中国を含む85か国以上が、AI Impactに関するニューデリー宣言を支持しました。これは拘束力のない合意であり、AIを、狭い意味での国家的または企業的な優位性ではなく、経済成長、社会の善、そして共通のグローバルな利益のために活用することを目的としています。宣言では7つの原則が強調されています。AI資源の民主化、社会的エンパワーメント、経済成長と社会の善、安全で信頼できるAI、科学のためのAI、スキルと教育の育成、そして持続可能なAIシステムです。
- 首脳級の演説でネンドラ・モディ首相は インド を、多様な層に向けた手頃なテクノロジーの原動力として売り込んだ。モディは、インドのテクノロジー人材の供給、公的な技術インフラ、そしてスタートアップのエコシステム(世界で3番目に規模が大きい)を挙げて、その強みを宣伝した。
- 主要なAI企業は、インドでの存在感を拡大した。アンソピックとオープンAIはそれぞれ、ベンガルールとムンバイにオフィスを開設した。オープンAIは 発表 したところによると、タタ・コンサルタンシー・サービシズのデータセンターを利用し、同社の ChatGPT Enterpriseサービスを提供するという合意を結んだという。グーグルは、南東部の港湾都市ビシャーカパトナムにAIハブを構築することを約束し、さらに 追加の海底ケーブルをインド、米国、そしてその他の国々の間でルーティングする ことを約束した。
- 人権団体は、AIガバナンスにおけるギャップに取り組めていないとして、このサミットを批判した。例えばアムネスティ・インターナショナルは 指摘 したところによると、「インドにおけるAIは、すでに有害な状況における市民的権利侵害の文脈の中で、マス・サーベイランスのシステムに寄与している」という。団体はサミットを「拘束力のある権利保護を前進させるうえで、ほぼ無関係で効果がない」とし、「デジタル面で安全な未来に向けた規制」を求めた。
ニュースの裏側: 主要なAI企業がそこに投資することを約束し、国の政府が自国のAIへの支出を増やしているため、インドは注目の的になっている。
- グーグルは、人工知能ハブを設立するために5年間で150億ドルを投じることを約束した。マイクロソフトは、インドのクラウドおよびAIインフラに4年間で175億ドルを投資する。アマゾンは、2030年までに350億ドルを使ってインドでの事業を構築する計画だ。
- 会議が始まると、インドは 11億ドルを割り当て 、AIやその他のハイテク分野のスタートアップを支援するための資金とした。
- 政府は 国内のスタートアップに資金提供 し、比較的少ない処理予算で動かしながら、公式に認められた22の言語を処理できるモデルを構築できるようにした。
なぜ重要か: AIの推進は世界的な取り組みであり、各国政府間のコミュニケーションは重要な一要素だ。今年のサミットは、処理と接続へのアクセスを確保することや、市場における競争を促すことといった、現実的な課題に焦点を当てた。これは、初回イベントを支配していた非現実的なSFめいた不安からの歓迎すべき変化だ 2023 。今年の前向きな空気は、 2024 と 2025 のサミットが、参加者にAIの価値を認識させるのに役立ったことを示している。同時に、批評家たちは、AIの急速な拡大を民主主義の価値観に沿わせるという、いまだ続く難題を指摘していた。
考えていること: 世界のリーダーが集まり、話し続けることが重要だ。AIサミットが継続しており、各国政府がAIをすべての人の利益のために活用しようとしていることを心強く思っている。
エージェンティックAIに対する投資家のパニック
大企業を動かすソフトウェアを作る企業の株価は、投資家が「AIシステムが自社の事業を損なう可能性がある」と懸念したことで急落した。今週、それらの銘柄は、アンソピックが同じような企業の一部と提携したことで、ある程度は反発した。
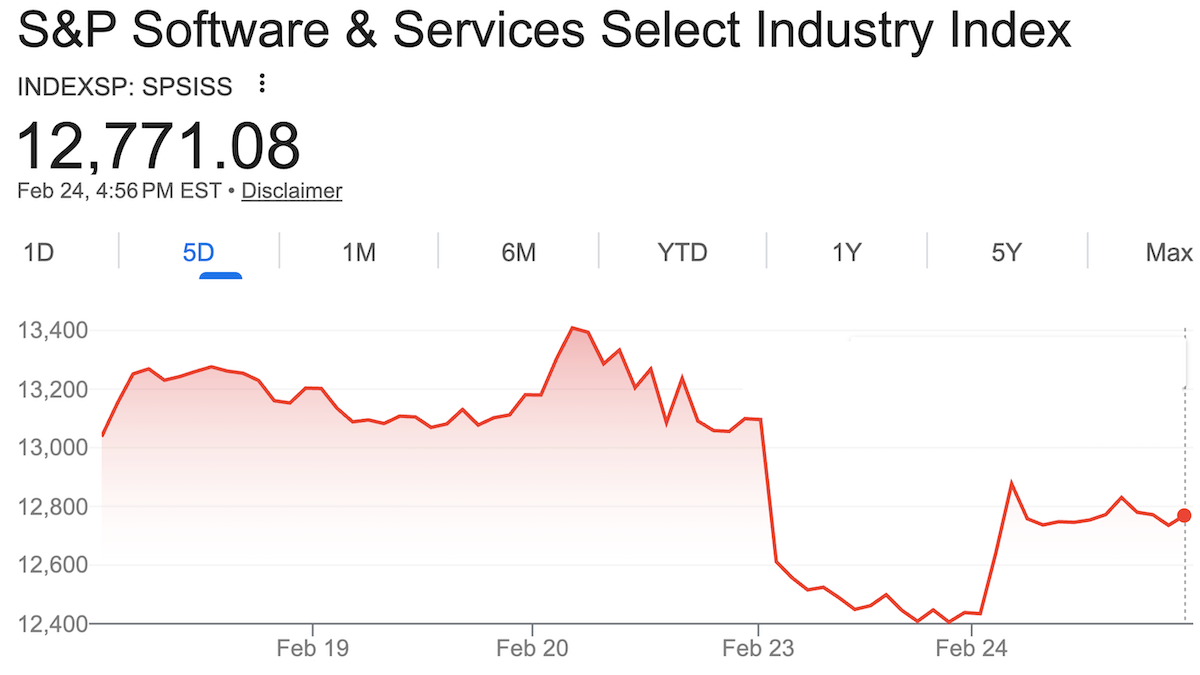
新しい動き: AIを使ったコーディング・システムが、人気のソフトウェアツールを再現できてしまうのではないかという見通しに、投資家が警戒を強めた結果、S&P Software & Services Index(マイクロソフト、オラクル、セールスフォース、ワークデイなどのソフトウェア大手を含む)が押し下げられた。同指数は、アンソピックがプロ向けのエージェントであるClaude Coworkを導入した1月12日から、回復の兆しが見え始めた2月23日までの間に 価値の25%を失った 。
SaaSpocalypse(サースペコラプス)到来: 株の売りが強まった影響は主に、SaaSとして知られる「ソフトウェアのサブスクリプション(ウェブ経由)」のベンダーに及んだ。投資会社Jefferies Financial Groupのストラテジストであるジェフリー・ファヴッザは、この出来事を「SaaSpocalypse」と名付けた。
- Anthropicは、SaaSが通常担っているタスクを引き受けることを目的としたさらなるリリースで火に油を注ぎました。1月30日、Anthropicはホワイトカラー職の業務機能をそれぞれ対象とする、11のオープンソース プラグインを公開しました。対象となる機能には、カレンダー管理、ドキュメントの検索と取得、営業、財務分析、データのクエリと可視化、法務レビューとコンプライアンス、マーケティング、カスタマーサポート、プロダクト管理、そして生物学研究があります。加えて、新しいプラグインを作成しカスタマイズするプラグインも含まれています。独立した開発者たちはすぐにプラグインの波を提供し、他のビジネスソフトに近い機能を実現しました。
- それから4日後、S&Pソフトウェア&サービス・インデックス は4%下落 し、市場の時価総額で2850億ドル超を吹き飛ばしました。JPMorganのソフトウェア指数 は7%下落 しました。LegalZoom.comの株価は約20%急落し、トムソン・ロイターは16%下落でした。
- 2月20日、Anthropicは Claude Code Securityを発表しました。これは、人間のレビューの後にソフトウェアの脆弱性を検出して修正パッチを当てることを目的としたサイバーセキュリティ・アプリケーションです。これに続いて、セキュリティ・ソフトウェア企業の株式が 売られる 事態が起きました。(GoogleのCodeMenderやOpenAIのAardvarkも同様に、AIを活用したセキュリティ機能を提供します。)
- 2月24日、Anthropicはソフトウェア企業に向けて親善の一手を打ちました。同社は 発表 したのは、Coworkが脅かすとされていた一部の企業との統合です。対象にはDocusign、FactSet、GoogleのGmail、Intuit、Salesforceが含まれます。彼らのアプリケーションを迂回するのではなく、新たなCoworkプラグインは直接それらと接続します。さらにこの新しいアプローチにより、企業はプラグインがどのように使われ、どのように監視されるかについてより多くのコントロールを持てるようになります。SaaS株は上昇しましたが、先の損失は回復していません。
ニュースの裏側: AIを使ったコーディングの台頭により、観測者の中には、AIが能力を複製するか、エージェントによって人間の利用者を置き換えることで、従来のソフトウェアを混乱させる可能性があると示唆する人もいました。後者の シナリオでは、AIは、顧客が特定のサービスへの“ロックイン”から抜け出すことを可能にします。つまり、別のベンダーのユーザーインターフェースやワークフローに適応したくないために、顧客がそのサービスに忠誠を保ち続ける状態のことです。12月、AI支援によるコーディングツールを作るCursorの開発者教育担当副社長であるLee Robinsonは、彼の会社が 以前に支払っていたコンテンツ管理システム(Sanity)を、ゼロから自社で構築したカスタムセットアップによって完全に置き換えた、と書いていました。同社は現在、gitを使ってWebページを管理し、継続的な費用として数万ドルを節約しています。SanityのスポークスマンであるKnut Melværは、Sanityの製品は、Cursorのセットアップでは容易に再現できない共同作業を促進するなどの目的に役立つ、とする公開 返信 を寄せました。
なぜ重要か: 投資家がパニックになった可能性はありますが、注意の向け先は間違っていません。AIはソフトウェア市場を変えています。それでも、多くのSaaS企業は引き続き繁栄し、新たな機会も生まれ続けるでしょう。大規模言語モデルは競争上の障壁の一部を溶かし得ますが、他の障壁は堅固なままです。これは、FintoolのCEOであるNicolas Bustamanteが示唆に富むソーシャルメディア 投稿 で説明している通りです。エージェントは、見慣れないユーザーインターフェースで動作し、複雑な業務プロセスをたどり、公的なデータセットにアクセスし、複数分野の専門性を1つのアプリケーションにまとめてしまえます。一方で、LLMに基づくシステムは、専有データ、規制対応、ネットワーク効果、組み込み取引に依存するSaaS提供を、必ずしも置き換えられるとは限りません。「SaaSpocalypse」のメッセージは、ソフトウェアが死ぬということではありません。小さなチームが競争力のあるプロダクトを迅速に作れるようになり、そして“持続力”のあるプロダクトは、LLMの手の届かないところにあるリソースを土台にして作られる、ということです。
私たちの見立て: SaaSは死にません。AIネイティブ化していくのです。
ローカルAIはクラウドの代わりになれるか?
大規模言語モデルの出力需要の見通しが、データセンターの大規模な増設を後押ししています。研究者たちは、ローカルの端末上で動く小型モデルが、その負荷を実質的に軽減できるのかどうかを尋ねました。
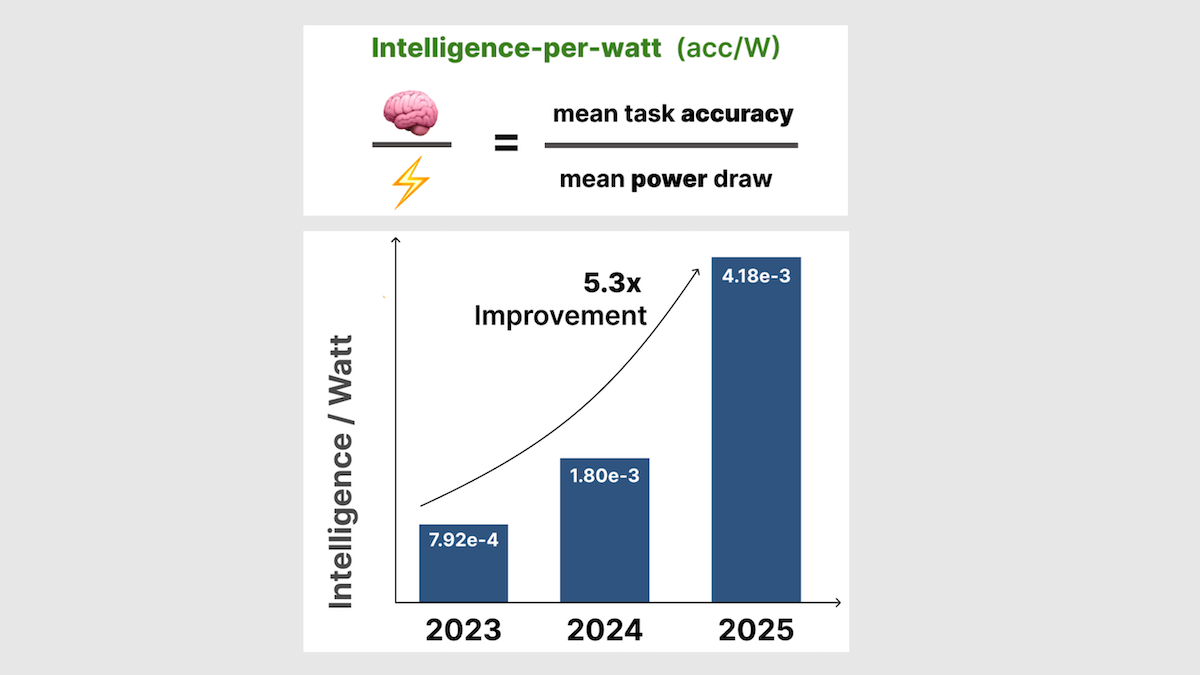
新着: Jon Saad-Falcon、Avanika Narayan、そしてスタンフォード大学と、ソフトウェア開発およびトレーニングの提供企業であるTogether AIの同僚らは、研究の結果、ラップトップがクラウド計算の代替としてますます有力になっていることを見出しました。それは、彼らが ワットあたりの知能(intelligence per watt) と呼ぶ指標に基づいています。
Key insight: クラウドシステムは一般に、ユーザーあたりで見たときローカルシステムよりもエネルギー効率が高い。しかし、小型で高性能なモデルが増えてきたことで、ローカルシステムでもより効率的に動かせるようになりつつある。以前の時代には、個人用コンピュータが同じかそれ以下のエネルギーで十分に高い性能を出せるようになったことで、処理がメインフレームから個人用コンピュータへと移行した。同様に、ノートPC上で動くより小型のモデルが、クエリあたりの消費エネルギーを抑えつつ十分な精度を提供できるなら、AIのワークロードはデータセンターから個人の端末へと移る可能性がある。ローカルとクラウドのどちらが現実的かは、「ワットあたりの知能(intelligence per watt)」を計算することで測定できる。つまり、あるタスクにおける精度を、それを達成するために消費された電力で割る。ローカルとクラウドが同程度の精度を達成できると仮定すると、ワットあたりの知能が高い方が、より効率的な選択となる。
How it works: 著者らは、ノートPC向けおよびデータセンター向けのサーバー向けに設計されたハードウェア上で、さまざまな「オープンウェイト」の大規模言語モデルを実行した。時間経過に伴う、ワットあたりの知能の傾向を測るために、最近のモデル(Qwen3、GPT-OSS、Gemma3、IBM Granite 4.0ファミリー、いずれも2025年後半頃のもの)と、古いモデル(Mixtral-8x7BおよびLlama -3.1-8B、2023〜2024年頃のもの)を両方含めた。また、最近のプロセッサ(Apple M4 MaxのノートPC向けチップやNvidia H100のデータセンターチップなど)と、古いプロセッサ(2018年頃のNvidia Quadro RTX 6000など)も含めた。モデルには、実世界の会話、サイエンス、およびアカデミック分野から 100万件のクエリを入力した。
- 精度を測るために、著者らは固定された出力を正解(グラウンドトゥルース)と比較し、オープンエンド(自由回答)の応答を評価するのにGPT-4oを用いた。
- 同時に、電力消費量も記録した。
- 著者らはこのデータを使って、クエリをモデルへ振り分けるための理想的なシステムをシミュレーションした。各クエリについて、(ローカルでホストされているかクラウドでホストされているかにかかわらず)正しく応答しつつ最も少ない電力を使ったモデルを追跡し、そのモデルが当該クエリを処理したものと仮定した。
Results: ローカルシステムは現時点ではワットあたりの知能でクラウドシステムにまだ追いついていないが、研究者がより小さなモデルを開発し、それによって高い性能を実現するにつれて改善している。ローカルシステムがクラウドシステムと同程度の正確さを持てるのであれば、クエリをローカルへルーティングすることで大幅な省エネルギーにつながる可能性がある。
- クラウドの計算システムは、ワットあたりの知能がより高い。Nvidia B200チップ上で動いたより小型のモデルは、ローカルのチップ上で動いた同じモデルよりも、少なくとも1.4倍高いワットあたりの知能を達成した。
- しかし、ローカルシステムではワットあたりの知能が急激に上昇している。ワットあたりの知能は、アルゴリズムの進歩とハードウェアの改善によって、2023年から2025年の間に5.3倍に増加した。
- 著者らの、一回の応答(single-turn)チャットおよび推論クエリの分析では、小さなモデルを動かしたローカルシステムは、クラウドシステムに対して、約88.7%のクエリを正しく答えることができた一方で、消費電力は大幅に少なかった。シミュレーションしたハイブリッド状況では、省電力は80%を超えた。
Yes, but: 著者らはOpenAI GPT-5のような独自(プロプライエタリ)モデルのワットあたりの知能を評価していない。おそらく、これらがどれだけ電力を使うのかが不明だからだ。ただし、独自モデルの精度は比較している。最も正確なローカルモデル(Qwen3-14B)は、GPT-5、Gemini-2.5-Pro、Claude Sonnet 4.5に対して、精度で11%から13%劣っていた。
Why it matters: 研究者は大規模言語モデルを急速に改良しており、同じ量の電力使用でより高性能なモデルを作れるようになっている。この性能向上を追跡することで、時間の経過に伴う「電力」と「性能」の相対的なトレードオフが見えてくる。そのトレードオフがますます低電力のデバイスへと傾いていくにつれて、人々にはより多くの選択肢が生まれる。これらの選択肢は、計算負荷を分散させ、機械の知能をより広く分配できる可能性をもたらす。
We’re thinking: プライバシーは、ローカルAIをめぐる議論を動かすことが多い。ワットあたりの知能が上がっていく見通しは、興味深い経済学的な議論を生み出している。




