ニック・コルヴィーノ ニックは2週間、ケープタウンにいます… 中国トークの集まり(ミートアップ)に参加したいなら、ニックにnick@chinatalk.mediaまで連絡してください!
最近、私たちは「中国が実際にどれくらいのコンピュート(計算資源)を持っているのか」を突き止めようと試みました。その問いに対して、供給側と需要側の両方からアプローチしました。そこで到達したのは、おおむね「H100換算で約250万〜280万」です。しかし、単一の集計数字だけでは全体像の一部しか捉えられません。
中国についてのジェンセン
先週のダワルケシュのポッドキャストで、ジェンセン・ファン(Jensen Huang)は、中国にはすでに最先端AIを作るのに十分なコンピュートがあると主張しました。
「彼らは世界の主流チップの60%を製造している。たぶんそれ以上だ。」
ダワルケシュが先進チップのギャップについて指摘すると、ジェンセンはこう返しました。
「AIは並列計算の問題ですよね?エネルギーはただ同然なんだから、4倍、10倍もチップをただ集めて(束ねて)しまえばいいのでは?」
ジェンセンは間違っていますが、それでも人々がこの推論に強く引きつけられないという意味ではありません。対中政策を所管する下院特別委員会の委員長であるジョン・ムーレンアーは12月、ルットニックに対し、中国の総計のAI計算能力を米国の計算能力の10%に上限を設ける「ローリング(逐次更新型)の技術的しきい値」を提案する書簡を送っています。これはずっと多面的で、計算上の要素としてメモリやネットワーク帯域も考慮するのですが、最終的には書簡が「死の一千の閾値未満チップによる死(death by a thousand sub‐threshold chips)」と呼ぶものを防ぐことが目的のように見えます。
輸出規制の線引きは難しい問題であり、総計の計算能力も確かに重要です。とはいえ、すべての計算(コンピュート)が同じ価値を持つわけではありません。最前線のモデルを学習(トレーニング)するための計算、既存のモデルに対する推論(インファレンス)を提供するための計算、そしてあなたのノートパソコンを動かすための計算は別物です。また、「死の一千の閾値未満チップ」は、最重要のチップの集中に比べれば、AIの進路にとっては懸念が小さくなります。
レガシー(旧世代)チップはAIにとって重要ではない
「中国は世界の主流(メインストリーム)チップの60%を製造している」というジェンセンの主張がどこから来ているのかは分かりにくいです。おそらく当初は、2024年の、以前の商務長官ジーナ・ライモンドによる、中国で立ち上がってくる新しいレガシー(旧世代)チップの増産余力に関する予測から来ているのかもしれません。しかしこれはAIの計算(コンピュート)を測る指標ではありません。そこには、あなたの車のエンジン・マネジメント・システムを動かすチップ、洗濯機の制御基板、そして産業用モーターのパワーエレクトロニクスに使われるチップが含まれ、通常は28nm以上で製造されます。これらは重要ですが、最前線のAIを学習させるためのチップではありません。電子レンジの中のチップはトランスフォーマーのための行列乗算はできず、中国のEVに搭載された40nmのマイクロコントローラがDeepSeek-V4を動かすのに役立つわけでもありません。
実際にAIに関係する中国のチップ生産のごく一部、主にファーウェイのAscendラインは、ざっくりおよそ100万個のチップです。しかし、たとえ主力のAscend 910C(今年の歩留まりが約30万〜60万個)でも、学習用途ではNvidiaのH20よりわずかに劣る程度であり、ブラックウェルには程遠く、さらに現行の生産の多くはいまなお、規制が引き締められる前に取得されたTSMCのダイ(チップ用素材)の在庫に依存しています。残りの中国の最先端(フロンティア)関連の計算能力は、密輸されたNvidiaのチップや、H20のようなより下位のチップが適法に輸入されていることに由来します。要するに、中国は低品質のチップを作っており、しかもそれらの量についても米国ほど作れません。中国の企業が「死の一千の閾値未満チップ」という状況に何か近いところまで到達するには、自社が持つ計算能力を、どの米国の研究室よりも強い度合いで集中させる必要があるはずですが、そのようなことは、彼らの間で繰り広げられている熾烈な競争を考えると、難しい課題です。
だからこそ、FLOPsはチップ総数よりもずっと正直な指標です。FLOPs(毎秒の浮動小数点演算数)は、あるチップが1秒間にどれだけの演算を実行できるかを測るもので、AIの学習と推論における基本通貨です。というのも、AIが実行するあらゆる命令は最終的に、乗算と加算の連なりだからです。そしてこの指標における最前線のチップとレガシー・チップのFLOPs差は途方もなく大きい。NvidiaのBlackwell B200が約10 petaFLOPsの高密度FP8性能を提供する一方で、典型的な28nmの自動車用マイクロコントローラはFP32で約0.12 teraFLOPs程度、つまりおよそ2万分の1という大きさです。1具体的に言えば、ある国がBlackwellを10万個持っているなら、対抗国は同じFLOPs出力に合わせるために、あり得ないほどの20億個ものレガシー・チップが必要になります。
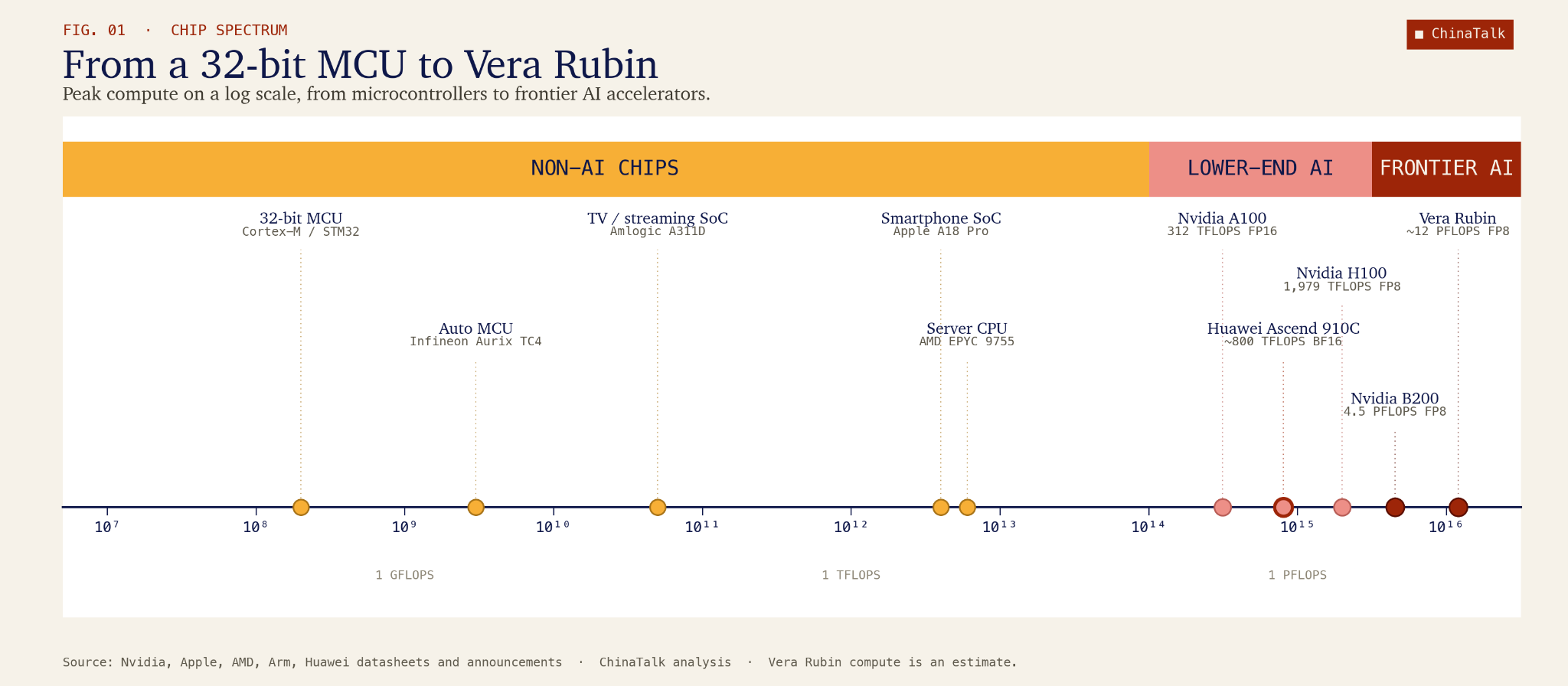
しかし、主流のレガシー製チップを脇に置くとしても、仮に中国が何らかの形で、(アセンデンスのような)弱いAI向けチップを大量に積み上げたとしても、その問題はFLOPsを合わせるところで終わりません。
2つの架空の国の物語
NvidianaとHuaweiopolisはそれぞれH100換算で200万基を持っています。紙の上では、両者は同格です。
Nvidianaのチップ資産は偏りが大きく、身が軽い。およそ30万の最前線チップ、ブラックウェルズと、まもなく登場するベラ・ルビンズが中核を成し、少数の目的特化型データセンターにおいて密に相互接続されており、数万基規模のチップをロックステップで同時に学習走行できます。さらに別の60万基のチップ、H100sとH800sが、大規模学習と本格的な推論を担当します。残りは、約65万基の古いアクセラレータと、軽いワークロード向けの汎用シリコンで埋められています。物理チップの総数は、およそ155万基。
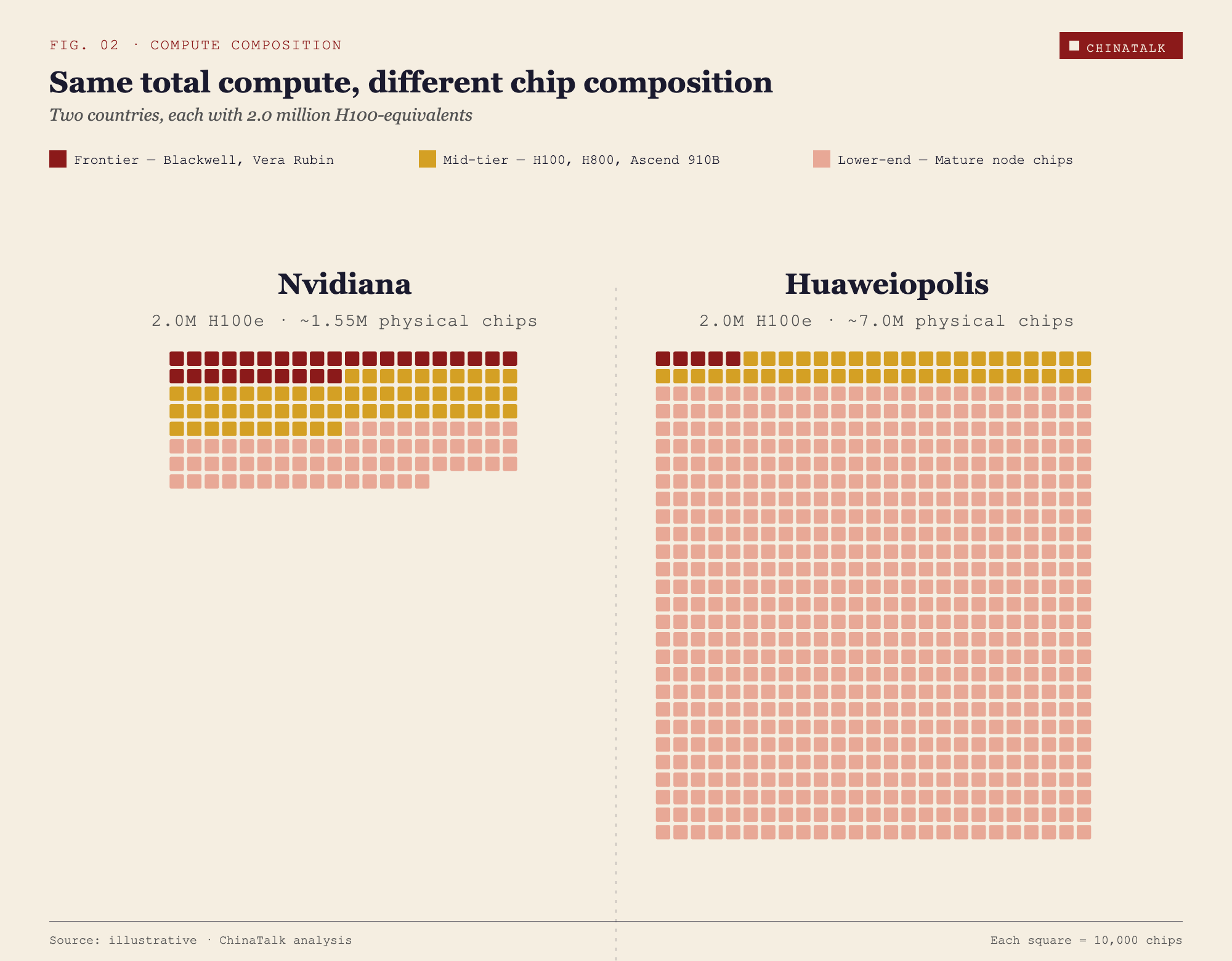
Huaweiopolisは、弱いチップを膨大な量で積み上げることで、同じ合計に到達しました。最上位は薄く、最新の輸出規制が始まる前に入手したおよそ50,000のフロンティア級チップで、おまけにそれらもいくつかのクラスターに分散しており、集中しているわけではありません。中位は約450,000チップで、古いHopper系バリアントと、HuaweiのAscend 910Bのような中国製アクセラレータの混成です。能力はあるものの、より弱い相互接続とメモリ帯域によって制約されます。Huaweiopolisのスタックの残りの大部分――約650万チップ――は、H20のような推論(inference)向けの古いチップ、そして転用された汎用ハードウェアです。物理チップ総数はおよそ700万。Nvidianaの4倍を超えています。
Nvidianaは次世代のフロンティアモデルを学習し、提供できます。Huaweiopolisはそれができず、さらにチップを増やしてもギャップは埋まりません。FLOP数が同一だとしても、AIの進化(軌道)の差はかなり大きくなります。
なぜ強力なチップが少ない方が、弱いチップが大量でも勝るのか
Huaweiopolisの性能が遅れる主な理由は3つあります。数値の精度(numerical precision)、メモリ帯域(memory bandwidth)、ネットワーク帯域(network bandwidth)です。2
数値の精度
古いチップは、数値の精度における最新トレンド――つまり、計算を行う際にチップが数値をどれだけ細かく、あるいは粗く表現するか――を見据えて設計されていません。これは、どれだけのデータを移動し、処理する必要があるかに直結します。Hopperシリーズのような古いチップは、せいぜいINT8演算に対応するように設計されており、つまり数値は8桁で計算されます。一方、新しいチップ(Blackwellシリーズなど)は、INT8 および FP4計算の両方に対応するように設計されており、これはチップの速度を本質的に2倍にする飛躍です。これらのチップは、性能をほとんど損なうことなく、数値を4桁までの精度で計算できます。桁数を半分にすることで、これらのチップは速度が2倍になります。多くの研究が採用しているような、INT8演算という基準でチップを比較する場合、FP4で計算できることによって新しいチップが得られる追加能力を見えにくくしてしまっていることになります。新しいモデルはFP4で学習されており、推論に関しても、精度が多少低くても本質的には大きくは気にしません。したがって、より低い数値精度で動作できることは大きな利点です。
メモリ帯域
FLOPsを測るだけでは、メモリ帯域の重要性を見落としています。ほとんどの推論ワークロードでは、チップの性能はFLOPsによって制約されるのではなく、メモリによって制約されます。モデルを動かすということは、単純な計算を各要素に対して数回行うためだけに、そこに保存された値を数十億個分検索して引き出すことになるからです。ロジックが数字を計算し終わるのを待つのではなく、ロジックは、計算するための数値をメモリが取り出してくるのを待っています。FLOPsが十分に高いのにメモリ帯域が足りないチップは、素晴らしい包丁さばきを持つ料理人が、食材置き場(パントリー)と厨房の間に、通路が細く1本しかない状況にいるようなものです。そこで彼女は、食材を取りに行くために、他の料理人の列に並んで待たなければならないことがよくあります。手がどれだけ速く動いても、食材が集まる速度が遅すぎて、結果として本当の速さは意味を持ちません。
フロンティアAIチップは通常、メモリ帯域幅を最大化するために高帯域幅メモリ(HBM)に依存し、その結果ダウンタイムが最小化されます。古いチップは古いHBMを使っており、メモリ帯域幅が劣ります。ホッパーシリーズは 帯域幅 が4.8TB/sのHBM3eを使用していますが、ブラックウェルシリーズは 帯域幅 が8TB/sの、より新しいHBM3eを使用しています。 (TB/sは、毎秒テラバイトのことで、メモリが格納された値を計算ユニットへ届ける速度を表します。)最新のヴェラ・ルービンチップ は メモリ帯域幅が 22TB/s超 のHBM4を 使用しています。一方で、国内の中国チップはまだHBM3を突破できていません。華為(ファーウェイ)のAscend 910C は (海外製の)HBM2Eを使用しており、メモリ帯域幅はわずか3.2TB/sです。つまり、華為ポリスのFLOPsにおける見かけ上のNvidianaとの同等性にもかかわらず、それらのFLOPsの大部分は推論ワークロードに使えないということです。ロジックユニットがメモリ待ちで手持ち無沙汰になってしまい、問い合わせ応答時間があまりにも長くなるためです。
ネットワーク帯域幅
最後に、ネットワーク帯域幅—別々のチップ間、またはチップラック間でデータが移動する速度—は、華為ポリスのクラスタの性能を深刻に制限することになります。メモリ帯域幅は チップ内の通信における制約要因です。なぜなら、チップのメモリとロジックの間でデータをどれだけ迅速に移動できるかが決まり、それによってチップが作業で途切れずに常に供給を受けられる速度が実質的に決まるからです。ネットワーク帯域幅—ラック内で別々のチップ同士がどれだけ速くデータをやり取りできるか—は チップ間の通信における制約要因であり、さらに ネットワーク帯域幅はメモリ帯域幅よりも大幅に遅い のです。B200を8チップ搭載したクラスタでは、メモリ帯域幅は合計64TB/sですが、ネットワーク帯域幅は14.4TB/sにすぎません。モデルの学習や推論の提供では、可能な限りネットワーク通信を使いたくありません。なぜなら、チップがデータ交換を行うたびに互いに停止して待ちが発生し、規模が大きくなると通信が支配的なコストになってしまうからです。その結果、チップ数を増やしても得られる効果は逓減し、最終的にはまったく追加の性能が出なくなります。
残念ながら華為ポリスにとって、戦略が、より低品質な大量のチップを接続して、少数の高品質チップのクラスタに対抗しようとするものである限り、成功することはできません。ネットワーク通信は避けられず、それが痛手になります。Nvidianaのクラスタは、チップあたりの電力とメモリ保存容量がより大きいため、チップ間通信に頼る前にチップ内でできることがはるかに多くなります。華為ポリスのクラスタは、このボトルネックにより頻繁にぶつかり、処理が遅くなります。特に、大規模モデルの学習では複数クラスタのチップを使う必要があるため、ネットワーク帯域幅の制限は致命的になり得ます。
ジェンセンはこの問題を、「Huaweiはネットワーク企業だ」としてネットワーキングを持ち出し、HBMの重要性を軽視することで片付けたがります。しかしそれは単に正しくありません。チップ内のデータはより短く、より直接的な接続で移動しますが、ネットワーキングでは、より長いリンクを介し、さらに調整の遅延が加わる形でデータ送信が必要になります。だから、ネットワーキングは常にメモリ帯域幅よりも不利になります。たとえ神の最高のNVL72や華為の光ファイバーでも、この戦いでHBMに勝つことはできません。「HBMを上回る」とは、チップ自身のメモリが処理できる速度と同じ速さで入力を供給することを意味しますが、それを外部ネットワークが同等に実現することは不可能だからです。
FLOPsは重要ですが、それが唯一の指標ではありません。おそらく現時点での比較における最良の指標ではありますが、適切な比較には複数の要因を考慮する必要があります。華為ポリスのクラスタをNvidianaのクラスタとFLOPsで単純に同等とみなすことは、華為ポリスのクラスタが学習も推論もいずれにおいても性能で不利になるという事実を隠してしまいます。これは効率やスピードの問題にとどまりません。極端な場合、システムは単に適切に学習できなくなることがあります。現代の学習では、多数のチップにまたがる勾配更新を厳密に同期させる必要があります。しかし通信が遅すぎる、または一貫していない場合、これらの更新が遅れて届くか、タイミングがずれます。その結果、モデルはもはや一貫した方向へ更新されておらず—勾配が確実に下降していない—学習が不安定になったり、収束しなかったりすることがあります。単に時間がかかる、あるいはより多くのエネルギーを要するといった程度ではなくなります。
結論
積算された計算能力は重要で、とりわけ経済全体にAIが広く普及していくうえでは大きな意味があります。しかし、「ある国が最も強力なAIモデルを持つかどうか」が問題になるときは、総人数よりも、そして総FLOPsよりも、最良のチップの質と集中度のほうがはるかに重要になります。
政策立案者が、この論理を内面化し始めている兆しがあります。今週導入されたモーレナーの SCALE Act は、依然としてローリング式の技術的閾値の枠組みを採用していますが、以前の提案である「中国の積算計算能力を米国の10%に上限を設ける」という、より積算(アグリゲート)に焦点を当てたアプローチからは切り替えています。代わりに、輸出を許可するのは、中国が国内で既に大規模に製造できる 最高の チップの性能の110%までとし、閾値を総計算能力ではなく中国国内の能力に連動させます。これはより狭く、観測可能な目標であり、チップ数(総人数)によるアプローチよりも、量より質という洞察をより真剣に扱っています。
どんなチップ政策にも完璧さはないものの、根底にある論理は、政策を最も重要な特定のチップに集中させることです。私たちは、積算のFLOP数のみに基づくのではなく、これらの“王冠の宝石”となるチップに対して執行を組み立てるべきであり、ましてや疑わしいチップ数に基づくべきではありません!
新しい投稿を受け取り、私たちの活動を支援するために、購読してください!
ムードミュージック(Jordan)
B200 と MCU の数値は、それぞれ異なる数値精度で測定されています。前者は FP8、後者は FP32 です。低精度フォーマットは、同じシリコン上でより多くの演算を可能にし、現代のテンソルコアでは、精度を半分にするたびにスループットが概ね 2 倍になります(Nvidia の blog によると)。FP8 から FP32 に切り替えると、ビット幅が 2 回分だけ倍になり、その結果スループットは概ね 4 分の 1 になります。これにより、Blackwell の 10 ペタFLOPs の FP8 は、推定 2.5 ペタFLOPs の FP32 にまで下がります。これを MCU の 0.12 テラFLOPs で割ると、比率は概ね 20,000 対 1 になります。
Huaweiopolis の構成も、同様に大幅にコストが高くなりますが、ここでは純粋に性能に基づく分析のため、これを省略します。




