昨日、同僚のAqib Zakariaが 中国の供給側の計算力(コンピュート)能力の見積もりを公表しました。チップの出荷台数、密輸に関する報告、国内生産、そして推定される西側のクラウドへのアクセス量を積み上げていくことで、彼は 約270万枚のH100相当GPUに到達しました。
今日、需要側から同じ問いにアプローチしてみます。チップの数を数えるのではなく、ワークロードを数えて、中国のAIエコシステムにどれくらいの計算資源(compute)が必要なのかを見積もります。 需要側のアプローチは供給側(つまり、私が感じで推測している割合がずっと大きい)より精密ではありませんが、供給側の数字が成り立つかどうかを相互に検証できます。
私がたどり着いた数字は 約280万台のH100eで、Aqibの推計とほぼ同じです——ただし、私たち両方が、たまたま互いの誤差が打ち消し合って等しくなっている、という可能性は十分あります。(重要な点として、数字は計算が終わった後で初めて共有しました!)
では、なぜこれが重要なのでしょうか? まず第一に、高度なチップに対する輸出規制は、そのチップが実際に何を可能にするのかについての理解がある限りにおいてのみ有効です。政策立案者がH200への規制を強化するかどうか、あるいはクラウドの計算資源の抜け道(loopholes)を塞ぐかどうかを議論しているなら、おそらく中国のAIエコシステムが実際にどれほどの需要を持っているのかを、具体的に把握しておくべきです。需要を見ることで、中国企業が西側のクラウド・サービス事業者からどれほどの計算資源を借りているのかを推測することも可能になるはずです。
この先では、私が自分の数字をどうやって導いたかを説明します。要するに…
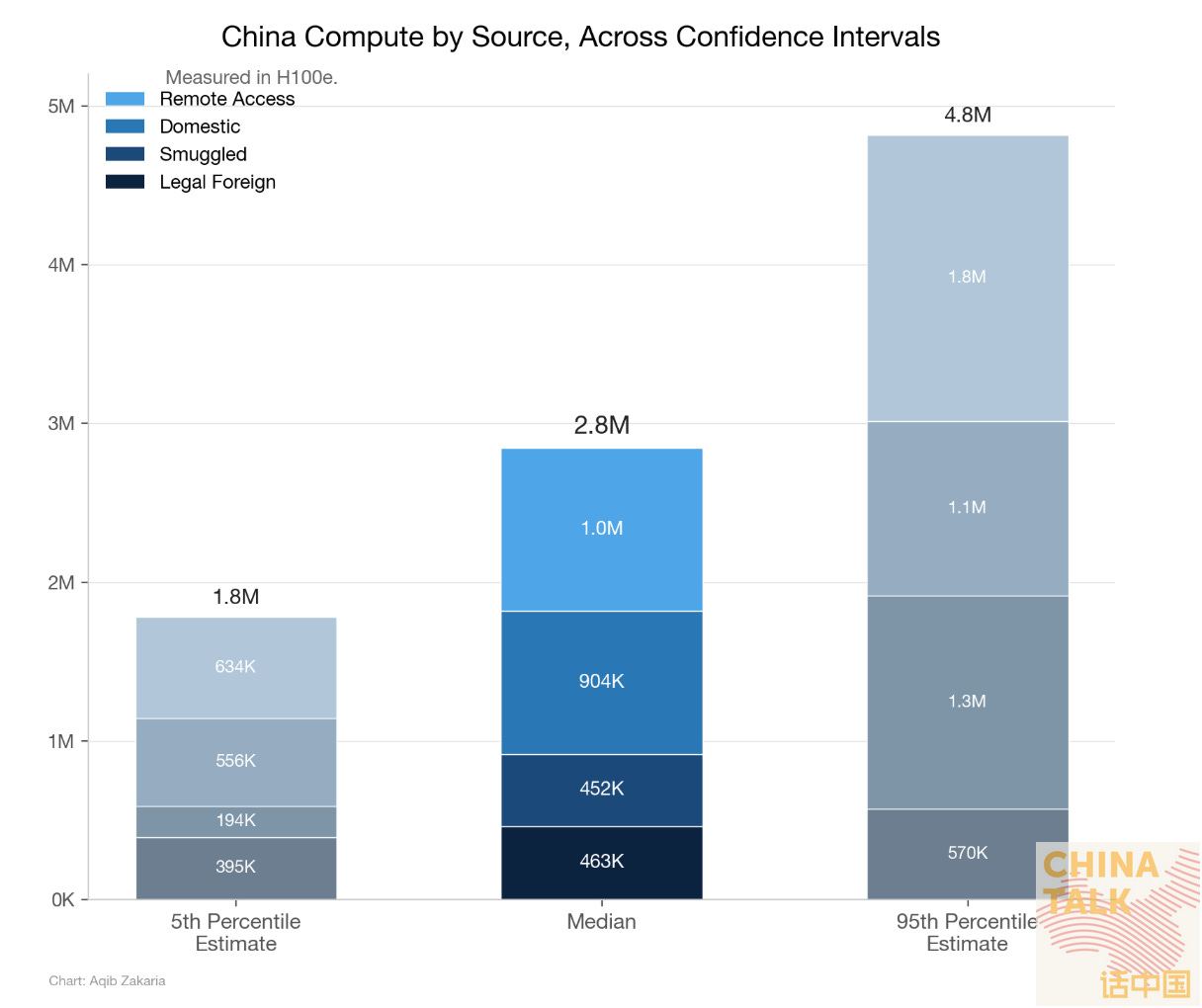
私の見積もりでは、中国のAIインフラは、チャットボット、エンタープライズ向けAPI、レコメンデーション(推薦)アルゴリズム、動画生成、監視、その他を含むあらゆる推論(inference)ワークロードにサービスするために、概ね 約237,000台のH100eが常時稼働して必要です。推論向けの推論チップが実際にどれほど集中的に運用されているかの中心推計である55%で割る——複数の会話と、「利用率(utilization)に関する議論」で一般に共有されている考え方に基づく——と、推論の最低導入基盤(installed base)は 約431,000台のH100eになります。さらに、モデル学習と研究のために断続的に使われる専用の学習クラスターとして 約128,000台のH100eを加えると、推論と学習を合わせた最低の総導入基盤は、およそ 約558,000台のH100eです。予備としてのチップ、稼働中ではない期間(トランジット)、実行と実行の間、あるいはまだ完全にオンラインになっていない分を勘案するためにスケールアップすると、全フリート(保有一式)稼働率20%(これも、会話と他者が提案している一般的な範囲に基づく)で 280万台に到達します。学習クラスターは推論と扱いが異なります。推論の利用率55%で割るのではなく、高い利用率(80%)における、利用可能なチップ時間(chip-hours)あたりの「年間の総学習計算量」を基に算出します。学習時には使用効率が高まるためです。
以下で、各ステップをもう少し詳しく説明します。完全な手法(methodology)については、ここにあります: China’s AI Compute Demand。
この作業を進めてみて、ぜひさらに詳しく知りたいことがいくつか見えてきました:
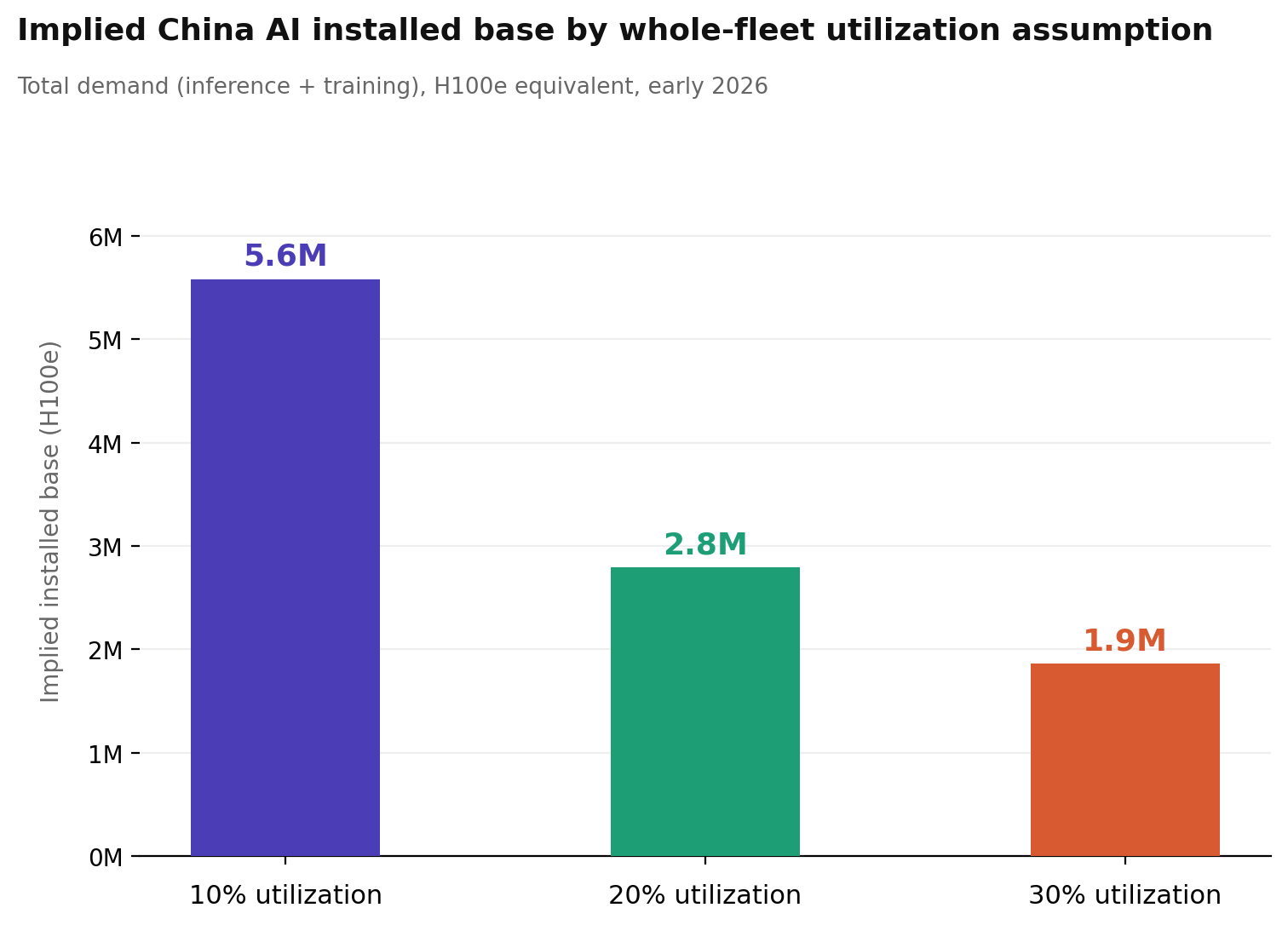
GPUの利用率。 正しい利用率の割合を選ぶことが計算で最も重要な要因であり、かなり論争の的です。複数の関係者との会話や、文献にある一般的な知見(common wisdom)に基づき、私は「推論向けに実際に投入されているチップがどれだけ稼働しているか」には40〜70%、「中国の総導入フリートのうち、ある時点で稼働している割合」には10〜30%を使います(中心推計は20%)。ただし、その“全フリート”の数値を1ポイント動かすだけで、最終的な数字が約186,000台のH100e変わってしまうので、正確さは非常に重要であり、ここにはさらなる調査が役に立つはずです。
エンタープライズAIの導入。 私は、中国のエンタープライズAPIの利用を米国レベルの約40%と見積もっています。これは、私の推計における最大の単一の推論カテゴリーです。とはいえ、中国も西側のAI企業も、エンタープライズ利用についてあまり開示していないため、もどかしさが残ります。
監視および推薦アルゴリズム。 監視や推薦アルゴリズムにはどれほどの計算資源が必要なのか、そしてその計算資源の質はH100eのようなものと比べて同等なのか、それともより単純なワークロード処理なのかは、どの程度でしょうか?
完全に見落としてしまったユースケース。 需要側分析の限界は、「自分が思いつかなかったカテゴリが必ずどこかに存在する」という点です。
この種の作業である以上、間違いが含まれるのは避けられません。とはいえ、このBOTECが他の人の土台になり、穴を見つけられ、改善されるためのフレームワークとして機能してくれればと願っています。私の数字のどれかが明らかに大きく外れているように見えたら nick@chinatalk.media まで連絡するか、コメントで教えてください。
ユースケース別に計算する
以下のチャートは、作業負荷(ワークロード)カテゴリ別に、中国のAI総計算需要を内訳で示しています。
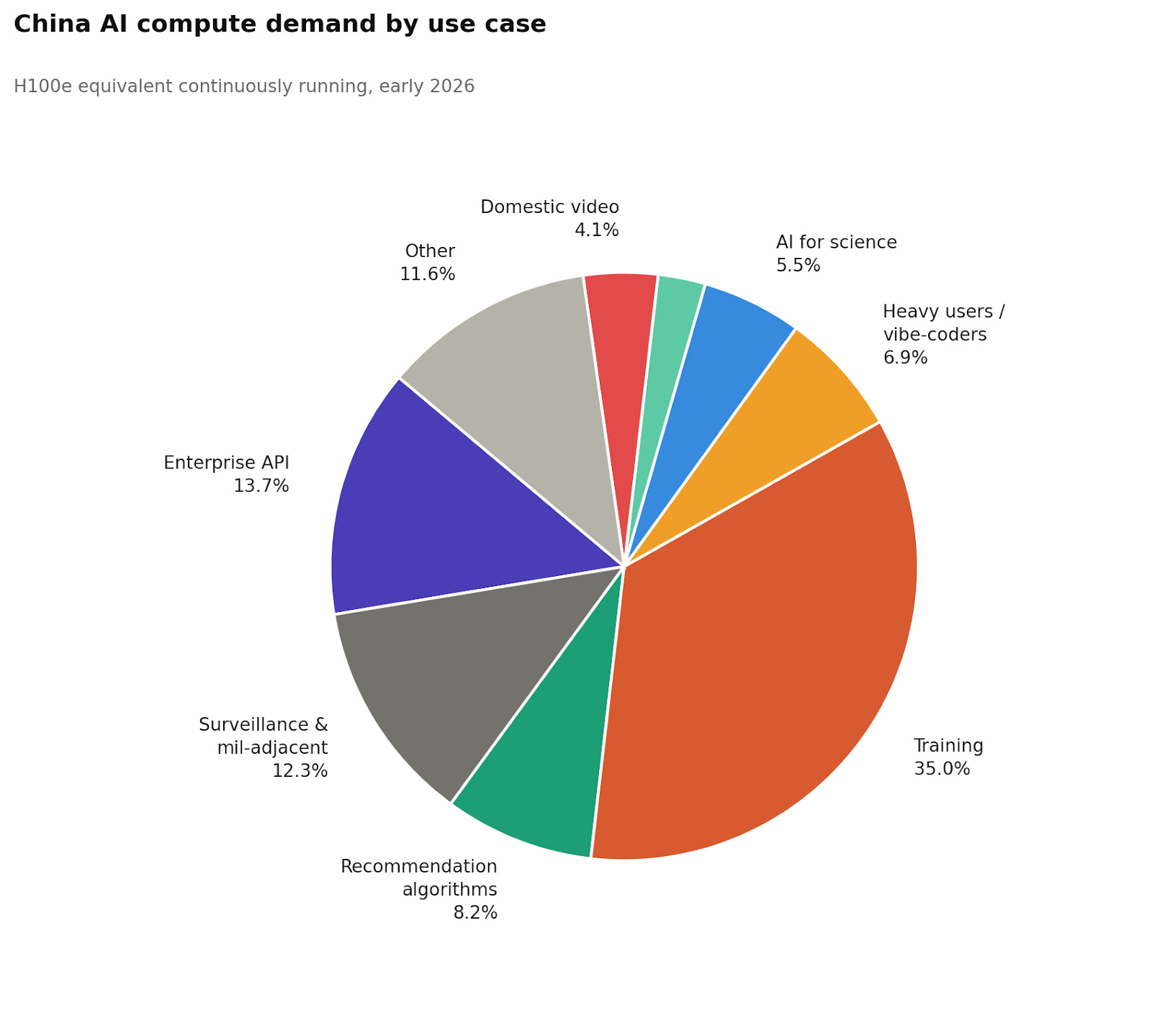
推論
最大のカテゴリである学習については、少し後で扱います。ですがその前に、私が興味深いと思った推論に関するいくつかの発見を紹介します。
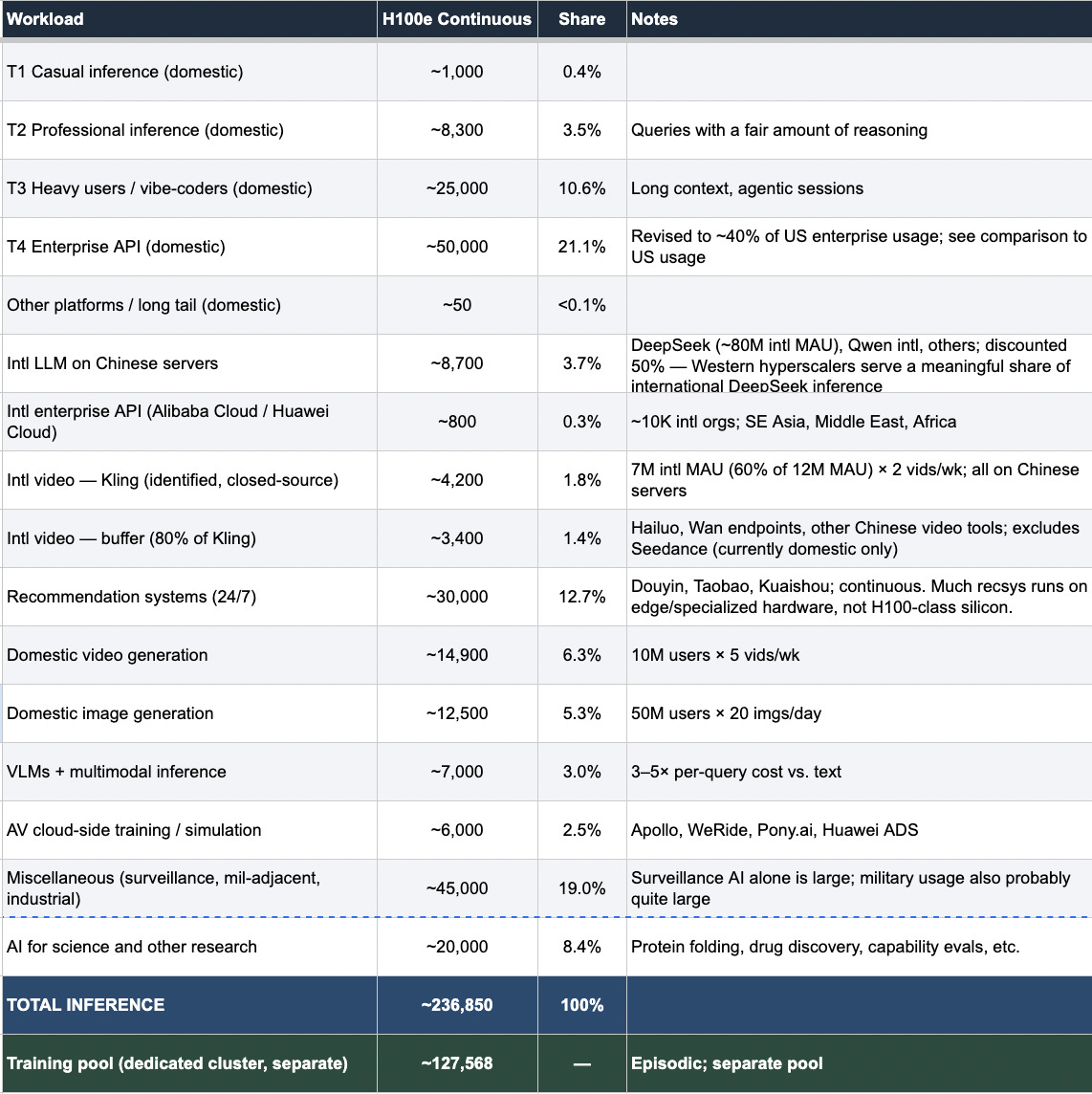
カジュアルな利用者は、巨大な規模でもほとんどカウントされない。 CNNICは、中国の生成AIの利用者ベースを2025年12月時点で「6億2000万人」と、驚くほどの数字で示している。ただしこの数には、AI搭載機能に一度でも触れた人が含まれるため、人数というよりは上限に近い。より役に立つのは、意味のある計算負荷を生む定常的なアクティブユーザーをおよそ1億7500万〜2億4000万人とみなす推計だと思う。さらにカジュアル層として約3億人が上乗せされる可能性がある。つまり、短い翻訳を送る、Doubaoの提案をタップする、あるいはAI搭載のフィルターを使うといった人たちだ。短いクエリを少数だけ、1日あたり約1,000トークンとすると、このカジュアル層全体が必要とするのは約1,000台のH100eで、推論需要全体の1%未満にすぎない。1つのエンタープライズ顧客が年にトリリオン・トークンを燃やしているなら、そこから生まれる計算量は、何千万人ものカジュアルな日次利用者をまとめてもなお上回る。
エンタープライズ向けAPIは、単一の最大推論カテゴリーだ。 私は国内のエンタープライズAPIを、およそ50,000台のH100e、つまり推論全体の約21%と見積もっている。ここでの最大の根拠は、OpenAIの2025年の「Enterprise AI Report」[pdf]で、年間1兆トークンを超える組織が約200社、年間100億トークンを超える組織が約9,000社あることを開示している。これらを下限値で扱い、1H100eあたり1時間で約0.8百万トークンに換算すると、OpenAIだけでも米国のエンタープライズ推論の下限は約41,000台のH100eになる。これは Microsoft(有料席15百万席)、Anthropic、Google、そして自社内展開(OpenAIに比べて自社のエンタープライズAIの取り組みがどれほど成功しているかという「体感」から、私はほぼそれに見合うように推計している)を加える前の数字だ。中国のエンタープライズAIエコシステムは成長しており、Alibaba CloudのTongyiプラットフォームは2024年に30万のエンタープライズ顧客に到達したと報じられているが、米国よりも初期段階で、利用者も少ない。中国のエンタープライズソフトウェアでは、AI統合が浅いことが多く、自動化されたワークフローも少なく、組織あたりのトークン量も小さい。その結果、OpenAIのエンタープライズ・コホートのような米国企業で計算量を押し上げる、ビジネスプロセスへの深いAPIレベルの埋め込みが進んでいないことが多い。したがって私は、中国の需要を米国エンタープライズ需要全体の約40%と見積もり、このことから50,000台のH100eという数字になるが、実際の値は2万〜7万台のどこにでもあり得ると思える。
監視、軍事に近い領域のAI、レコメンドアルゴリズム、そして正体不明の「unknown unknowns」(起き得るが予測できない要因)を合わせると、計算量全体の約32%だが、特定するのが最も難しい。 例えば、レコメンドシステム(Douyin、Taobao、Kuaishou、Pinduoduo)は24時間365日、継続的にリアルタイムでランキング推論を回しており、夜間需要が落ち込む度合いは小さい。私はこれらを30,000台のH100eとしているが、その作業の多くはH100級のハードウェアではなく、エッジ側のシリコンや専用アクセラレータ上で実行されている。その他のカテゴリー――政府の監視AI、軍事に近い用途、産業システム――については45,000台のH100eとしている。この数字には最も自信がない。6億〜7億台のカメラにまたがるリアルタイムの映像再識別は計算集約的である(エッジNPUが最初の検出を担うとしても、バックエンドの集約と再識別にはデータセンター級のハードウェアが必要になる可能性がある)。また軍事AIの使用は、実質的に公的な痕跡が残らない。私が大きく過大/過小に予測し得る変数の中でも、最もそのどれかである可能性が高い。
他にもいくつか、興味深い変数がある。全体の内訳を確認すれば見えるように、例えば中国のサーバー上の国際ユーザー(特にDeepSeekの大きな国際ユーザーベース。同社は中国のハードウェアで推論を行っている)や、国内・国際の映像生成がある。これらは、KlingやSeedanceのようなプラットフォームが拡大するにつれて成長し、意味のある計算量カテゴリーになってきている。
トレーニング
トレーニングで使う計算資源を推論と同じ土俵に乗せるには、別の手法が必要です。推論は、いま動いているチップとして自然に表現されます。一方、トレーニングはエピソード(まとまった期間に集中)型です。つまり、クラスタは数週間から数か月間フル稼働したあと、アイドル状態になるか、次の実行の間のどこかで推論へ回されます。
そこで私は「今稼働しているチップは何枚か」と聞く代わりに、「中国はトレーニングに年間でどれくらいのGPU時間を消費していて、それは専用チップとしてはどれくらいの規模を意味するのか」と聞きました。アンカー(基準)にしたのは、DeepSeek V3の 開示されたトレーニング実行である2.788百万H800-GPU時間で、(過少申告の可能性を考慮して)1.5倍に上方調整しました(中国の研究所には、開示計算をできるだけ小さく見せる強いインセンティブがあると私は考えています。効率性の物語を補強し、輸出管理の監視が厳しくなる中で、必要なチップ数を過小に見せられるからです)。そこから、階層を積み上げました。大手5社(ByteDance、Alibaba、Baidu、Huawei、Tencent)はそれぞれ、年間に複数回の最先端LLMの実行を行い、アブレーション、RLHF、失敗した実験のためのオーバーヘッドも見込みます。次に中堅10社。さらに、国家機関および軍に近い組織が5つ。それに加え、動画モデルのトレーニング、画像モデル、AVシミュレーション。年間のトータルのトレーニング予算は、およそ298百万H100e時間です。
これを専用クラスタの規模に換算するために、トレーニングクラスタは、稼働中の利用率80%で年あたり約4か月稼働していると仮定しました。すると、チップ1台あたり年間で利用可能な時間は約2,336時間になります。298百万を2,336で割ると、専用トレーニングプールとして示唆されるH100eはおよそ128,000台分です。さらに、生産用トレーニング実行の範囲を超えた研究・実験のために約50百万H100e時間を加えました。具体的には、アーキテクチャのテスト、スケーリング則の実験、RLパラダイムに関する研究です。これにより、純粋に生産実行だけを計上した場合に比べて、総計はより大きくなります。

しかし、すべての計算が同じではありません。中国の学習クラスターには、H800のような最良のチップや、密輸されたBlackwellsが必要です。これはつまり、中国が推論を大規模に行うための計算能力は十分にある可能性がある一方で、次世代のフロンティアモデルをどれだけ速く学習できるかについては、依然として意味のある制約に直面しているということです。
最終的な数字
推論と学習について考慮したので、次は「能動的に動いている計算」から「中国が実際に設置(導入)しているチップ」へと橋渡しする必要があります。そのためには、2つの別々の稼働率(利用率)調整が必要です。
1つ目は設置ベースの稼働率(installed base utilization)です。これは、ある時点でリクエストを処理している配備済みの推論用チップの割合を指します。これは、忙しいクラスタでさえ100%ではありません。クエリ量が落ちる夜間の谷、トラフィック急増に備えて確保しておく余力、ロジックがメモリ待ちになっている間のダウンタイム、そしてリクエスト間でアイドル状態のチップが存在します。私は中核となる推定値として55%を使います。これは、既存の文献の集積と専門家との会話に基づく、もっとも現実的だと思われる40〜70%という範囲の中点にあたります。55%では、237,000台のH100eが連続稼働していることから、推論の設置ベースはおよそ431,000台のH100eになります。上記で述べたように、その学習クラスタ(128,000台のH100e)は計算にすでに稼働率が織り込まれているため、それを追加すると、最小の総設置ベースはおよそ558,000台のH100eになります。これは下限です。つまり、中国が、観測される負荷をまだ生み出せるだけの最小限のチップ数はこれだ、ということです。

2つ目は 全フリートの稼働率です。これは、ある時点において、これまで中国が購入してきたすべてのチップのうち、何らかの稼働をしている割合を指します。これは、推論(inference)に提供するための稼働率よりも構造的にずっと低くなります。なぜなら、この指標には、新たに調達されたばかりでまだ輸送中のチップ、立ち上げ途中で稼働が立ち上がりきっていない最近設置されたクラスター、実行の合間にアイドル状態になっている学習用ハードウェア、そして将来の需要に備えて確保されている予備能力が含まれるからです。中国はAIハードウェアを非常に凄まじいペースで調達しており、そのかなりの部分は、どの時点のスナップショットでも、作業負荷(ワークロード)に投入されているのではなく、パイプラインのどこかに位置しています。私は、もっともあり得る範囲として10〜30%を採用し、20%を中心推計(central estimate)とします。
中央値である、設置済みベース(minimum installed base)558,000台のH100eを、稼働率20%で割ると、暗黙の中国のAI半導体在庫総量として 約280万台のH100eが得られます。稼働率レンジの悲観的な端(10%)ではその数は560万台まで増えます。一方、楽観的な端(30%)では190万台まで下がります。この感度(sensitivity)は深刻であり、だからこそ稼働率の仮定には、より集中的な調査が必要なのです。
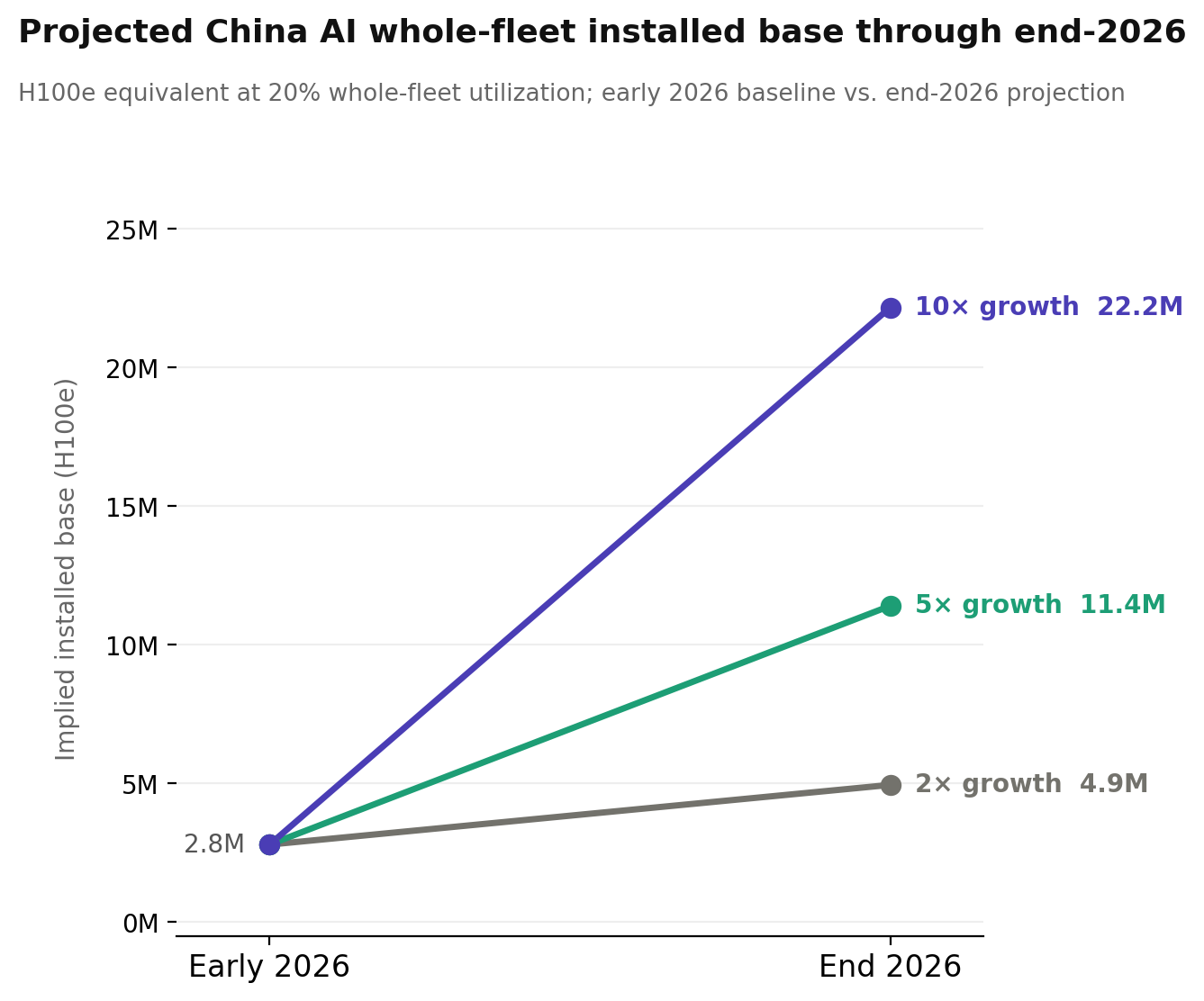
2026年の成長シナリオ
世界のAIトークン消費は、毎年およそ 5× 成長しており、中国が例外である特段の理由はありません。2026年末までに状況がどこまで進む可能性があるのかを把握するため、私は3つのシナリオをモデル化しました。推論プールに2×、5×、10×の成長を適用し、訓練クラスタはフラットに据え置きます。これは、今後訓練が計算集約的になるのか、あるいはその逆になるのかが不確かだからです。
2×なら、全フリートの導入基盤(installed base)が概ね2倍になって約500万台のH100eになります。5×なら約1,100万台。10×なら約2,200万台まで増えます。参考までに、Epoch AI は 現在の世界のハイエンドAI計算能力を20百万台のH100eと推定しています。つまり、これらシナリオの上限は、中国のAIフリート単独で、今日の世界全体の保有規模に近づくことを意味します。2026年末までにそれが起こる可能性は高くないでしょうが、需要側の分析が重要になる理由はこの点にあります。いま扱っている数値は大きいものの、本当に影響が大きいのは「その道筋(トラジェクトリー)」です。輸出管理、半導体の調達、そして米国と中国の間でのAI能力のバランスを考えるうえで、将来の伸び方が本質的になります。
未来のことを考えることこそが、最終的に私がこのBOTECに役立つことを期待している理由です。供給側のカウントなら、中国に何があるかが分かります。需要側のカウントなら、中国が「今日」何を必要としているのか、そして今後数年で何を必要とするのかが分かります。
完全な手法はここで読めます: 中国のAI計算需要

ChinaTalk は読者の支援によって成り立つメディアです。新しい投稿を受け取り、私たちの活動を支えるために、無料または有料の購読者になることをご検討ください。