これまで本連載「AIデータ設計」は19回にわたって、データをどのように設計すると効果的にAI(人工知能)の「能力」を引き出せるのかを解説してきました。本連載開始時はAIエージェントの普及が見えていなかったこともあり、新年度のスタートに当たってあらためてAIエージェント前提のAIデータ設計について、以下のような問題意識の下で、再スタートを切ります。
AIの推論能力は飛躍的に向上しているにもかかわらず、組織は賢くならない――。この根本的な原因はAIの性能不足ではなく、AIに与えている「データ」にあります。多くの企業でナレッジマネジメントが進められてきましたが、その大半はファイルサーバーの整理やマニュアル共有といった「情報」の管理にとどまっています。一部で属人的なノウハウの共有が試みられていても組織全体には至らず、真の「暗黙知」の管理は不十分なのが現状です。
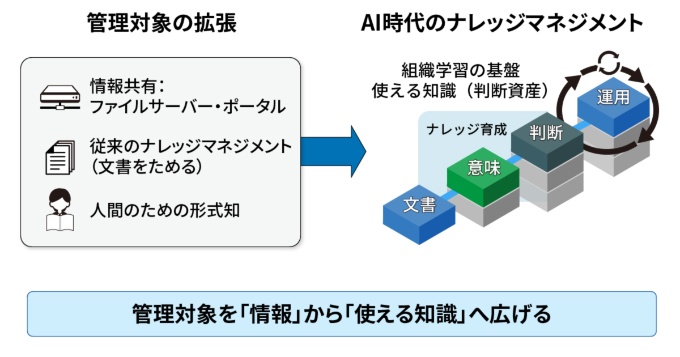
自律的に業務を支援するAIエージェント時代において、管理すべき対象は単なる「文書」から、人とAIが共に使える「判断資産」へとシフトしています。AI時代のナレッジマネジメントは、単なる知識の蓄積を超えた「組織学習の基盤」です。現場の例外や失敗を知識資産へ昇格させ続ける「ナレッジ育成」を軸に、それを実現する手法からエージェント間の業務連係、組織・業務設計までを装い新たに解説していきます。
文書が増えても現場の判断は楽にならない
【ユースケース】FAQもマニュアルもあるのに現場が迷う「問い合わせ対応」
企業に蓄積されているデータの大半は、人間が人間のために書いた「文書」です。業務マニュアルや社内規定などデータ量は日々増加していますが、文書が増えても現場の業務が楽になるとは限りません。
例えば社内ヘルプデスクで業務部門が「新しいクラウドサービスを導入したい。セキュリティー要件を教えてほしい」とAIに質問したとします。AIは社内規定を検索し、「規定第5条に基づき、チェックシートを提出してください」と正確に回答するでしょう。
しかし、担当者が本当に知りたいのは規定の文面ではなく、「今回導入したいサービスはどのセキュリティーレベルに該当し、誰の承認を得れば最短で導入できるか」という具体的な「判断」です。
マニュアルが完璧に整備されAIが正確に検索できても、業務はそこで止まってしまいます。現場が直面しているのは情報の不足ではなく、「どう決断すべきか」という「判断基準の欠如」だからです。
AI時代に管理すべきは「知識」だけでなく「意味・判断・運用」
これまでのナレッジマネジメントは、知識を形式知化し「共有の仕組み(ファイルサーバーなど)」に蓄積することが目的でした。つまり、管理対象の大半は「情報(文書)」にとどまっていました。
しかし、人とAIが共に業務を回す時代において、文書をためるだけでは不十分です。AIに「社内規定のPDF」をそのまま読み込ませるだけでは、「どの条件なら例外処理が認められるか」「最終的に誰が責任を持つのか」を読み取れないからです。
本当に強い実務者は、昔から手順を丸暗記していたわけではなく、「何を見るべきか」「どこで例外に注意すべきか」という判断の作法を押さえていました。AI時代に変わったのは、判断の重要性そのものではありません。その判断を、ベテランの経験の中に閉じたままにせず、人にもAIにも見える形で共有・更新できる状態にしておく必要性が高まったということです。
これからのナレッジマネジメントは、管理対象を文書から拡張し、データの「意味」をそろえ、「判断」を支え、人とAIで「運用」を回し、「改善」を続けるための組織学習の基盤へと進化しなければなりません。単に蓄積するだけでなく、現場の判断や例外対応の経験を、責任と根拠を伴う新たな知識資産へ昇格させ続ける仕組みが求められます。
本連載ではこのプロセスを「ナレッジ育成」と呼びます。一度つくって終わりの「蓄積」ではなく、使いながら磨き続ける「育成」への転換です。
次のページ
ナレッジマネジメントを「組織学習の基盤」へ再定義...この記事は会員登録で続きをご覧いただけます



