親愛なる皆様、
今週のDeepSeekを巡る話題は、多くの人にとって、皆の目の前で起こっているいくつかの重要なトレンドを明確にしました:(i)中国が生成AIで米国に追いつきつつあり、AIサプライチェーンに影響を与えている。(ii)オープンウェイトモデルが基盤モデル層のコモディティ化を進め、アプリ開発者に機会を提供している。(iii)AIの進展にはスケーリングアップだけが道ではない。大量の処理能力への注目と誇大宣伝がある一方で、アルゴリズムの革新が急速にトレーニングコストを押し下げている。
1週間ほど前、中国のDeepSeek社がDeepSeek-R1という驚くべきモデルを公開しました。ベンチマーク上の性能はOpenAIのo1に匹敵します。さらに、このモデルはMITライセンスのもとでオープンウェイトモデルとして公開されました。先週のダボス会議では、技術者ではないビジネスリーダーから多くの質問を受けました。そして月曜日には『DeepSeek売り』と呼ばれる現象が株式市場で見られ、Nvidiaや他の米国テック企業の株価が急落しました(執筆時点では多少回復しています)。
私が考えるに、DeepSeekは多くの人々に次のことを実感させました:
中国は生成AIで米国に追いついている。 ChatGPTが2022年11月にリリースされた当時、米国は生成AIで中国よりかなり先を行っていました。しかし印象はゆっくりと変わり、最近でも米中の友人は中国は遅れていると思っている人がいました。ですが実際には過去2年でその差は急速に縮まりました。Qwen(私のチームも数ヶ月使用)、Kimi、InternVL、DeepSeekといった中国モデルによって、この差は明らかに縮んでおり、動画生成の分野などでは中国が先行した瞬間もありました。
私はDeepSeek-R1がオープンウェイトモデルとして、多くの技術的詳細を公開した技術報告書とともにリリースされたことを非常に嬉しく思います。対照的に、米国の複数企業は人類絶滅など仮説的なAI危険性を煽ってオープンソースを規制しようとしてきました。今やオープンソース/オープンウェイトモデルはAIサプライチェーンの重要な一部であり、多くの企業がこれらを使用します。米国がオープンソースを妨げ続ければ、中国がこのサプライチェーン分野を支配し、多くの企業は米国より中国の価値観を反映したモデルを使うことになるでしょう。
オープンウェイトモデルは基盤モデル層のコモディティ化を促進する。 以前書いたように、LLMのトークン価格は急速に低下しており、オープンウェイトがこの傾向に寄与し、開発者により多くの選択肢をもたらしています。OpenAIのo1は100万出力トークンあたり60ドルですが、DeepSeek R1は2.19ドルです。この約30倍の価格差が低価格化の動きを多くの注目を集めました。

基盤モデルをトレーニングしAPIアクセスを販売する事業は大変です。多くの企業は莫大なモデル学習コストを回収できる道を模索中です。記事「AIの6000億ドル問題」はこの課題を良く説明しています(とはいえ基盤モデル企業は素晴らしい仕事をしており、成功を願っています)。一方で基盤モデルの上にアプリを構築することは多くの素晴らしいビジネスチャンスを生みます。既に誰かが数十億ドルを投じて訓練したモデルを、わずかな費用で使ってカスタマーサービス用チャットボットやメール要約、AI医師、法的文書アシスタントなどが作れるのです。
スケーリングアップがAI進展の唯一の道ではない。 モデルの規模拡大に大きな熱狂がありました。率直に言えば、私も以前はスケーリングアップの支持者でした。多くの企業は、より多くの資本で(i)スケールアップし(ii)予測可能に改善をもたらせるという物語で巨額の資金を集めました。そのため多様な進展方法よりむしろスケールアップに過度に注目が集まりました。米国のAIチップ禁輸の影響もあり、DeepSeekチームはより性能が劣るH800 GPUで動かすために多くの最適化革新を実施し、最終的に(研究費用を除き)600万ドル未満の計算費用でモデルを訓練しました。
これで計算需要が本当に減るかはまだわかりません。単位コストを下げると、全体の支出は増えることもあります。知性と計算需要は長期的にほぼ無限の伸びしろがあると思うので、知性の活用はより安価になっても増え続けると楽観視しています。
DeepSeekの進展にはソーシャルメディアでさまざまな解釈があり、まるでロールシャッハテストのように人々が自分の意味を投影していました。DeepSeek-R1には地政学的な影響があり、それはまだ整理されていません。一方でAIアプリ開発者にとっても素晴らしいニュースです。私のチームはすでにオープンかつ高度な推論モデルへの容易なアクセスがもたらす新たなアイデアをブレインストーミング中です。今はまさに絶好の開発時期です!
学び続けてください、
アンドリュー
DEEPLEARNING.AIからのメッセージ

Anthropicの新機能「Computer Use」を発見しましょう。これはLLMベースのエージェントがコンピュータのインターフェースを使用できる機能です。この無料コースでは、画像推論と関数呼び出しを適用して、モデルが画面の画像を処理し、状況を分析し、マウスクリックやキーストロークでコンピュータを操作する方法を学べます。今すぐ始めよう!
ニュース
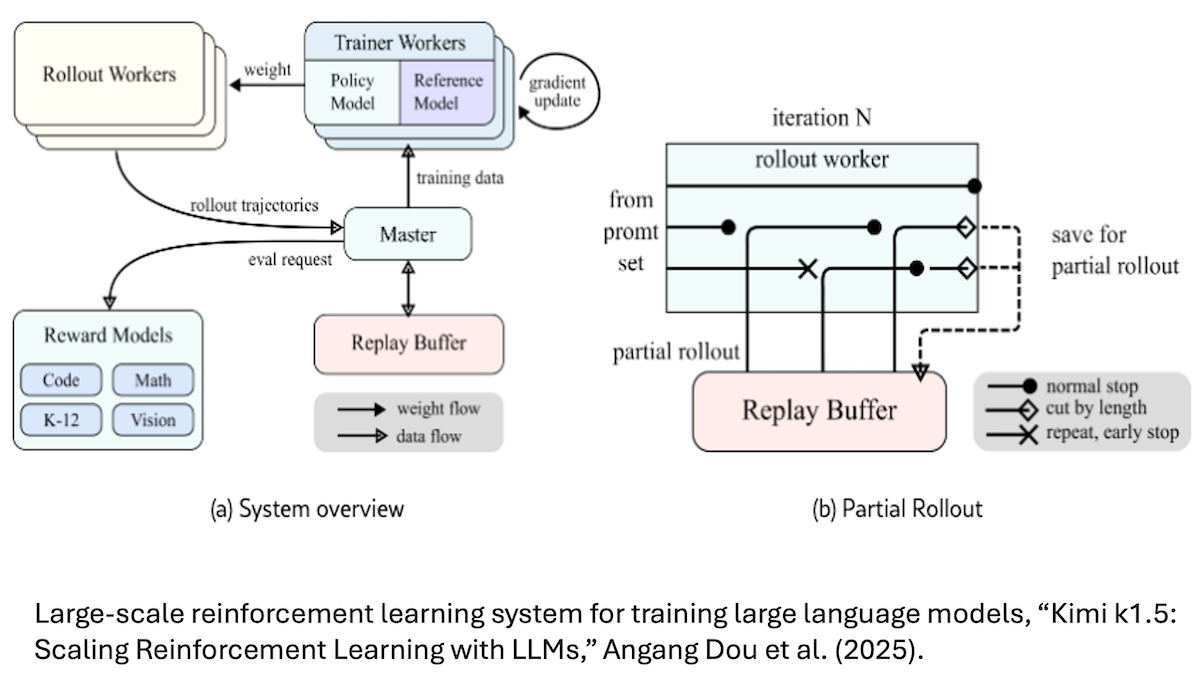
強化学習が熱を帯びる
強化学習は高度な推論能力を持つ大規模言語モデル構築の新たな方法として浮上しています。
新情報:最近の高性能モデル2つ、DeepSeek-R1(およびDeepSeek-R1-Zeroなどの派生モデル)とKimi k1.5は、強化学習で推論過程での論理の筋道を改善することを学びました。o1が昨年この方法を開拓しました。
強化学習(RL)の基本:モデルが特定の行動をとる、または目標を達成すると報酬または罰を与えます。教師あり・教師なし学習とは異なり、RLは明示的に正解を教えません。モデルは最初ランダムに動作し、報酬を獲得しながら望ましい行動を発見します。これがゲームやロボット制御のモデル訓練に適しています。
仕組み:思考の連鎖(CoT)を持つLLMを強化学習で改善するには、数学、コーディング、科学など既知の解答がある問題で正しい解を出すようモデルを奨励します。通常のLLM訓練が出力トークンごとに次のトークンを出しながらフィードバックを受けるのと異なり、この方法は、正確な結論に至る長い推論過程を生成すれば多くの中間トークンを含んでも評価し、推論過程自体には明示的な訓練を行いません。
- DeepSeekチームは、事前学習後の強化学習単独のファインチューニングでDeepSeek-R1-Zeroが解答を二重チェックする戦略を学ぶことを発見しましたが、一方で言語混在などの奇妙な動作も示しました。これを改善するために、DeepSeek-R1では強化学習前に少数の長いCoT例で教師ありファインチューニングを行いました。
- Kimi k1.5チームも同様に、長いCoTでのファインチューニング後に強化学習を行うことで独自の解法戦略を編み出せることを見出しました。この結果、長く正確な回答が出せるようになりましたが生成コストが高いため、2回目の強化学習で回答を短く抑える方策も加えました。AIME 2024ベンチマークでは回答トークン数が約20%減少、MATH-500では約10%減りました。
- OpenAIはo1の訓練法を限定的に公表していますが、チームメンバーは強化学習で思考の連鎖を改善したと述べています。
背景:RLはゲームやロボット制御モデルの訓練で長らく使われてきましたが、LLMでの役割は主に人間の好みに沿う調整に限られていました。人間の評価に基づく強化学習(RLHF)やAI評価に基づく強化学習(RLAIF)は、直接的な選好最適化が開発されるまで主流でした。
重要性:強化学習はLLMの推論訓練に意外に有効です。研究者が数学、コード生成、アニメーションなどより複雑なタスクにモデルを適用するにつれ、RLは重要な進展の道になっています。
私たちの見解:3年前までは強化学習は扱いづらく価値が低いと考えられていましたが、今や言語モデリングの重要な方向性です。機械学習は驚きに満ちています!

コンピュータ利用が勢いを増す
OpenAIはユーザーの代わりに簡単なウェブタスクを行うAIエージェントを発表しました。
新情報: Operatorは商品購入、チケット予約、フォーム記入などをブラウザ環境で制御し自動化します。デスクトップ向けにChatGPT Pro(月額200ドル)向けのリサーチプレビューとして提供中で、将来的な一般提供やAPI公開、多段階タスク(異なるベンダーのカレンダー間の会議調整など)対応も約束されています。
仕組み:OperatorはComputer-Using Agent (CUA)という新モデルを使い、テキスト入力をウェブ操作命令に翻訳し、ウェブのボタンやメニュー、テキスト欄と直接対話します。OpenAIはCUAの構造や訓練手法を非公開としましたが、シミュレーション及び実際のブラウザ状況での強化学習で訓練したと述べています。
- OpenAIによるテストの一つWebVoyagerでは成功率87%を記録。OSWorldでは成功率38.1%でした。AnthropicやDeepMindのテスト結果も併せて紹介しています。
- Operatorは未検証ウェブサイトとのインタラクションやユーザーの同意なく機密データ共有は禁止され、コンテンツフィルターを備え、別のモデルがリアルタイムで監視し不審な動作があれば停止します。
背景:Operatorは日常的タスクの自動化エージェント群の波に乗っています。OpenAIは先週ChatGPT Tasksを発表し、リマインダー設定などを支援しますがウェブ操作には対応していません(初期ユーザーは不具合や細かな指示の必要性を指摘しています)。AnthropicのComputer Useは基礎的なデスクトップ作業の自動化に注力し、DeepMindのProject MarinerはGemini 2.0基盤のウェブブラウジング支援AIです。Perplexity AssistantはAndroidスマホでUber予約などモバイルアプリ操作を自動化します。
意義:初期報告ではユーザーが人間より効率が悪いと感じることもありましたが、エージェント型AIは消費者市場に入ってきており、Operatorは多くの人が初めてAI支援を体験する製品として注目されます。多様な個人・ビジネス用途をサポートし、他のLLM開発者にとってのChatGPT同様、次世代製品のテンプレートになるでしょう。
私たちの見解:コンピュータ利用技術は成熟の段階に入り、勢いが鮮明です。AI開発者はツールボックスに加えるべきです。

ホワイトハウスが強力なAI政策を指示
新大統領の下、米国はAI規制の方針を転換し、制限を緩和して世界的支配を目指しています。
新情報:先週就任したトランプ大統領は行政命令に署名し、180日以内にAI行動計画を策定する期限を設定しました。この命令は国家安全保障、経済競争力、AIにおける米国のリーダーシップ強化を目指します。
仕組み:行政命令は策定責任を首席科学技術顧問のマイケル・クラツィオス氏(元Scale AIマネージングディレクター)、AIと暗号通貨特別顧問のベンチャーキャピタリスト、デイビッド・サックス氏、国家安全保障顧問のマイケル・ウォルツ氏の3名に割り当てています。
- AI行動計画は「人間の繁栄、経済競争力、国家安全保障を促進するために米国のAIの世界的支配を維持・強化」することを求めています。
- 命令はバイデン大統領の2023年の行政命令(トランプ大統領が撤回)で競争力や安全保障を妨げる可能性がある政策の停止・廃止を各機関長に指示します。
- 米国企業は「イデオロギー的偏見や社会的な工作から自由なAIシステム」を開発すべきとされており、政府はAIシステムにリベラルな政治的偏見が埋め込まれているとみなしています。
- 連邦管理予算局は行政の強調する競争力強化と国家安全保障に整合するAI企業に政府契約を優先的に付与します。
- 多くの条項は行動計画策定チームにかなりの裁量を残しており、解釈や実施が柔軟です。
AIインフラ拡充:行政命令とともにトランプ大統領はOpenAI、Oracle、ソフトバンクが参加するStargateを発表しました。3社はAI向け次世代データセンターなどコンピューティングインフラに1000億ドル投資、4年で5000億ドル規模の計画を示しました。加えて連邦土地での石油、ガス、再生可能エネルギー開発の規制障壁を緩和し、AI向けのエネルギー供給強化を狙った国家的エネルギー緊急宣言と国内エネルギー生産拡大命令も出しました。
意義:トランプ政権はバイデンの2023年規制を「過重で不必要」とし、技術革新を抑制して米国のAIリーダーシップを危うくしたと主張。新行政命令はAI開発に対する官僚的管理を減らし、より寛容な規制環境を作り(イデオロギー的偏見を除く)、米国の競争力と主導権強化を目指します。
私たちの見解:バイデン政権の2023年行政命令は実際のリスクではなく仮説的リスクを警戒し、モデル学習に用いる処理量をリスク指標とするなど不十分なところがありました。NISTのAI安全研究所はAI進展を妨げませんでしたが、全体としてはイノベーションや安全保障にプラスとは言えませんでした。新政権が仮説リスクでなく進展に注力する点は歓迎します。
ファインチューニングの微調整
合成データでのファインチューニングが定着しつつありますが、合成データがトレーニングタスクをよく表現していても、毒性など望ましくない特性を持つ場合があり、目標とする出力長など望ましい特質も一貫しないことがあります。研究者らは生成データの特性を選別し、望む特性を保持する手法を開発しました。
新情報:Cohereのルイーザ・シマブコロらはactive inheritanceと呼ぶファインチューニング手法を発表しました。これは望ましい特性を持つ合成データ例を自動選択します。
キーアイデア:合成ファインチューニングデータの単純な生成法は、モデルにプロンプトを与えて出力を収集し、それをファインチューニングに使うことです。合成データは安価なので、より適切な応答を複数生成し、目的に最適なものを選べます。
方法:著者はLlama 2 7BとMixtral 8x7Bを教師と生徒の両方として用い、Alpacaの52,000プロンプトを与え、生成結果の社会的バイアス、毒性、単語数、語彙多様性、キャリブレーションなどを自動評価しました。
- 各プロンプトに対し10応答を生成。
- 応答ごとにStereoSet、CrowS-Pairs、Bias Benchmark for Question-Answeringで社会的バイアスを測定。Perspective APIと独自コードで毒性を測定。HELMでキャリブレーションをチェック。TextDescriptivesでテキスト関連指標を計算。
- (i)初期応答全体、(ii)各プロンプトからランダムに1応答選択、(iii)望ましい特性に最も合致する応答1つでファインチューニングしたモデルを別々に構築。
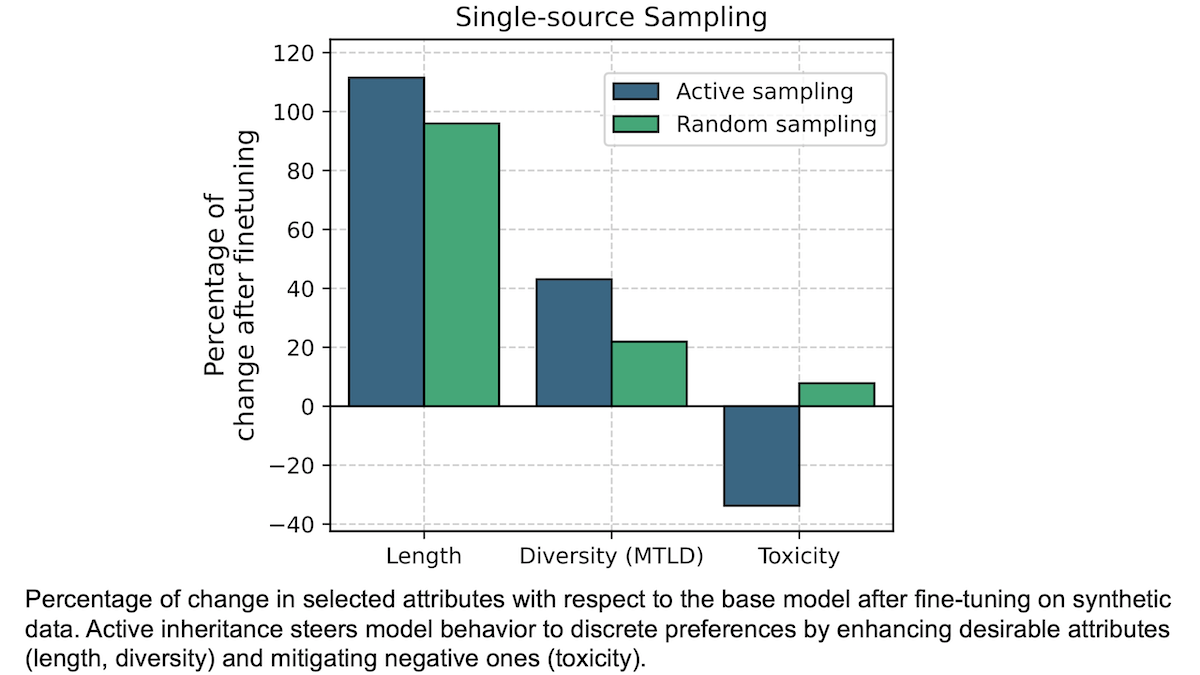
結果:望む特性に最適な応答でファインチューニングすると、初期応答やランダム選択の場合より性能がその特性で向上しました。
- 著者の手法はMixtral 8x7Bの毒性低減に効果的でした。ファインチューニング前の予想最大毒性は65.2(小さいほど良い)で、Llama 2 7Bの最も毒性の低い応答でファインチューニング後は43.2に減少。ランダム応答でのファインチューニングでは70.3に上昇しました。
- Llama 2 7Bの毒性も削減されました。ファインチューニング前は71.7で、最も毒性の低い応答でファインチューニング後は50.7、ランダム応答では68.1に低下。
- より一般的な性能指標への影響は限定的。たとえばLlama 2 7Bを最も毒性の低い応答でファインチューニングしたところ、7ベンチマークで平均正答率は59.97%から60.22%へ、ランダム応答選択では61.05%へとわずかに向上しました。
- 一方で性能低下もありました。Mixtral-8x7Bを最も毒性の低いLlama 2 7B応答でファインチューニングすると、7ベンチマークで70.24%から67.48%に、ランダム応答選択では65.64%に低下。
意義:合成データでの学習は増加中で、データ生成のベストプラクティスはまだ模索段階です。著者の手法は望ましい応答を自動選択し、負の特性を減らし正の特性を強化することで、この分野に貢献します。
私たちの見解:近年の知識蒸留はより高性能かつコンパクトなモデルを生み出しています。この手法はそこにさらなる制御の手玉を加えます。