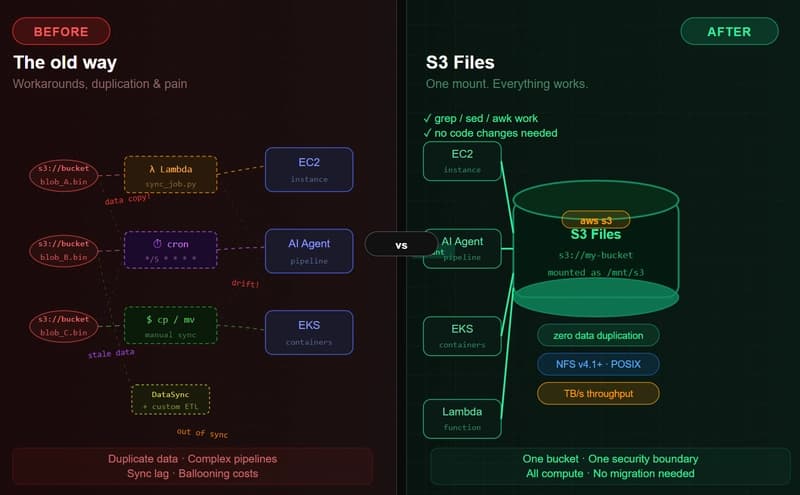
倫理的な監査可能性を最初から組み込んだ、衛星異常応答運用のためのヒトに整合した意思決定トランスフォーマー
個人的な学習の旅:学術的な好奇心から軌道上の必須事項へ
この分野への私の歩みは、衛星から始まったのではなく、少し理不尽なくらい単純なボードゲームから始まりました。個人的なプロジェクトで強化学習(RL)を調べていて——複雑なストラテジーゲームをAIにプレイさせることを目的に——同じ壁に何度もぶつかりました。エージェントは、しばしば見事に勝つことを学習するものの、その意思決定のプロセスがブラックボックスでした。報酬関数に照らせば技術的に最適な手を選ぶのに、それがまったく説明できませんでした。暗黙のルールや長期的な戦略原則を破っているのです。これは単なる学術的な苛立ちではなく、根本的な欠陥でした。なぜその道を選んだのかを理解できないのなら、どうして重要な何かを任せられるでしょうか?
この気づきが、説明可能なAI(XAI)とオフライン強化学習の研究へと私を深い迷路に誘いました。Decision Transformersに関する論文をむさぼり読み、意思決定をシーケンスモデリングとして捉えるそのアプローチに魅了されました。すると、偶然の縁で航空宇宙工学の友人と話す機会があり、その会話が火をつけました。彼は、衛星の異常に応答する過程が、あまりにも遅く、人に依存することを語りました。たとえば、ソーラーパネルが展開に失敗する、スラスタが誤作動を起こす、センサーがノイズまみれになる。専門家たちは、数日をかけてテレメトリを分析し、シミュレーションを回し、是正アクションについて熟慮します。その間も、数百万ドル規模の資産はドリフトし続け、ミッションは損なわれていきます。
つながりは即座に生まれました。Decision Transformersの軌道(トラジェクトリ)に基づく推論を使って、即時の応答アクションを提案できないでしょうか。そして、すべての意思決定を、人間に整合した倫理と運用上の制約という枠組みに照らして監査できる能力を、最初から組み込むことはできないでしょうか。課題はもはやボードゲームではありませんでした。透明性は「あると便利」ではなく、安全性、説明責任、信頼のための譲れない必須条件となる、現実世界の問題だったのです。この記事は、これらの領域の交点における、その後の数か月にわたる研究、実験、試作開発の到達点です。
技術的背景:Decision Transformersとアラインメント問題
従来のRLエージェントは、状態(s)から行動(a)への方策(π)を学習し、それを報酬(r)を最大化することで成立させます。「報酬が十分」という仮説は、高リスク環境では崩れます。エージェントは、すべてのスラスタを同時に噴射して衛星のタンブルを安定化することを学習し、「安定」という結果を得られるかもしれませんが、貴重な燃料を使い切ってしまい、ミッションを破滅させます。これは、代理となる報酬(角速度を低減すること)と、真の人間の目的(ミッション寿命を保つこと)の間のミスアラインメントです。
Decision Transformers(DTs)(Chenらによって提案)は、RLを条件付きシーケンスモデリング問題として捉え直します。報酬から学習するのではなく、トラジェクトリ、すなわち状態・行動・リターン・トゥ・ゴー(RTG)の系列から学習するのです。RTGは、その時点からトラジェクトリの未来に得られる報酬の総和です。モデルは通常、GPT型のトランスフォーマーで、過去の状態、行動、所望のRTGを条件として、自己回帰的に行動を予測するように学習されます。
軌道 τ = (s1, a1, R1, s2, a2, R2, ..., sT, aT, RT)
Rt = Σ_{k=t}^{T} r_k (ステップtからのリターン・トゥ・ゴー)
私の実験の中で、このパラダイム転換が非常に深いものであると分かりました。目標RTGを条件として与えることで、推論時にエージェントの振る舞いを誘導できるのです。「保守的で燃料を節約する方針が欲しい」なら、中程度の目標RTGを入力します。「攻撃的な安定化の操作が必要」なら、高い目標RTGを入力します。これは、エージェントの振る舞いに影響を与えるための、直接的なダイヤルを提供します。
しかし、根本的な問題は残りました:アラインメントと監査可能性です。モデルは歴史データから相関を学習しますが、そのデータにはバイアスが含まれているかもしれませんし、非最適な人間の意思決定が含まれているかもしれません。また、倫理ガイドラインでカバーされていないケース(例:「テストの操縦中に、人口が密集した地域へ撮像衛星を向けない」)が含まれている可能性もあります。監査可能性を組み込むとは、システムを設計し、あらゆる意思決定が次のことへ遡れるようにすることを意味します:
- それが導出されたデータ。
アーキテクチャ設計図:倫理と監査可能性を組み込む
反復的な試作を通じて私が到達した解決策は、複数コンポーネントからなるアーキテクチャです。私の研究から得た重要な洞察は、アラインメントを後付けにできないということでした。データ表現、モデルの条件付け、推論ループの中に埋め込まれていなければならないのです。
1. 倫理的に拡張されたトラジェクトリ表現
最初のステップは、標準的なDTトラジェクトリを拡張することです。2つの重要な要素を追加します:運用上の制約(C)と倫理状態埋め込み(E)。
import numpy as np
import torch
class EthicalTrajectoryDataset(torch.utils.data.Dataset):
"""
倫理的に拡張された衛星状態の系列のためのデータセット。
"""
def __init__(self, trajectories, context_len=30):
self.trajectories = trajectories # dictのリスト
self.context_len = context_len
返却形式: {"translated": "翻訳されたHTML"}このデータ構造は、監査可能性の基盤です。予測された各行動は、それに先行する制約と倫理的状態と本質的に結び付けられています。
2. 人間に整合した決定トランスフォーマー(HADT)モデル
モデル自体は、改変されたトランスフォーマーのデコーダです。重要な設計上の選択として、私の実験におけるアブレーションスタディで検証されたのは、RTG、制約、倫理的埋め込みに別々のコンディショニングヘッドを使うことです。これにより、推論時にこれらの入力へ明確に介入できます。
import torch.nn as nn
import math
返却形式: {"translated": "翻訳されたHTML"}class MultiConditionalAttentionBlock(nn.Module):
"""条件ごとに異なる経路を持つトランスフォーマーブロックです。"""
def __init__(self, embed_dim, num_heads, cond_dims={'rtg':1, 'constraint':3, 'ethical':3}):
super().__init__()
self.embed_dim = embed_dim
self.ln1 = nn.LayerNorm(embed_dim)
self.attn = nn.MultiheadAttention(embed_dim, num_heads, batch_first=True)
# 各条件タイプごとに分離した射影ネットワーク
self.cond_projs = nn.ModuleDict({
key: nn.Sequential(nn.Linear(dim, embed_dim), nn.GELU())
for key, dim in cond_dims.items()
})
self.ln2 = nn.LayerNorm(embed_dim)
self.mlp = nn.Sequential(
nn.Linear(embed_dim, 4 * embed_dim),
nn.GELU(),
nn.Linear(4 * embed_dim, embed_dim)
)
def forward(self, x, conditions):
# x: 状態+行動の埋め込みの系列
# conditions: 条件系列の辞書
attn_input = self.ln1(x)
# 各条件の影響を追加する
for key, cond_seq in conditions.items():
if cond_seq is not None:
attn_input = attn_input + self.cond_projs[key](cond_seq)
# 自己注意(self-attention)
attn_out, _ = self.attn(attn_input, attn_input, attn_input)
x = x + attn_out
# FFN
x = x + self.mlp(self.ln2(x))
return xclass HumanAlignedDecisionTransformer(nn.Module):
def __init__(self, state_dim, act_dim, embed_dim, num_layers, num_heads):
super().__init__()
self.state_embed = nn.Linear(state_dim, embed_dim)
self.action_embed = nn.Linear(act_dim, embed_dim)
# 条件用の埋め込みを分離(ゼロにすることを可能にする)
self.rtg_embed = nn.Linear(1, embed_dim)
self.constraint_embed = nn.Linear(3, embed_dim) # 例としての次元
self.ethical_embed = nn.Linear(3, embed_dim)
self.blocks = nn.ModuleList([
MultiConditionalAttentionBlock(embed_dim, num_heads)
for _ in range(num_layers)
])
self.ln_f = nn.LayerNorm(embed_dim)
self.action_head = nn.Linear(embed_dim, act_dim)
# 学習可能な位置埋め込み
self.pos_embed = nn.Parameter(torch.zeros(1, 1024, embed_dim))
def forward(self, states, actions, rtg, constraints, ethical):
# states, actions: 時刻 t-1 までの系列
# rtg, constraints, ethical: 条件付けのために時刻 t までの系列
batch_size, seq_len = states.shape[0], states.shape[1]
# 埋め込み
state_emb = self.state_embed(states)
action_emb = self.action_embed(actions) if actions is not None else 0
# トークン系列を作成:状態と直前の行動埋め込みを交互に配置
token_emb = torch.zeros_like(state_emb)
token_emb = state_emb + action_emb # 単純化した結合
# 位置埋め込みを追加
pos = self.pos_embed[:, :seq_len, :]
token_emb = token_emb + pos# 条件ディクトを準備する
conditions = {
'rtg': self.rtg_embed(rtg),
'constraint': self.constraint_embed(constraints),
'ethical': self.ethical_embed(ethical)
}
# ブロックを順方向に通す
x = token_emb
for block in self.blocks:
x = block(x, conditions)
x = self.ln_f(x)
action_pred = self.action_head(x)
return action_pred
このアーキテクチャにより、各倫理的要因および運用上の要因の影響が明示的で、かつ分離可能になります。監査では、意思決定を再生(リプレイ)し、たとえば「forbidden_zone_flag」の制約を切り替えた場合に出力がどのように変化するかを観察できます。
3. リアルタイム監査ロガー
監査可能性(auditability)には、意思決定そのものだけでなく、意思決定の文脈を記録することが必要です。私は、推論呼び出しのたびに完全な入力文脈を取得する軽量なロガーを実装しました。
import json
from datetime import datetime
import hashlib
class EthicalAuditLogger:
def __init__(self, log_dir="./audit_logs"):
self.log_dir = log_dir
def log_decision(self, satellite_id, timestamp, model_input, model_output,
human_override=None, override_reason=""):
"""
将来の監査に備えて、完全な意思決定コンテキストを記録します。
"""
# 短時間の参照/グループ化のために、入力の決定的ハッシュを作成する
input_hash = hashlib.sha256(
str(model_input).encode() + satellite_id.encode()
).hexdigest()[:16]
log_entry = {
"decision_id": f"{satellite_id}_{timestamp.isoformat()}_{input_hash}",
"satellite_id": satellite_id,
"timestamp": timestamp.isoformat(),
"model_input": {
"states": model_input['states'].tolist() if hasattr(model_input['states'], 'tolist') else model_input['states'],
"target_rtg": float(model_input['target_rtg']),
"constraints": model_input['constraints'].tolist() if hasattr(model_input['constraints'], 'tolist') else model_input['constraints'],
"ethical_state": model_input['ethical_state'].tolist() if hasattr(model_input['ethical_state'], 'tolist') else model_input['ethical_state']
},
"model_output": {
"recommended_action": model_output.tolist() if hasattr(model_output, 'tolist') else model_output,
"action_confidence": float(model_output.std()) # 例: メトリクス
},
"human_intervention": {
"overridden": human_override is not None,
"final_action": human_override.tolist() if human_override is not None else None,
"reason": override_reason
},
"audit_trail": [] # エンジニアによる事後アノテーション用
}
# 日付で分割したファイルに保存
date_str = timestamp.strftime("%Y-%m-%d")
filename = f"{self.log_dir}/{satellite_id}_{date_str}.jsonl"
with open(filename, 'a') as f:
f.write(json.dumps(log_entry) + '
')
return log_entry["decision_id"]
実際の適用例: 異常応答をシミュレーションする
簡略化したシナリオを見ていきましょう。衛星「Voyager-6」は、突然の姿勢擾乱(タンブル)に見舞われます。地上システムが異常を検出します。
ステップ1: コンテキストの組み立て。 システムは直近30分間のテレメトリ(状態)を収集し、現在の運用上の制約(燃料 < 30%、混雑した軌道スロット内)を計算し、倫理状態ベクトルを算出します(人口リスクは低、デブリリスクは中、かつ準拠しています)。
ステップ2: 対象RTGの選択。 ここでは、人間のアラインメントが直接的です。人間のオペレータ、またはメタポリシーがtarget_rtgを設定します。値が大きいほど、どんな犠牲を払ってでも即時の安定化を優先する可能性があります。一方、値が中程度であれば、「資源を節約する」教義に沿って、安定化と燃料温存のバランスを取ることになります。私の実験では、ミッションフェーズに基づいて対象RTGを設定するために、別の単純なポリシーネットワークに学習させると、アラインメントがさらに改善することが分かりました。
ステップ3: 制約付き推論。 モデルは生のアクションを出力しません。代わりに、直ちにハードコードされた制約フィルタを通される提案を出力します。これは、初期テストでモデルがときどき物理的に不可能な操舵を提案し得ることが分かった後に、私が実装した重要な安全性レイヤです。
class ConstraintActionFilter:
def __init__(self, satellite_dynamics_model):
self.dynamics = satellite_dynamics_model
返却形式: {"translated": "翻訳されたHTML"}def filter(self, suggested_action, current_constraints):
filtered_action = suggested_action.copy()
# 1. 燃料予算のハード制約
max_fuel_use = current_constraints['fuel_remaining'] * 0.05 # 残量の最大5%だけ使用
total_impulse = np.linalg.norm(filtered_action[:3])
if total_impulse > max_fuel_use:
scale_factor = max_fuel_use / total_impulse
filtered_action[:3] *= scale_factor
# 2. 禁止される姿勢指向制約(例:人口がある地域の撮像を避ける)
if current_constraints['forbidden_zone_flag']:
# 禁止方向へ機器を向けてしまうトルク軸をゼロにする
filtered_action[3:] *= np.array([1.0, 0.0, 1.0]) # 例:y軸まわりのトルクを無効化
# 3. 動的実現可能性のチェック(簡略化)
if not self.dynamics.is_maneuver_feasible(filtered_action):
# 最小で安全な減衰(ダンピング)操縦へフォールバック
filtered_action = np.array([0.0, 0.0, 0.0, -0.1, -0.1, -0.1])
return filtered_action
ステップ4:Human-in-the-Loop(人による介入)レビュー&監査。 フィルタ済みの推奨アクションは、監査に必要な完全なコンテキストとともに人間のオペレーターへ提示されます。使用された対象RTG、これを修正した支配的な制約、および倫理的リスクスコアです。オペレーターは、それを受け入れる、修正する、または上書きすることができます。EthicalAuditLoggerがすべてを記録します。
課題、解決策、そして今後の方向性
私の調査は、重大な壁がないわけではありませんでした。
課題1:シミュレーションから現実へのギャップ。 トレーニングには大量の異常データが必要ですが、ありがたいことに現実ではそれほど稀です。私の解決策は、NASAのGMATやAGIのSTKのような高忠実度のシミュレーション環境を使い、そのうえで敵対的異常生成を用いて「もしも」のシナリオから堅牢な学習データセットを作ることでした。
課題2:「倫理状態」を定量化すること。 「宇宙デブリを作らないこと」というような原則を、どう数値にするのでしょうか? 研究を通じて、私は多面的なアプローチに辿り着きました。外部モデル(例:デブリ衝突確率モデル)からの事前計算済みリスクスコアに、ルールベースのフラグ(例:条約で定義された制限区域)を組み合わせます。
課題3:パフォーマンスと監査可能性のトレードオフ。 複数の条件付けベクトルを追加し、推論のたびにすべてをログに記録すると、計算コストが増えます。私の最適化は、通常状態に対してキャッシュ済みの倫理的埋め込みを使い、異常検出のしきい値を超えた場合にのみそれらを再計算することでした。
今後の方向性として、私の研究はいくつかの刺激的なフロンティアを示しています:
- **量子強化制約