親愛なる皆様、
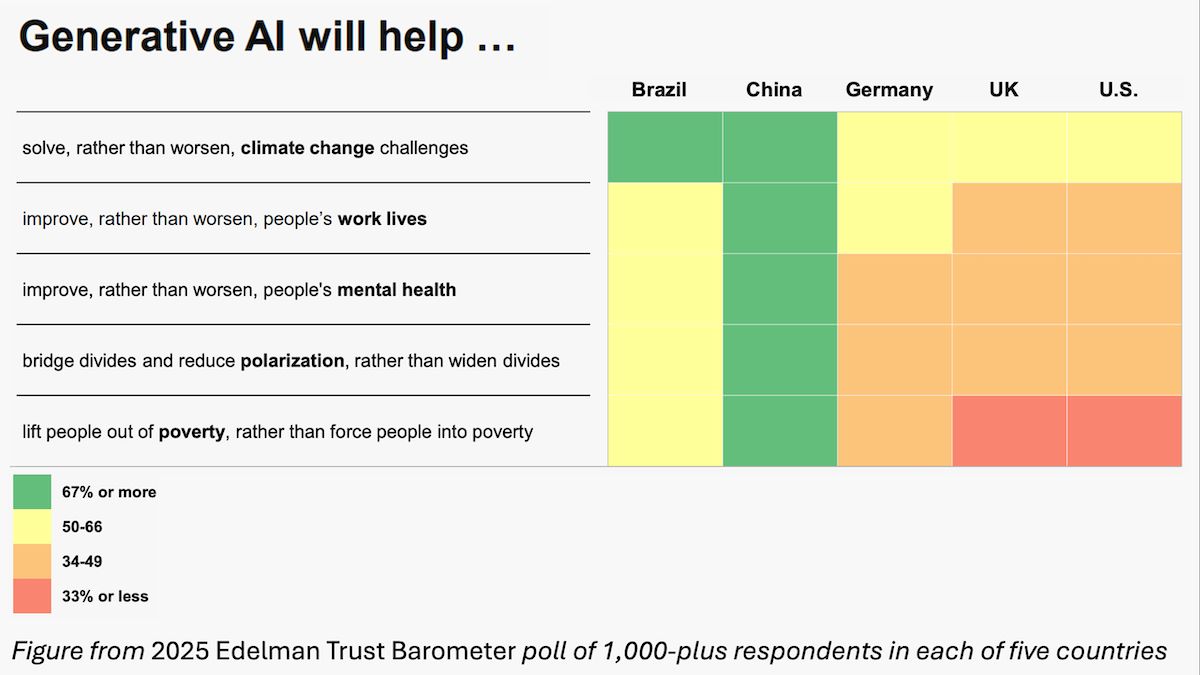
広告代理店のEdelmanとPew Researchによる別々の報告によると、アメリカ人、さらにはヨーロッパや西洋の多くの地域の人々はAIを信頼せず、熱意も持っていないことが示されています。AIコミュニティがAIがもたらす莫大な利益に楽観的である一方で、私たちはこれを真剣に受け止め、軽視すべきではありません。一般の人々のAIに対する懸念は進歩の大きな足かせとなり、私たちはそれらに対処するために多くのことができます。
Edelmanの調査によると、アメリカでは49%の人がAIの利用拡大を拒否し、17%が受け入れています。中国では拒否者が10%、受け入れ者は54%です。Pewのデータもまた、米国よりはるかに多くの国々がAI採用に熱心であることを示しています。
AIに対する好意的な感情は国家的な大きな利点です。一方で、広範なAIへの不信は以下を意味します:
- 個人の採用が遅れる。例えばEdelmanのデータでは、米国でAIをほとんど使わない人々は、動機不足やアクセス(55%)や技術への怯え(12%)よりも信頼の問題(70%)を挙げています。
- 社会的支援が必要な価値あるプロジェクトが妨害される。例えば、インディアナ州での地元の抗議運動はGoogleのデータセンター計画を潰しました。データセンター建設の妨害はAIの成長を阻害します。コミュニティにはAIへの一般的な嫌悪を超えたデータセンターへの具体的な懸念もありますが、それについては後のレターで触れます。
- AIに対するポピュリストの怒りは法律の成立リスクを高め、AI開発の妨げとなる恐れがあります。
はっきり言って、AIに取り組む私たちはAIの利益と害(例:ディープフェイクによるソーシャルメディアの汚染、偏ったまたは不正確なAI出力によるユーザーの誤誘導)を注意深く見極め、両者について正直に語り、問題の改善に努めながら利益を拡大していく必要があります。しかし、AIの危険性を誇張することは私たちの分野への信頼に実害を与えています。この誇張の多くは、核兵器と比較するなどして自社の技術を非常に強力に見せようとする主要なAI企業によって生み出されました。残念ながら、かなりの割合の一般大衆がこれを真に受け、AIが世界の終わりをもたらすと考えています。AIコミュニティはこの自傷行為を止め、社会の信頼を取り戻すべきです。
今後の方針は?
まず、人々の信頼を勝ち取るためには、AIが広く誰にとっても利益をもたらすように多くの努力が必要です。「生産性の向上」は一般には「上司がより多くの利益を得る」、あるいは「解雇」というコードワードのように見えがちです。ChatGPTは素晴らしいものの、人々の生活にさらに大きな良い影響を与えるアプリケーションを築くためにまだ多くの仕事があります。私は人々へのトレーニング提供が鍵になると考えています。DeepLearning.AIはAIトレーニングの先頭に立ち続けますが、それだけでは不十分でしょう。
次に、私たち自身が本当に信頼されるに値する存在になる必要があります。これはたとえ注目を集めたり政府に圧力をかけて競合製品(オープンソースなど)を妨げる法律を通そうとするときでも、過剰な誇張や恐怖を煽ることを避けなければならないということです。
また、誇張を広める報道を私たちのコミュニティが批判することも望みます。例えば、Nirit Weiss-Blattは優れた記事を書いています。60 Minutesが報じたAnthropicの研究において、シャットダウンを脅迫と呼んだ行動は誤解を招くものでした。研究は熟練した研究者が何度も試みた末にAIシステムを追い詰めて「脅迫」行動を起こさせたものであり、ニュース報道はそれを自然発生のように誤って伝えています。この報道はAIがどれほど頻繁に「策略」を巡らせるかについて非常に誇張されたイメージを多くに与えました。レッドチーミング(脆弱性検査)は重要な手法ですが、この誇張された報道は長期間AIに悪影響を与えるでしょう。
私がシリコンバレーに住んでいることは、AI愛好者のバブルの中にいることを意味します。これはアイデアを交換し、互いの創造を励ますには素晴らしい環境です。一方で、AIには問題があることも認識しており、AIコミュニティはそれらに取り組む必要があります。様々な職業の人々と話す機会が多く、芸術家はAIが自分の作品の価値を下げることを懸念し、大学生は厳しい就職市場にAIが拍車をかけていると心配し、親は子供がチャットボットに依存し有害な助言を受けていることを気にしています。
これらの問題全てを解決する方法はまだ分かりませんが、私はできるだけ多くの問題の解決に努力します。そして皆さんもそうであってほしいです。社会の信頼を取り戻すには私たち皆の取り組みしかありません。
これからも頑張ってください!
アンドリュー
DEEPLEARNING.AIからのお知らせ

「Building Coding Agents with Tool Execution」では、コーディングエージェントがどのように推論し、隔離されたサンドボックスでコードを実行し、ファイルを管理し、フィードバックループを扱うかを学びます。さらに、データ分析エージェントやサンドボックス化されたNext.jsウェブアプリなどの実例に適用します。今すぐ登録してください
ニュース

オープン3D生成パイプライン
MetaのSegment Anything Model(SAM)画像セグメンテーションモデルは、3Dオブジェクト生成のためのオープンウェイトスイートへと進化しました。SAM 3は画像をセグメント化し、SAM 3Dはセグメントから3Dオブジェクトを生成し、SAM 3D Bodyはセグメントの中のあらゆる人を3Dオブジェクトとして生成します。これら三つを試すことができます。
SAM 3: SAM 3はテキスト入力に基づいて画像と動画をセグメント化します。これまで通りジオメトリ入力(バウンディングボックスやポイント)に基づく物体のセグメント化も可能です。
- 入出力: 画像、動画、テキスト、ジオメトリ入力;セグメント化された画像または動画出力
- 性能: Metaのテストでは、多様な画像・動画セグメンテーションベンチマークで競合をほぼ全て上回りました。たとえばLVIS(テキストからの物体セグメント化)では、SAM 3(48.5%平均精度)がDINO-X(38.5%)を上回りました。LVISのトレーニングセットで学習したAPE-D(53.0%)には劣りました。
- 提供: 非商用・商用利用可能なウェイトとファインチューニングコードがMetaのライセンスの下で利用可能です。
SAM 3D: このモデルは、セグメンテーションマスクに基づいて画像から3Dオブジェクトを生成します。画像内の各オブジェクトを個別に予測することでシーン全体を表現でき、ポイントクラウドも取り込んで出力を向上させます。
- 入出力: 画像、マスク、ポイントクラウド入力;3Dオブジェクト(メッシュ、ガウシアンブラット)出力
- 性能: 写真から生成されたオブジェクトやシーンの評価で、人間はほぼ80%の割合でSAM 3Dの出力を他モデルより好みました。
- 提供: ウェイトと推論コードがMetaのライセンスの下で自由に利用可能です。
SAM 3D Body: Metaは、画像から3D人体形状を生成するモデルを追加で発表しました。入力のバウンディングボックスやマスクにより対象となる人体を指定でき、オプションのトランスフォーマーデコーダーで手の位置や形状をさらに調整可能です。
- 入出力: 画像、バウンディングボックス、マスク入力;3Dオブジェクト(メッシュ、ガウシアンブラット)出力
- 性能: Metaの評価では、SAM 3D Bodyは画像や動画から3D人体形状を生成する他モデルより多くのデータセットで最高の性能を示しました。例えば、野外の人物データセットEMDBでは62.9のMPJPEで、次点のNeural Localizer Fields(68.4)を上回りました。手の正確さを測るFreihandでは専門モデルに匹敵する性能を示しました。(なお、専門モデルはFreihandのトレーニングセットで学習されています。)
- 提供: ウェイト、推論コード、および学習データがMetaのライセンスの下で自由に利用可能です。
重要性: このSAMシリーズは、画像から3Dモデルを生成する統一されたパイプラインを提供します。各モデルは最先端を推進し、テキストからより正確な画像セグメント化、より人間に好まれる3Dオブジェクトおよび人体形状を実現しています。これらは既にMetaのユーザー体験に革新をもたらしており、例えばFacebookマーケットプレイスの利用者は家具やインテリアが実際の空間にどう見えるかを確認できます。
私たちの考え: これら三つのモデルは基本的に同じデータパイプラインで学習されています。モデルが苦手な例を見つけ、人間が注釈を付け、それを利用して学習を続けることで、質の高いデータセットのアノテーションにかかる時間とコストが大幅に削減されました(Metaの発表による)。

生成可能・編集可能なバーチャルスペース
通常3D空間を生成するモデルは、探索用の永続的な世界を作らず、ユーザー移動に伴って生成します。新たなモデルはエクスポートや修正が可能な3Dワールドを生み出します。
新情報: World LabsはMarbleを公開しました。これはテキスト、画像、その他の入力から永続的で編集可能かつ再利用可能な3D空間を生成します。同社はまたChiselという統合エディタを発表し、利用者はテキストプロンプトでMarbleの出力を修正したり、空間環境を一から作成できます。
- 入出力: テキスト、画像、パノラマ、動画、3Dボックスおよび平面レイアウト入力;ガウシアンブラット、メッシュ、動画出力
- 機能: 空間の拡張、空間の組み合わせ、視覚スタイルの変更、テキストプロンプトや画像からの編集、生成空間のダウンロード
- 利用形態: 月額サブスクリプションプランには無料(テキスト・画像・パノラマ各4個生成可)、月20ドル(複数画像・動画・3Dレイアウト12個生成)、月35ドル(拡張機能と商用権利付き25個生成)、月95ドル(全機能75個生成)がある。
仕組み: Marbleは複数のメディアタイプを受け付け、様々なフォーマットで3D空間をエクスポート可能です。
- 単一のテキストプロンプトや画像から3D空間を生成可能。より詳細な制御のために複数画像とテキスト(前面、背面、左右など)を受け付け、どの画像がどの部分にマッピングされるか指示できる。さらに短い動画、360度パノラマ、3Dモデルも入力でき、複雑な空間構築も可能。
- Chiselエディタは3D空間の直接作成・編集を支援。平面やブロックなどの幾何シェイプを壁や家具など構造要素に使用でき、テキストや画像のプロンプトでスタイル設定可能。
- 生成空間は拡張や接続をクリック操作で簡単に実行可能。
- 出力はウェブブラウザでレンダリング可能な半透明粒子による高品質表現のガウシアンブラット、物理シミュレーション用の単純化したコライダーメッシュ、高品質編集可能メッシュ、制御可能なカメラパスや煙・流水などのエフェクトを含む動画など。
性能: 初期ユーザーはゲーム風環境や現実の場所のフォトリアリスティックな再現を報告しています。
- Marbleは深度マップやポイントクラウドよりも物体の形状を含むより完全な3D構造を生成するとWorld Labsは述べています。
- そのメッシュ出力はゲーム開発、視覚効果、3Dモデリングで一般的なツールと統合可能です。
背景: 従来の生成モデルはユーザー移動に応じてその場で3D空間を生成することが多いですが、通常は保存や対話的再訪問ができません。Marbleは空間を保存・編集可能にする点で際立っています。例えば10月にWorld LabsはRTFMを披露し、ユーザーが移動中にリアルタイムで空間を生成します。競合するDecartやOdysseyはデモ公開中で、GoogleのGenie 3は研究プレビュー段階です。
重要性: World Labs創設者でスタンフォード教授のFei-Fei Liは空間知能の理解—物理的な物体が空間をどのように占め移動するかの理解—が言語モデルだけでは不充分な知能の重要な側面であると主張しています。Marbleは世界のモデリング分野の発展を促進し、ChatGPTや大型言語モデルがテキスト処理で進歩を引き起こしたのと同様の役割を果たそうとしています。
私たちの考え: Marbleによって生成されるバーチャル空間は幾何学的に一貫しており、ゲーム、ロボティクス、VRで価値を持つ可能性があります。ただし、空間内の物体は静的です。動きを含む仮想世界はAIが物理現象をより深く理解する方向に近づくでしょう。
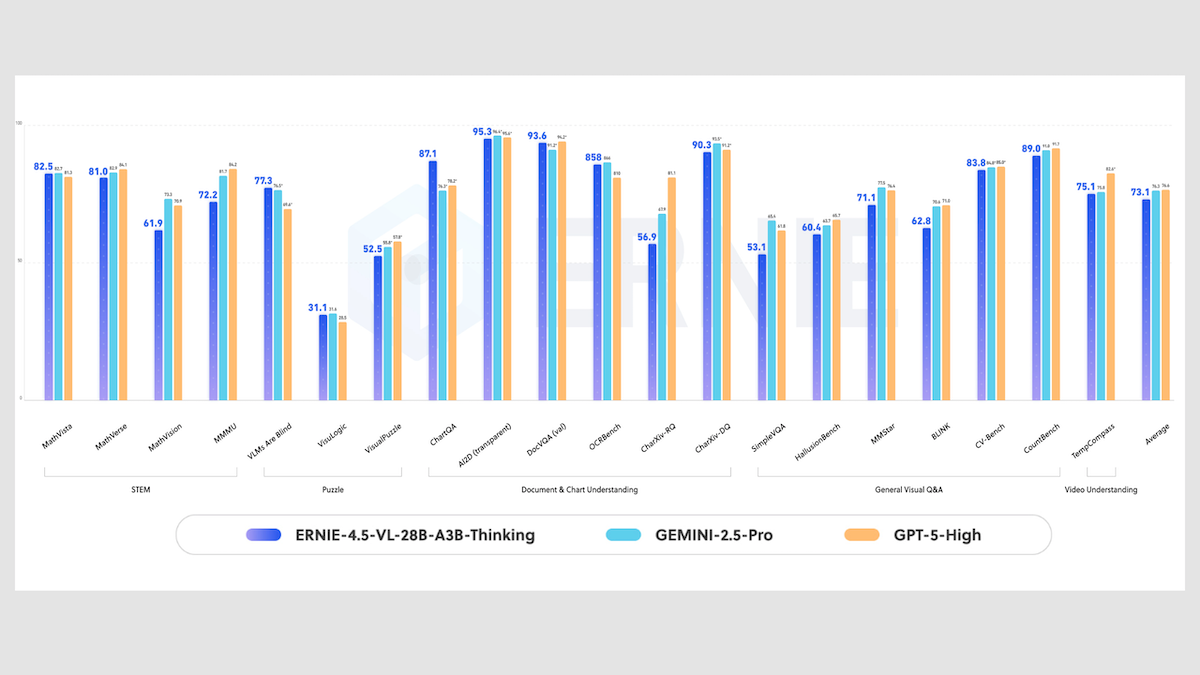
Baiduのマルチモーダル展開
Baiduは、軽量でオープンウェイトのビジョン・言語モデルと、米国競合に挑む巨大な専有マルチモーダルモデルの2モデルを公開しました。
Ernie-4.5-VL-28B-A3B-Thinking: Baiduの新しいオープンウェイトモデルは、テキストのみのMoE推論モデルErnie-4.5-21B-A3B-Thinkingに、70億パラメータのビジョンエンコーダを追加したものです。視覚推論タスクで同等または大きなモデルを上回ります。画面上のテキスト抽出や動画の時間解析が可能で、ツールを呼び出して画像の詳細をズーム表示したり関連画像を検索することもできます。
- 入出力: テキスト、画像、動画入力(最大128,000トークン);テキスト出力
- アーキテクチャ: 専門家混合(MoE)トランスフォーマー(合計280億パラメータ、トークンごとに30億アクティブ)と210億パラメータの言語デコーダ/エンコーダ
- 学習: 途中学習で視覚と言語の推論例を使用し、リインフォースメントラーニング(RL)でマルチモーダルデータのファインチューニングを行いました。MoEはRLで不安定になりやすいため、GSPOとIcePopを組み合わせて安定化を図りました。
- 特徴: ツール使用、推論機能
- 性能: Baiduによると、Ernie-4.5-VL-28B-A3B-Thinkingは3億パラメータだけをアクティブにしながら、文書理解タスクでより大きな専有モデルに匹敵しています。例えばChartQA(グラフ解釈)では87.1%の正答率でGemini 2.5 Pro(76.3%)、GPT-5高推論設定(78.2%)を上回りました。OCRBench(画像内文字認識)では858点でGPT-5(810点)より高いですが、Gemini 2.5 Pro(866点)には劣ります。
- 提供: Apache 2.0ライセンスで非商用・商用利用可能なモデルウェイトと、Baidu QianfanのAPIは入力・出力100万トークンあたり0.14ドル/0.56ドルです。
- 未公開: 出力サイズ制限、学習データ、報酬モデル
Ernie-5.0: BaiduはErnie-5.0をネイティブマルチモーダルと表現し、テキスト・画像・音声・動画を統一的に同時学習したモデルです。学習後に複数モーダルエンコーダを組み合わせたり専門モデルへ入力を振り分けたりする方式とは異なります。性能はGoogle Gemini 2.5やOpenAI GPT-5に匹敵するとしています。
- 入出力: テキスト、画像、音声、動画入力(最大128,000トークン);テキスト、画像、音声、動画出力(最大64,000トークン)
- アーキテクチャ: MoEトランスフォーマー(合計2.4兆パラメータ、トークンごとに720億未満アクティブ)
- 特徴: 画像・言語・音声理解、推論、主体的計画、ツール使用
- 性能: Baiduはマルチモーダル推論、文書理解、視覚質問応答テストでErnie-5.0がOpenAI GPT-5高推論版やGoogle Gemini 2.5 Proと同等か上回ると報告しています。OCRBench、DocVQA、ChartQAの各タスクではトップ評価です。MM-AU(マルチモーダル音声理解)やTUT2017(音響シーン分類)でも競争力がありますが、詳細スコアは公開されていません。
- 提供: 無料ウェブインターフェースおよびBaidu Qianfan APIで、利用料金は入力・出力100万トークンあたり0.85ドル/3.40ドルです。
- 未公開: 学習データ・学習手法
課題: Ernie-5.0の公開直後、ある開発者が指示無視でツールを繰り返し呼び出す問題を報告。Baiduは問題を認め修正中と発表しました。
重要性: Ernie-4.5-VL-28B-A3B-Thinkingは視覚推論タスクで高性能を安価に実現し、ファインチューニングや商用カスタムの柔軟性もあります。長らく期待されたErnie-5.0は所期の期待には届かなかったようで、視覚分野の一部でトップモデルには匹敵するものの、LM Arenaなどのランキング上位(Qwen3-MaxやKimi-K2-Thinkingなど)には届いていません。テキスト・画像・動画・音声の同時プレトレーニングは比較的新しく、異なるメディアのエンコーダ/デコーダを組み合わせる現在の複雑なシステムを単純化できる可能性があります。
私たちの考え: Ernie-5.0はGemini 2.5やGPT-5を上回る可能性がありますが、GoogleやOpenAIはすでにGemini 3やGPT-5.1へと移行済みです。

ロボットチームの協調
工場では、狭い空間で複数のロボットアームが互いに干渉しないように手動で動作がプログラムされています。研究者たちは、強化学習で訓練したグラフニューラルネットワークを用いてこのプログラミングの自動化を進めました。
新情報: Google DeepMind、ユニバーシティ・カレッジ・ロンドン、ロボティクスソフト企業IntrinsicのMatthew Lai、Keegan GoらはRoboBalletを開発しました。これはロボットアームを協調させるグラフニューラルネットワークです。
重要な洞察: 複数ロボットアームの協調は、関節の動きの可能な組み合わせを探索して衝突を避ける従来型の探索ベースプランナーでは計算が実質不可能です。ロボットや障害物が増えるごとに可能な構成は爆発的に増えます。グラフニューラルネットワークは、様々なロボット配置・障害物・目標位置で多数のシミュレーションを通じて、同期し衝突のない動作を学習することでこの制約を克服します。
仕組み: RoboBalletはロボット、障害物、目標物の位置と方向を入力とし、各アームの現在位置から目標までの関節速度を出力します。著者らはTD3アクタークリティックアルゴリズムという強化学習手法で完全にシミュレーション上で訓練しました。約100万のシミュレーション作業空間を生成し、4または8台の3関節Franka Pandaアーム、ランダム配置の30個の障害物ブロック、40個の目標位置・方向を含みます。衝突で開始する構成は除外しました。
- 作業空間は、ロボット、障害物、目標位置をグラフのノードとして表現。各ロボットの先端は目標位置、障害物、他のロボットにエッジで接続されます。エッジ埋め込みは相対位置、サイズ、方向などを符号化します。
- 訓練中は100ミリ秒ごとにモデルが全ロボットの関節速度を選択(アクター役割)。同時に選択の良し悪しを評価し(クリティック役割)、将来の報酬の期待値を算出します。
- 目標に触れたアームに報酬を与え、衝突にはペナルティを与えます。目標に触れることがほとんどなかったため、ヒンズサイトエクスペリエンスリプレイという方法で、偶然到達した点も意図的なゴールとして学習に利用しました。
- 損失は長期報酬を最大化する行動を促し、一時的な報酬最大化を避けるように促します。
結果: 訓練済みモデルは実世界でも試験されました。実環境では既知のジオメトリ情報、ロボット配置、障害物の3Dメッシュからグラフを生成します。
- 新しい作業空間では8台までのFranka Pandaアームの衝突のない軌道を生成しました。
- RoboBalletは作業を効果的に並列化し、4台で20目標達成に7.5秒かかっていたのが8台では4.3秒に短縮されました。
- 4台・20目標の簡易ベンチマークで、RoboBalletは最良手動最適化ベースラインと同等の8〜11秒で全目標位置に到達しました。
重要性: RoboBalletは学習アルゴリズムが多台数ロボットの協調を実世界設定で実現可能であることを示し、シミュレーションのみの訓練で達成しています。さらにモデルは堅牢で、ロボットが故障しても固定ルールでは対応できませんが、本モデルはロボット、タスク、障害物の関係を継続的に追跡し、失敗時に即座に計画を修正できます。
私たちの考え: 世界をグラフとして表現することは、データに組み込みの構造を与え、物体間の相対的な位置・関係性を追跡します。他のデータ構造では物体間関係を学習しなければならず、ネットワーク学習が複雑になります。グラフの利用は、関係性を理解しながらタスクを学ぶことを容易にします。