Amazon Bedrockを使ったテキストからSQLへのソリューションを構築することで、データ主導の組織における最も根強いボトルネックの1つを解消できます。それは、ビジネス上の問いを投げてから、明確でデータに裏付けされた答えを得るまでに生じる遅延です。たとえば、初回の質問が、よりインパクトの大きい仕事の後ろで待ち行列に並んでしまい、優先順位の競合に対処する必要があるという課題を、すでにご存じかもしれません。テキストからSQLのソリューションは、既存のチームを拡張します。ビジネスユーザーはルーチンの分析的な質問をセルフサービスで行えるため、組織全体の技術的なキャパシティを、複雑で価値の高い取り組みに振り向けられます。 「顧客セグメント別の前年比売上成長率はどれくらいですか?」といった質問が、技術チームに追加の作業負荷を生み出すことなく、誰にでもアクセス可能になります。
多くの組織では、ビジネス上の意思決定プロセスにおいて、データの洞察にアクセスすること自体が依然として大きなボトルネックになっています。従来のアプローチでは、SQL構文を学ぶ必要があるか、技術者のリソースを待つ必要があるか、もしくは特定の質問に答えてくれない可能性のある既製のダッシュボードに落ち着くことになります。
本記事では、Amazon Bedrockを使って、ビジネス上の質問をデータベースクエリに変換し、実行可能な回答を返す自然なテキストからSQLのソリューションを構築する方法を紹介します。モデルは、生のSQLだけでなく、実行された結果を秒単位で、数時間ではなく、明確で自然な言語のナラティブに統合して返します。このソリューションを大規模に展開する際のアーキテクチャ、実装戦略、学びを順を追って説明します。最後には、ビジネス上の質問とデータへのアクセス性のギャップを埋める、自分たちのテキストからSQLシステムをどのように作るかが理解できるようになります。
なぜ従来のビジネス・インテリジェンスが不十分なのか
Amazon Quickのようなツールは、自然言語でのダッシュボード照会や、自動的な洞察生成など、多くのセルフサービスの分析ニーズに対してすでに効果的に対応している点に注意する価値があります。これらのツールは、分析要件が、構造化されたダッシュボード、厳選されたデータセット、管理されたレポーティングのワークフローと整合している場合に最適です。ユーザーが、複雑で複数テーブルにまたがるスキーマを横断し、組織固有の深いビジネスロジック、領域に特化した用語、さらに既製のダッシュボードのデータセットがサポートしない一回限りの質問を扱う必要がある場合、カスタムのテキストからSQLソリューションが価値を持ちます。
テキストからSQLのソリューションを構築すると、従来のビジネス・インテリジェンス(BI)ツールだけでは足りない必要性を生む、3つの基本的な課題が明らかになります。
- SQLの専門知識という壁が、迅速な分析を妨げる。 多くのビジネスユーザーには、複雑なデータにアクセスするために必要な技術的なSQL知識がありません。単純な質問でも、複数テーブルの結合、時間に関する計算、階層的な集計が必要になることがあります。こうした依存関係により、ビジネスユーザーはカスタムレポートのために長時間待つことになり、一方でアナリストは戦略的な分析ではなく、反復的なクエリ依頼に貴重な時間を費やします。
- 最新のBIシステムにも柔軟性の境界がある。 最新のBIツールは、自然言語での問い合わせやセルフサービス分析において大きく進歩してきました。しかし、こうした機能は通常、あらかじめ厳選されたセマンティックレイヤー、管理されたデータセット、または事前にモデル化されたダッシュボードの範囲内で最も効果を発揮します。ビジネスユーザーが厳選された境界を超えて調査する必要があるとき、たとえば一回限りの結合、オンザフライでの組織固有の計算、セマンティックレイヤー外の生のデータウェアハウス・テーブルへの問い合わせが必要になると、依然として技術者による介入が必要となる制約に直面します。カスタムのテキストからSQLソリューションは、事前に設定されたセマンティックモデルに依存するのではなく、ビジネスコンテキストを動的に取得しつつ、データウェアハウスのスキーマに対して直接動作することで、このギャップを埋めます。
- コンテキストとセマンティックの理解が、翻訳ギャップを生む。 SQLアクセスが可能であっても、ビジネス用語を正しいデータベースのクエリへ変換することは難しい課題です。attainment、pipeline、forecastのような用語は、それぞれ固有の計算ロジック、特定のデータソース要件、そして組織によって異なるビジネスルールを持っています。どのテーブルを結合するべきか、指標がどのように定義されているか、どのフィルタを適用するかを理解するには、深い組織内の知識が必要ですが、多くのユーザーにはそれが容易に提供されません。
自分たちのソリューションを構築する際は、戦略的な原則、顧客セグメント分けのルール、運用プロセスといった、この深いビジネスコンテキストをシステムがどうエンコードするかを考えてください。そうすることで、ユーザーは複雑なデータベーススキーマやSQL構文を理解しなくても、より速くデータに基づく意思決定を行えるようになります。
仕組み:体験
アーキテクチャに入る前に、ユーザー視点での体験がどのようなものかを示します。
ビジネスユーザーが、たとえば、 「上位の顧客セグメントについて、今年の売上は昨年と比べてどう推移していますか?」 のような内容を、会話型のインターフェースに入力します。裏側では、システムが次の処理を数秒で実行します。
- 質問を理解する。 それが単一ステップの参照で済むのか、複数の要素に分解して扱う必要がある複雑な質問なのかを判断します。このケースでは、「売上の推移」「前年比の比較」「上位の顧客セグメント」が、それぞれ異なるデータ取得ステップを必要とすることを認識します。
- ビジネスコンテキストを取得する。 システムは、組織固有の指標定義、ビジネス用語、テーブル関係、データルールをエンコードしたナレッジグラフを検索します。システムは、売上が自社の環境で何を意味するのか、どのテーブルにそれが含まれているのか、また顧客セグメントがどのように定義されているのかを把握しています。
- SQLを生成し検証する。 システムは構造化されたSQLクエリを作成し、決定論的チェックによって正しさと安全性を検証したうえで、それをデータウェアハウスに対して実行します。検証で問題が見つかった場合、システムは人の介入を必要とせずに、修正して再試行します。
- 回答を統合する。 生のクエリ結果は、裏付けとなるデータとともに自然言語のナラティブへと翻訳され、ユーザーには洞察だけでなく、その信頼につながる透明性も提供されます。
その結果、ビジネスユーザーは複雑な分析的質問への回答を数秒から数分で得られます。また、基となるロジックを完全に可視化できます。アナリストは、反復的なクエリ作業から解放され、より価値の高い戦略的分析に集中できるようになります。
ソリューション概要
この体験を提供するために、ソリューションは3つの中核的な機能を組み合わせます。
- 自然言語理解とSQL生成のためのAmazon Bedrock上の基盤モデル(FMs)
- ビジネスコンテキストの取得のためのGraph Retrieval-Augmented Generation(GraphRAG)
- 高速なクエリ実行のための高性能データウェアハウス
Amazon Bedrockは、このアーキテクチャにおいて中心的な役割を果たします。大規模言語モデル(LLM)の推論レイヤーと、エージェントのオーケストレーション実行ランタイムの両方を提供するためです。Amazon Bedrockは幅広いFMsへのアクセスを提供しているため、チームは進化するパフォーマンス、コスト、レイテンシ要件に応じてモデルを選択・差し替えできます。その際、システムを再アーキテクチャする必要はありません。
アーキテクチャ図に示すとおり、
- Amazon Bedrock AgentCore Runtime は、エンドツーエンドのワークフローを調整するスーパー バイザー Agent をホストする中核となるオーケストレーション層として機能します。ユーザーの質問をルーティングし、文脈取得のために GraphRAG Search Tool を呼び出し、行レベルのセキュリティを適用し、SQL の生成と検証をトリガーし、データベース(Amazon Redshift)に対してクエリを実行します。ランタイムは、MCP や HTTP など複数の入口(エントリポイント)をサポートしており、AWS Quick Sight のような埋め込み型分析基盤やカスタムWebインターフェイスの両方との統合を可能にします。
- Amazon Bedrock AgentCore は、組み込みの オブザーバビリティ(可視化機能)も提供し、エージェント実行のトレースやパフォーマンス指標を Amazon CloudWatch に取り込み、モニタリング、デバッグ、継続的な最適化に活用できます。このマネージドランタイムにより、独自のエージェント基盤を構築する際の差別化されにくい大変な作業が軽減されるため、チームは業務ロジック、プロンプトのチューニング、ドメイン知識の充実に集中できます。
次の図は、このワークフローがどのように動作するかを示しています。
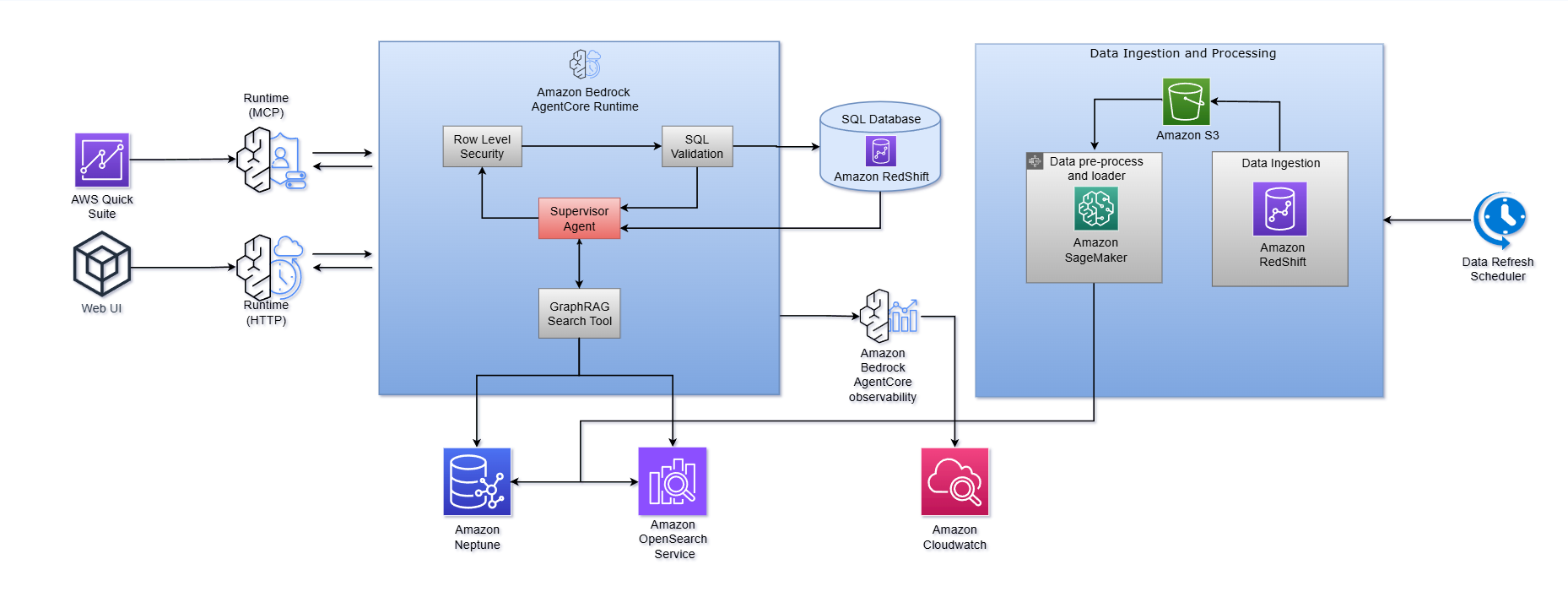
このアーキテクチャは、5つの主要な段階を持つ オーケストレーションされたマルチエージェントシステム として動作します。
ステージ 1:質問の分析と分解
質問が届くと、質問プロセッサーが最初にそれを分類します。たとえば 「Q4 の総売上はいくらでしたか?」 のような、単純で原子的、事実ベースの質問は、データ取得パイプラインに直接ルーティングされます。複雑、または複数パートからなる質問は、別々のエージェントチームが並行して処理できるように、自己完結した独立したサブ質問へと分解します。この分解ステップにより、複数のデータドメイン、期間、あるいはビジネス次元にまたがる高度な分析質問をシステムが扱えるようになります。
ステージ 2:知識グラフと GraphRAG のコンテキスト取得
ここでシステムは コンテキストの壁 を解決します。そして、素朴なテキストから SQL へのアプローチと比べた最も重要な差別化要因がここです。
意味的な基盤として、 Amazon Neptune と Amazon OpenSearch Service 上に構築された知識グラフを使用します。ここには、組織のテーブルのオントロジーが格納され、ビジネスエンティティ、指標、用語、組織階層の間の関係が捉えられます。重要なのは、このグラフが、テーブル所有者やドメインの専門家から得た 業務に特化した記述のためのドメイン知識で拡張されている点です。具体的には、ビジネス固有の説明、メトリクス定義、用語のマッピング、分類タグなどが、構造化された設定ファイルから読み込まれて追加されます。
システムが質問を処理する際、3つのフェーズで動作する 軽量な GraphRAG 検索 を実行します。
- ベクタ検索(Amazon OpenSearch Service を使用):ユーザーの質問に含まれる概念に合致する、意味的に関連性の高い列の値、列名、テーブルの説明を見つけます。
- グラフ探索(Amazon Neptune を使用):知識グラフ内の関係をたどり、照合された値からその親となる列、さらにその親となるテーブルへと辿っていきます。これにより、どのデータアセットが関連しているのか、またそれらがどのようにつながるのかを、完全なイメージとして構築します。
- 関連度スコアリングとフィルタリング:取得したコンテキストをランク付けし、構造化します。これにより、SQL 生成器には、必要な情報が、適切なテーブル、適切な列、適切な結合パス、適切なビジネスロジックとともに正確に渡されます。
知識グラフとそれに関連するデータは、スキーマの変更、新しいテーブル、変化するビジネス定義を反映するために 定期的に更新されます。コンテキスト層が豊かであればあるほど、下流の SQL 生成はより正確になります。
ステージ 3:構造化 SQL の生成と検証
システムは Amazon Bedrock の function calling 機能を使用して、SQL クエリを構造化データとして生成します。これにより厳密な出力形式が強制され、脆弱な後処理や複雑な正規表現を用意する必要がなくなり、信頼性が大幅に向上します。
生成されたクエリは、その後 抽象構文木(AST)レベルで動作する決定論的な SQL バリデータ を通過します。これらのバリデータは、潜在的に危険な操作や、文法的には正しいが意味的に危険なクエリ(たとえば、上限のないスキャン、フィルタの欠落、誤った集計ロジック)を、事前に検出します。バリデータが問題を検出した場合は、問題の内容を詳細に説明し、修正案を提示します。
さらに頑健性を高めるため、サイクル全体は 軽量な SQL 生成エージェント で包まれており、設定可能なリトライ上限が尽きるまで、妥当で実行可能なクエリが生成されるまで自動的に反復します。このアプローチは、プロンプトエンジニアリングだけに比べて 大幅に良い信頼性 を提供することを目指しています。
ステージ 4:テスト時並列コンピュート
曖昧または複雑な質問については、同じ質問を並列のエージェントに投入して、 複数の潜在的な回答や推論パスを同時に生成 できます。結果は多数決によって統合され、最も信頼できる出力が選択されます。これは、複数の解釈があり得る質問に特に有価であり、精度と頑健性の両方を実質的に向上させます。
ステージ 5:応答の合成
最後に、数値、データフレーム、実行ログを含む生のクエリ結果を、ユーザーに提供される 自然言語のナラティブ(説明文) として合成し、実行可能な回答として返します。クエリの完全な透明性は維持されます。ユーザーは、生成された SQL や基となるデータをいつでも確認でき、システムの出力に対する信頼を構築できます。
本番品質の結果を得るための主要な戦略
アーキテクチャだけでは不十分です。このソリューションを大規模に導入することで得られた以下の戦略は、本番利用が要求する精度、安全性、応答性を達成するために不可欠です。
エンドユーザーにプロンプトの形作りを任せる
経験豊富なユーザーであっても、曖昧な用語に対する既定の解釈が人によって異なることや、曖昧な質問への回答に関する期待がさまざまであることはよくあります。テーブル所有者や指定されたパワーユーザーが、統制された範囲内でプロンプトをカスタマイズできるようにするには、たとえばwebアプリケーションのような カスタマイズ用インターフェースを構築することを推奨します。カスタマイズは、コンテンツポリシーを強制し、プロンプトインジェクションの試みを制限し、変更が承認済みのテンプレートおよびパラメータ内に収まることを保証するバリデーションのガードレールを通過させるべきです。これにより、ドメイン知識や嗜好をシステムに取り入れつつ、無制限のフリーテキストによる変更を防ぐことができます。このカスタマイズ機能は、さまざまなビジネス領域が必要とする、きめ細かな理解を実現するうえで不可欠です。解決策は、「一律にすべてに適用する」アプローチを押し付けるのではなく、そうした違いに対応できるものである必要があります。
SQLバリデーションを安全性に不可欠な層として扱う
プロンプトエンジニアリングだけでは、文法的には正しいが意味的に誤ったSQLを生み出すエラーを取り除くことはできません。これらのエラーは特に危険です。なぜなら、もっともらしく見える結果を返して、ユーザーの信頼を静かに損なったり、誤った判断を導いたりし得るからです。SQLは定義が明確な言語であるため、 決定論的バリデータ なら、クエリがデータベースに到達する前に、こうした誤りの幅広い種類を検出できます。内部テストでは、このバリデーション層によって生成クエリ内の重大なエラーが効果的に回避できました。これは交渉の余地のない安全メカニズムとして優先してください。
レイテンシを徹底的に最適化する
会話型AIに慣れたユーザーは、ほぼ即時の応答を期待します。ライブデータの取得や計算の実行は静的な知識ベースから回答する場合より本質的に時間がかかりますが、レイテンシは第一級のユーザー体験として、アクティブに管理される必要があります。パフォーマンス分析によると、ワークフローには複数のステップがあり、SQL実行時間だけに対する最大の機会は、それらステップにまたがる累積時間にあることが分かります。
最適化するには、次に注力してください:
- 並列エージェント実行 – 複数パートの質問を逐次ではなく同時に処理します。これにより、複雑なクエリにかかる総時間を大幅に短縮できます。
- 高性能な分析用ストレージ – ビジネスインテリジェンスで典型的に見られる集約中心のワークロードに強い列指向データベースを使用します。
- トークン最適化 – プロンプトの最適化と応答フォーマットの標準化により、エージェントのやり取りごとの入力および出力トークン数を最小化します。各呼び出しが増え続けるコンテキストをエージェントに再取り込みさせることになる、ツール呼び出し型のエージェントフレームワークへの依存を減らしてください。
これらの最適化により、私たちのデプロイ環境では単純なSQLクエリは通常約3〜5秒で生成されます。実際の応答時間は、データウェアハウスのパフォーマンス、クエリの複雑さ、モデルの選定、知識グラフのサイズなどの要因によって変動します。インタラクティブなビジネス分析に対して現実的なレイテンシ目標を設定するために、ご自身の環境でベンチマークを行うことを推奨します。
最初からセキュリティとガバナンスを組み込む
行レベルセキュリティ(RLS) の統合を実装し、ユーザーが許可されたアクセス権のあるデータしか決して見られないようにします。システムは、既存の組織システムからのアクセス制御ポリシーを強制する複合(コンポジット)エンタイトルメントテーブルを維持します。ユーザーがクエリを送信すると、適切なRLSフィルタが、実行前に生成されるSQLへ 自動的に注入されます。これらはユーザーにとっては透過的ですが、強制は厳格に行われます。この層は、ユーザー体験に摩擦を増やすことなく、厳格なデータガバナンス基準を維持するよう設計してください。
実装結果と影響
この投稿で示したアーキテクチャと戦略に従うことで、テキストからSQLへのソリューションは、データの可用性と分析生産性の両面で大きな改善をもたらします:
- 速度の改善により、従来の手法では数時間または数日かかっていた複雑なビジネス課題への回答が、数分で得られます。複数テーブルの結合、時間的な計算、階層的な集計など、これまでカスタムSQL開発を必要としていた質問も、自然言語によって利用可能になります。
- 分析の民主化により、SQLの専門知識がないビジネスユーザーでも、営業オペレーション、財務計画、経営層のリーダーシップ領域で、より高度なデータ分析を行えます。これは通常、データエンジニアリングチームの分析作業負荷を減らし、反復的なクエリ要求ではなく、戦略的な取り組みに集中できるようにします。
- 複雑なクエリの取り扱いにより、次の機能を備えた多次元の収益分析をサポートします:
- 自動セグメンテーション
- 分散の説明付きの、前年差(前年同月比)および月次のトレンド
- 利用パターンを伴う粒度の高いレベルでの顧客インテリジェンス
- 目標との比較を含むフォーキャスト分散分析
- 期間およびビジネスユニットをまたいだクロスファンクショナルなベンチマーク
今後に向けて
Amazon Bedrock によって強化されたテキストからSQLへのソリューションは、データ分析をビジネスユーザーにとって利用しやすいものにするための大きな前進です。 Amazon Bedrock Agents を用いるマルチエージェントアーキテクチャは、複雑なクエリ分解と並列処理をサポートし、一方で知識グラフはビジネス上の文脈と意味理解を提供します。これらの構成要素を組み合わせることで、技術的な障壁なしにビジネスユーザーがデータに基づく意思決定を行える、正確で高速かつ利用しやすい分析が実現されます。
独自のソリューションを構築する際には、知識グラフのカバレッジを追加のビジネス領域へ拡張し、高度なキャッシュ戦略によって応答レイテンシを最適化し、より多くのエンタープライズデータソースと統合することを検討してください。 Amazon Bedrock Guardrails は、出力のバリデーションと安全性の機能を強化するもので、探索する価値があります。また Amazon Bedrock Flows は、エージェント型ワークフローのための高度なオーケストレーションパターンを提供します。
Amazon Bedrock で利用可能なFMの柔軟性、エージェントのオーケストレーション機能、知識ベース統合は進化を続けており、組織をまたいだビジネスユーザーにとってデータ分析がますます直感的で強力なものになっていきます。
独自のテキストからSQLへのソリューションを構築するには、Amazon Bedrock ユーザーガイドを調べ、Amazon Bedrock ワークショップに参加し、 Amazon Bedrock を使用した生成 AI エージェントの構築に関するガイドをご確認ください。最新の動向については、AWS の最新情報(What’s New with AWS)をご覧ください。
謝辞
この取り組みを実現するうえで、そのビジョンと助言によって道を切り開いてくださったエグゼクティブスポンサーおよびメンターの皆さまに、心より感謝申し上げます。: Aizaz Manzar(AWS グローバルセールス ディレクター); Ali Imam(スタートアップセグメント責任者); そして Akhand Singh(データエンジニアリング責任者)です。




