DeepSeekの新モデルは効率が良すぎてトースターで動くほど…と言うのは、つまりHuaweiのNPUのことです
プレビューで利用可能に。DeepSeek V4は推論コストをR1の一部にまで削減
中国のAI界の寵児DeepSeekが戻ってきた。最先端の米国の専用(プロプライエタリ)LLMに匹敵する性能を約束する、新しいオープンウェイトの大規模言語モデルだ。おそらくそれ以上に重要なのは、推論コストを劇的に削減できると主張していること、そしてHuaweiのAscendファミリーのAIアクセラレータへの対応を拡張していることだ。
金曜日に発表されたDeepSeek V4は、Hugging Faceのような人気モデルリポジトリ、同社のAPI、そしてWebサービスで、2つの新しいフレーバーとしてダウンロード可能になっている。1つ目は、アクティブパラメータが130億(13 billion active parameters)に相当する、より小型の2,840億パラメータのFlash混合・専門家(MoE)モデル。もう一方の大きいモデルは、1.6兆パラメータで、そのうち常に稼働しているのは490億パラメータだ。
V4-Proは3,300億トークンで学習されており、DeepSeekを信じるなら、オープンウェイトのすべてのLLMを上回り、ベンチマーク群においては西側の最高の専用モデルとも肩を並べる。
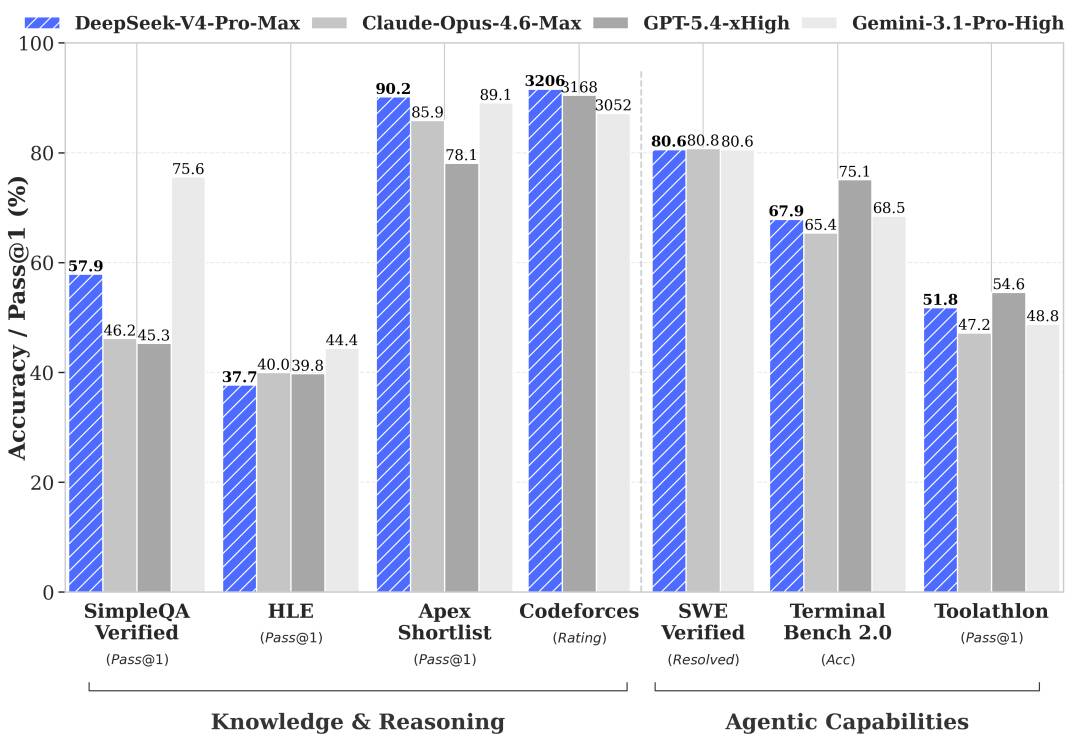
DeepSeekが、自社のV4モデルが競合に対してどのように見えるかを示したもの。 - クリックして拡大
もちろん、これらの主張は割り引いて受け止めるべきだ。DeepSeekは、V3やR1ファミリーのモデルによって中国の開発者を一躍有名にしたという強い実績がある。しかし、決められたベンチマークで好成績を出すことが、実世界のアプリケーションでも同じように通用することを意味するとは限らない。
我々は、DeepSeek V4-Proが同社の従来の取り組みよりはるかに良いものになると期待している。新モデルは、ほぼ1兆パラメータ分も大きくなっており、推論時に使用されるアクティブパラメータも増えている。とはいえ、DeepSeek V3でも同じことが起きたように、大規模なフロンティアモデルは、従来考えられていたよりも少ない計算資源で学習できるのだと示されたとしても、ベンチマークだけでは全てが分かるわけではない。
内部では、DeepSeek V4は、開発者によれば、モデルの提供コストを大幅に下げられるはずだという、いくつかの新しいアーキテクチャ上の変更を導入しています。
最初の変更は、かなり単純です。今回は、DeepSeekが2つ目の、より小型のFlashモデルをリリースします。これにより、実行に必要なインフラが少なくて済み、より低コストで、よりインタラクティブなユーザー体験を提供できます。小型モデルは単純に、提供コストが安くすみます。
それ自体は新しい戦略ではありませんが、少なくとも自社のモデルに関して言えば、DeepSeekがそれを今になってようやく取り入れている、という点が新しいところです。
より大きく、かつ意味のある変化は、DeepSeekが注意(attention)を計算する方法にあります。モデルのattention機構は、プロンプトを、出力トークンを生成するために使われるキー・バリューの組に変換する際に影響します。
新しいモデルと並行して発表された論文で、DeepSeekの研究者は、2つの技術を組み合わせたハイブリッドattention機構について説明しています。それは、推論時に必要な計算量と、モデル状態を追跡するために使われるKVキャッシュが必要とするメモリ量を減らすために、Compressed Sparse Attention(圧縮されたスパースattention)とHeavy Compressed Attention(強く圧縮されたattention)を組み合わせるものです。
後者の要素がDeepSeek V4の効率性の鍵です。これらのキャッシュはかなり大きくなり得るためです。推論提供事業者もまた、コールドスタートのペナルティを避けるために、これらをシステムメモリやフラッシュにオフロードする傾向があります。より強く圧縮されたKVキャッシュは、大規模な推論デプロイメントに必要なメモリとストレージをより少なくすることにつながります。
これらを組み合わせることで、モデルはDeepSeek V3.2に比べて9.5倍〜13.7倍少ないメモリ使用量で、100万トークンのコンテキストウィンドウをサポートできます。
さらにメモリ使用量のフットプリントを減らすために、DeepSeekは、より低精度のデータ型を使うという伝統を続けています。DeepSeek V3は、FP8で学習された最初期のオープンウェイトモデルの一つでした。
現在、V4の両モデルはFP8とFP4の精度を混在させて使用しています。具体的には、モデル開発者はMoE(Mixture of Experts)のエキスパート重みに対して、量子化を意識した学習(quantization-aware training)を使いました。
先に述べたとおり、FP4はFP8と比べてモデル重みの保存に必要なメモリを実質半分にします。精度の低下に耐えられるなら、これは大きな節約になります。
DeepSeekのアーキテクチャ上の改善は、推論だけにとどまりません。V4では、モデル開発者が、収束を速め、学習の安定性を高めることを目的とした新しいオプティマイザ「Muon」を導入しました。
自社開発のモデルを自社開発のハードウェアで
おそらく最も興味深い、しかも新しいモデルの中では詳細が最も少ない要素は、モデルが動いているハードウェアに関する点です。DeepSeek V3がホッパー(Hopper)GPU向けに大きく最適化されていたのに対し、V4はNvidiaとHuaweiの両方のアクセラレータで動作することが検証されています。
DeepSeek V4の論文では、チップについては話半分に触れる程度で、「同社は『きめ細かなEP(Expert Parallel)方式』をNvidiaのGPUとAscend NPUの両方で検証した」と述べています。
ここで明確にしておくと、これはモデルが完全にHuaweiのハードウェアだけで学習されたことを意味するわけではありません。そうではなく、DeepSeekが中国の通信大手のAIアクセラレータを、モデル提供(サーブ)に用いるために検証した、ということです。
DeepSeekが事前学習(pre-training)にはNvidiaのGPU、強化学習にはHuaweiのアクセラレータを組み合わせて使った可能性はあります。後者は、モデルに新しいスキルや振る舞い、そして思考の連鎖(chain of thought)の推論を教えるために用いる、推論に近い位置づけの事後学習ステップです。ただし、論文はこの点を直接扱ってはいません。
一般に、新しいチップメーカーにとって推論は参入障壁が低くなります。しかしある時点で、DeepSeekは自社のモデルをHuaweiのチップでも学習しようとしていました。この取り組みは、報道によれば不具合のあるチップ、非常に遅いインターコネクト、未成熟なソフトウェアスタックによって頓挫し、その結果DeepSeekは最終的にNvidiaの陣営に戻されることになったといいます。
最後に、V4で4ビット精度のデータ型を使っていることから、NvidiaのBlackwellアクセラレータに手を伸ばしたのだと想像する人もいるかもしれません。BlackwellはAI兵器商人が中国に売ることを許されていないものですが、だからといって厳密に必要というわけではありません。
ホッパーGPUはFP4のハードウェア加速には対応していませんが、重みのみのデータ型として扱う形なら動かせます。このアプローチは浮動小数点の性能向上にはつながりませんが、学習と推論の両方で必要なメモリフットプリントと帯域幅を削減できます。そのため、多くのユースケースでは妥当なトレードオフになります。
- Anthropicは、賢くしようとしてClaudeを「バカにした」ことを認める
- Claude Opus 4.7が過剰に熱心な問い合わせ監視(クエリ警官)に変わってしまったと開発者が不満
- 「それを支配する唯一の1チップ」は忘れよう:TPU 8でGoogleは勝利のためのAI兵器競争に臨む
- マイクロソフトのGitHubが供給逼迫の中でCopilotアカウント登録を差し止め
売れる価格で
DeepSeek V4は現在プレビュー段階で、ベース版とインストラクション調整版の両方が、ダウンロード用、または同社のAPI経由で利用可能になっています。
同社は当然のように、APIアクセスで小型モデルを、入力トークン(未キャッシュ)100万あたり0.14ドル、出力トークン100万あたり0.28ドルという割安な料金で提供しています。
より大きいProモデルは、入力トークン100万あたり1.74ドル、出力トークン100万あたり3.48ドルと、かなり高額ですが、それでも、主要な西側のAIベンダーが最上位モデルへのアクセスに請求している金額の一部にすぎません。参考までに、OpenAIはGPT-5.5. ®について、入力トークン100万あたり5ドル、出力トークン100万あたり30ドルを請求しています。




