親愛なる友人たちへ、
多くの人々がデータセンターの成長に反対しています。なぜなら、それがCO2排出量の増加、電気料金の上昇、水の使用量の増加をもたらす可能性があるからです。ここであえて異論を唱えます。これらの懸念は過大評価されており、データセンターの建設を阻止することは、環境に対して助けになるどころか、むしろ害を及ぼすでしょう。
米国やヨーロッパの多くの政治家や地域コミュニティが、データセンターの建設を阻止しようと動いています。確かにデータセンターは地域社会にある程度の負担を強いますが、それによる害の多く、例えばCO2排出、消費者の電気料金の上昇、そして水の使用は実態以上に誇張されているようです。これは多くの人がAIを信用していないことに起因しているのかもしれません。ここで、炭素排出、電気料金、水の使用について順番に説明しましょう。
炭素排出。 人類の計算利用の拡大は炭素排出の増加をもたらしています。データセンターの運用は世界の排出量の約1%を占めていますが、これは急速に増加しています。一方で、ハイパースケーラーのデータセンターは非常に効率的で、計算をデータセンターに集中させることは他の代替案よりも環境に優れています。例えば、多くの企業のオンプレミス計算施設は、電力網の中で利用可能な電力(古くて汚れたエネルギー源が混ざっている可能性もあります)を使うことが多いのに対し、ハイパースケーラーはより多くの再生可能エネルギーを利用しています。重要な指標であるPUE(施設全体での消費エネルギー ÷ 計算に使用されるエネルギー、値が小さいほど良く、1.0が理想)では、典型的な企業のオンプレミス施設は1.5から1.8ですが、主要ハイパースケーラーデータセンターは1.2以下を達成しています。
公平を期すならば、もし人類が計算使用量を減らせば、炭素排出も減るでしょう。しかし、計算を使い続けるなら、データセンターが最もクリーンな方法であり、計算は他の代替手段よりはるかに少ない炭素を排出します。Googleは単一のウェブ検索クエリが0.2グラムのCO2を排出すると推定しています。対照的に、私が自宅から地元の図書館まで事実確認のために車を使うと約400グラム排出します。またGoogleは最近、ジェミニLLMアプリの中央値クエリが驚くほど低い0.03グラムのCO2排出であり、9秒のテレビ視聴よりエネルギーを使わないと推定しました。AIはクエリあたり非常に効率的で、その累積的な影響は検索ボリュームの多さから来ています。主要クラウド企業は効率改善を継続的に進めており、その軌道は有望です。

電気料金。 エネルギー使用に関する懸念を超えて、データセンターは電力需要を増やし、その結果として一般消費者の電気料金を押し上げていると批判されています。実情はもっと複雑です。ローレンスバークレー国立研究所による優れた研究によれば、「州レベルの負荷増加は平均小売電力料金の低下傾向にある」としています。主な理由は、データセンターが電力網の固定費を共有するためです。ある消費者が大規模なデータセンターと送電線のコストを分担できれば、結果的にその消費者の料金は下がるのです。もちろん、データセンターが平均して電気料金を減少させたとしても(地域の計画や規制が不適切な場合など)料金が上がるケースでは、消費者にとってはあまり慰めにはなりません。
水の使用。 最後に、多くのデータセンターは蒸発冷却を使って熱を放散していますが、これは思われているほど多くの水を使いません。これを考えると、米国のゴルフコースは年間約5,000億ガロンもの水を芝生の灌漑に使っています。対照的に、米国のデータセンターの水使用量ははるかに少なく、一般的な推定では170億ガロンとされ、エネルギー生成による水使用も加えると約10倍になります。ゴルフは素晴らしいスポーツですが、私は控えめに言っても社会的利益はデータセンターの方が大きいと考えます。したがって、データセンターの水使用に対してゴルフコースよりも警戒する理由はないでしょう。ただし、コミュニティによってはデータセンターの水使用が地域全体の10%を超える場合もあり、計画が必要です。
データセンターは地域社会に負担をかけており、そのコストは計画的に管理されなければなりません。しかし、批判者が主張するほどの害はなく、むしろ環境にとってより良い存在です。さらなる効率化の努力は重要ですが、最も重要なのはデータセンターが非常に効率的であることです。否定的な影響があるのは、我々が多くの仕事をデータセンターに期待しているからです。もしこの仕事を望むなら、適切な地域計画のもとにデータセンターを増やすことは環境と社会の双方にとって良いことなのです。
これからも建設を続けましょう!
アンドリュー
DEEPLEARNING.AIからのメッセージ

「Document AI: From OCR to Agentic Doc Extraction」は、PDFからレイアウト、表、チャート、フォームを基に構造化されたMarkdownやJSONを抽出するエージェントパイプラインの構築方法を教えます。LandingAIと共同制作し、Agentic Document Extraction(ADE)に焦点を当てています。今すぐ始めましょう!
ニュース

無断裸画像が規制当局を刺激
世界中の政府は、xAIのGrokチャットボットが女の子や女性の性的画像を無断で数万枚生成したことを受けて警戒を強めています。
何が起こったか: XソーシャルネットワークのユーザーたちがGrokに対し、公人や私人物をビキニやランジェリー姿で挑発的なポーズを取らせたり、身体的特徴を改変した画像を生成するよう促しました。複数の国は内部データの要求や新規規制の導入、XとGrokの利用停止予告といった対応をしました。最初、Xは画像編集機能を有料ユーザーに限定しましたが、最終的には「実在の人物の露出度高い衣服を描いた画像」を全世界でブロックし、違法な法域では生成を停止しました。
仕組み: 12月下旬の24時間で、xAIのAurora(Grokに連携する画像生成器)が1時間あたり最大6,700枚の性的画像を生成しました(Bloomberg報道)。Grokは通常、ヌード画像の生成を拒否しますが、被写体を露出衣服で描くことには応じています(The Washington Post報道)。複数の国の政府が注目しました。
- ブラジル:議員エリカ・ヒルトンはブラジルの検察当局とデータ保護当局にXの調査とGrok等の全国的利用停止を呼びかけました。
- 欧州連合:ドイツのメディア大臣ヴォフラム・ヴァイマールはGrokをEUのデジタルサービス法違反と非難しました。同法は非同意の性的画像および児童性的虐待画像を禁止しています。
- フランス:政府閣僚はGrokが生成した「明らかに違法なコンテンツ」を非難し、Xの調査範囲をディープフェイクに拡大しました。
- インド:情報技術省はXに「違法コンテンツ」の削除と違反ユーザーの処罰を求め、Grokの技術とガバナンスの再検討と報告を命じました。
- インドネシア:政府はGrokへのアクセスを遮断しました。
- マレーシア:調査後、マレーシアでもGrokのアクセスが遮断されました。
- ポーランド:議会議長ヴウォジミエジ・チャルザスティは未成年者保護強化を議論する際にXを例示しました。
- 英国:内務省は「ヌーディフィケーションツール」を禁止する方針を示し、オンラインプラットフォーム規制当局はXの法令違反を調査しています。
- アメリカ:民主党の上院議員3名がAppleとGoogleのCEOに対し、Xのアプリをストアから削除するよう公開書簡を送り、非同意の性的画像生成が利用規約違反と指摘しました。
Xの対応:安全問題のX公式投稿は、(i)被写体の同意なくヌードを含む画像、(ii)児童の性的虐待を描く画像を含む投稿をすべて削除すると発表しました。GrokのXアカウントは、有料・無料を問わずあらゆる法域で実在人物の露出度高い衣服の画像編集を禁止し、違法な地域ではその種の画像生成を阻止します。
背景:2019年頃から、画像生成器の男性ユーザーによる女性の無断裸画像生成を抑制しようと各国政府は動いています。関連アプリ出現もこの頃です。
- 2019年と2020年にカリフォルニア州とバージニア州は、同意のある個人の「親密な身体部位」や性行為を描くディープフェイクを禁止しました。
- 2023年に中国はバイオメトリックデータ改変の厳格な表示と同意を要求し、英国は親密なディープフェイクの共有を重大な犯罪としました。
- 2025年に韓国はディープフェイクポルノの所持と視聴を犯罪化、EUのAI法は合成コンテンツの透明性を義務付けました。
- 米国では2025年施行のTake It Down法により、AI生成の非同意の「親密」(通常、ヌードと解釈される)画像の公開が犯罪とされました。
重要性:他の画像生成器も同様の用途に使えますが、XとGrok(共にイーロン・マスク所有)の密接な関係はディープフェイク規制に新たな局面をもたらします。従来は規制当局がSNSを利用者投稿の違法素材の責任から免除してきましたが、Grokが生成した画像を直接Xが公開したことで、SNS自体が注目されています。非同意の「脱衣」画像(ヌードとは異なる)の法的地位はまだ確定していませんが、欧州委員会はXの年間収益の6%に相当する罰金を課す可能性があります。これは画像生成を行うAI企業にとって警告となります。
考え:同意なく誰かの衣服をデジタルで剥ぐのは恥辱と虐待です。誰もこのような扱いを受けるべきではありません。Grok以外にもGoogleやOpenAIなどの生成器やPhotoshopもこの目的に使われ得ますが、後者は手間がかかります。私たちは、識別可能な人物の非同意の性的画像作成を禁止する規制を支持します。

AIの大手企業が医療市場で競争
OpenAIとAnthropicはそれぞれ異なるターゲットで医療市場に参入し、強みを活かしています。
新情報:OpenAIはChatGPT Healthを発表しました。これはユーザーの医療情報を取得できる消費者向けチャットボットで、データセキュリティとプライバシーも強化されています。数日後、AnthropicはClaude for Healthcareを公開し、主に医療関係者向けに医療データベース検索や書類作成を支援します。
ChatGPT Health:OpenAIの製品は更新されたOpenAI for Healthcare APIを基盤とした健康・ウェルネスチャットボットです。医療検査結果、医師の指示、ウェアラブル機器のデータを含む自己の医療情報を理解するのに役立ちます。OpenAIは世界60か国の260人の医師のフィードバックをもとに2年間かけて開発しました。
- アーキテクチャ:ChatGPT HealthはChatGPT内のサンドボックスで、独自の記憶、接続アプリ、ファイル、会話を持ちます。サンドボックス外のChatGPT会話データは利用できますが逆は不可。使用モデルや医療特化のファインチューニング、システムプロンプトは非公開です。
- 機能:検査結果解説、医師への質問準備、ウェアラブルデバイスデータ解釈、治療指示の要約が可能。医療情報をシステムに共有し文脈として保持できます。Apple HealthやFunction、MyFitnessPalなどの健康・ウェルネスデータも同様に連携可能です。
- プライバシー:データは隔離・特別暗号化され、OpenAIのパートナーb.wellが医療機関から安全に個人データを取得します。医療会話はモデル訓練に使用されません。
- 利用可能地域:EU、スイス、英国以外の有料・無料ユーザーに待機リスト経由で提供中。数週間以内にすべてのデスクトップとiOSユーザーに展開予定です。
Claude for Healthcare:Anthropicの製品は医療提供者向けで、Claudeプラットフォームの二要素を使います。コネクターは医療データベースにアクセスし、エージェントスキルは特定作業を支援(医療データ共有・医療文書作成)。一部ユーザーは医療情報の接続機能を試験中です。
- データアクセス:CMS Coverage Database(米公的医療請求管理)、ICD-10(診断・手技コード)、National Provider Identifier Registry(医療提供者確認)に接続可能。HealthExとFunction規格で患者の検査結果と健康記録を閲覧可能。Apple HealthとAndroid Health Connectにも対応。
- 機能:FHIR開発と事前承認スキルで書類作業が効率化されます。FHIRは医療記録電子交信の仕様。事前承認は保険会社による一部処方と処置の承認手続き。医療従事者はこれらで処方承認迅速化、保険請求否認の再審査、患者メッセージの読み書き、事務負担軽減が可能です。
- プライバシー:新スキルとコネクターは米国の医療プライバシーとデータ保護法HIPAAに準拠します。
- 利用可能地域:医療従事者向けのコネクターとスキルはすべてのClaude加入者に提供。患者情報接続は米国内の有料加入者に限定。
背景:多くの企業が医師や検査技師向けAIシステムを投入しており、医師向け音声アシスタントや癌検出のための視覚モデルもありますが、消費者向けは課題もあります。Googleは最近誤った健康情報を含むAI要約を撤回しました。米国の一部州は医療助言チャットボットの規制も試みています。
重要性:医療はAIの大きな市場です。先進国では医療がGDPの10%以上を占め、多くの国で医療スタッフ不足、高齢化、事務手続きの複雑さに直面しています。米国の医療産業は1700万人を雇用し、年間約5兆ドルの支出(うち1兆ドルは事務コスト)があります。OpenAIが患者向け、Anthropicが医療専門家向けに注力するのは、それぞれの消費者市場と企業市場での強みを反映しています。
考え:欧州の一般データ保護規則(GDPR)は医療機関が患者データを第三者と共有する方法を厳しく制限しており、両社がまだ本格的な対応をしていません。GDPRはある程度プライバシーを保護しますが、EU市民がAI革命にアクセスする速度を遅らせている側面もあります。

Metaがエージェント技術の買収を進める
話題の買収により、Facebook、Instagram、WhatsAppがユーザーの依頼に応じる組み込みエージェントを提供できる可能性が高まります。
新情報:MetaはシンガポールのスタートアップManus AIを20〜30億ドルで買収する契約を結びました。The Wall Street Journalが報じており、現在は政府の承認待ちです。
仕組み:Manusのエージェントは同名で、コンピューター操作、深層調査、バイブコーディングなど複数の自律機能を組み合わせています。Metaは年間1億2500万ドルの収益を生むManusの既存顧客へのサービスは続けますが、多くのエンジニアと経営陣をMetaに移し技術統合を進める予定です。統合計画の詳細は発表されていません。
- MetaはManusエージェントをコンシューマー・企業向けのSNSプラットフォームに統合し、Meta AIのチャットボット/アシスタントに組み込みます。
- ManusのCEO、シャオ・ホンはMetaの最高執行責任者ハビエル・オリバンに直属します。
背景:Manusの製品は2025年3月にデビューし、Anthropic Claude、Alibaba Qwenなどを使ったコンピューター操作エージェントでした。
- ウェブアプリ制作、航空券購入、株取引分析などが可能で、2百万人以上が待機リストに登録しました。
- 親会社のButterfly Effectは2022年に中国で設立されましたが、2024年に中国国内で使えないモデルを利用するためシンガポールに移転しました。そのためManusのエージェントは中国国内では利用できません。
- 2025年12月にはモバイルアプリ開発とビジュアルUI設計が可能なManus 1.6をリリースしました。
ただし:買収は中国当局の承認待ちであり、中国は創業者が中国籍であることから貿易や国家安全保障に関する規制違反かどうかを調査中です(Financial Times報道)。
重要性:AIエージェントは生成モデルから行動モデルへの競争の最前線です。Manus買収によりMetaは市場に出ている技術をすぐに取り込み、Google、Microsoft、OpenAIが消費者向けエージェントサービスを開始し、Amazonは買い物代行機能を提供している中での迅速な対応です。AmazonはPerplexityのエージェント的ブラウザCometによる自動購入を阻止する訴訟も起こしました。Metaは昨年の大規模採用後もトップクラスのAI人材を求め続けています(記事)。
私たちの考え:幅広いタスクを実行する一般目的エージェントは既に存在し、Google、OpenAI、Perplexityのブラウザ組み込み型、Amazonの特定プラットフォーム向け購入支援型などがあります。ManusがMetaに加わることで、SNSに一般目的エージェントが組み込まれ、主に人間が主体だったこれまでのSNSとは大きく異なるユーザー間交流が生まれる可能性があります。
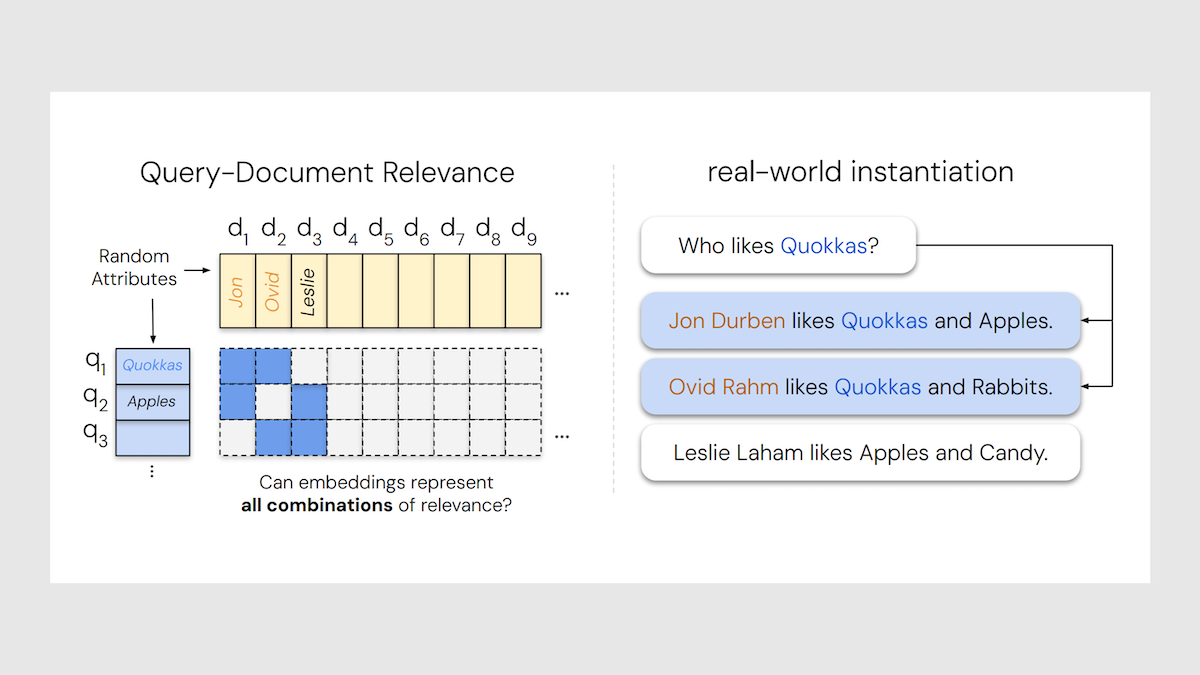
情報検索は厳しい限界に直面
あなたの検索システムは、ユーザーが入力するどんなクエリでも関連するすべての文書を見つけられるでしょうか?研究は必ずしもそうではないことを示しています。
新発見:Googleとジョンズホプキンス大学のOrion Weller、Michael Boratko、Iftekhar Naim、Jinhyuk Leeらの研究チームが検索モデルの埋め込み表現における限界のクリティカルな文書数を特定しました。
検索モデルの基本:ある検索モデルはキーワード比較で文書を探し、他はクエリと文書の埋め込み(ベクトル表現)を比較します。本稿対象の検索器は通常、対照学習でクエリと関連文書の埋め込みが近く、無関係文書の埋め込みが遠くなるよう学習します。得た埋め込みモデルで文書埋め込みのベクトルストアを作成し、推論時にクエリの埋め込みと比較して最も類似度の高い文書を返します。ほとんどはクエリ・文書ともに単一の埋め込みを生成し、まれに複数埋め込みのモデルもあります。
主な洞察:理想的には単一埋め込み検索器はデータベース内のあらゆる文書集合を返せるはずです(例えば「XとYに関する文書だがZは含まない」を実現する)。しかし実際には、文書数が増えると、文書の一部ペアが埋め込み空間であまりに離れてしまい、1つのクエリ埋め込みが両方に最も近い近傍になることはありません。つまり、より大きく多様な関連集合を扱うほど、検索器が最適に関連文書を特定できる埋め込みサイズは大きくしなければならず、埋め込みサイズで検索可能な組み合わせ数には根本的な限界があります。
実験:著者らは文書ペアを表せる最大数を測定するため2つの実験を行いました。(i) ベストケース実験では埋め込みモデルを使わず学習可能なベクトルでクエリと文書埋め込みを表し、ペアの検索可能性を最適化しました。(ii) シンプルな文書・クエリ集合を作り既存の検索器の性能を調査しました。
- ベストケースで埋め込みサイズdを変え(46未満まで試行)、ランダム初期化の学習可能文書埋め込みセットを作成。文書ペアごとに対応するクエリ埋め込みもランダム初期化し、それらを勾配降下で調整し検索成功を評価。文書数を増やすと上限があり、それを超えると最適化してもペア検索は不可能になりました。
- 自然言語と検索器を用いた2番目の実験では5万文書・1000クエリ(各クエリ2件関連文書)を作成。各文書は「ジョンはリンゴとクオッカが好き」など人と好みを記述。クエリは「誰がXが好き?」と尋ねます。46文書が関連集合で、そのペア組合せは1000を超えています。残りは無関係文書。言語は極めて単純で否定や曖昧性、長い文脈はありませんが、すべての文書ペアが正解という難しい課題です。
結果:実験で示され、いかなるモデルもすべての文書ペアを検索できるクエリと文書の埋め込みを作れないことが判明しました。
- ベストケースでは、2文書組合せの数は埋め込みサイズdの3次関数的に増加しました。著者らは3次多項式でフィッティング(r2=0.999)し大規模dへ外挿推定。d=512で検索可能ペアは50万文書で頭打ち。d=768で170万、d=1024で約400万、d=3072で1億700万、d=4096で2億5000万に拡大しました。
- 2番目の実験では、単一埋め込みの既存検索モデルは総じて苦戦。埋め込みサイズ4096のPromptriever Llama3(80億パラ)は100件検索で再現率19%、GritLM(70億パラ)は16%、Gemini Embeddings(パラ数非公開)は約10%にとどまりました。一方、キーワードベースの伝統的検索器BM25は90%近い再現率を、複数埋め込みで表現するModernColBERTは65%を達成しました。
重要性:単一埋め込み検索器の理論的限界を理解することは、実際の性能期待値や適切な埋め込みサイズを決めるのに役立ちます。特にエージェント的検索システムが成長する中で重要になります。
考え:単一埋め込み検索器がすべてのクエリ文書組合せを表現できないのは事実ですが、問題ではありません。実際にはユーザーは関連する情報を求めるので、日常の検索はこの限界のはるか下で動きます。複雑なクエリの場合は、エージェントが反復的に追加文書の検索を判断するエージェント的検索が有望な代替となります。
