コーディングエージェントの構成要素
コーディングエージェントがツール、メモリ、リポジトリの文脈をどう活用して、実運用でLLMをより良く機能させるか
この記事では、コーディングエージェントおよびエージェントハーネスの全体的な設計について、つまりそれらが何であるのか、どのように動くのか、そして実際にはどのようにさまざまな要素が組み合わさるのかを取り上げたいと思います。私の Build a Large Language Model (From Scratch) と Build a Large Reasoning Model (From Scratch) の本を読んだ方は、しばしばエージェントについて質問します。そこで、参照としてこちらを指し示せるような記事を書くのは有用だと考えました。
より一般的には、エージェントは重要なトピックになっています。というのも、最近の実用的なLLMシステムにおける進歩の多くは、単により良いモデルを得ることだけではなく、それらをどう使うかに関するものだからです。現実の多くのアプリケーションでは、ツールの利用、コンテキスト管理、メモリなど、モデルの周辺にあるシステムが、モデルそのものと同じくらい重要な役割を果たします。これはまた、Claude CodeやCodexのようなシステムが、チャットインターフェースだけで使われる同じモデルよりも、かなり能力が高いように感じられる理由も説明できます。
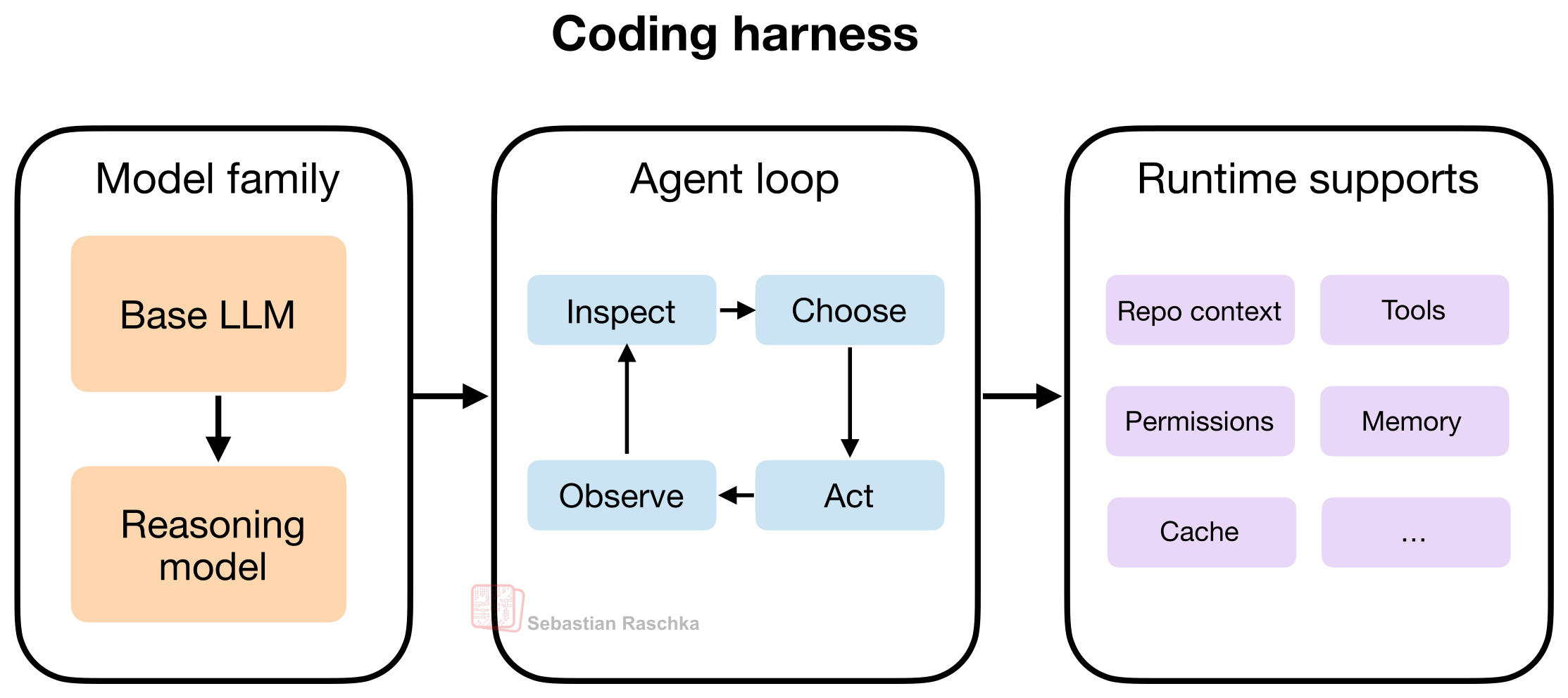
この記事では、コーディングエージェントの主要な構成要素を6つ示します。
Claude Code、Codex CLI、その他のコーディングエージェント
おそらくあなたはClaude CodeやCodex CLIには馴染みがあるでしょう。しかし、話の導入として言うと、それらは本質的に、LLMをアプリケーション層で包む「エージェント的なコーディングツール」であり、コーディングタスクに対してより便利で、より良い性能を発揮するための、いわゆるエージェントハーネスです。
コーディングエージェントは、モデルの選択だけでなく、リポジトリのコンテキスト、ツールの設計、プロンプトキャッシュの安定性、メモリ、長時間セッションの継続性など、周辺のシステム全体が重要になるソフトウェア作業向けに設計されています。
この違いは重要です。というのも、LLMのコーディング能力について話すとき、人々がしばしばモデル、推論のふるまい、エージェント製品を1つのものにまとめてしまうからです。しかし、コーディング・エージェントの具体に入る前に、まずはより広い概念であるLLM、推論モデル、エージェントの違いについて、少しだけ追加の背景を簡単に説明します。
LLM、推論モデル、エージェントの関係について
LLMはコアとなる次トークンモデルです。推論モデルも依然としてLLMですが、通常は、中間的な推論、検証、あるいは候補回答に対する探索に、推論時の計算(inference-time compute)をより多く使うように学習され、またはプロンプト設計されているものです。
エージェントはその上に重ねられる層であり、「モデルの周りに置かれた制御ループ」として理解できます。一般に、目標が与えられると、エージェント層(またはハーネス)は、次に何を調べるか、どのツールを呼び出すか、状態をどう更新するか、いつ停止するかなどを決定します。
ざっくり言うと、関係は次のように考えることができます。LLMはエンジン、推論モデルは強化されたエンジン(より強力だが、使用にはよりコストがかかる)であり、エージェント・ハーネスがそのモデルを助けます。たとえとしては完全ではありません。というのも、従来型の推論LLMや推論用LLMをスタンドアロンのモデルとして(チャットUIやPythonセッションで)使うこともできるからです。ただ、それでも主要なポイントは伝わると期待しています。

つまり言い換えると、エージェントは、環境の中でモデルを繰り返し呼び出すシステムです。
それでは、短くまとめると次のようになります:
LLM:生のモデル
推論モデル: 中間的な推論の痕跡を出力するよう最適化され、また自分自身をより強く検証するよう最適化されたLLM
エージェント:モデルに加えてツール、メモリ、環境からのフィードバックを使うループ
エージェント・ハーネス:文脈、ツール利用、プロンプト、状態、制御フローを管理する、エージェントの周囲のソフトウェアの足場(スキャフォールド)
コーディング・ハーネス:エージェント・ハーネスの特別なケース。つまり、コードの文脈、ツール、実行、反復的なフィードバックを管理する、ソフトウェアエンジニアリング向けのタスク専用ハーネス
上で列挙したとおり、エージェントやコーディング・ツールの文脈では、agent harness と(agentic)coding harness の2つのよく知られた用語もあります。コーディング・ハーネスとは、モデルの周囲にあるソフトウェアの足場であり、モデルがコードを効果的に書いたり編集したりできるようにします。そしてエージェント・ハーネスはもう少し広く、コーディングに特化していません(たとえば OpenClaw のようなものを想像してください)。Codex や Claude Code はコーディング・ハーネスだと考えられます。
とにかく、より良いLLMは、追加の学習を含む推論モデルのためのより良い基盤を提供し、そしてハーネスはその推論モデルからより多くを引き出します。
もちろん、LLMや推論モデルは、ハーネスなしでも自分自身でコーディング課題を解くことはできますが、コーディング作業は次トークン生成だけの話ではありません。多くの部分は、リポジトリのナビゲーション、検索、関数の参照、差分の適用、テストの実行、エラーの観察、そして関連するすべての情報を文脈の中に保ち続けることにあります。(コーダーなら、これは大変な頭の作業なので、コーディングセッション中に邪魔されたくない、ということはご存じかもしれません :))。
ここでの要点は、優れたコーディング用ハーネスなら、推論を行うモデル/行わないモデルのどちらでも、単なるチャットボックスよりもはるかに強い印象にできます。これは、文脈(コンテキスト)の管理や、それ以上の部分で役立つからです。
コーディング・ハーネス
先ほどのセクションで述べたように、 ハーネスと言うとき、私たちが通常意味するのは、プロンプトを組み立て、ツールを公開し、ファイルの状態を追跡し、編集を適用し、コマンドを実行し、権限を管理し、安定したプレフィックスをキャッシュし、メモリを保存し、そしてその他多くのことを行う、モデルの周囲にあるソフトウェア層です。
今日LLMを使うとき、この層は、モデルに直接プロンプトを渡す場合や Web のチャットUIを使う場合(「アップロードしたファイルとチャットする」ことに近い)と比べて、ほとんどのユーザー体験を形作っています。
私の見立てでは、現在のLLMの素のバージョンは、非常に似た能力を持っています(例:GPT-5.4、Opus 4.6、GLM-5 などの素のバージョン)。そのため、あるLLMが別のLLMよりもうまく機能するかどうかを分けるのは、多くの場合ハーネスです。
これは推測ですが、GLM-5のような最新で高性能なオープンウェイトLLMの1つを、同様のハーネスに投入すれば、CodexにおけるGPT-5.4や、Claude CodeにおけるClaude Opus 4.6と、同等の性能を発揮できる可能性が高いと考えています。とはいえ、ハーネス固有の追加の事前学習(ポストトレーニング)は通常有益です。たとえばOpenAIは歴史的に、別々の GPT-5.3 と GPT-5.3-Codex のバリアントを維持してきました。
次のセクションでは具体的な点をさらに掘り下げ、私の Mini Coding Agentを使って、コーディング用ハーネスの中核となるコンポーネントについて議論したいと思います:https://github.com/rasbt/mini-coding-agent。

ちなみにこの記事では、簡単にするために「coding agent」と「coding harness」という用語を、やや互換的に使っています。(厳密に言うと、エージェントはモデル駆動の意思決定ループであり、ハーネスは文脈、ツール、実行のためのサポートを提供する周辺のソフトウェアの土台です。)
とにかく、以下にコーディングエージェントの主要な6つのコンポーネントを示します。より具体的なコード例については、私の「最小限だが完全に動作する、スクラッチからの 」Mini Coding Agent(純粋なPythonで実装)のソースコードを参照してください。このコードでは、下で議論する6つのコンポーネントをコードコメントで注釈しています:
##############################
#### Six Agent Components ####
##############################
# 1) Live Repo Context -> WorkspaceContext
# 2) Prompt Shape And Cache Reuse -> build_prefix, memory_text, prompt
# 3) Structured Tools, Validation, And Permissions -> build_tools, run_tool, validate_tool, approve, parse, path, tool_*
# 4) Context Reduction And Output Management -> clip, history_text
# 5) Transcripts, Memory, And Resumption -> SessionStore, record, note_tool, ask, reset
# 6) Delegation And Bounded Subagents -> tool_delegate1. ライブリポジトリコンテキスト
これはおそらく最も分かりやすいコンポーネントですが、同時に最も重要なものの1つでもあります。
ユーザーが「テストを直して」や「xyzを実装して」と言うとき、モデルはそれがGitリポジトリの中なのか、どのブランチにいるのか、どのプロジェクトのドキュメントに指示が含まれている可能性があるのか、などを把握しているべきです。
なぜなら、そうした詳細はしばしば変化したり、正しいアクションに影響したりするからです。たとえば「テストを直して」は、自己完結した指示ではありません。エージェントがAGENTS.mdやプロジェクトのREADMEを見つければ、どのテストコマンドを実行すべきかなどを学べるかもしれません。リポジトリのルートや構造が分かっていれば、当て推量ではなく適切な場所を調べられます。
また、Gitのブランチ、状態、コミットは、現在どの変更が進行中で、どこに注力すべきかを示す文脈の手がかりにもなります。
要点は、コーディングエージェントが作業を始める前に情報(ワークスペース要約としての「安定した事実」)を前もって収集することで、毎回のプロンプトで文脈なし・ゼロからスタートすることを避ける、という点です。
2. プロンプトの形とキャッシュ再利用
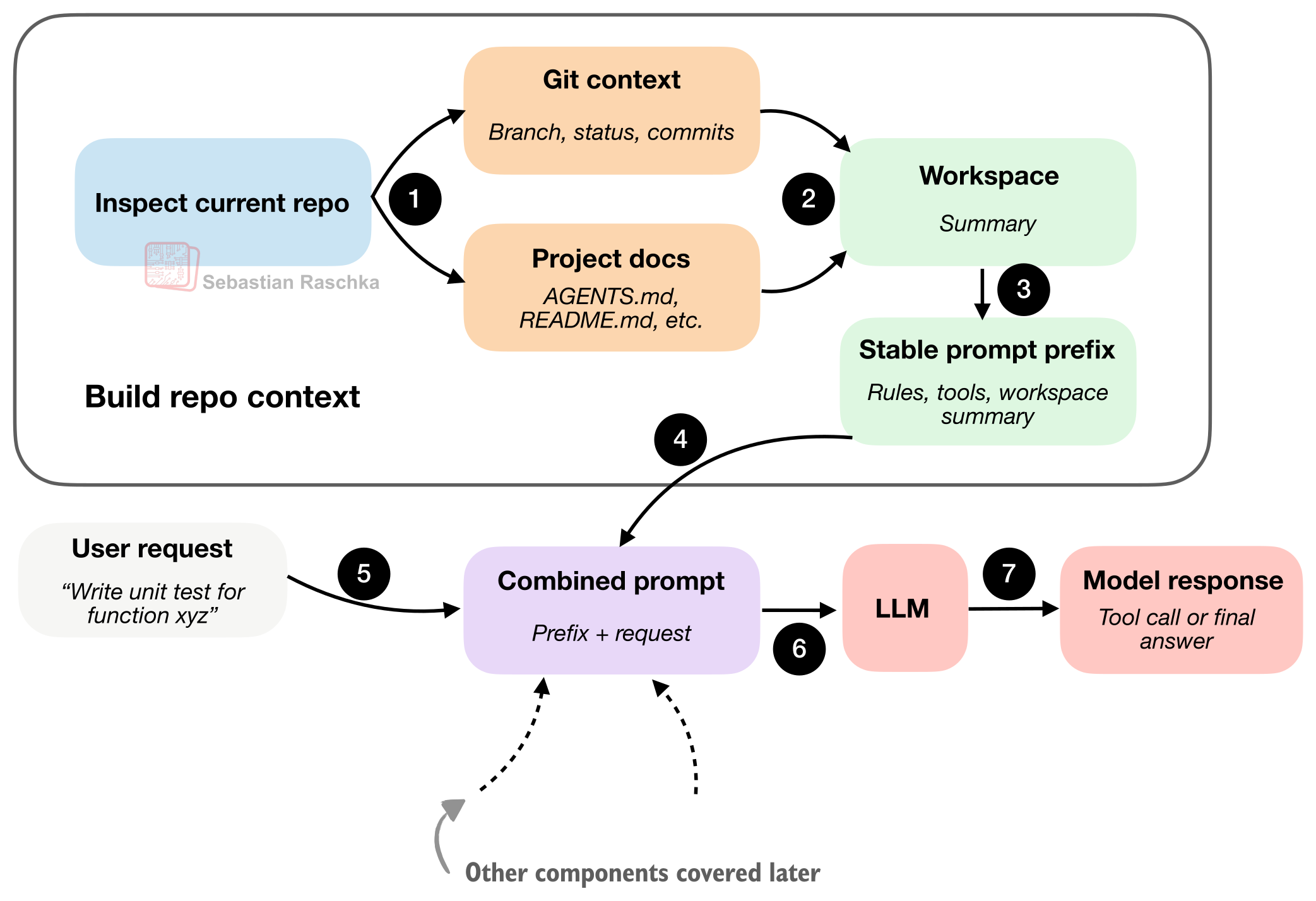
エージェントがリポジトリのビューを得たら、次の問題は、その情報をモデルにどう渡すかです。前の図はこれを簡略化して示していました(「結合プロンプト:プレフィックス+依頼」)が、実際には、ユーザーの問い合わせごとに作業スペース要約を結合して再処理するのは比較的無駄が大きいでしょう。
つまり、コーディングセッションは反復的であり、エージェントのルールは通常同じままです。ツールの説明も通常同じままです。そして、作業スペース要約もたいてい(ほぼ)同じままです。主な変更点は通常、最新のユーザー依頼、最近のトランスクリプト、そしておそらく短期メモリです。
「スマート」なランタイムは、下の図で示すように、毎ターン、巨大で区別のない1つのプロンプトとしてすべてを作り直したりはしません。
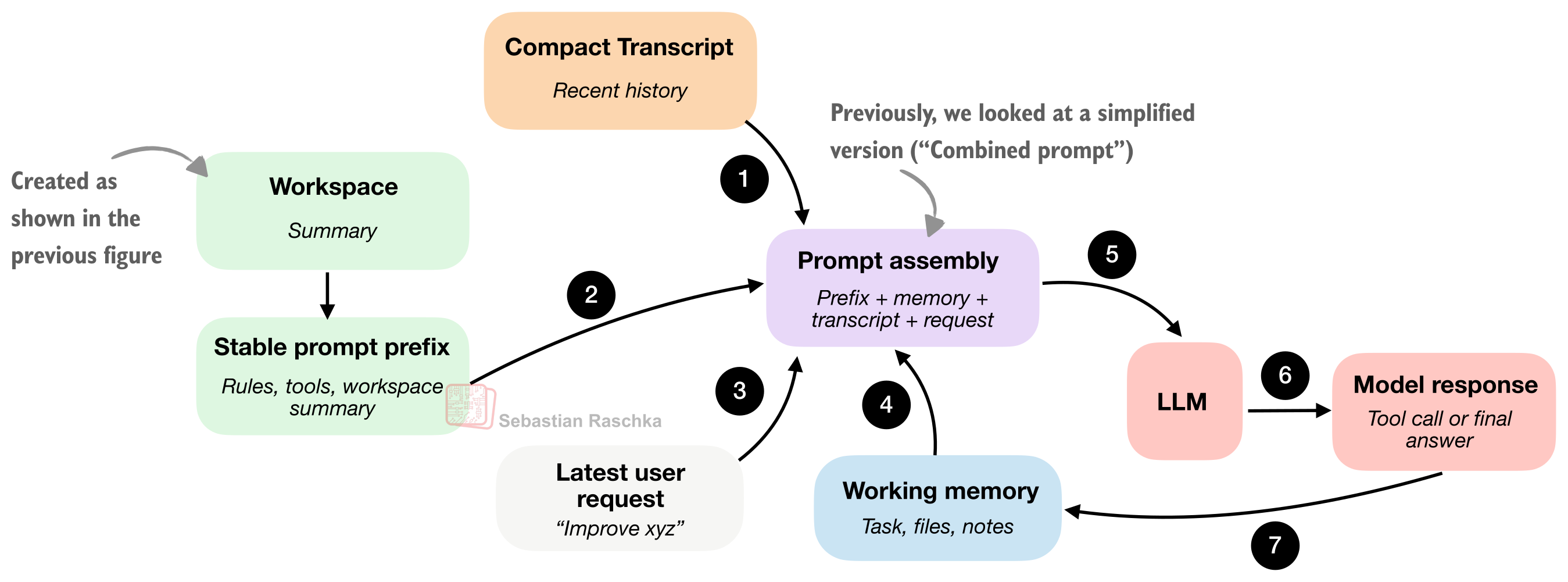
セクション1との差は主に、セクション1がリポジトリの事実を集めることについてだった点です。ここでは、反復するモデル呼び出しのために、それらの事実を効率的にパッケージ化し、キャッシュすることに関心があります。
「安定」な「安定したプロンプトのプレフィックス」とは、そこに含まれる情報があまり変わらないという意味です。通常、それには一般的な指示、ツールの説明、そしてワークスペースの要約が含まれます。重要な変更がなければ、各やり取りのたびにゼロから作り直すために計算量を無駄にしたくありません。
他の構成要素はより頻繁に更新されます(通常は各ターンごと)。これには短期記憶、直近のトランスクリプト、そして最新のユーザー要求が含まれます。
要するに、「安定したプロンプトのプレフィックス」に関するキャッシュの考え方は、賢い実行時(ランタイム)がその部分を再利用しようとする、ということです。
3. ツールへのアクセスと使用
ツールへのアクセスとツールの使用は、チャットというよりエージェントのように感じられるところから始まります。
単純なモデルでも文章の中でコマンドを提案できますが、コード用のハーネス内にあるLLMは、より狭くて有用なことを行い、実際にそのコマンドを実行して結果を取得できるべきです(つまり、こちらが手動でコマンドを呼び出して結果をチャットに貼り付けるのではなく、ハーネスがそれを行う、ということです)。
しかし、モデルに恣意的な構文を即興で作らせるのではなく、通常ハーネスは、許可された名前付きツールの事前定義リストを用意し、入力も明確で境界も明確にします。(もちろん、Python subprocess.call のようなものがこの仕組みに含まれていて、エージェントが任意に幅広いリストのシェルコマンドを実行できるようにすることもありえます。)
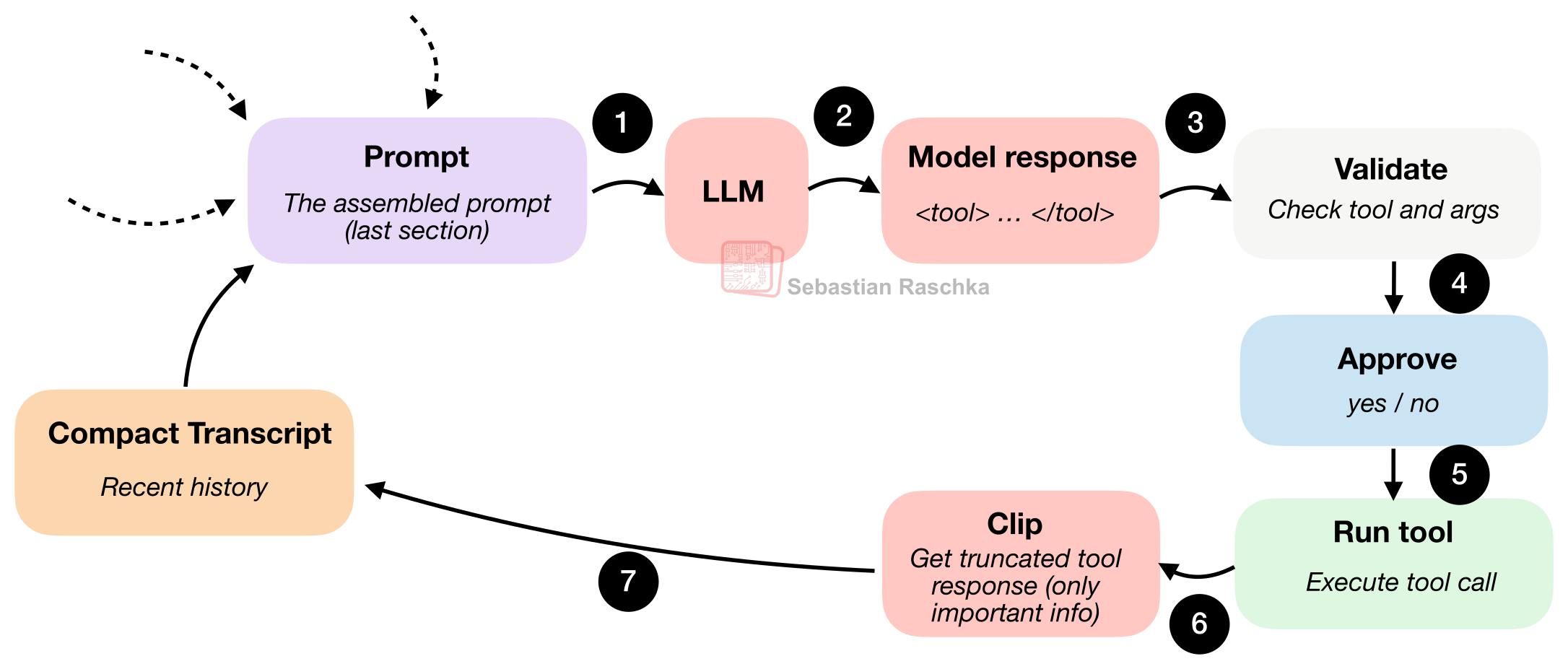
ツールの利用フローは、下の図に示します。
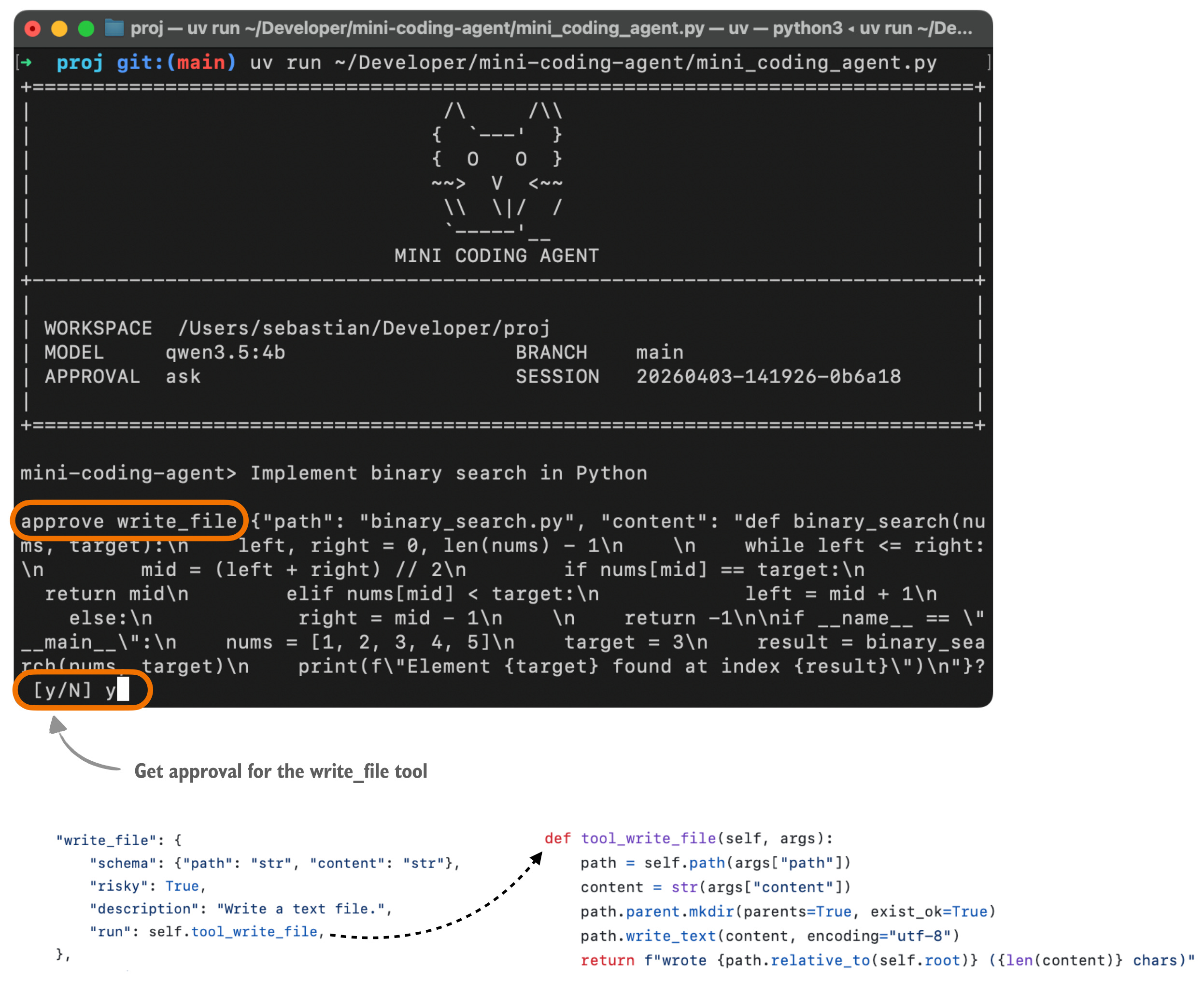
これを説明するために、以下に私のMini Coding Agentを使ったときに、通常ユーザーにどう見えるかの例を示します。(Claude CodeやCodexほど見栄えはよくありません。非常にシンプルで、外部依存のないプレーンなPythonを使っているためです。)
ここでは、モデルは、ハーネスが認識できるアクションを選択する必要があります。たとえばファイル一覧の取得、ファイルの読み取り、検索、シェルコマンドの実行、ファイルへの書き込みなどです。また、ハーネスが検証できる形で引数を提示する必要もあります。
そのため、モデルが何かを実行しようと要求したとき、ランタイムは停止して、次のようなプログラムによるチェックを実行できます。
「これは既知のツールですか?」
「引数は有効ですか?」
「ユーザーの承認が必要ですか?」
「要求されたパスは、そもそもワークスペース内ですか?」
これらのチェックにすべて通った後でなければ、実際の実行は行われません。
コーディングエージェントの実行にはもちろん一定のリスクがありますが、ハーネスのチェックが信頼性も高めます。なぜなら、モデルが完全に恣意的なコマンドを実行しないようにできるからです。
また、不正な形式のアクションを拒否したり、承認ゲーティングを設けたりすることに加えて、ファイルパスをチェックすることで、ファイルアクセスをリポジトリ内に制限できます。
ある意味では、ハーネスはモデルに与える自由度を減らしているわけですが、その一方で同時に使い勝手も向上させています。
4. コンテキストの肥大を最小化する
コンテキストの肥大は、コーディングエージェントに固有の問題というわけではなく、一般にLLMにとっての課題です。もちろん最近のLLMは、より長いコンテキストを扱えるようになっています(そして私は最近、計算可能性を高める attention variants について書きました)。しかし、長いコンテキストは依然としてコストが高く、またノイズを増やす原因にもなりえます(無関係な情報が大量にある場合です)。

コーディング・エージェントは、多回(マルチターン)のチャット中に、通常のLLMよりもコンテキストの肥大化(context bloat)に対してさらに影響を受けやすくなります。理由は、ファイルの読み取りが繰り返されること、長いツール出力、ログなどがあるためです。
実行時にそれらをすべて高い忠実度のまま保持し続けると、利用可能なコンテキスト・トークンがかなり早い段階で尽きてしまいます。したがって、優れたコーディング用ハーネスは、通常のチャットUIが要約情報を単に切り詰めるだけで済ませる以上の形で、コンテキストの肥大化に対処する点で、たいていかなり洗練されています。
概念的には、コーディング・エージェントにおけるコンテキスト圧縮(context compaction)は、下の図に要約されているように機能するかもしれません。具体的には、前のセクションの図8における(ステップ6)の部分を、さらに少しズームしています。
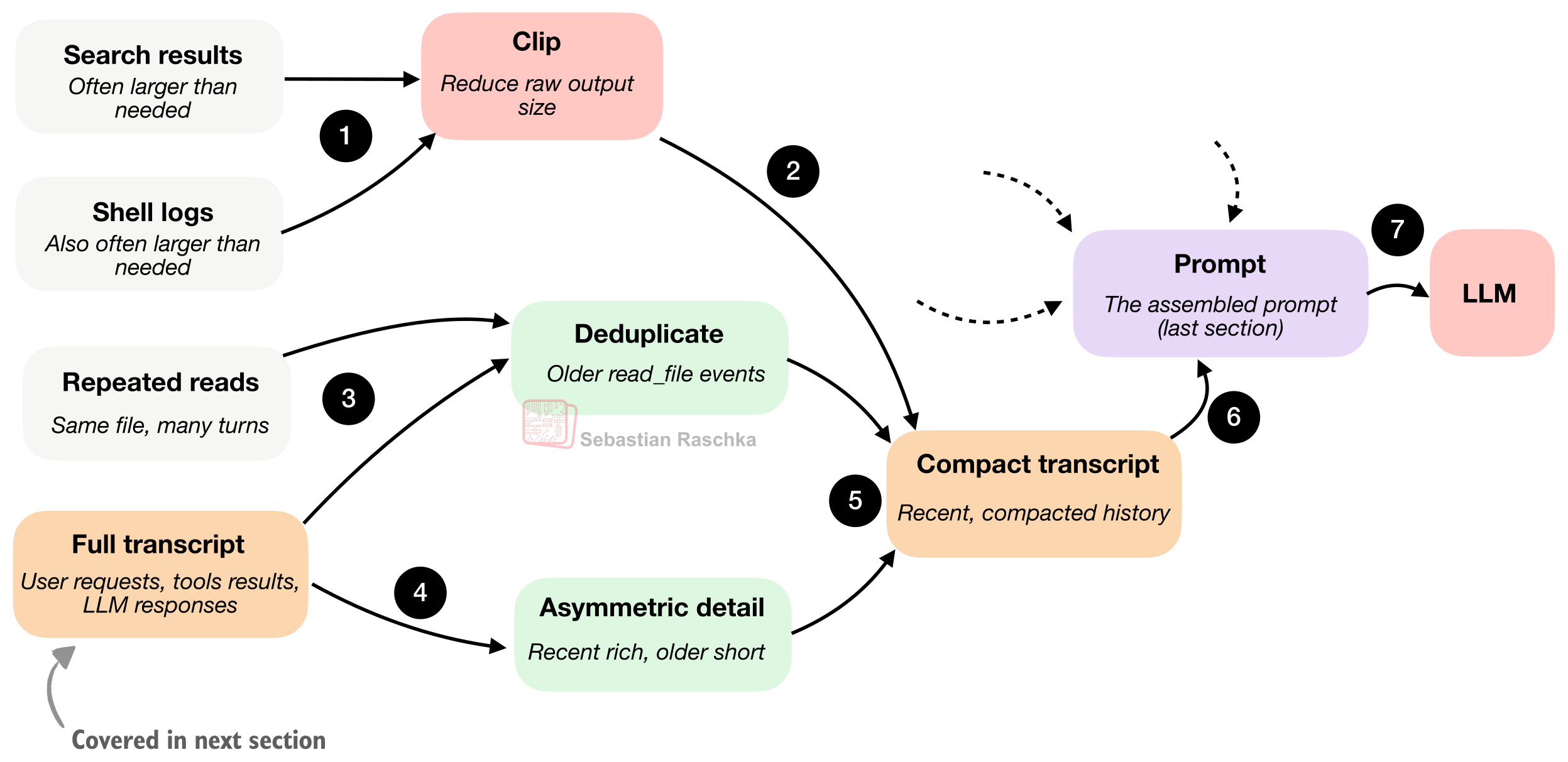
最小限のハーネスは、この問題を管理するために少なくとも2つの圧縮戦略を使います。
1つ目はクリッピングで、長いドキュメント抜粋、大きなツール出力、メモリノート、トランスクリプトの記録を短くします。つまり、冗長だったというだけで、どれか1つのテキストがプロンプトの予算を占有してしまうのを防ぎます。
2つ目の戦略はトランスクリプトの削減、または要約で、セッション履歴の全体(次のセクションで詳しく説明します)を、より小さな「プロンプト可能な要約」に変換します。
ここでの重要なコツは、最近の出来事はより豊富に保つことです。というのも、それが現在のステップにおいて重要である可能性が高いからです。そして、古い出来事は関連性が低い可能性が高いため、より積極的に圧縮します。
さらに、モデルが同じファイル内容を、セッションの途中で複数回読んだだけの理由で何度も繰り返し見続けないように、古いファイル読み取りを重複排除することも行います。
全体として、私は、優れたコーディングエージェント設計の中でも、このような「過小評価されがちで、退屈な」部分があると思っています。見かけ上の「モデル品質」の多くは、実際には文脈の品質です。
5. 構造化されたセッションメモリ
実際には、ここで扱った6つのコア概念はすべて強く絡み合っており、各セクションや図は、それぞれ異なる焦点やズームレベルでそれらをカバーしています。前のセクションでは、履歴をプロンプト投入時にどう使うか、そしてコンパクトなトランスクリプトをどう構築するかを説明しました。そこでの問いは、「次のターンに、過去のどれくらいをモデルに戻すべきか」です。したがって強調点は、圧縮、クリッピング、重複排除、そして鮮度(recency)になります。
ここからのこのセクション(構造化されたセッションメモリ)は、履歴を保存する際の構造、つまり保管時の構造に関するものです。ここでの問いは、「エージェントは、永続的な記録として、時間の経過とともに何を保持するのか」です。つまり、実行時(runtime)では、より軽いメモリ層に加えて、耐久性のある状態として、より完全なトランスクリプトを保持するという点を強調しています。その軽いメモリ層は、小さく保たれ、単に追記するのではなく、更新され、コンパクトにされていきます。
まとめると、コーディングエージェントは状態を(少なくとも)2つの層に分離します。
ワーキングメモリ:エージェントが明示的に保持する、小さく蒸留された状態
完全なトランスクリプト:ユーザーからのすべての要求、ツール出力、そしてLLMの応答をカバーするもの
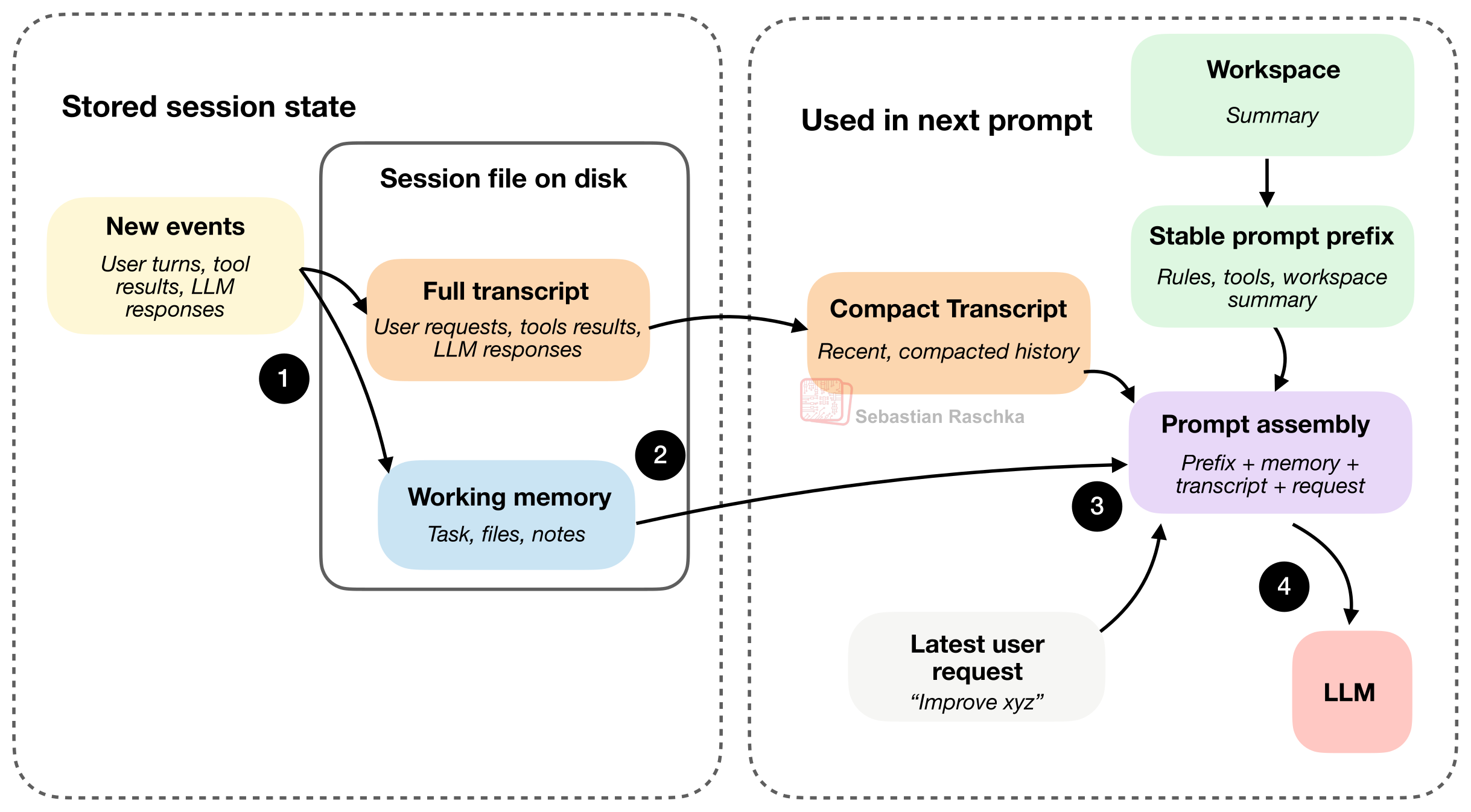
上の図は、ディスク上のJSONファイルとして通常保存される2つの主要なセッションファイル、完全なトランスクリプトと作業メモリを示している。前述のとおり、完全なトランスクリプトは全履歴を保存し、エージェントを閉じても(途中で中断しても)再開可能である。作業メモリは、現在最も重要な情報だけに絞り込んだ、いわば蒸留版で、コンパクトなトランスクリプトともある程度関連している。
しかし、コンパクトなトランスクリプトと作業メモリは、果たす役割が少し異なる。コンパクトなトランスクリプトは、プロンプト再構築のためのものだ。その役割は、モデルに「最近の履歴の圧縮された見え方」を与えて、毎ターンごとに完全なトランスクリプトを参照しなくても会話を継続できるようにすることである。作業メモリは、よりタスクの継続性のために設計されている。その役割は、ターンをまたいで重要なものに関する小さく、明示的に管理された要約を維持することだ。たとえば現在のタスク、重要なファイル、そして最近のメモなどである。
図のステップ4に続いて、最新のユーザー要求は、LLMの応答とツール出力とともに、「新しい出来事」として完全なトランスクリプトと作業メモリの両方に記録される。次のラウンドでは、そのような追加によって上の図がごちゃごちゃしないようにするため、図中にはそれは表示していない。
6.(上限付き)サブエージェントによる委任
エージェントにツールと状態(ステート)が備わったら、次に役立つ機能の1つが委任である。
その理由は、サブエージェントを使って特定の作業をサブタスクとして並列化し、メインのタスクを高速化できるからだ。たとえば、メインのエージェントはあるタスクの途中にいても、なおサイドの答えが必要になることがある。たとえば、どのファイルがシンボルを定義しているのか、設定(config)は何を言っているのか、あるいはなぜテストが失敗しているのか、といった情報である。それらを、1つのループにあらゆる作業の糸を一度に背負わせるのではなく、上限付きのサブタスクとして切り離すのが有用だ。
(私のミニ・コーディング・エージェントでは実装はより単純で、子エージェントは同期的に動くが、根本の考え方は同じである。)
サブエージェントが実際の作業を行うのに十分な文脈(コンテキスト)を継承できる場合に限り有用だ。だが、制限しなければ、複数のエージェントが同じ作業を重複して行ったり、同じファイルに触れたり、さらにサブエージェントを増やしたりしてしまい、問題が起きる。
つまり難しい設計課題は、単にサブエージェントを生成する方法だけではなく、それをどう「束ねる(バインドする)」か、にもある。:)
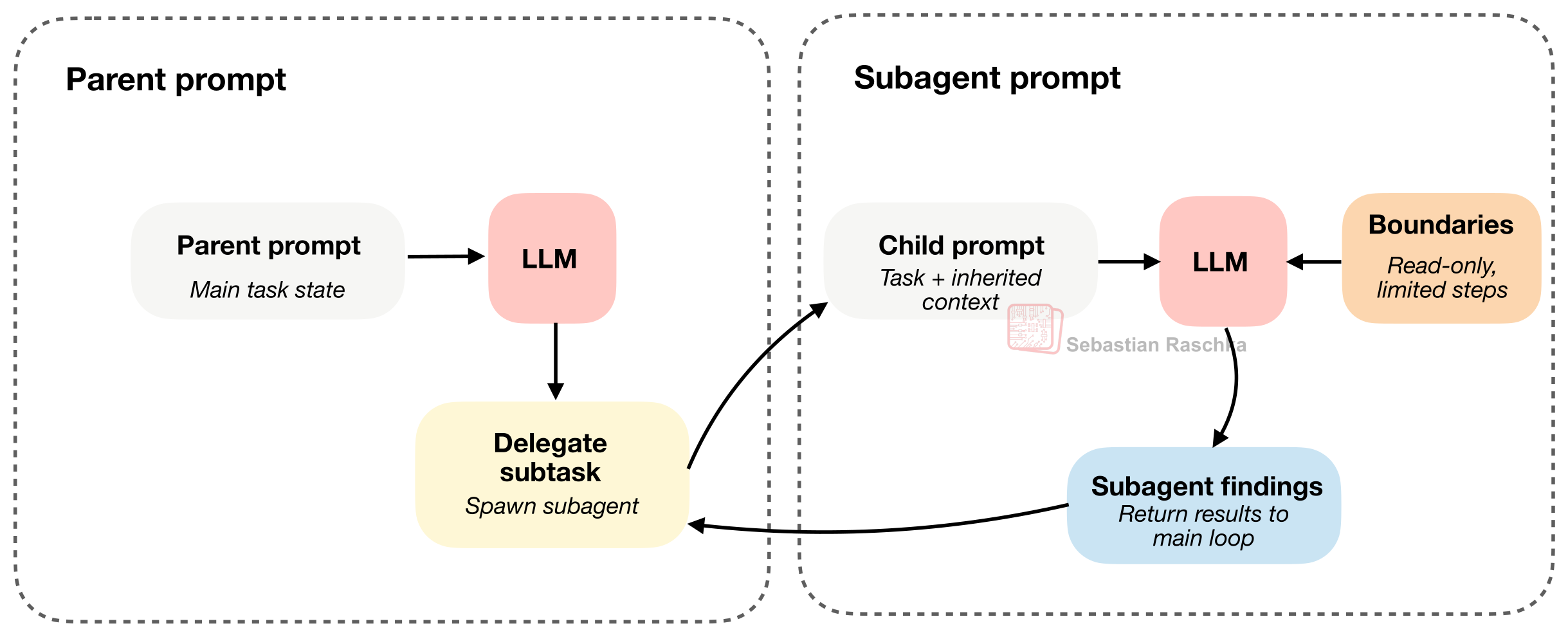
ここでのコツは、サブエージェントが有用なだけの十分な文脈を継承しつつ、同時にそれが制約されている点です(たとえば、読み取り専用にされていたり、再帰の深さが制限されていたりします)。
Claude Code は長い間サブエージェントをサポートしてきており、Codex はより最近になって追加しました。Codex は一般的にサブエージェントを読み取り専用モードに強制しません。代わりに、通常はメインエージェントのサンドボックスや承認設定の多くを継承します。つまり、その境界は主に、タスクのスコープ設定、文脈、そして深さに関するものです。
コンポーネント要約
上のセクションでは、コーディングエージェントの主要なコンポーネントをカバーしようとしました。前にも述べたとおり、それらは実装の中で、ある程度まで密に絡み合っています。しかし、1つずつ取り上げて説明することで、コーディング用の仕組みがどのように動くのか、そしてなぜ単純なマルチターンのチャットよりもLLMをより有用にできるのか、という全体像(メンタルモデル)を掴む助けになることを願っています。



