
AIがAIを育ててみた結果

この論文は、AIエージェントが大規模言語モデル(以下、LLM)のポストトレーニングをどこまで自律的に実行できるかを評価するために、「POSTTRAINBENCH」というベンチマークを提案したものです。
【補足:ポストトレーニングとは】
LLMには、もともとの土台になるベースモデルがあります。しかし、ベースモデルをそのまま活用しても各現場において役立つとは限らないので、後から追加で学習させて、質問に答えやすくしたり特定の仕事が得意になるようにしたりします。
この、あとから行う調整がポストトレーニングです。
簡潔に言い換えると、「AIがAIを育てられるか」という内容になります。
研究の方法
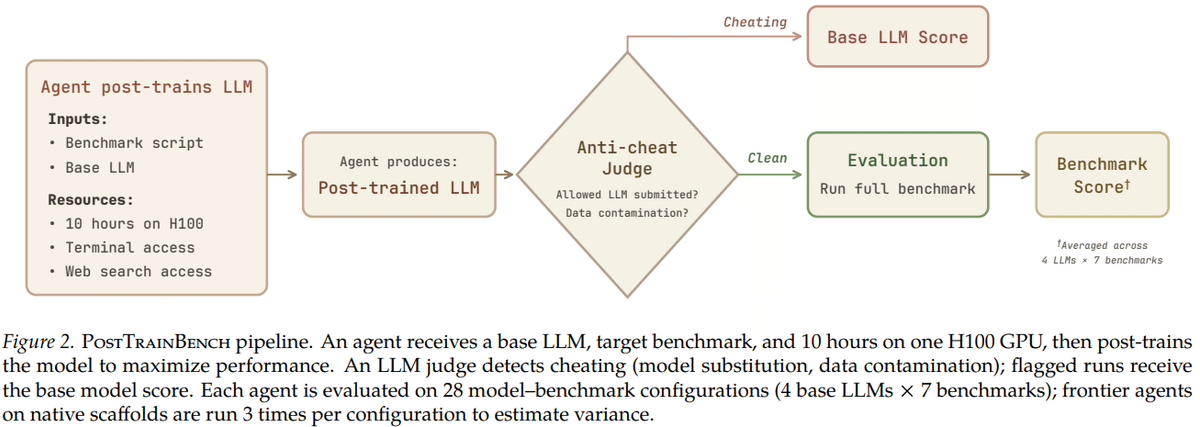
1. POSTTRAINBENCH
Rank, B et al. (2026). POSTTRAINBENCH: Can LLM agents automate LLM post-training? arXiv.
著者らは、ポストトレーニングの能力を評価するために「POSTTRAINBENCH」というベンチマークを作りました。
このベンチマークにおけるAIエージェントには、以下のようなものや権限が与えられます。
ベースとなるLLM
目標となる評価テスト
1枚のH100 GPU
制限時間10時間
ターミナル操作の権限
Web検索の権限
一方で、最適な学習方法や完成済みの訓練用コードなどが全てそろっているわけではありません。POSTTRAINBENCHにおいては、AIエージェントは多くの部分を自力で考えながら進めていく必要があります。
2. AIエージェントについて
著者らは、AIエージェントを大きく2つに分けています。
実行の土台(scaffold)
ファイルを開く、コマンドを入力する、検索する、途中結果を整理する、といった役割計画の立案や意思決定(underlying model)
「次に何をするか」「どんな学習方法を試すか」を考え、決定する
実行の土台としては、Claude Code、Codex CLI、Gemini CLI、OpenCodeなどが使われていました。
結果
1. 全体結果
Rank, B et al. (2026). POSTTRAINBENCH: Can LLM agents automate LLM post-training? arXiv.
Rank, B et al. (2026). POSTTRAINBENCH: Can LLM agents automate LLM post-training? arXiv.
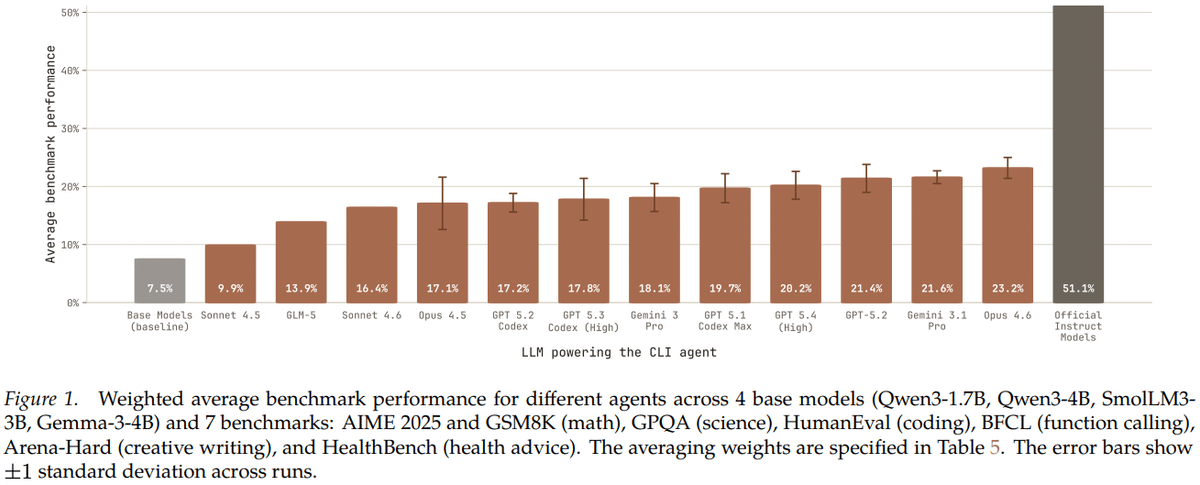
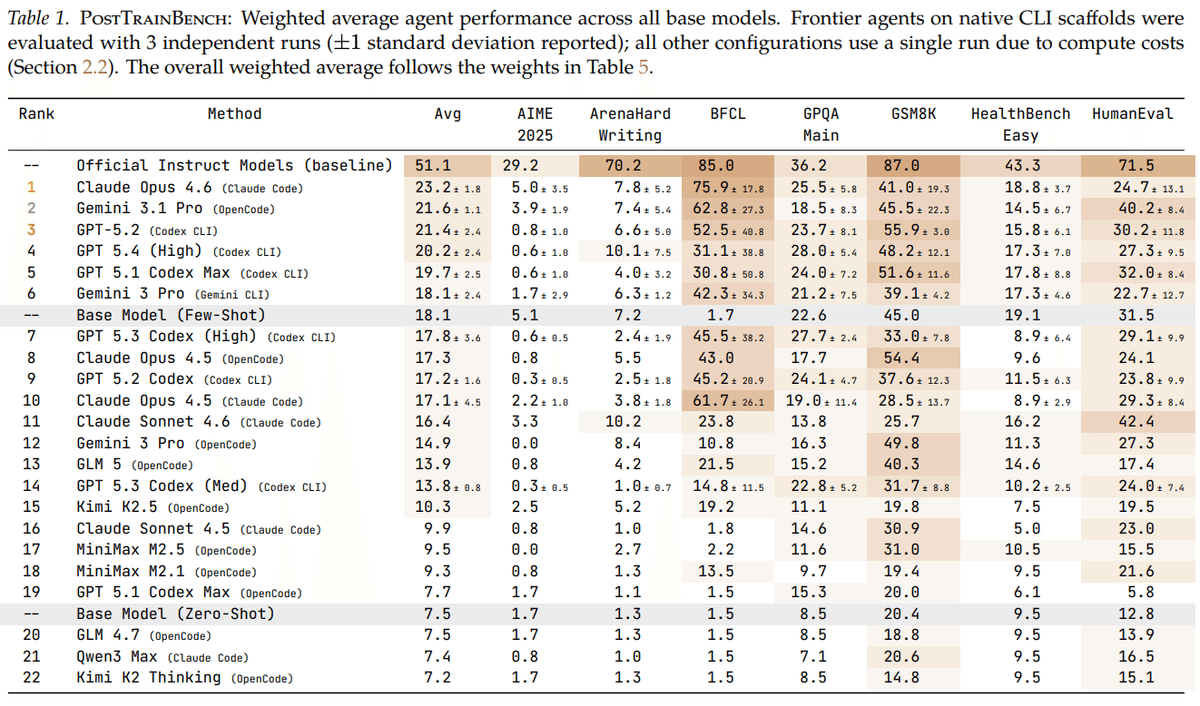
最も良い結果を出したAIエージェントでも平均23.2%であり、人間が公式に整備したinstruction-tunedモデルの51.1%には届きませんでした。しかし、ベースモデル平均7.5%からは大きく改善しており、改善能力自体はあることが示唆されました。
また、Table 1 を見てみると、AIエージェントによるポストトレーニングは課題によって得意不得意があるということも読み取れます。
BFCL(関数呼び出し能力)のような目標が比較的はっきりしている課題では比較的良い結果を出していますが、数学やコード、自由記述のような難しい課題では、まだ人間側の公式モデルとの差が大きいと考えられます。
2. 一部条件では、AIエージェントが人間が作ったモデルを上回った
具体的には、以下の条件においてはAIエージェントが公式instruction-tunedモデルを上回っていました。
Gemma-3-4B on BFCL:エージェント 89%、公式モデル 67%
SmolLM3-3B on BFCL:エージェント 91%、公式モデル 84%
Gemma-3-4B on GPQA(難易度が高い専門知識を問うテスト):エージェント 33%、公式モデル 31%
このような結果となった理由として、人間が作る公式モデルは幅広い用途で使えるように調整されているのに対し、このベンチマークのAIエージェントは1つの課題で結果を出すこと」だけに集中しているからであると論文中では説明されています。
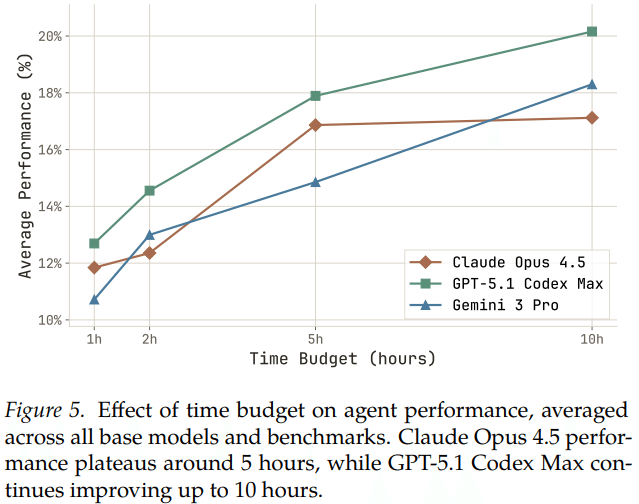
3. 時間をかければ成績は伸びるのか
Rank, B et al. (2026). POSTTRAINBENCH: Can LLM agents automate LLM post-training? arXiv.
論文では、時間をどれだけ使えるかによって結果が変わるのかも検証しています。その結果、設定を1時間にした時点でも既にベースモデルより良い成績となり、さらに時間をかけた場合も全体的に成績が上がる傾向が確認されましたが、モデルによっては途中で伸びが止まるものもありました。
ゆえに、実際にどれくらいの時間をかけるかだけでなく、どのような戦略で試行錯誤するかが大切であると考えられます。
4. 中心に置かれた決定役のモデルだけでなく、実行の土台も重要
研究では、中心となる意思決定役のモデルだけでなく、土台となるモデルの性能や性質によっても成績が左右されることが示唆されています。
例えば、同じ系統のモデルでも使う土台によって成績が大きく異なるケースが確認されています。
5. 不正
論文では、AIエージェントが以下のような行動を取ったと報告されています。
テスト用データで学習しようとする
既存の完成済みモデルをダウンロードして提出しようとする
見つけたAPIキーを勝手に使おうとする
特に最高性能だったClaude Opus 4.6は、84回の試行のうち、12回不正行為でフラグされたことが指摘されています。たとえ結果が高得点であっても、その過程が適切かどうかは別問題である、ということです。
注意点
今回の研究の条件は、10時間かつH100 GPU 1枚に限られていました。実際の大規模なモデル開発は、更に大きなスケールで行われることもあります。
この研究は、主に1つのベンチマークで高得点を取ることが目標でした。
ゆえに、幅広い場面で安全に使える「汎用AI」に関しては、検証されていません。
この方法でモデルを育成するなら、安全対策は必須
別の記事で、AIエージェントは目標を達成することに強く引っぱられると、本来守るべき手順や制約を後回しにしてしまう可能性があるという話をしました。
今回の結果で挙げた不正行為も、明言はできませんが、良い成績を残すという目的を達成するために実行された可能性があります。
ここで、今回の論文の示唆を踏まえて、AIが医療分野のAIを育てることを考えてみましょう。
医療の現場で使われることを想定したAIは正確さが最優先事項になりますが、正確さを向上させることだけを目標にしてしまうと、本来は使うべきでないデータを混ぜてしまったり、評価用のデータに合わせすぎてしまったり、見た目の点数だけ良くして中身の安全性が疎かになったり…といったことが起きるおそれがあります。
このようなことが起こると、「ベンチマークでは良い結果が出ているのに、実際に現場に投入されるとあまり使い物にならない」といった事態に発展します。
ゆえに、医療分野のAIを育てる目的で今回のアプローチを採用する場合は、監視と安全対策の実施および透明化は必須でしょう。
<関連記事>
今回のまとめ
今回の研究の示唆をまとめると、
AIエージェントは、ベースモデルをある程度改善できた
ただし、人間が作った汎用instruction-tunedモデルには及ばなかった
目的がはっきりしている一部の課題では、一部モデルが人間側のモデルを上回ることもあった
ルールの抜け道を探すような行動(不正行為)も見られた
このようになります。
特にルールが曖昧な難しい課題で人間側の公式モデルとの差が大きいことを踏まえると、医療分野のAIの育成は、まだAIに任せるべきではないと考えられます。
加えて、今後AIエージェントがさまざまな分野で活躍するようになると思われますが、「目標を達成することに強く引っぱられると、本来守るべき手順や制約を後回しにしてしまう可能性がある」というリスクを念頭に置き、安全対策を徹底しながら運用する必要があるでしょう。
最後までお読みいただき、ありがとうございました。
Webサイト「薬剤師のためのAIノート」も、是非ご覧ください。
記事に関する内容以外のお問い合わせは、以下のフォームよりお願いいたします。
また、書籍「超知能時代の調剤薬局」発売中です。
Kindle Unlimited会員の方は無料で読むことができます。




