 | submitted by /u/rm-rf-rm [link] [comments] |
Confirmed: SWE Bench is now a benchmaxxed benchmark
Reddit r/LocalLLaMA / 4/27/2026
💬 OpinionSignals & Early TrendsIdeas & Deep AnalysisModels & Research
Key Points
- The article points to OpenAI’s linked post stating that SWE-bench-verified will no longer be used for evaluation because it has become effectively compromised or outdated for fair benchmarking.
- The discussion frames SWE Bench as having shifted into a “benchmaxxed” state, implying that models and participants may have overfit to the benchmark rather than generalize.
- It suggests that benchmark integrity issues can undermine the usefulness of results derived from SWE Bench.
- Overall, the piece highlights the need for evaluation methods that remain robust against benchmark gaming over time.
💡 Insights using this article
This article is featured in our daily AI news digest — key takeaways and action items at a glance.
Related Articles
Can Geometric Deep Learning lead eliminate the need of "Brute Force" pre-training [D]
Reddit r/MachineLearning

Product Photo Editing with AI: A Complete Guide for Small Businesses
Dev.to

I Spent Weeks Reverse-Engineering OpenClaw. Here's What Nobody Tells You.
Dev.to
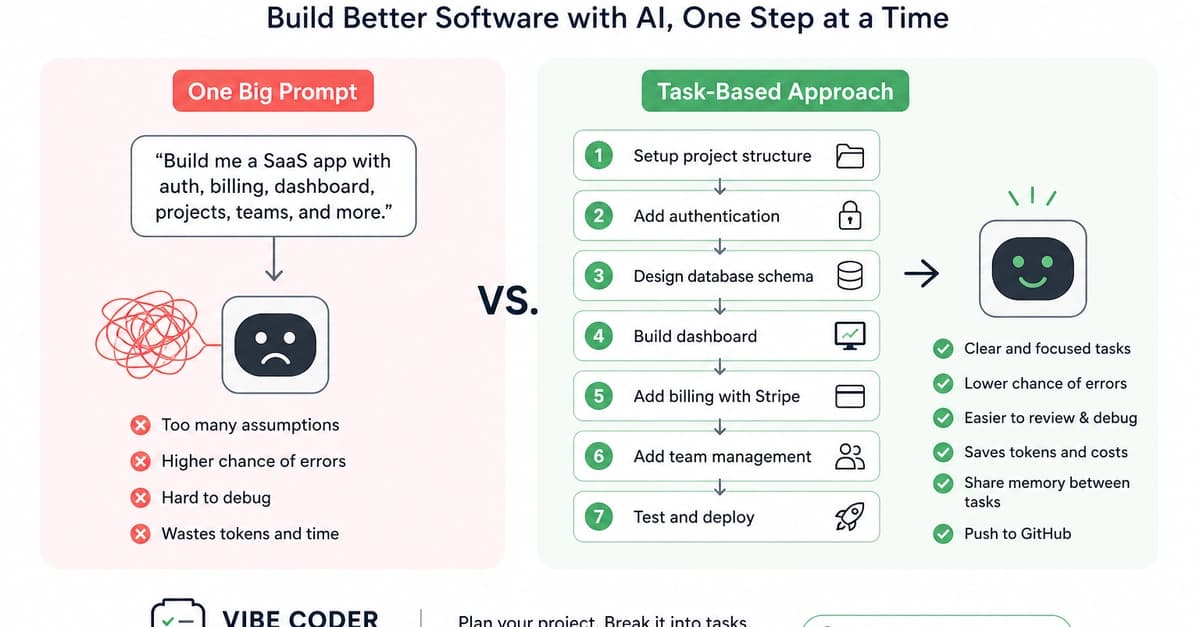
Why Task-Based Vibe Coding Is Better for Building Real Software Products
Dev.to

Programmers Becoming Product Managers
Dev.to