GPT-5.5徹底比較:Claude Opus 4.7・Gemini 3.1 Pro・DeepSeek V4との性能差を検証
Zenn / 4/26/2026
💬 OpinionIdeas & Deep AnalysisModels & Research
Key Points
- GPT-5.5を軸に、Claude Opus 4.7・Gemini 3.1 Pro・DeepSeek V4との性能差を比較し、どこで優劣が出やすいかを検証する内容です。
- 複数の主要LLMを同一観点で見比べることで、用途別(文章生成、推論、指示追従など)の選び方に示唆を与えます。
- 従来の“モデル名ベース”ではなく、実測ベースでの差分理解を促す比較形式になっています。
- ベンチマーク/評価の観点が重要で、同じタスクでもモデルの挙動差が出る可能性に言及しています(比較検証を通じて示す構成)。
GPT-5.5徹底比較:Claude Opus 4.7・Gemini 3.1 Pro・DeepSeek V4との性能差を検証
2026年4月23日、OpenAIは新モデルGPT-5.5(コードネーム"Spud")をリリースしました。GPT-4.5以来初の完全再学習ベースモデルであり、Terminal-Bench 2.0で82.7%のスコアを記録しています。一方で、SWE-Bench ProではClaude Opus 4.7に5.7ポイント差をつけられ、ハルシネーション率86%という課題も報告されています。
この記事では、GPT-5.5をClaude Opus 4.7、Gemini 3...
Continue reading this article on the original site.
Read original →Related Articles
Can Geometric Deep Learning lead eliminate the need of "Brute Force" pre-training [D]
Reddit r/MachineLearning

Product Photo Editing with AI: A Complete Guide for Small Businesses
Dev.to

I Spent Weeks Reverse-Engineering OpenClaw. Here's What Nobody Tells You.
Dev.to
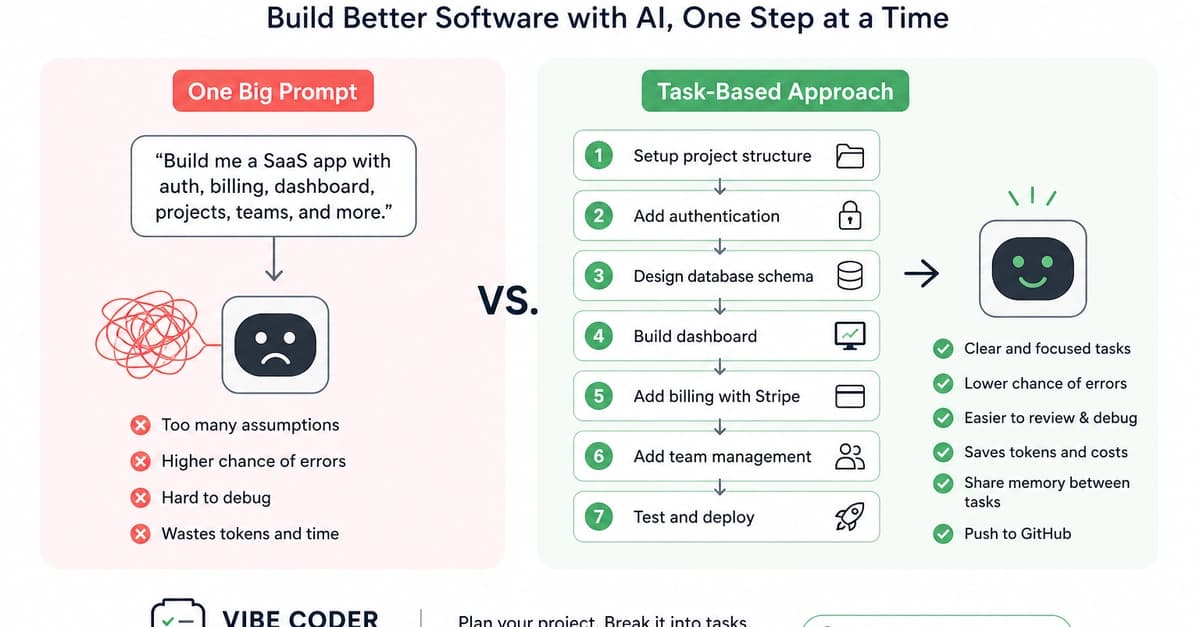
Why Task-Based Vibe Coding Is Better for Building Real Software Products
Dev.to

Programmers Becoming Product Managers
Dev.to