Quantifying and Predicting Disagreement in Graded Human Ratings
arXiv cs.CL / 5/5/2026
📰 NewsModels & Research
Key Points
- The paper analyzes how disagreement varies across items in graded human ratings for inappropriate language, such as offensive, hate, and toxic language perception.
- It tests whether annotation disagreement levels can be predicted using textual features and proposes an “Opposition Index” to measure annotator perspective opposition per item.
- The results find a moderate positive correlation between estimated disagreement (variance) and observed annotation variance, indicating that text-based signals partially capture human disagreement.
- Two variance-prediction approaches—directly predicting variance and inferring it from predicted annotation distributions—achieve comparable performance.
- For predicting opposing perspectives, items with high Opposition Index values are harder to predict and models tend to underestimate these disagreements.
Related Articles
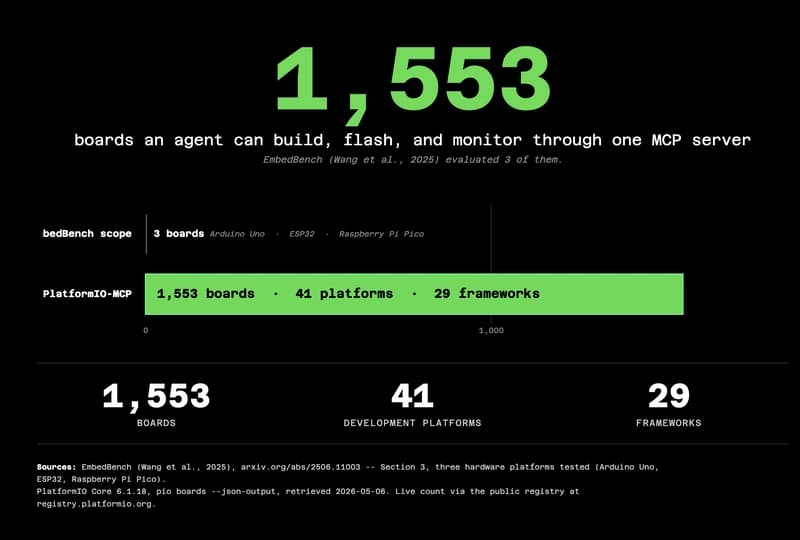
The 55.6% problem: why frontier LLMs fail at embedded code
Dev.to

Four CVEs in a week, all the same shape: when agents execute LLM-generated code
Dev.to
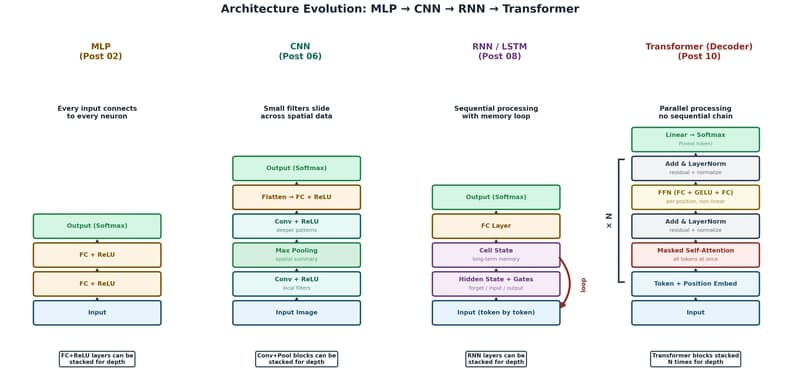
The Transformer: The Architecture Behind Modern AI
Dev.to

Foundational Models Defining a New Era in Vision: A Survey and Outlook
Dev.to

ParoQuant: Pairwise Rotation Quantization for Efficient Reasoning LLM Inference
Reddit r/LocalLLaMA