単発ターンのエージェントのやり取りを評価することは、多くのチームがよく理解しているパターンに従います。入力を与え、出力を収集し、結果を判定します。Strands Evaluation SDK のようなフレームワークは、helpfulness、faithfulness、tool usage を評価するエバリュエータによって、このプロセスを体系化します。以前のブログ記事では、これらの機能を使って AIエージェントのための包括的な評価スイートを構築する方法 を取り上げました。しかし、生産環境の会話は、実際には1ターンで終わることはほとんどありません。
実際のユーザーは、複数ターンにわたって展開するやり取りを行います。回答が不十分ならフォローアップの質問をし、新しい情報が出てきたら方向転換し、ニーズが満たされないと不満を表明します。たとえば、単独で「パリ行きのフライトを予約して」と適切に処理できる旅行アシスタントでも、同じユーザーが「やっぱり、電車を見てみられない?」や「エッフェル塔の近くのホテルはどう?」と続けてきた場合には苦戦するかもしれません。こうした動的なパターンをテストするには、固定された入力と期待出力だけで構成された静的なテストケース以上のものが必要です。
本質的な難しさはスケールです。エージェントが変更されるたびに、何百もの複数ターンの会話を手作業で個別に実施することはできず、スクリプト化した会話フローを書くと、実際のユーザーの振る舞いを見落としてしまう、あらかじめ決められた経路に固定されてしまいます。評価チームが必要としているのは、現実的で、目標に基づくユーザーをプログラム的に生成し、そのユーザーを複数ターンにわたって自然にエージェントと会話させる方法です。この投稿では、ActorSimulator が Strands Evaluations SDK において、この課題にどう構造化されたユーザーシミュレーションで対処し、評価パイプラインに統合するかを探ります。
なぜマルチターンの評価は本質的に難しいのか

単発ターンの評価には、わかりやすい構造があります。入力は事前にわかっており、出力は自己完結的で、評価コンテキストはその1回のやり取りに限定されます。マルチターンの会話は、これらの前提をすべて打ち破ります。
マルチターンのインタラクションでは、各メッセージが、それまでに起きたすべてに依存します。ユーザーの2つ目の質問は、エージェントが1つ目にどう答えたかによって形作られます。不完全な回答は、抜け落ちた部分についてのフォローアップを引き起こし、誤解はユーザーに元の依頼を言い直させ、意外な提案は会話を新しい方向へ送ってしまうことがあります。
これらの適応的な振る舞いによって、会話の経路はテスト設計時点では予測できません。I/O ペアの静的なデータセットは、どれほど大規模でも、この動的な性質を捉えられません。なぜなら、「次に来るユーザーの正しいメッセージ」は、エージェントが直前に言った内容に依存するからです。
理論上は手動テストでこのギャップを埋められますが、実際にはうまくいきません。テスターは現実的なマルチターンの会話を行えますが、それをあらゆるシナリオで、あらゆるペルソナタイプごとに、エージェントの変更のたびに実施するのは持続可能ではありません。エージェントの能力が成長するほど、会話経路の数は組合せ的に増大し、チームが手作業で探索できる範囲を大きく超えていきます。
そこで一部のチームは近道としてプロンプトエンジニアリングに頼り、テスト中に大規模言語モデル(LLM)に「ユーザーのように振る舞って」と頼みます。しかし、構造化されたペルソナ定義や明示的な目標の追跡がないと、こうしたアプローチは結果が安定しません。シミュレーションされたユーザーの振る舞いは実行のたびに揺らぎ、時間経過での評価比較や、本当の退行(レグレッション)をランダムな変動と区別することが難しくなります。構造化されたユーザーシミュレーションは、人間の会話の現実味と、自動化テストの再現性・スケールを組み合わせることで、このギャップを埋めることができます。
良いシミュレートユーザーとは何か
シミュレーションベースのテストは、他のエンジニアリング分野では確立されています。フライトシミュレータは、現実世界で危険だったり再現不可能だったりするシナリオに対する操縦士の応答をテストします。ゲームエンジンは、リリース前にAI駆動のエージェントでプレイヤーの行動経路を何百万通りも探索します。会話型AIにも同じ原理が当てはまります。定義した条件のもとで、現実的なアクターがあなたのシステムと相互作用する制御された環境を作り、その結果を測定します。
AIエージェントの評価のために役立つシミュレートユーザーは、まず一貫したペルソナから始まるべきです。あるターンでは技術の専門家のように振る舞い、次のターンでは混乱した初心者のように振る舞うユーザーは、信頼できない評価データを生みます。一貫性とは、実際の人がそうであるように、すべてのやり取りを通じて同じコミュニケーションスタイル、専門性レベル、そしてパーソナリティ特性を維持することです。
同じくらい重要なのが目標に基づく振る舞いです。実際のユーザーは、何か達成したいことを持ってエージェントに来ます。達成するまで粘り、うまくいかないときは方針を調整し、目標が満たされたことを認識します。明示的な目標がないと、シミュレートユーザーは会話を早すぎるタイミングで終えるか、あるいは無限に質問を続ける傾向になります。どちらも実際の利用を反映していません。
また、シミュレートユーザーは、あらかじめ決められた台本を追うのではなく、エージェントが言うことに対して適応的に応答しなければなりません。エージェントが確認質問をしたら、アクターはキャラクターに合わせて答えるべきです。応答が不完全なら、アクターは話を先に進めるのではなく、残っている部分(抜け落ちた内容)に対してフォローアップします。会話が話題から逸れたら、アクターは元の目標に向けて軌道修正します。これらの適応的な振る舞いにより、シミュレーションされた会話は評価データとして価値を持ちます。なぜなら、プロダクション環境であなたのエージェントが直面するのと同じ会話ダイナミクスを検証するからです。
ペルソナの一貫性、目標の追跡、そして適応的な振る舞いをシミュレーションのフレームワークに組み込むことこそが、アドホックなプロンプトとは異なる「構造化されたユーザーシミュレーション」を特徴づけます。Strands Evals の ActorSimulator は、まさにこれらの原則に基づいて設計されています。
ActorSimulator はどのように動作するか
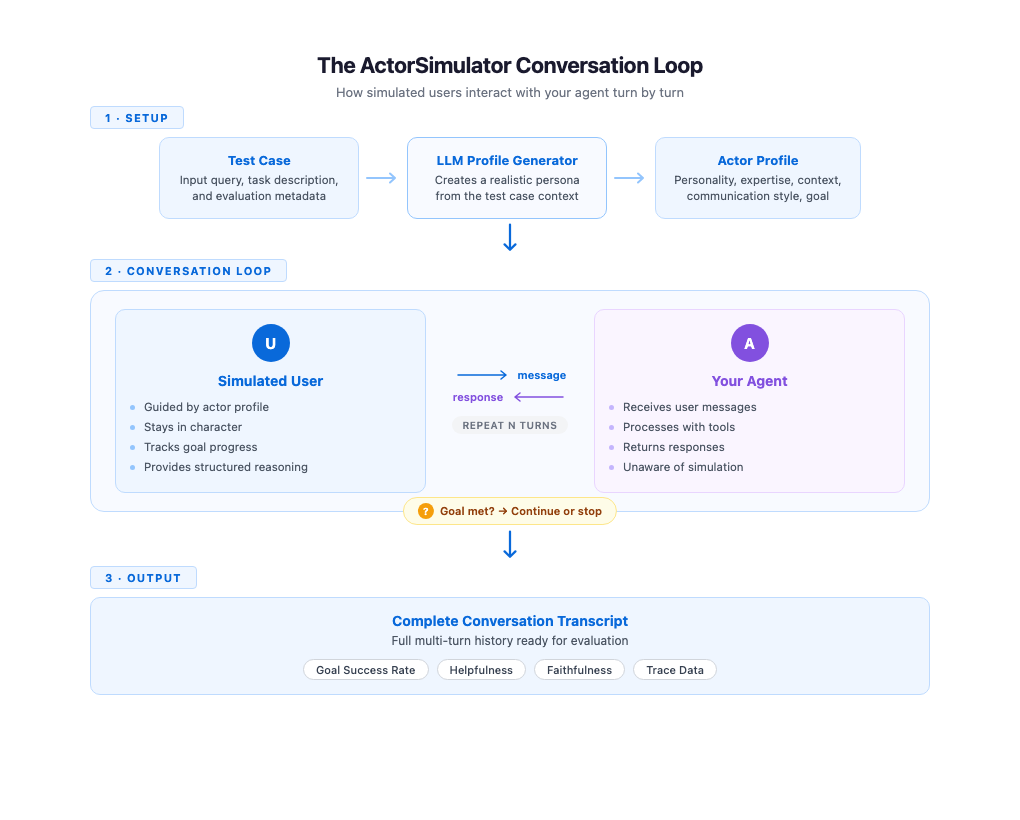
ActorSimulator は、現実的なユーザーペルソナとして振る舞うよう設定された Strands Agent をラップする仕組みにより、これらのシミュレーション特性を実装します。プロセスはプロファイル生成から始まります。入力クエリと任意のタスク説明を含むテストケースが与えられると、ActorSimulator は LLM を使って完全なアクタープロファイルを作成します。たとえば、入力が「パリ行きのフライト予約を手伝ってほしい」で、タスク説明が「予算内でフライト予約を完了して」であるテストケースでは、予算を意識した旅行者で、初心者レベルの経験を持ち、カジュアルなコミュニケーションスタイルの人物が生成されるかもしれません。プロファイル生成により、それぞれのシミュレート会話には、異なる一貫したキャラクターが与えられます。
プロファイルが確立されると、シミュレータは会話をターンごとに管理します。会話の履歴全体を保持し、各応答を文脈に基づいて生成することで、シミュレートされたユーザーの振る舞いが、そのプロファイルと目標に沿った状態で会話全体を通じて維持されます。エージェントがリクエストの一部にしか対応しない場合、シミュレートされたユーザーは自然に不足している部分に対してフォローアップします。エージェントからの明確化の質問には、そのペルソナと一貫した回答が返されます。すべての応答が、その役(アクター)のペルソナとこれまでに述べられた内容の両方を反映しているため、会話は有機的に感じられます。
目標の追跡は、会話と並行して実行されます。ActorSimulatorには、シミュレートされたユーザーが内蔵の目標達成アセスメントツールを呼び出して、元の目的が達成されたかどうかを評価できる仕組みが含まれています。目標が満たされた場合、またはシミュレートされたユーザーがエージェントには自分の依頼を完了できないと判断した場合、シミュレータは停止シグナルを発し、会話は終了します。目標が達成される前に最大ターン数に到達した場合も、会話は停止します。これは、エージェントがユーザーのニーズを効率的に解決できていない可能性を示すシグナルになります。この仕組みにより、会話が無限に続いたり、恣意的に途中で打ち切られたりするのではなく、自然な終了点を持つように保証されます。
シミュレートされたユーザーの各応答には、メッセージ本文に加えて、構造化された推論も含まれます。シミュレートされたユーザーが、なぜその発言を選んだのかを確認できます。たとえば、不足情報へのフォローアップなのか、混乱を表しているのか、会話を別の方向へ向け直しているのか、といった点です。この透明性は評価開発の際に価値があります。各ターンの推論を追えるため、会話が成功している箇所や、脱線している箇所をより追跡しやすくなるからです。
ActorSimulator の使い始め
開始するには、次のコマンドで Strands Evaluation SDK をインストールする必要があります: pip install strands-agents-evals。手順に沿ったセットアップについては、当社の ドキュメント、または詳細は 以前のブログ を参照してください。これらの概念を実際に使うには、最小限のコードで済みます。入力クエリと、ユーザーの目標を捉えたタスク記述でテストケースを定義します。ActorSimulator は、プロファイル生成、会話管理、目標追跡を自動的に処理します。
以下の例では、マルチターンのシミュレート会話を通して旅行アシスタントエージェントを評価します。
from strands import Agent
from strands_evals import ActorSimulator, Case, Experiment
# テストケースを定義します
case = Case(
input="I want to plan a trip to Tokyo with hotel and activities",
metadata={"task_description": "Complete travel package arranged"}
)
# 評価したいエージェントを作成します
agent = Agent(
system_prompt="You are a helpful travel assistant.",
callback_handler=None
)
# テストケースからユーザーシミュレータを作成します
user_sim = ActorSimulator.from_case_for_user_simulator(
case=case,
max_turns=5
)
# マルチターン会話を実行します
user_message = case.input
conversation_history = []
while user_sim.has_next():
# エージェントがユーザーに応答します
agent_response = agent(user_message)
agent_message = str(agent_response)
conversation_history.append({
"role": "assistant",
"content": agent_message
})
# シミュレータが次のユーザーメッセージを生成します
user_result = user_sim.act(agent_message)
user_message = str(user_result.structured_output.message)
conversation_history.append({
"role": "user",
"content": user_message
})
print(f"Conversation completed in {len(conversation_history) // 2} turns")会話ループは has_next() が False を返すまで継続します。これは、シミュレートされたユーザーの目標が満たされた場合、エージェントが依頼を完了できないとシミュレートされたユーザーが判断した場合、または最大ターン上限に到達した場合に発生します。生成される conversation_history には、評価の準備ができた完全なマルチターンのトランスクリプトが含まれます。
評価パイプラインとの統合

独立した会話ループは素早い実験には便利ですが、本番環境での評価にはトレースを取得し、それを評価用パイプラインに投入する必要があります。次の例では、ActorSimulator を OpenTelemetry のテレメトリ収集 と Strands Evals のセッションマッピングと組み合わせます。タスク関数はシミュレート会話を実行し、各ターンからスパンを収集して、それらを評価用の構造化されたセッションにマップします。
from opentelemetry.sdk.trace.export import BatchSpanProcessor
from opentelemetry.sdk.trace.export.in_memory_span_exporter import InMemorySpanExporter
from strands import Agent
from strands_evals import ActorSimulator, Case, Experiment
from strands_evals.evaluators import HelpfulnessEvaluator
from strands_evals.telemetry import StrandsEvalsTelemetry
from strands_evals.mappers import StrandsInMemorySessionMapper
# エージェントのトレースを取得するためのテレメトリをセットアップします
telemetry = StrandsEvalsTelemetry()
memory_exporter = InMemorySpanExporter()
span_processor = BatchSpanProcessor(memory_exporter)
telemetry.tracer_provider.add_span_processor(span_processor)
def evaluation_task(case: Case) -> dict:
# シミュレータを作成します
user_sim = ActorSimulator.from_case_for_user_simulator(
case=case,
max_turns=3
)
# エージェントを作成します
agent = Agent(
system_prompt="You are a helpful travel assistant.",
callback_handler=None
)
# 会話全体にわたってスパンを蓄積します
all_target_spans = []
user_message = case.input
while user_sim.has_next():
memory_exporter.clear()
agent_response = agent(user_message)
agent_message = str(agent_response)
# テレメトリを取得します
turn_spans = list(memory_exporter.get_finished_spans())
all_target_spans.extend(turn_spans)
# 次のユーザーメッセージを生成します
user_result = user_sim.act(agent_message)
user_message = str(user_result.structured_output.message)
# 評価用にセッションへマップします
mapper = StrandsInMemorySessionMapper()
session = mapper.map_to_session(
all_target_spans,
session_id="test-session"
)
return {"output": agent_message, "trajectory": session}
# 評価データセットを作成します
test_cases = [
Case(
name="booking-simple",
input="I need to book a flight to Paris next week",
metadata={
"category": "booking",
"task_description": "Flight booking confirmed"
}
)
]
evaluator = HelpfulnessEvaluator()
dataset = Experiment(cases=test_cases, evaluator=evaluator)
返却形式: {"translated": "翻訳されたHTML"}# Run evaluations
report = Experiment.run_evaluations(evaluation_task)
report.run_display()
このアプローチでは、会話ターンをまたいだエージェントの振る舞いの完全なトレースを取得できます。スパンには、ツール呼び出し、モデル呼び出し、およびシミュレーションされた会話のあらゆるターンのタイミング情報が含まれます。これらのスパンを構造化されたセッションにマッピングすることで、単発のターンではなく、会話全体を GoalSuccessRateEvaluator や HelpfulnessEvaluator のような評価者が評価できるようになります。
ターゲットテストのためのカスタムアクタープロファイル
自動プロファイル生成はほとんどの評価シナリオをうまくカバーしますが、一部のテスト目標では特定のペルソナが必要になります。たとえば、忍耐強い初心者とは異なる形で、せっかちなエキスパートユーザーをあなたのエージェントが扱えることを確認したい場合や、ドメイン固有のニーズを持つユーザーに対して適切に応答できることを確認したい場合があります。こうしたケースでは、ActorSimulator は、あなたが制御できる完全に定義されたアクタープロファイルを受け付けます。
from strands_evals.types.simulation import ActorProfile
from strands_evals import ActorSimulator
from strands_evals.simulation.prompt_templates.actor_system_prompt import (
DEFAULT_USER_SIMULATOR_PROMPT_TEMPLATE
)
# Define a custom actor profile
actor_profile = ActorProfile(
traits={
"personality": "analytical and detail-oriented",
"communication_style": "direct and technical",
"expertise_level": "expert",
"patience_level": "low"
},
context="Experienced business traveler with elite status who values efficiency",
actor_goal="Book business class flight with specific seat preferences and lounge access"
)
# Initialize simulator with custom profile
user_sim = ActorSimulator(
actor_profile=actor_profile,
initial_query="I need to book a business class flight to London next Tuesday",
system_prompt_template=DEFAULT_USER_SIMULATOR_PROMPT_TEMPLATE,
max_turns=10
)
忍耐レベル、コミュニケーションスタイル、専門性といった特性を定義することで、さまざまなユーザーセグメントに対するエージェントのパフォーマンスを体系的にテストできます。忍耐強く、技術に不慣れなユーザーでは高得点でも、せっかちなエキスパートでは評価が低いエージェントは、埋めるべき具体的な品質ギャップを示しています。同じ目標を複数のペルソナ構成で実行することで、ユーザータイプ別の強みと弱みを理解するためのツールとして、ユーザーシミュレーションを活用できます。
シミュレーションベース評価のベストプラクティス
これらのベストプラクティスにより、シミュレーションベースの評価から最大限の効果を得られます。
max_turnsはタスクの複雑さに基づいて設定します。集中的なタスクには 3〜5、複数ステップのワークフローには 8〜10 を使いましょう。ほとんどの会話で目標を達成できないまま上限に到達する場合は、増やします。- シミュレーターが評価できる具体的なタスク説明を書きます。「ユーザーがフライトを予約できるように手助けして」は完了を信頼性高く判定するには曖昧すぎますが、「日付、目的地、価格が確認されたフライト予約の確定」は具体的な到達目標を与えます。
- ユーザータイプを幅広くカバーするには、自動生成プロファイルを使い、プロダクションログから特定のパターン(たとえばせっかちなエキスパートや初めてのユーザー)を再現するにはカスタムプロファイルを使います。
- 個々のトランスクリプトではなく、テストスイート全体におけるパターンに注目します。シミュレーションされたユーザーからの一貫した軌道修正は、エージェントが話題から逸れていることを示唆し、エージェント変更後にゴール達成率が低下するのは回帰を示します。
- まずは、最も一般的なシナリオをカバーする少数のテストケースから始め、評価の実践が成熟するにつれて、エッジケースや追加のペルソナへ拡張します。
まとめ
私たちは、ActorSimulator が Strands Evals において、現実的なユーザーシミュレーションを通じて会話型AIエージェントを体系的にマルチターン評価できることを示しました。単一のやり取りしか捉えない固定のテストケースに頼るのではなく、目標とペルソナを定義し、自然で適応的な会話の中でシミュレーションされたユーザーがエージェントと相互作用するようにできます。その結果得られるトランスクリプトは、単一ターンテストにあなたが使っているのと同じ評価パイプラインに直接投入され、各会話ターンにまたがる有用性スコア、ゴール達成率、そして詳細なトレースを得られます。
まずは Strands Agents samples リポジトリ 内の動作するサンプル例を探索してください。Amazon Bedrock AgentCore でデプロイされたエージェントを評価するチーム向けに、次の AgentCore evaluations sample は、デプロイ済みエージェントとのやり取りをシミュレーションする方法を示しています。まずは、最も一般的なユーザーシナリオを表す少数のテストケースを用意し、ActorSimulator を通して実行して、結果を評価してください。評価の実践が成熟するにつれて、より多くのペルソナ、エッジケース、会話パターンをカバーするように拡張していきます。

