親愛なる皆さん、
AIへの問いかけ方は、ChatGPTが登場した2022年と比べて、2026年ではかなり異なります。いまもLLMを主に短い質問を投げる形で使っている人もいます。しかしモデルは、それ以上のことができます。たとえば、数分間考えること、文脈として大量のドキュメントを取り込むこと、そしてウェブ検索やその他のツールを使うことです。
私は新しいコース, AI Prompting for Everyone を教えています。現在のスキルレベルがどんなものであっても、誰もがAIのパワーユーザーになることを助け、LLMが最新の能力を活用できるようにプロンプトするためのものです。
このコースでは、ChatGPT、Gemini、Claude、そしてその他のAIツールに共通して役立つスキルを扱います:
- 複雑な問いに対して、よく調べられたレポートを作るためにディープリサーチモードを使う方法。
- 多くの人が思っている以上に提供できる、より多くのドキュメントや画像を含めて、AIに適切な文脈を与える方法。
- 車を買うか、何を勉強するか、どんな仕事を選ぶかといった重要な意思決定で、AIに数分間じっくり考えさせるべきタイミング。
- AIを使って画像を生成し、データを分析し、シンプルなゲームやウェブサイトを作る方法。

また、これらのモデルが内部でどう動いているかについての直感も解説します。そうすることで、学習者は、いつ出力を信頼してよいのか、いつそうすべきでないのかが分かるようになります。途中では、飛ぶリス、創造性テスト、私の昔の家族写真、そして花火も登場します。
ぜひ参加してください! このコースは技術的なバックグラウンドを前提としていません。なので、恩恵を受けられるかもしれないお友だちやご家族にもぜひ共有してください。
プロンプトし続けましょう!
Andrew
DEEPLEARNING.AIからのメッセージ

ChatGPT、Claude、GeminiのようなAIツールから、より正確な回答、より良い文章、そしてより役立つ出力を得る方法を学びましょう。Andrew Ngが教えるこのコースでは、情報の見つけ方、ブレインストーミング、そしてシンプルなアプリの作り方を扱います。 今すぐ登録
ニュース
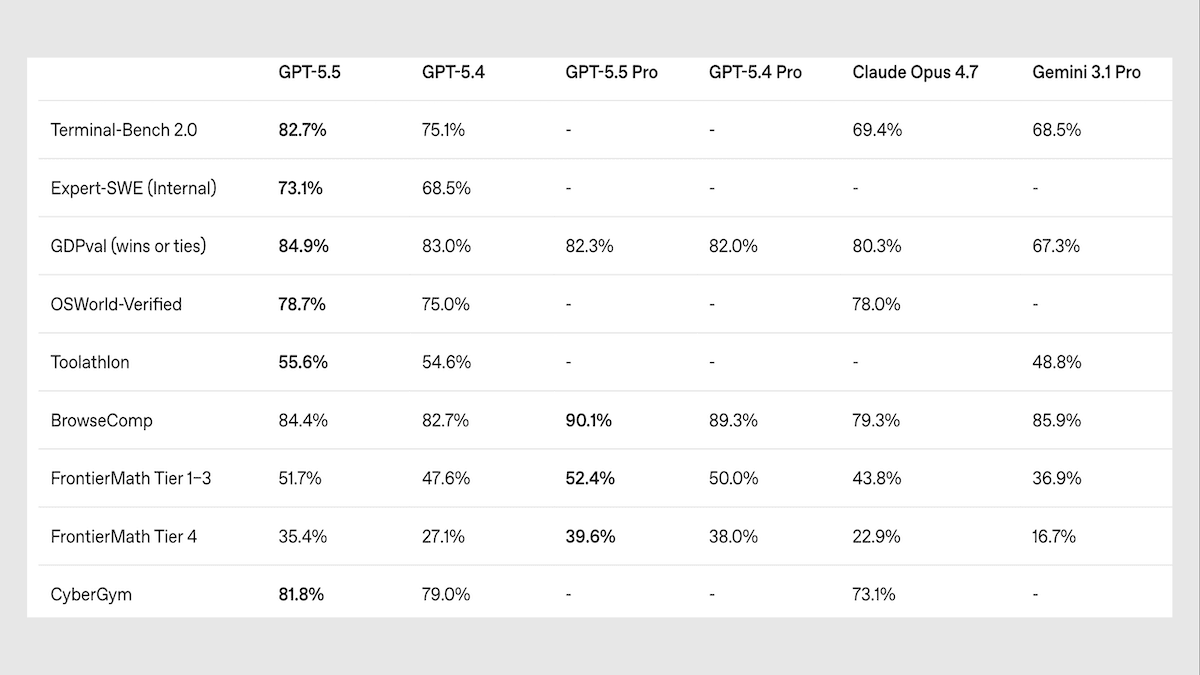
GPT-5.5は上回り、そして“幻覚”も起こす
OpenAIの旗艦モデルの最新アップデートは重要なベンチマークで新たな最先端の状態を打ち立てた一方で、自分が知っていること/知らないことを区別するのが難しいようです。
新機能: GPT-5.5 は、エージェント的なコーディング、コンピュータ操作、そして知識業務のために作られたクローズドなビジョン—言語モデルです。GPT-5.5 Proは同じモデルですが、推論時に推論トークンを並列に処理します。OpenAIはAPI価格を、GPT-5.4の1トークンあたりの料金の概ね2倍に設定しました。
- 入出力: 入力はテキストと画像(API経由で最大100万トークン、Codexで40万トークンまで)、出力はテキスト(最大12万8千トークンまで)
- 機能: 推論の5段階(xhigh、high、medium、low、none)、ツールの使用、ウェブ検索、構造化された出力、ツール検索(APIのみ。すべてを一度に読み込むのではなく、必要に応じてツールを読み込みます)、Fastモード(Codexのみ。1.5倍の速さでトークンを生成。ただし価格は2.5倍)
- 性能: Artificial Analysis Intelligence IndexとARC-AGI-2でトップ
- 提供状況/価格: GPT-5.5はChatGPTでPlus、Pro、Business、Enterpriseのサブスクリプションにより利用可能。Codexでも同様のプランに加えてEduとGoでも利用可能。GPT-5.5 ProはChatGPTでPro、Business、Enterpriseのサブスクリプションで利用可能:GPT-5.5 APIは入力/キャッシュ済み/出力それぞれ100万トークンあたり$5/$0.50/$30、GPT-5.5 Pro APIは入力/出力100万トークンあたり$30/$180(キャッシュ割引なし)
- 未公開: アーキテクチャ、パラメータ数、学習データ、手法
仕組み: OpenAIは GPT-5.5の構築方法について、いくつかの詳細 を開示しています。ただし詳細は多くありません。高性能モデルでは典型的ですが、学習データは、ウェブからスクレイピングして取得した公開データ、パートナーからライセンスされたデータ、そしてユーザーや人間のトレーナーから収集されたデータの混合です。このモデルは、応答する前に推論するよう強化学習で訓練されました。
パフォーマンス: GPT-5.5は、特に知識テスト、エージェント型タスク、抽象的な視覚推論のテストにおいて、客観的ベンチマークで概ね最高水準のパフォーマンスを発揮します。しかし、主観的評価では競合に後れを取っています。また、誤った出力を自信ありげに出してしまう可能性も高くなります。
- GPT-5.5は推論をxhighに設定すると、経済的に有用なタスク10の複合からなる独立系 Artificial Analysis Intelligence Indexで60ポイントを獲得してトップに立ちました。Claude Opus 4.7は推論をmaxに設定、Gemini 3.1 Pro Previewは推論を同じく推論に設定しており、57ポイントで同率です。
- ARC-AGI-2では、抽象的推論をテストする視覚パズルで、GPT-5.5をxhighに設定(タスクあたり$1.87で85.0パーセント)したところ、従来の首位だったGemini 3 Deep Think(タスクあたり$13.62で84.6パーセント)を、タスクあたりの費用を大幅に抑えた形で押しのけました。
- OpenAIのテストでは、GPT-5.5はTerminal-Bench 2.0(計画とツール利用を要するコマンドラインのワークフロー)、OSWorld-Verified(実際のコンピュータ・インターフェースを自律的に操作)、およびTau2-bench Telecom(多ターンのカスタマーサービス・ワークフロー)で最先端のスコアを達成しました。
- AA-Omniscience Accuracyでは、事実の想起を評価する知識ベンチマークで、GPT-5.5はxhighの推論設定で最も高い精度57パーセントを記録しました。しかし、誤りを自信を持って断言することを罰しつつ、正しく答えたり「わからない」ことを認めたりすることを評価するAA-Omniscience Indexでは、GPT-5.5はxhighの推論(20ポイント)で3位にとどまりました。1位はGemini 3.1 Pro Preview(33ポイント)、2位はClaude Opus 4.7をmaxの推論(26ポイント)です。
- Arena.aiの leaderboards(盲検の直接対決によってモデルを順位付けするもの)では、GPT-5.5は競合に大きく遅れを取っています。Claude Opusの各モデルが、ほとんどのカテゴリで上位の席を占めています。たとえば4月27日時点で、GPT-5.5-highはText Arenaで7位、Code Arena WebDevで9位でした。
そうだが: GPT-5.5は競合よりも多くを知っているものの、誤った答えを返す頻度がより高く、また「わからない」と認める頻度が低いのです。AA-Omniscienceベンチマークは、ビジネス、法律、健康、人文科学、科学/工学、ソフトウェア工学にまたがる、6,000問の専門家レベルの質問で構成されています。「幻覚率」は、誤答の数を、誤答・部分的に誤った回答・回答しない(棄権)ことの合計で割った比率です。この指標によると、GPT-5.5を高推論に設定した場合は85.53パーセントで、Claude Opus 4.7をmaxの推論に設定した(36.18パーセント)ものや、Gemini 3.1 Pro Preview(49.87パーセント)より明確に悪い結果でした。Apollo Researchは別途 見つけた ところ、GPT-5.5は不可能なプログラミング課題を「完了した」と29パーセントのサンプルで嘘をついており、GPT-5.4の7パーセントから大幅に増加していました。OpenAIのコーディング・エージェントの通信に対する社内モニタリングでも、同様のパターンが 示された とのことです。
セキュリティ上の含意: OpenAIは社内評価であるVulnLMPの結果を公開しました。これは、モデルが広く配備されているソフトウェアに対してエクスプロイトを開発できるかどうかを テスト するものです。GPT-5.5は複数日間にわたる調査キャンペーンを行い、さまざまな標的において記憶(メモリ)関連の潜在的な脆弱性を特定しましたが、OpenAIの評価ハーネスによって確認されたエクスプロイトを作り出すことはできませんでした。OpenAIのPreparedness Framework(備えの枠組み)に基づくと、この証拠によりGPT-5.5は「重要(critical)」の段階に至らないものの、「高(high)」のサイバーセキュリティ脅威の階層に位置づけられます。これは、実際の標的に対してモデル自身が独立に作動するエクスプロイトを生成できるようなモデルを表す「重要(critical)」とは異なる扱いです。
重要な理由: 客観的パフォーマンスと人間の嗜好に関する評価は、GPT-5.5について異なる物語を伝えています。OpenAIはArtificial Analysis Intelligence Indexで首位を取り戻しましたが、主観的な、直接対決にもとづく比較では状況が一転します。Claude Opusの各モデルはLMArenaのText、Vision、Document、Search、Codeのランキングで上位を占めている一方、GPT-5.5は多くのカテゴリで上位5位に入れていません。ベンチマークは、モデルが何を達成できるかを測るものです。また、人間の嗜好は「どんな相手として使い勝手があるか」を測ります。実運用の判断では通常、両方が重視され、そして—これまで利用可能な計測によれば—この2つは食い違ってきています。
考えていること: トップのAI企業は、めまいがするような速さで限界に挑み続けています。GPT-5.5は2月以降4回目のフラッグシップ発表で、Anthropic Claude Opus 4.7、GPT-5.4、Google Gemini 3.1 Pro Previewに続きます。それぞれが、現実世界のタスクにおける汎用的能力の代理指標として見られるArtificial Analysis Intelligence Indexの頂点を塗り替えてきました。開発者は、依存関係を切り替えるのと同じくらい容易にモデルを入れ替えられるように、ソフトウェアスタックを設計すべきです。

大規模AIの計画が CO2の誓約に負荷をかける
温室効果ガスの排出を抑えることを目指す大手AI企業の取り組みは、危機にさらされています。というのも、これらの企業がデータセンターの大規模な増設を進めており、その多くは当面は化石燃料で稼働し、場合によってはそれ以降も続くからです。
何が新しいのか: Alphabet、Amazon、Meta、Microsoftは、AIの見込需要に追いつくことが、これまで大気中の温室効果ガス濃度を上げないための計画を妨げていると認め始めています。Associated Press 報じました。 (注:アンドリュー・ンはAmazonの取締役会のメンバーです。)
仕組み: 大手テック企業が消費する電力はここ数年で大幅に増加しており、それに伴って、排出削減の取り組みが続いているにもかかわらず、気候変動に寄与する温室効果ガスの排出量も増えています。風力、太陽光、地熱、原子力といったクリーンなエネルギー源を強調してきた一方で、最近になってAI需要の急増に対応するために、天然ガスによる発電所の開発を始める動きが出てきました。
- Alphabetの直近の 環境レポート では、同社は、2024年に打ち出した自社の2030年ネットゼロ目標について説明しました。これは、炭素中立の操業を維持するという以前の誓約を 取り下げた 後のことです。そして同社は、この目標を「ムーンショット」と位置づけました。最近の 報道 によれば、ノーステキサスの同社データセンターは、天然ガス発電所によって一部電力が賄われる見通しです。Alphabetは、次世代の地熱や原子力のような電源にも投資してきましたが、これらはまだ十分な規模で導入されていません。2024年にはデータセンターとオフィス向けエネルギーの66%がカーボンフリーの源から供給されており、計算(コンピュテーション)単位あたりの排出量も大幅に減少した一方で、温室効果ガスの総排出量は2019年から2024年にかけて54%増加しました。
- Amazonの直近の サステナビリティレポート で、同社は、AIを規模拡大するうえで最大の課題の1つがエネルギー需要の増加であると述べました。同社は、近隣のデータセンターのエネルギー需要を満たすために、ミシシッピ州とインディアナ州で天然ガス発電所に投資しています。原子力をカーボンニュートラルに到達するための戦略の重要な要素だと位置づけているものの、計画されている原子力発電の電源は2030年代まで稼働しない見込みです。その一方で、Amazonの総炭素排出量は2019年以来33%増加しています。
- Metaの直近のサステナビリティ レポート は、ネットゼロへの道筋は、新しい技術、サプライヤー、そしてグローバルな連合との連携に左右されることを強調しました。同社は、データセンターの電力を生み出すために 民間のガス火力発電所 を建設しており、これにはルイジアナ州の田園地帯にある同社最大規模(5ギガワット)の施設も含まれます。また同社は、風力・太陽光発電をよりうまく活用できるようにするための地熱、原子力、エネルギー貯蔵などを含め、2035年までに新規および既存のクリーンエネルギーとして最大6.6ギガワットを支えられる可能性のあるプロジェクトに投資しています。同社の総排出量は2020年から2024年にかけて60%以上増加し、データセンターによる電力消費はほぼ3倍になりました。
- Microsoftのこれまでのサステナビリティレポートでは、2030年までに自社が排出するより多くの温室効果ガスを除去することに向けた進捗が強調されていた一方で、直近の 版 では、この目標を「短距離走ではなくマラソン」だと説明しています。Microsoftは最近、チェブロンと合意に署名し、天然ガス発電所を建設 することにしました。これは、ニューヨーク州のスリーマイルアイランドで原子炉を再稼働させるための20年間の購入契約(2027年に稼働開始すると見込まれている)に署名した後でも行われたものです。2020年以降、Microsoftの総排出量は23%増加し、電力消費は2倍以上になりました。
ニュースの背景: 2015年のパリ協定(世界の温暖化を、産業革命以前の水準から2度摂氏上回ることに制限することを政府に求めるもの)の後の数年間で、多くの企業が、気候変動を遅らせることを意図した目標を達成するための企業としての誓約(コーポレート・プレッジ)を行いました。たとえば、2019年にAmazonとGlobal Optimismが共同で立ち上げた「The Climate Pledge(気候誓約)」には600社以上が署名しており、企業に温室効果ガスのネットゼロ排出を2040年までに達成することを約束させています。また、2015年に立ち上げられた科学的根拠に基づく目標(Science-Based Targets)イニシアチブも、パリ協定に整合する気候目標を企業に設定させることを求める別の企業間の取り決めです。主要なAI企業はこれらの原則を受け入れ、コミットメントを果たすための取り組みを記録する年次レポートを公開しています。
重要な理由: 2024年、データセンターは 電力消費の約1.5% を世界で占め、米国では4.4%を占めました。米国の数値は、今後数年で最大12%にまで上がる見通しです。大手AI企業はクリーンな電源から十分なエネルギーを得られると考えていたものの、最近の急激な需要増が、気候変動につながる温室効果ガスを排出する化石燃料への依存をさらに強めています。
私たちの見立て: 主要なAI企業は、風力や太陽光のような再生可能エネルギー、そして 原子力 や地熱といった次世代の電源に、実質的に投資してきました。しかし、これらの電源は依然としてスケール(規模拡大)に課題があるため、企業は増え続けるエネルギー需要を満たす手段として天然ガス発電所に目を向けています。これは懸念すべき傾向です。ただし、彼らが行っている作業量の規模に照らせば、きちんと運用されているデータセンターは依然として最も効率的な選択肢であり、AIにおけるさらなる効率改善が増加する排出量を相殺してくれることを期待しています。
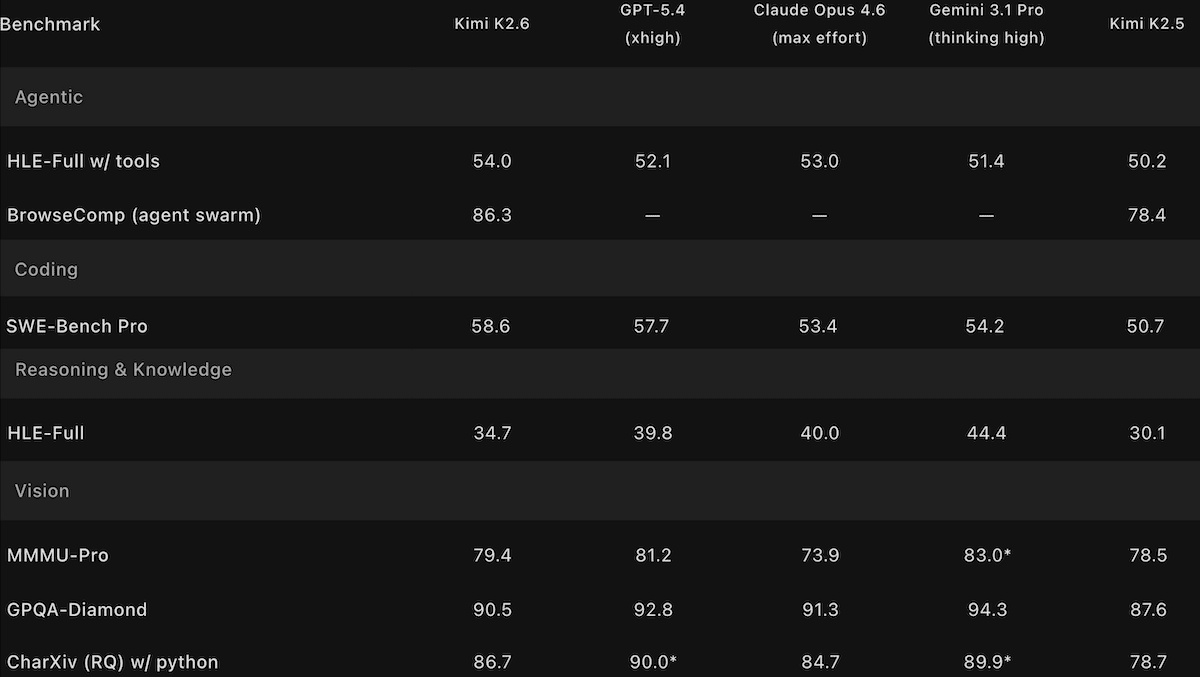
Kimi K2.6 Challenges オープンウェイト陣のチャンピオン
Moonshot AIの更新版Kimiモデルは、より長い自律的なコーディングセッションを扱えるようになり、前モデルに比べてマルチエージェントのオーケストレーションを拡張しました。
新しい点: Kimi K2.6 は、1兆パラメータの視覚言語モデルで、Qwen3.6 Max Previewや新たにリリースされたDeepSeek V4とほぼ互角の性能を示し、トップクラスのクローズドモデルにはわずかに及びません。これは、数日間続き得るプラン(計画)→書き込み→テスト→デバッグのループでコードを生成するように設計されており、単一のタスクに協働する何百ものエージェントを立ち上げることもできます。さらに、前モデルよりも幻覚(ハルシネーション)が少ないとされています。
- 入出力: 入力はテキスト、画像、動画(最大256,000トークン)、出力はテキスト(最大98,000トークン)
- アーキテクチャ: Mixture-of-experts、総パラメータ数1兆、1トークンあたりアクティブ320億、MoonViT視覚エンコーダ
- 機能: ツール利用、Web検索、ネイティブINT4量子化、「思考を保持」モード、エージェント・スウォーム
- 性能: Artificial Analysis Intelligence Indexで他のオープンウェイトモデルを上回る一方、主要なプロプライエタリ(クローズド)モデルには後れを取る
- 提供/価格: 重みは Hugging Face からダウンロード可能で、 改変MITライセンス の下で提供されます。これは、月間アクティブユーザーが1億人超、または月間売上が2,000万ドル超の製品について、帰属表示(アトリビューション)を条件に商用利用を許可するものです。加えて、kimi.com およびKimiモバイルアプリで無料のチャットインターフェースを提供し、APIはMoonshotで1,000万入力/キャッシュ済み/出力トークンあたりそれぞれ$0.95/$0.16/$4.00で利用可能です
- 未公表: 学習データおよび手法
仕組み: Kimi K2.6は、Kimi K2で導入されKimi K2.5で洗練されたアーキテクチャを流用しており、複数ヘッドの潜在注意(キーとバリューを圧縮することでメモリ要件を削減する注意の変種)や、MoonViT視覚エンコーダ(4億パラメータ)などが含まれます。Moonshotは、Kimi K2.6が学習データと手法の点でKimi K2とどう異なるのかについては開示していません。
- Kimi K2 ThinkingおよびKimi K2.5と同様に、Kimi K2.6はネイティブINT4量子化で学習されています。
- 思考を保持 オプションは、多ターンのやり取りにまたがって、以前に生成された推論トークンを保持し、Moonshotによればコーディング性能を向上させます。
- エージェント・スウォーム モードでは、コーディネータ・エージェントがタスクをサブタスクに分解し、最大300の並列サブエージェントを作成します。これらのサブエージェントは、4,000ステップ(Kimi K2.5では100のサブエージェントと1,500ステップ)を実行してタスクを進め、エージェントが失敗したり停止したりした場合は作業を再割り当てします。研究向けプレビュー機能である claw groups により、エージェント・スウォーム・モードを他の開発者のエージェントにも開放できます(任意のデバイスやモデルで実行可能であり、人間の協力者も含められます)。
性能: Kimi K2.6は、知能およびエージェント的な能力を測る一部のベンチマークにおいてオープンウェイトモデルのトップに立ち、人間の嗜好に関する主観的テストでも同業他社に比べて高い順位を獲得しています。しかし、大規模プロジェクトの推論やコーディング、ならびに人間の嗜好を評価するベンチマークでは、主要なクローズドモデルに後れを取ります。
- Artificial Analysisの Intelligence Index(経済的に有用なタスク10のテストをまとめた複合指標)で、推論(54)においてKimi K2.6はオープンウェイトモデルをリードしますが、xhigh推論(60)に設定されたGPT-5.5、max推論(最大の推論)に設定されたClaude Opus 4.7、および推論に設定されたGemini 3.1 Pro Previewには及びません。最も近いオープンウェイトの競合は、max推論に設定されたQwen3.6 Previewと、max推論に設定されたDeepSeek-V4-Pro(52で同率)です。
- Intelligence IndexにおけるKimiK2.6の順位は、GPQA Diamond(大学院レベルの科学質問に答える)、HLE(推論を試すために設計された、専門家レベルの学際的な質問に答える)、SciCode(科学研究のためのコードを生成する)においてオープンウェイトモデルの中で上位の性能を示していることに支えられています。とはいえ、5つの指標ベンチマークでは、新たにリリースされたオープンウェイトモデルDeepSeek-V4-Proにわずかに及ばず、残る2つのベンチマークではXiaomi MiMo-2.5-Proおよび他のオープンウェイトモデルに対して性能が下回りました。
- Moonshotは、Qwen3.5-0.8Bの推論コードをZig(システムプログラミング言語)に移植し、Mac向けに最適化するよう依頼することで、Kimi K2.6が大規模なコーディングプロジェクトを完了できる能力を検証しました。4,000回超のツールコールと、12時間以上にわたる14回連続の改訂の結果、Kimi K2.6は移植のスループットを1秒あたり約15トークンから193トークンへ引き上げ、同じハードウェア上で動く人気のローカル推論アプリであるLM Studioよりもおよそ20%速いところで終了しました。
- Artificial Analysisは、Kimi K2.6の幻覚率(一般知識の質問応答ベンチマークに基づく。誤りのある応答、無知の表明、応答拒否を含む不正確な出力の割合)を39.26%と測定しました。これはKimi K2.5(64.6%)より低く、概ねAnthropic Claude Opus 4.7(36.18%)と同程度です。
- Arena.aiのCode Arena WebDev リーダーボード(ブラインドなペアワイズ比較によってWeb開発のコーディング性能を順位付けする)では、Kimi K2.6(1,529 Elo)は67モデル中で第6位でした(2026年4月26日時点)。順位は、Anthropic Claude Opus 4.7(1,565 Elo)、Claude Opus 4.6(1,548 Elo)、およびZ.aiのオープンウェイトGLM-5.1(1,534 Elo)の後ろでした。
ニュースの裏側: 自律的な実行を数時間にわたってタスクに集中し続ける能力は、2025年末に競争上の最前線として浮上しました。AnthropicのClaude Code、OpenAIのCodex、AlibabaのQwen3-Coderはいずれも、最新リリースでこの能力を狙っていました。2025年7月にリリースされたKimi K2は、エージェント的なツール利用における初期のオープンウェイト参入組で、以降このファミリーは数か月ごとに更新され続けており、長期的な実行への重点が高まっています。
なぜ重要か: Moonshotは、Kimi K2ファミリーのモデルが自律的に有用な形でタスクを実行できる期間を着実に延ばしてきました。まずは短い推論の痕跡、次に複数ステップのツール利用、そして数時間に及ぶコーディングセッション、いまや複数日規模のプロジェクトです。こうした拡張のたびに、エージェントを軌道に乗せ続けるために必要な人間のチェックイン間隔は広がります。
考えています: 持続的な自律性と、幻覚(ハルシネーション)率の低さは関連していますが、その関連はますます弱くなっています。エージェントが間違いを犯しても、作業を確認し、誤りを見つけて、直すことができます。
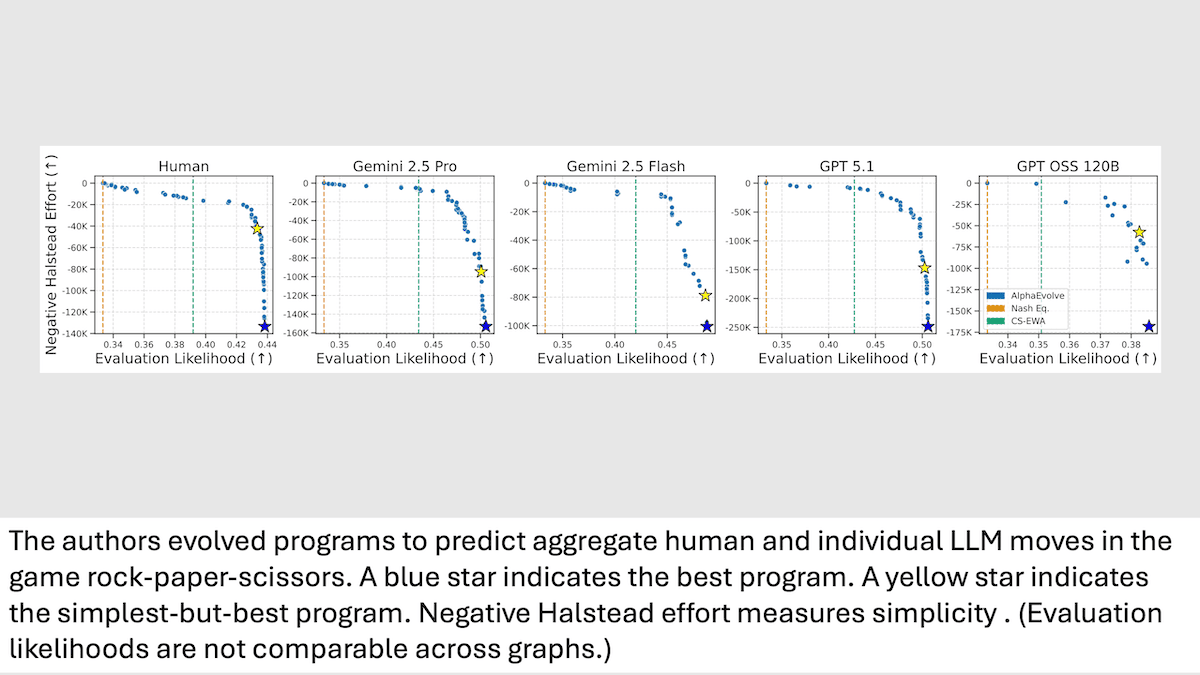
LLMにおける戦略的思考 vs. 人間
大規模言語モデルは人間らしい振る舞いをすることができますが、類似点は表面的なものです。単純な戦略ゲームを使うことで、彼らの戦略的アプローチにははっきりした違いがあることが明らかになりました。
何が新しい: オースティンのテキサス大学とGoogleのCaroline Wangらは、古典的なじゃんけん(グー・チョキ・パー)をしているときに 人間とLLMによる意思決定のパターン を解釈し、LLMは人が考えるよりも洗練された形で対戦相手をモデル化している場合があることを見出しました。
核心となる洞察: 記録された対戦データがあれば、LLMはプレイヤーの次の手を予測するコードを反復的に改良できます。もしそのコードがプレイヤーの行動をかなりの精度で予測できるなら、その意思決定アルゴリズムは、プレイヤーが使っていたものと機能的に同等であると仮定できます。コンピュータコードは解釈可能であるため、そのようなアルゴリズムを見抜き、人間とLLMが用いるものを比較することが可能です。
仕組み: じゃんけんゲームにおいて、著者らは個々のLLM(Gemini 2.5 Pro、Gemini 2.5 Flash、GPT-5.1、GPT-OSS 120B)を、複雑性の異なる15種類の事前プログラム済みボットそれぞれと対戦させました。そして、各プレイヤーの手を、それぞれ300ラウンドから成る20ゲーム分記録しました。先行研究では、同じボットとの対戦における人間同士のゲームについての類似の 記録 が提供されていました。著者らは、各プレイヤー—AIと人間の両方—がラウンドごとに選んだ手と、その結果が勝ちか負けか引き分けかを追跡しました。次に、 AlphaEvolve(進化的プロセスによってコードを反復的に最適化するエージェント的手法)を用いて、各LLM個別および人間の集団について、次の手を予測するPythonプログラムを改善しました。
- AlphaEvolveはまず、著者らが書いた単純なテンプレートプログラムを使ってゲームデータを処理しました。明かされていない数の各進化ステップのそれぞれにおいて、Gemini 2.5 Flashは、単純さ( Halstead effortによって測定される)と、評価がどれだけ起こりやすいか(プログラムがプレイヤーの選択をどれだけうまく予測したか)を釣り合わせる関数を改善するための修正案を提案しました。
- 各プレイヤーについて、著者らは、最良のものからわずかな許容誤差内で最大予測精度に近い値を達成した、最も単純なプログラムを選びました。それぞれのプログラムは、予測対象として進化させられたプレイヤーに対して最良の評価のしやすさ(高いほど良い)を生み出しました。つまり、それは対応するプレイヤーの振る舞いを、他のどのプレイヤーよりも適切に表していました。
結果: AlphaEvolveが処理していないゲームデータを用いて、著者らは各プログラムが他のプレイヤーの手をどれだけうまく予測できるかを比較しました。その後、プログラムを調べて、それぞれのプレイヤーがどんな戦略を用いていたのかを特定しました。
- Gemini 2.5 Pro、Gemini 2.5 Flash、GPT-5.1を表すプログラムは、ボット相手にプレイする局面でも、互いの手を予測する際の成績がほぼ同等でした。これは、この3者が類似した戦略を使っていたことを示唆します。たとえば、Gemini 2.5 Proの行動を予測した場合、Gemini 2.5 Proを予測するプログラム、Gemini 2.5 Flashを予測するプログラム、GPT-5.1を予測するプログラムはいずれも、それぞれ0.507、0.507、0.506の評価のしやすさを達成しました。一方で、人間やGPT OSS 120Bを表すプログラムは、この3者の行動をよりうまく予測できませんでした。達成した評価のしやすさはそれぞれ0.476と0.403であり、おそらく異なる戦略を用いていたことを示しています。
- プログラムを解釈すると、Gemini 2.5 Pro、Gemini 2.5 Flash、GPT-5.1は、人間やGPT-OSS 120Bよりも、より効果的に逐次的なパターンを維持していることが示唆されました。それらのプログラムを予測するコードは、プレイヤーの直前の1〜2手に基づいて、各可能な手が出される頻度を追跡していました。つまり、3ラウンドにわたってプレイヤーが「グー→チョキ→グー」や「グー→チョキ→パー」といった系列を、どれくらいの頻度で呼んだかを追跡していたのです。これに対し、人間やGPT-OSS 120Bを表すコードは、相手の最新の手の頻度だけを追跡していました。
- Gemini 2.5 Pro、Gemini 2.5 Flash、GPT-5.1、そして人間のプレイヤーを表すコードは、各可能な次の手について、(i)その可能な次の手、(ii)ボットの直前の手、(iii)プレイヤーの直前の手に基づいて、次の手の暫定的な値を計算していました。GPT-OSS 120Bは、可能な次の手だけに基づいて値を計算しました。
重要な理由: 研究者たちは、理解するための方法や、ある種の
ニューラルネットワークの挙動の
重要な理由: 研究者たちは、理解するための方法や、一部の
側面の
重要な理由: 研究者たちは、理解するための方法や、ある種の 側面 を把握する方法などを見つけてきましたが、それでも大規模言語モデル(LLM)は、多くの点で依然としてブラックボックスです。LLMの挙動から直接コードを統合(生成)することは、意思決定を解釈するための強力な手段を提供します。
考えていること: LLMが、学習データに表されている人間の振る舞いを模倣することを学ぶのだと考えるのは、つい飛びついてしまいがちです。しかし、平均的な人間よりも体系的にゲーム戦略を符号化できることが分かったというのは、別種の学習が行われていることを示しています。



