
[MTP Drafter] LLM高速化技術の裏側 〜隠されざる下書きコストの天秤〜

2026年5月5日、GoogleのオープンLLMであるGemma 4向けにその推論速度を引き上げるMTP drafterがリリースされました。
MTP Drafterを利用すると、品質劣化なしに最大で3倍の高速化が可能となると言います。
これまで、推論速度を引き上げたければ、ハードウェアを強化するか、品質を犠牲にしてモデルのサイズを小さくするか、または、従来とは全く異なる構造のLLMを使うなどがありました。
しかし、今回発表されたMTP Drafterは元のGemma 4の品質を一切劣化させずに速度だけ引き上げることができます。
これはどのようにして実現したのでしょうか。
今回は、Googleの発表した技術記事『Accelerating Gemma 4: faster inference with multi-token prediction drafters』を読みます。
LLM推論の基本
これは、皆さんご存知だと思いますが、LLMは文章を生成する際、1単語(トークン)ずつ、順番に生成しています。厳密にはトークンと呼ばれる単位で処理されますが、ここではわかりやすく単語として説明します。

一気に複数単語ずつ生成できたら速いのですが、なぜ、1単語ずつしか生成できないのでしょうか?
それは、新しいトークンを生成するには、それまでに生成された全てのトークンが必要になるためです。
「吾輩」の次は「は」の可能性が高いと計算
「吾輩 は」と続いたら、次は「猫」の可能性が高いと計算
「吾輩 は 猫」と続いたら、次は「で」の可能性が高いと計算
このように、予測のたびに単語が積み上げられていき、その単語の積み上げの上で次の1単語を予想するという仕組みとなっています。
自分の生成した出力が次の生成のための入力になる構造を、専門的には自己回帰と呼びます。または逐次処理とも呼びますね。
もしも、「吾輩」だけから、「は 猫 で」を一気に予測しようとするとどうなるでしょうか。1単語先ではなく、3単語先までを一気に予測する場合、膨大なパターンを一度に考慮する必要があります。
LLMが知っている単語の数が$${N}$$だとしましょう。
1つずつ単語を確定させていけば、次の単語の候補は$${N}$$個であり、$${N}$$個の中から最も確率が高い単語を選べばよいですよね。
しかし、2つの単語の組み合わせを一度に選ぶとなると$${N \times N}$$個の単語の組み合わせから最も確率が高い単語を選ばなければなりません。
そして、3つの単語であれば、$${N \times N \times N}$$個の組み合わせです。このように、複数単語を同時に生成するのは、候補の組み合わせが爆発的に増大し、実質的に予測不能となってしまうのです。
平等な労力が無駄を生む
ここで一つ気になることがあります。
従来のLLMは単語の予測の際に、全ての単語を同じ労力で予測しています。
「吾輩」の次に来るものを予測する場合、名詞の次はほぼ確実に助詞が来るので、数がそこまで多くない助詞の中(は、の、がなど)だけを探索すれば良いですよね。
吾輩 は ?
吾輩 の ?
吾輩 が ?
吾輩 も ?
吾輩 を ?
次に来る言葉は限られている
一方で、「吾輩 は」の次を予測する場合、広大な種類がある名詞(猫、犬、人)、動詞(歩く、見た)、そして形容詞(眠い、静か、空腹)、副詞(ようやく、ふらふらと)、連体修飾など、色々と可能性があります。
吾輩 は 犬 ?
吾輩 は 歩く ?
吾輩 は 眠い ?
吾輩 は ふらふらと ?
吾輩 は 主人 の 家 に ?
… 可能性のある言葉は膨大
このように、言語学的に見れば、次に来る可能性のある言葉が限られてる時もあれば、多様な選択肢がある時もあるのです。しかし従来のLLMでは、探索するべき範囲が全く異なる予測であっても、全て平等な計算で全てを探索する構造となっています。

この平等で無駄な計算労力、なんとかしたいですよね。
実は以前からあった2つの技術
ここまでの説明の通り、LLMを高速化する鍵は2つあります。
LLMは1度に1単語ずつしか生成できないから遅い
⇒ 複数同時に生成できる仕組みを考えるLLMは全ての単語を平等に推測するから遅い
⇒ 単語の種類ごとに推測範囲を狭める仕組みを考える
実はこの高速化の仕組み、数年前に既に登場し、実際に様々なLLMで使われています。
1. 複数同時に生成する仕組み
まず、複数単語を同時に推測させる仕組みについて見ていきましょう。
今から3年以上も前の2022年11月に、Googleの研究者は、『Fast Inference from Transformers via Speculative Decoding』という論文を発表しました。
【論文情報】
Leviathan, Yaniv, Matan Kalman, and Yossi Matias. "Fast inference from transformers via speculative decoding." International Conference on Machine Learning. PMLR, 2023.
この論文では、Drafting(下書き)を使って、推論を高速化する手法が提案されました。この手法は「投機的デコード」と呼ばれます。
下書きによる先読み
投機的デコードでは2つのLLMを利用します。
本書き用LLM:非常に大きくて高性能だが、動きが遅いモデル
下書き用LLM:性能はそこそこだが、小型で非常に高速に動く
まず、下書きLLMが、「吾輩」に続く単語を数個生成します。これは普通の逐次処理のため、1単語ずつの生成ですが、下書きLLMは非常に小さいモデルなので、高速に推測できます。

下書きができたら、本書きLLMの出番です。
本書きLLMを使って、先ほど下書きした単語と同じ場所を、再度一斉に生成します。「吾輩」の次だけでなく、下書きによって予測済みの、「は」の次、「猫」の次、「で」の次も一緒に生成するのです。
すなわち、以下を1 stepで実行することができます。

大きくて重たい本書きLLMですが、下書きを使えば1回の推論で複数単語を同時に生成することができるため、1単語ずつ推論するよりもその分時間が短縮されるのです。
ただ、これが成立するには下書きが本書きと同じであるという前提が必要です。つまり、この作業は、下書きLLMで生成された内容が、本書きLLMでも同じく生成されるかを検証する作業と言えます。
上手いこと、本書きLLMの結果が下書きLLMと一致していた場合、その結果をそのまま出力として採用できます。
しかし、一致していなかった場合は、不一致となった地点よりも後ろは誤った下書きの上で推論された単語であるため不採用にして、それ以前の部分だけを出力として確定させます。その後、先ほどの不一致した箇所を新しい最後尾と置き直して、再び次の下書きの生成を行います。
例えば、下書きLLMが「吾輩」「は」「犬」「で」「ある」と下書きしたとしましょう。ここで、本書きLLMの方は、「犬」ではなく「猫」と生成した場合、不一致と判定されます。すると、下書き「犬」をもとに推論した「と」「ない」は、誤った下書きに基づく推論なので、出力せずに破棄します。

「猫」までは正しい下書きの上で生成されたものなので、問題なく出力できます。ですので、次のサイクルでは、出力が確定した単語の後ろから同じく数単語分の下書きを生成することになります。そして、下書きしたらまた本書きLLMで検証するというように、繰り返します。

このように、投機的デコードは、この下書きと本書きのサイクルを繰り返していくことで、テキストの生成を進めるプロセスとなっています。
本書きと下書きの生成が一致していれば、本書きLLMは同時に複数単語を生成できるので、同時生成の数だけ倍速になります。3単語同時生成ならば、3倍速ということです。
仮に、本書きと下書きが全て不一致であっても、本書きLLMが推論する最初の1単語だけは下書きに左右されない純粋な推論なので、1サイクルの中で最低でも1単語は必ず出力として確定されます。
つまり、不一致の場合でも普通の逐次処理と同じ速度(1推論で1生成)、運よく一致すれば、その分だけ倍速(1推論で複数生成)になる。というわけです。
ちなみに、複数単語を同時に推論すると、1単語を推論するのと比べて1回あたりの計算時間が遅くなるのではないか?と思う人もいるかも知れません。
確かに、複数単語を同時に推論すると、1単語よりも計算量は増えます。しかし、実際にかかる時間は殆ど変わらず、むしろ同時に複数さばける分、高速になるのです。これは、LLMを実行しているGPUの特性によるものです。GPUは演算ユニット(コア)を大量に持っているため、単純な計算を同時に並行して処理するのが得意です。通常通りの1単語ずつの推論だと、並列が得意なGPUの能力を活かせていないのです。GPUでは推論毎にメモリからコアへとデータを運ぶ(これがそこそこ時間がかかる)のですが、せっかく運んだのに1単語しか推論しないのはもったいないと思いませんか?この時、複数単語を同時に推論することができれば、GPUの持て余していた余力が活かされ、1回のデータ転送に対する演算効率も上がり、トータルの生成時間が削減できるのです。
品質を保証した高速化
この高速化手法が優れているのは、出力される文章の質が劣化しないという点です。最終的に出力を決めているのは変わらずに賢いモデル(本書きLLM)自身であるため、結果は変わらないのです。
2.全単語を平等に探索しない仕組み
最初に書いた通り、LLMの単語予測は、数十万もある膨大な数の単語辞書を毎回ひとつずつ調査する作業です。これは専門用語でロジット計算と呼ばれ、非常に重たい作業です。1単語生成する毎に、毎回辞書を全件探索するのですから大変ですよね。
そこで、全単語を総当りで探索するのではなく、明らかに可能性の高いところから探索しようという仕組みが考えられました。
実際には、2017年にMeta(旧Facebook)が発表した論文『Efficient softmax approximation for GPUs』にAdaptive Softmaxという仕組みが提案され、実用的に使われるようになりました。
【論文情報】
Joulin, Armand, et al. "Efficient softmax approximation for GPUs." International conference on machine learning. PMLR, 2017.
この仕組みでは、あらかじめ単語をその出現頻度ごとにグループ分けしておきます。推論の際は、まず次に来る単語がどのグループに所属するかを予測します。そして、予測したグループの中の単語だけ探索するのです。
例えば、高頻度な単語と予測した場合は高頻度グループの単語だけを評価します。これにより、全ての単語を評価する必要がなくなり、計算コストを一気に抑えることができます。
イメージとしては、よく使う単語は辞書の前の方まとめて整理して、めったに使わない単語は辞書の奥の方にまとめるというように整理することで、高速に探索できるようにするという形ですね。
この方法は言語学の観点からも理にかなっています。なぜなら、自然言語において、実際に使う単語はほぼ同じものばかりであり、レアな単語を使うことは本当にレアだからです。
ジップの法則というのを聞いたことがあるでしょうか。多くの言語において、単語を出現頻度順に並べた場合、その順位と規模(使われる量)はおよそ反比例の関係になるという経験則です。例えば、出現頻度1位の単語は2位の単語の約2倍利用され、10位の単語の約10倍利用されるということを示しています。実際にこの論文では、自然言語における全単語のわずか20%が、文書全体の約87%をカバーする偏りがあると書かれています。
実際によく使う単語が全単語の一握りの単語であるということを考えれば、初めから頻度毎にグループ分けしておいて、そのグループの単語だけ見るというのは非常に効率的であるということがわかりますね。
Gemma4での統合と洗練
さて、ここまで見てきた2つの仕組みは既存の技術として他のモデルでも使われています。では、今回、Gemma4向けのMTP Drafterは何が新しいのでしょうか。
1. 洗練された投機的デコード
従来の投機的デコードでは、本書き用LLMと下書き用LLMはそれぞれ独立して推論計算をするのが一般的でした。
しかし、Gemma 4では、これら2つのLLMが密接に結合されています。
入力エンベディングの共通化
両方のLLMは単語を数値列(ベクトル)に変換するための辞書(入力エンベディングテーブルと呼ぶ)を共有して同じ物を利用します。
つまり、『猫』という単語をコンピュータが計算できる数値列に変換する際に下書きLLMも本書きLLMも必ず同じ数値列に変換されるのです。
これにより、下書きと本書きとで単語の捉え方にズレが生じにくくなります。そして、下書きと本書きの不一致が起きる確率を下げ、高速化が作用しやすくするのです。本書きLLMの計算内容を使って下書きする
こちらはGemma4で取り入れられたとてもユニークな技術です。下書きLLMは、本書きLLMの最後のレイヤーから出力された計算途中の特徴量を直接受け取って、自分の予測に役立てます。いわば、本書きLLMの思考をカンニングしながら下書きをしているようなもので、これにより予測精度が飛躍的に高まっています。本書きLLMのKVキャッシュを下書きLLMで利用する
LLMは通常、これまで生成した情報をKVキャッシュという形で保持しています。投機的デコードでは、下書きと本書きの不一致がおきた時、不一致の後ろから再度下書きを始める必要がありますが、この時、一致時点までの本書きのKVキャッシュを利用して下書きをすることで、その地点までの計算を再度行わなくても良いようにしています。
また、洗練された点は、LLM間の結合だけではありません。
下書き量の自動調整
何個まとめて下書きするかという1サイクルあたりの生成単語数を、テキスト中の場面に応じて自動的に調整します。前回のサイクルで下書きが全部採用されれば、今の地点は比較的、小型モデルでも正答率が高くなる簡単な文書だと判断し、一度に下書きする量を増やします。逆に一致しなくなると、今は下書きモデルの能力では難しそうなので慎重に進めようとして一度に下書きする量を減らします。このようにして、高速化出来そうな時は加速し、不一致が多発しそうな地点では、堅実にという制御が成されるのです。
2. 進化した探索範囲の絞り込み
先ほどのAdaptive Softmaxもそのまま実装されているわけではありません。
スマホなどリソースが限られた環境を想定されたGemma4のE2B/E4Bモデルでは、より細かなグループ分けを採用したEfficient Embedderが導入されています。
意味ベースでの詳細なグループ分け
LLMを学習する際に、似たような意味や使われ方をする単語を、グループにまとめます。
例えば、以下のような形です。
-【果物】グループ:「リンゴ」「バナナ」「ミカン」など
-【動詞(運動)】グループ:「走る」「泳ぐ」「投げる」など
-【プログラミング言語】グループ:「Python」「Rust」「C++」など
そして、推論時は、可能性の高いグループをまず予測し、そのグループの中の単語のみを評価します。
これにより、評価対象の単語の数を劇的に絞ることができるようになっています。
投機的デコードでは下書きを素早く作る事が重要となりますが、下書きLLMがどれほど小型なモデルであっても数十万の単語を全て探索するのにそれなりの時間がかかります。特にスマホなどの計算資源が少ない端末(E2B/E4Bモデルの対象環境)で実行しようとすると、下書きを導入したことがかえって、速度低下の原因となってしまったと言います。この単語の探索範囲を絞る技術は、投機的デコードの下書きコストを減らし、高速化効果を際立たせる重要な役割を果たしています。
Gemma4 MTP Drafterの力
ここまで見てきて、MTP Drafterは魔法の杖のように、とりあえず使っておけば高速化するように聞こえますよね。
本当にそうなのか、実際に試してみましょう。
今回は、無料で利用できるGoogle Colabの汎用的なT4 GPUを使って検証しています。なお、T4 GPUは2018年にリリースされた古いGPUです。現在主流のGPUと比べると性能が非力である点はご了承ください。
検証するモデルはスマホなどの計算資源が少ない環境で動作させることを想定したE2Bモデルです。
LLMの設定では、出力サンプリング(do_sample)を無効とし、確率が最も高い単語を出力する方式を使います。
また、評価値は同じ条件での測定を5回繰り返して平均した値です。
試すプロンプトは『猫が101匹登場する物語を書いてください。』とします。
結果は以下の通りでした。

MTP Drafter(投機的デコード)を使った方が遅くなっていますね。
その差、約1.6倍です。
実は、投機的デコードには、場合によって遅くなる罠があるのです。
先ほどの説明の通り、投機的デコードは、下書きLLMの実行と本書きLLMの実行の2段階の推論を行います。
つまり、トータルの実行時間は以下のようになります。
トータル時間$${t_{s}}$$ = 下書きの時間$${t_d}$$ + 本書きの時間$${t_{as}}$$
投機的デコードを使わなければ、そのまま本書きLLMの時間だけですよね。
トータル時間 $${t_{u}}$$ = 本書きの時間$${t_{au}}$$
その時間差(削減時間)は以下のようになります。
削減時間$${(t_u - t_s)}$$ = 本書きの削減時間$${(t_{au} - t_{as})}$$ - 下書きの時間$${t_d}$$
この式より以下の関係が成り立つことがわかります。
本書きの削減時間 > 下書きの時間 ⇒ 削減時間はプラス(削減成功)
本書きの削減時間 < 下書きの時間 ⇒ 削減時間はマイナス(時間増加)
すなわち、投機的デコードの成果は、本書きLLMの削減時間と下書きLLMの実行時間の天秤の上で成り立つのです。
本書きLLMの削減量は、どれほど下書きと本書きが一致するか?で変動します。1つも一致しない場合は、削減量は0であり、ただただ下書きLLMの実行分だけ時間は伸びてしまいます。一致率が上がれば、本書きLLMが同時に推論する単語の数が増え、本書きLLMの実行時間が削減されていきます。
今回のプロンプトは、物語を書かせるという自由度と創造性の高いタスクです。どんな単語だって使えますし、生成される物語の選択肢は無数にあります。そのため、2つのLLMの結果が一致する可能性は低く、実際に一致率は11.2%とほぼ空振りしています。
また、この実験からもう一つの面白い特性がわかります。MTP Drafterを使う場合と使わない場合で、生成された単語数が異なっています。最終的に出力を決めているのは同じ本書きLLMであり、出力の品質差は無いはずでしたよね。
実は、実際の実装において、下書きと本書きが一致しているかの評価が、完全な一致でない場合があります。これを緩和投機的デコード、または近似投機的でコードと呼びます。
下書きLLMは次は「犬」だと言い、本書きLLMが「猫」だと言ったとします。本来の投機的デコードであれば、不一致したので改めて下書きをやり直しますよね。しかし、緩和投機的デコードでは、以下の2つの条件をクリアすれば、例外的にそのまま下書きを正として推論を続けて良いとしています。
下書きLLMが「犬」を求めた際の確信度(その位置が犬である確率値)があるしきい値より大きい
本書きLLMの中で「犬」の確信度(その位置が犬である確率値)があるしきい値より大きい
つまり、本当の本書きの確信度1位は「猫」だけど、「犬」も確信度は高いし、下書きでの確信度も高いから許可しよう、ということです。
一致はしてないけど、本書きLLM的に見ても出る確率の高い単語だから品質を落とすほどの差ではないと考えるのです。
今回の実例を見てみましょう。
生成の中で一番最初に食い違いが発生した場所は以下の「一匹目の猫は」と「一番最初に現れたのは」という箇所です。意味的には同じですが、異なる表現になっています。一部表現が変わると、LLMはそこまでの生成内容を元に次の単語を予測するので、この微妙な差が枝分かれ地点となり別の道に進んで行きます。結果として、最終的文章も少し違ったものとなります。
【MTP Drafterなし】
一匹目の猫は、純白の毛並みをしており、まるで雪が形になったかのようだった。彼は静かに目を閉じ、谷間の朝露を浴びていた。
【MTP Drafterあり】
一番最初に現れたのは、純白の毛並みを持つ、優雅な「雪」だった。雪は、周囲の苔をそっと撫で、静かに森の息吹を感じ取っていた。
本書きLLMが推測する結果を基準に採用しているので、品質が劣化しないことは確かですが、緩和投機的デコードにおいては、一字一句完璧に同じ結果を保証するという意味ではないということに注意しましょう。あくまで、人間が見た時の品質が維持されると解釈すると良いと思います。
更に実験を進めていきます。
次は、回答の選択肢の幅が狭い、簡単なプロンプトを試してみましょう。
『あなたはAIですか?猫ですか?答えの後に理由を述べてください。』
明確な答えがある質問なので、回答の方向はかなり固定されるはずです。

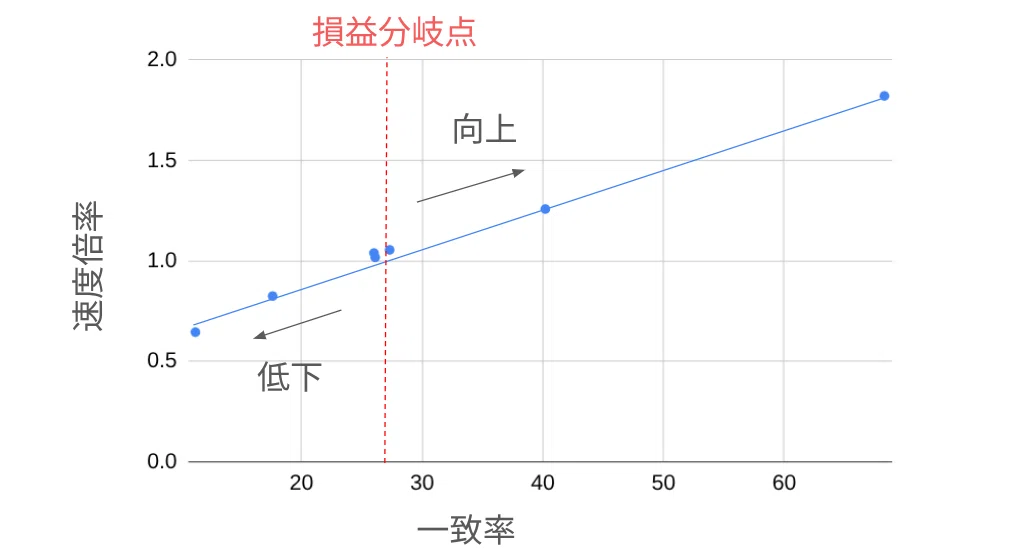
結果を見ると、ほとんど同じ速度になりました。一致率を見ると26.0%と先ほどのプロンプトよりも上昇しています。
この結果より、T4 GPU x E2Bモデルにおいては、一致率26.0%付近が損益分岐点ということがわかります。
これより一致率が低くなるプロンプトでは、MTP Drafterを使うと損します。
MTP Drafterの真価はまだ発揮できませんね。日本語だから一致率が上がりにくいのでしょうか?
次に、このプロンプトを英語にして、英語での生成にしてみましょう。
『Are you an AI? Or a cat? Please explain your reasoning after your answer.』

僅かに一致率が上がっていますが、明らかな差があると言えるほどの結果ではありません。単に英語にすれば改善するというものではないことがわかります。
次に、決まった回答へと誘導するプロンプトで実験します。
『次の言葉から始まる早口言葉を3回ずつ繰り返してください。なお、それ以外の出力はしないでください。1.かえるぴょこぴょこ… 2.あかまきがみ... 3.となりの客は...』
指示した言葉を繰り返すだけなので、生成されるべき文章の自由度はほぼありません。

遂に、MTP Drafterを使うことで高速化されました。約1.26倍の高速化です。一致率も約40.2%と高い値となっていることがわかります。
テンプレートをなぞるだけのような、回答の自由度がない場合において、威力を発揮しやすいようですね。
生成された内容もみてみましょう。以下の通り、早口言葉を完成させずに、プロンプトで示した冒頭のみを3回繰り返しています。単に示された言葉をなぞるだけなので、一致率が高くなるのも頷けます。
かえるぴょこぴょこ かえるぴょこぴょこ かえるぴょこぴょこ
あかまきがみ あかまきがみ あかまきがみ
となりの客は となりの客は となりの客は最後に、プログラミングの場合を見てみましょう。以下の通り、Pythonプログラムを生成させます。要件を細かく指定しているのがポイントです。
『pythonでdatetimeライブラリを利用して、今から3日後の日時を「YYYY-MM-DD HH:MM:SS」の形式で標準出力する関数print_3_days_later()を作成してください。関数以外は出力しないでください。解説やコメント文は不要です。』

一致率は68.3%を記録し、約1.82倍の高速化を実現しました。
プログラミングでは構文が厳密なため、回答の自由度は一気に下がります。
コーディングスタイルなども細かく指定すれば、安定した高速化を実現できるでしょう。
実際に生成されたプログラムは以下の通りです。プロンプトの内容を理解して、新たにコードを創造しています。このような創造的なタスクでもプログラミングのような書き方が限定的な創造であれば、一致率は高くなることがわかります。
from datetime import datetime, timedelta
def print_3_days_later():
future_date = datetime.now() + timedelta(days=3)
formatted_date = future_date.strftime("%Y-%m-%d %H:%M:%S")
print(formatted_date)ここまでの結果でわかることは、MTP Drafterはタスクに応じて使い分けるのが良いということです。
最初の猫の物語を生成するような創造的なタスクのように、下書きの空振りが多くなると、むしろ遅くなるのです。
高速化を実感するには、プログラミングでの利用やプロンプト内で例示をするなど、具体的に何を生成するべきかが定まっている使い方が良いでしょう。
今回の実験環境 T4 GPU + E2Bモデルでは、打率が26%を超えると高速化効果が下書きのコストを上回ります。
とりあえずMTP Drafterを有効にするのではなく、自身の環境において、どこが損益分岐点か、実行しようとしているタスクがMTP Drafterに適しているかを見極めることが大切になるということがわかりました。
まとめ
今回は、最新LLMであるGemma 4の高速化技術『Accelerating Gemma 4: faster inference with multi-token prediction drafters』を読みました。
その中身は、従来からある投機的デコードの仕組みをより洗練させた実装となっていました。
投機的デコードは足の速いモデルに下書きをさせ、賢いモデルがまとめて添削するという役割分担が、高速化の肝となっています。
下書きを土台にすることで賢いモデルは複数単語をまとめて推論できます。
出力自体も賢いモデルにより評価された結果なので、品質の劣化もありません。非常に理にかなったスマートな仕組みですよね。
そして、高速化の度合いは下書きの精度により変化します。どれだけ、下書きLLMの推論内容が本書きLLMと一致するかが重要で、それはプロンプトの内容(タスク)によって変わるのです。
プログラミングや翻訳など、出力の自由度が少なければ一致しやすく、物語生成や会話などの自由な生成ができるタスクでは、一致しにくくなります。
そして、今回の実験からは、一致率が低くすぎる場合、下書きのコストが足を引っ張り遅くなる場合もあることもわかりました。
技術の仕組みを知ると、挙動の理由が明確にわかります。新たな技術を目にするとキラキラしたメリットばかりに目が行きがちですが、不測の事態を防ぐためには、その挙動を見極めて扱うことが大切です。
様々な仕組みが日々登場するAI界隈、なぜ?本当に?という視点が一層大切になるでしょう。




