親愛なる皆さん、
先週末、学習アルゴリズムを使わないことにしました。時には、機械学習を使わない方法のほうが最適です。
娘が2歳を少し過ぎていて、しかも行動範囲が非常に広いので、階段に近づかないようにするベビーゲートが常に閉まっていることを確実にしたいのです。通り抜けるときについ忘れて、開けたままにしてしまうことが簡単に起きます。皆さんはどうしていますか?
そこで私は、ゲートが開いている状態と閉じている状態の両方の画像を集め、それらを区別できるようにニューラルネットワークを学習させるシステムを設計し始めました。次に、そのモデルをTensorRTを使ってRaspberry Piコンピュータ上にデプロイし、60秒以上開けたままだったらビープ音を鳴らすようにするつもりでした。

私は配線まで進めました。すると、冷蔵庫のドア用アラートウィジェットが目に入りました。これは、磁石が検出器から離れたときに同じ仕事をしてくれるものです。
これは、時には大きなニューラルネットワークが不要だということを示しています。(でも、本当に必要なときもあります。その場合は便利です。)だから、いろいろな技術の手札を持っておくのは良いことです。そうすれば、与えられた仕事に対して最適なものをよりうまく選べます。
ここでの教訓の一つは、適切なセンサーを選ぶことかもしれません。カメラでやろうとすると、コンピュータビジョンのアルゴリズムが必要でした。しかし磁気センサーなら、ゲートが開けたままだったときにビープ音を出す判断は、簡単です。
学び続けましょう!
Andrew
News
 |
Medical AI Gets a Grip
手術ロボットは、人の管理のもとで毎年何百万もの繊細な手術を行っています。今、それらは自分自身で手術できるよう準備を始めています。
何が新しいのか:UCバークレー、UCサンフランシスコ、SRIインターナショナルの研究者たちは、手先の器用さ、正確さ、スピードを試すタスクを通じてダ・ヴィンチ の2つのアームを持つ手術ロボットを操縦するために、機械学習システムを訓練しました。ニューヨーク・タイムズが報じています。
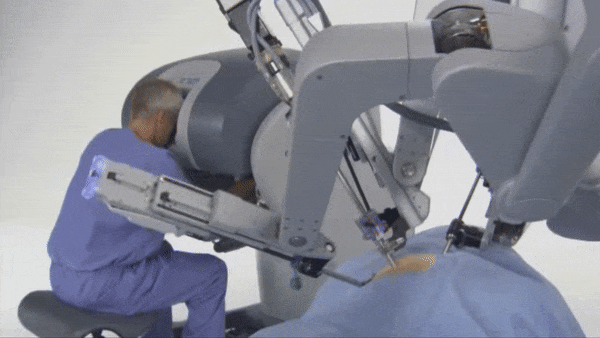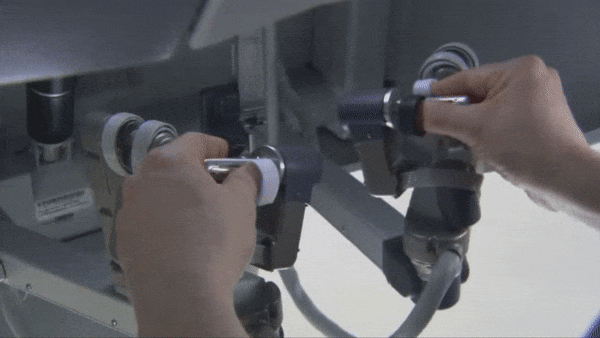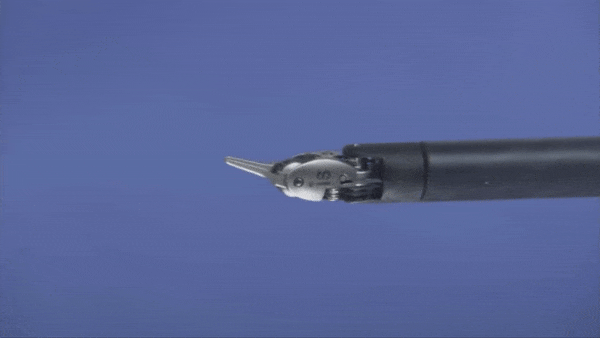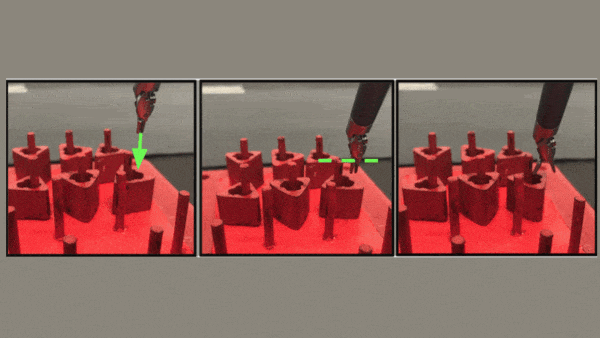
仕組み:このシステムは模倣学習によって、小さなプラスチックのリングをペグボードの上から持ち上げ、あるクローから別のクローへと渡し、さらにそれらを異なるペグの上へスライドさせることを学びました。このタスクは、腹腔鏡手術を行うことを学ぶ外科医のための練習にもなっています。腹腔鏡手術では、カメラやその他の専用の器具が、小さな切開を通して患者の体内に挿入されます。
- 著者らは、人間の外科医がロボットを使って誤りとその修正方法を実演するための、180本のRGBD(赤・緑・青+深度)動画クリップに加えて、ロボットの関節位置に関する情報を用いて、4つの畳み込みニューラルネットワークのアンサンブルを訓練しました。システムはタスクの実行を学習しましたが、時間が経つにつれて精度が低下しました。ロボットの四肢を動かすケーブルが伸びたことで、モデルが目標を外してしまったためです。
- 精度の低下が進行するのを補うために、著者らは、機械が自律的にランダムな動きを行った際のロボット関節位置のモーションキャプチャデータに対してLSTMを訓練しました。
- この2つのモデルを合わせることで、リングとペグのテストにおいて、人間の外科医よりも機敏で、正確で、迅速であることが示されました。
ニュースの背景:AIはすでに、いくつかの小さいながらも重要な手順で医師を支援しています。たとえばオランダ企業Microsureのロボットツールは、血管の微小な切開を縫合するのを助けますが、同時にAIを使って術者の手の震えを安定化させます。
なぜ重要か:これは、ロボット制御において概念ドリフトを扱うアルゴリズムの良い例です。モデルベース強化学習の多くの研究では、固定されたモデルを前提としています。しかし、人の腕は疲れるとダイナミクスが変わるように、そして外科医はその疲れていく腕を制御するために適応しなければならないように、ロボットのダイナミクスの緩やかな変化に対して学習アルゴリズムも適応してほしいのです。
私たちが考えていること:私たちは、栄養、運動、そして睡眠の最適化を手助けしてくれるAIシステムに注目しています。メスを振るうAIシステムから私たちを遠ざけるために!
 |
クロスワードは囲碁の道を行く
深層学習と記号(シンボリック)AIのハイブリッドが、大規模なパズル競技で優勝を果たしました。
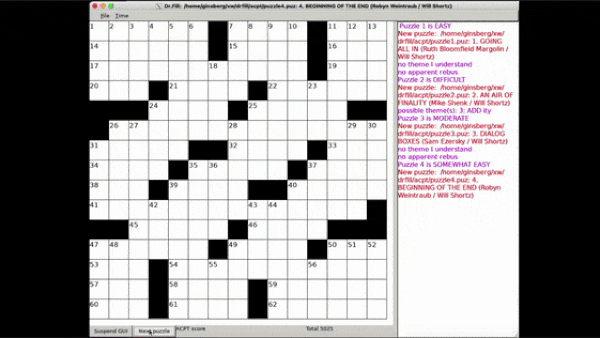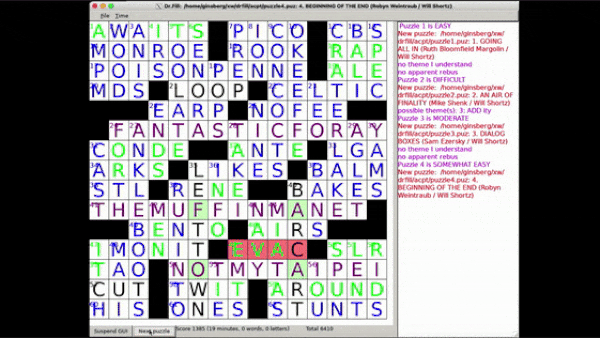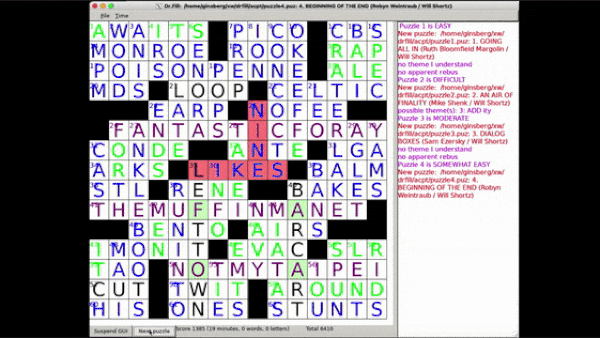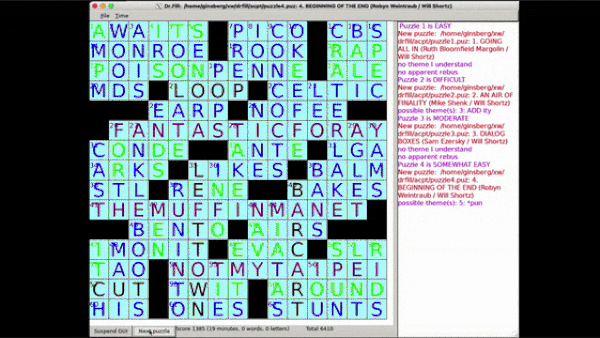
新着: 4月に開催された年次のAmerican Crossword Puzzle Tournamentで、Dr. Fillというシステムが人間の出場者約1,300人を上回ったとSlateが報じました。
仕組み: オレゴン州の多才な研究者Matt Ginsbergは、2012年の大会で論理ベースのシステムを初披露し、第11位に入賞しました。今年は、Ginsbergが自分のモデルに、UCバークレーで開発されたニューラル・クロスワード・ソルバーを組み合わせました。
- 6,000,000件の「手がかり(クルー)」と「答え」のペアから学習したBerkeleyのシステムは、パズルの手がかりを読み取り、候補となる単語を生成します。
- その候補を記号(シンボリック)システムに渡し、各候補が正解である確率を算出します。これは、文字数や綴りが交差する単語と衝突するかどうかといった要因に基づきます。
- 4月下旬の大会でDr. Fillはミスをわずか3回に抑え、最終問題を49秒で解きました—最速の人間よりも2分以上速く、2分超の差です。
今回の背景: 1978年に設立されたAmerican Crossword Puzzle Tournamentでは、競技者は2日間で8つのパズルを解く必要があります。最速かつ最も正確な上位3名が、賞金3,000ドルのグランドプライズをかけて、最後のパズルで対決します。
なぜ重要か: ニューラルネットワークと記号(シンボリック)システムは、しばしば対立するアプローチとして見られます。しかし、両者を組み合わせることで、それまで解きにくかった問題の解決に役立てられる可能性があります。
考えてみると: 知識やスキルを得ることに対する粘り強い姿勢を表す、12文字のキャッチフレーズとは何でしょうか?
DEEPLEARNING.AIからのメッセージ
.png?upscale=true&width=1200&upscale=true&name=The%20Batch%20Image%201%20(1).png) |
Machine Learning Engineering for Production(MLOps)Specializationの最初の2つのコースが、Courseraで公開中です!今すぐ申し込む
 |
リアルタイムにおけるバーチャルリアリティ
理想的には、仮想現実や拡張現実などのリアルタイム3Dアプリケーションは、シーンの異なる視点の間を滑らかに切り替えますが、新しい視点を生成するには時間がかかることがあります。新しい研究が、そのプロセスを高速化します。
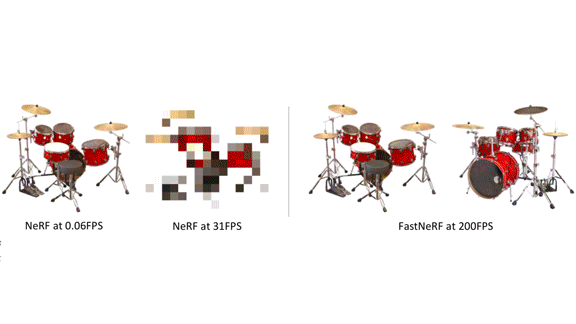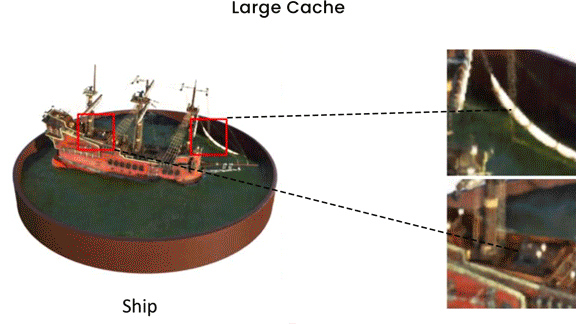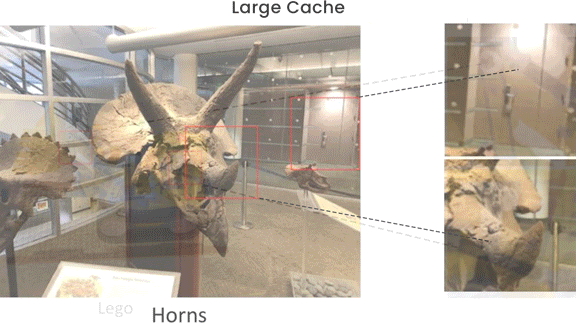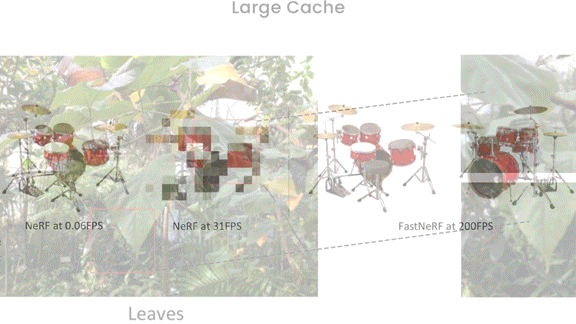
新着: MicrosoftのStephan Garbinと共同研究者たちは、FastNeRFを開発しました。これは、Neural Radiance Fields(NeRF)として知られるフォトリアルな3Dレンダリング手法を高速化し、あらゆる角度からシーンを毎秒200フレームというテンポで可視化します。
重要な洞察: 3Dシーンの1フレームを可視化するには、仮想カメラの位置と、フレーム内の各ピクセルを通ってカメラから伸びる一連の仮想の光線(バーチャルライトレイ)の方向を把握する必要があります。(ピクセルの背後にある物体には基本の色があり、そこから光、影、遮蔽、不透明度によって変化が加わります。)NeRFは、関連する光線に沿って存在するすべての点の色/透明度を組み合わせて、ピクセルの色を計算します。これは数百回にも及ぶニューラルネットワークの推論を要するため、リアルタイムで実行するのは大変です。FastNeRFは、2段構えの回避策によって計算負荷をやりくりします。まず、都度その場で計算するのではなく、考えられるすべての光線と、それらに沿う点についての情報を事前計算して保存します。次に、すべての可能な「光線と点」の組み合わせ(空間次元あたり1,024サンプルを仮定すると、1,024^3 * 1,024^2個の値)を保存しないようにするため、各点の基本の色と透明度を、その位置にもとづいて保存し、さらに光線の方向による色のシフト(1,024^3 + 1,024^2個の値)も保存します。
仕組み: FastNeRFは2つの素朴なニューラルネットワークを使って、点の位置(位置ネットワーク)とレイの方向(方向ネットワーク)に基づく情報を計算します。著者らは、モデル船やLEGOの組み立て物のような現実の物体について360度の視点を含むSynthetic NeRFと、Local Light Field Fusionにある物体の正面視点で構成されるデータを用いてシステムを学習させました。
- FastNeRFはシーン全体にわたって点を均等にサンプリングします。位置ネットワークは、各点の透過度と、基本的な色を表すベクトルを計算します。そしてそれらの結果を保存します。
- 同様にFastNeRFは、あらゆる方向を向くレイを均等にサンプリングします。方向ネットワークは、それぞれのレイの方向が、そのレイ上のすべての点の色にどう影響するかを表すベクトルを計算します。そしてその結果も保存します。
- ピクセルの値を計算するために、FastNeRFは、レイ上のあらゆる点について、透過度・基本色・レイ方向の効果を組み合わせます。
- そして各点の色(位置ネットワークの出力)を、方向ネットワークの出力で重み付けします。次に、各点の色をその透過度でさらに重み付けします。最後に、レイ上のすべての点について、2回重み付けされた色を合計します。
結果:高性能なコンシューマー向けGPUボード上で実行したところ、FastNeRFはNeRFの3,000倍以上の速さを実現しました。たとえば、LEGOのトラクターのシーンを0.0056秒でレンダリングしましたが、NeRFでは17.46秒でした。速さにもかかわらず、Synthetic NeRFではFastNeRFは29.97dBのピーク信号対雑音比(PSNR)を達成しました。これは生成画像が元画像をどれだけよく再現できているかを測る指標(高いほど良い)で、NeRFの29.54dBと比較されます。
重要な理由:著者らは、点の位置とレイの方向に基づいて情報を2つのモデルの間で分割することで、扱いきれないほどの高次元データ量を実用的なサイズにまで削減しました。同様のアプローチは、創薬や天候モデリングのように、多数の入力パラメータに対して最適化が必要となる用途で役立つ可能性があります。
私たちが考えていること: 拡張現実や仮想現実は、教育・エンターテインメント・産業に強力な新しいアプローチをもたらすことを約束しています——それを、安価で、簡単で、十分に速いものにできるなら。ディープラーニングが、その実現を後押ししています。
 |
シャチのためのアルゴリズム
コンピュータービジョンとドローンの組み合わせは、減少しているシャチ(killer whale)の個体数の回復に役立つかもしれません。
新しい動き:オレゴン州立大学と保全団体がSR3とVulcanとともに、シャチの健康状態を評価するシステムを開発したと、Geekwireが報じています。
仕組み:研究者たちは、ブリティッシュコロンビア州とワシントン州の沖合でドローンを飛ばし、水面近くを泳ぐシャチの映像を撮影します。4つの機械学習モデルから成る「Aquatic Mammal Photogrammetry Tool(海洋哺乳類フォトグラメトリツール)」が、その映像を解析します。
- 最初のモデルは、シャチが写っている映像フレームを特定し、被り物体の周囲にバウンディングボックスを描きます。次に、セグメンテーションモデルが体の輪郭を描きます。ランドマーク検出器が、各個体の吻(鼻先)、背びれ、その他の部位を特定し、その相対的な形状と位置を使って健康状態を推定します。4つ目のモデルは、背びれの後ろにある灰色のパッチの形状に基づいて個体を識別します。
- シャチの写真を、体調不良の兆候があるかどうか調べる作業は、これまで6か月かかっていました。システムはその期間を、数週間または数日まで短縮します。
- 得られた結果は、保護措置の必要性について政策決定者に情報を提供できます。たとえば、商業漁師が捕獲してよいサーモンの数を制限して、より多くの餌をシャチに残すといったことです。
ニュースの裏側:保全活動家たちは、動物界全体で機械学習の助けを得ています。
- オープンソースのプロジェクトが、AI搭載の首輪を開発しており、密猟者からゾウを守ろうとしています。
- 南カリフォルニア大学で開発されたシステムは、カンボジアのレンジャーが密猟者を食い止められるよう、最適な巡回ルートを提案します。
- Wildlife.aiは、カエル、魚、その他の動物のうち絶滅が危惧される種を特定するためのAIプロジェクトを組織する非営利のハブです。
重要な理由:個々の生き物の健康状態に関する詳細な情報があれば、保全活動家は困ったときにより素早く対応できます。開発者たちは、自分たちの成果をオープンソース化する計画でおり、他のシャチの集団、場合によっては他の水生哺乳類の種にも適用できるようにしたいと考えています。
私たちが考えていること:太平洋北西部のシャチの個体群は75頭まで減少しており、過去30年で最少です。回復を期待しています。




