Claude Opus 4.7を紹介します

最新モデルであるClaude Opus 4.7は、現在一般提供を開始しています。
Opus 4.7は、先行するOpus 4.6に比べて、高度なソフトウェアエンジニアリングにおいて顕著な改善を果たしており、とりわけ最も難しいタスクで大きな伸びが見られます。ユーザーは、これまで厳密な監督が必要だった、自分たちの最も手強いコーディング作業を、Opus 4.7に自信をもって引き継げるようになったと報告しています。Opus 4.7は、複雑で長時間にわたるタスクを、厳密さと一貫性をもって処理し、指示に正確に注意を払い、報告する前に自らの出力を検証するための手段を考案します。
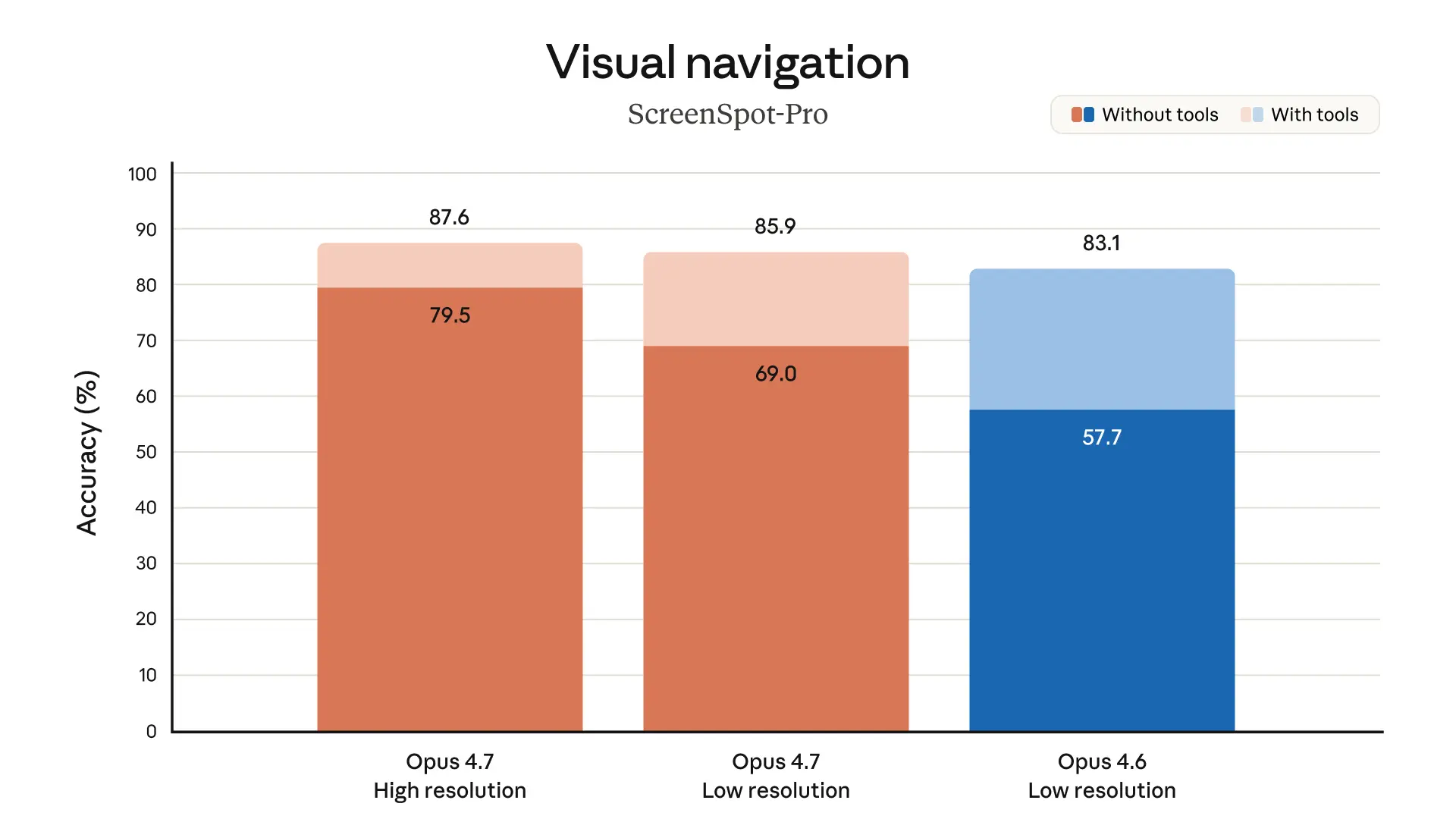
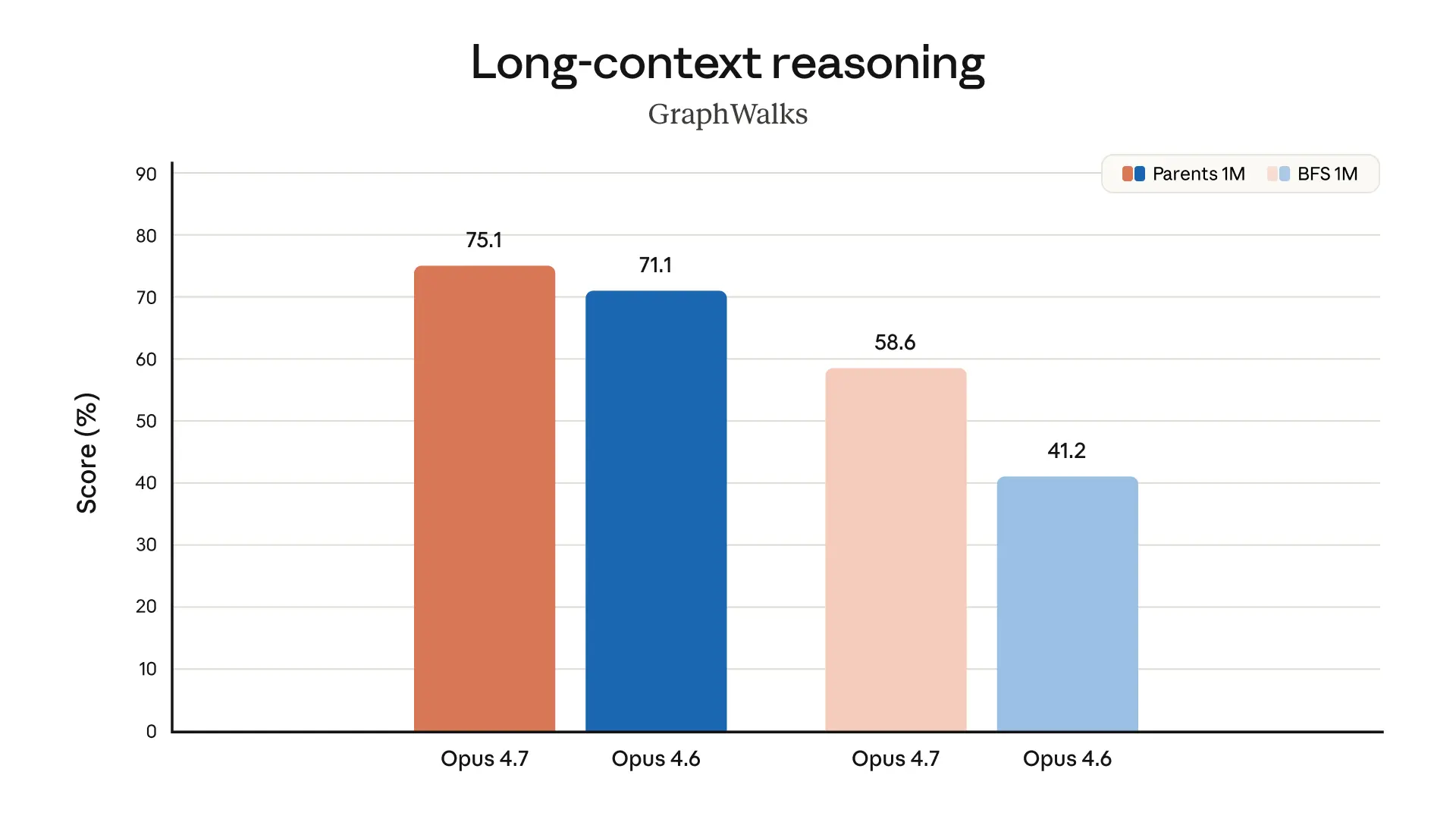
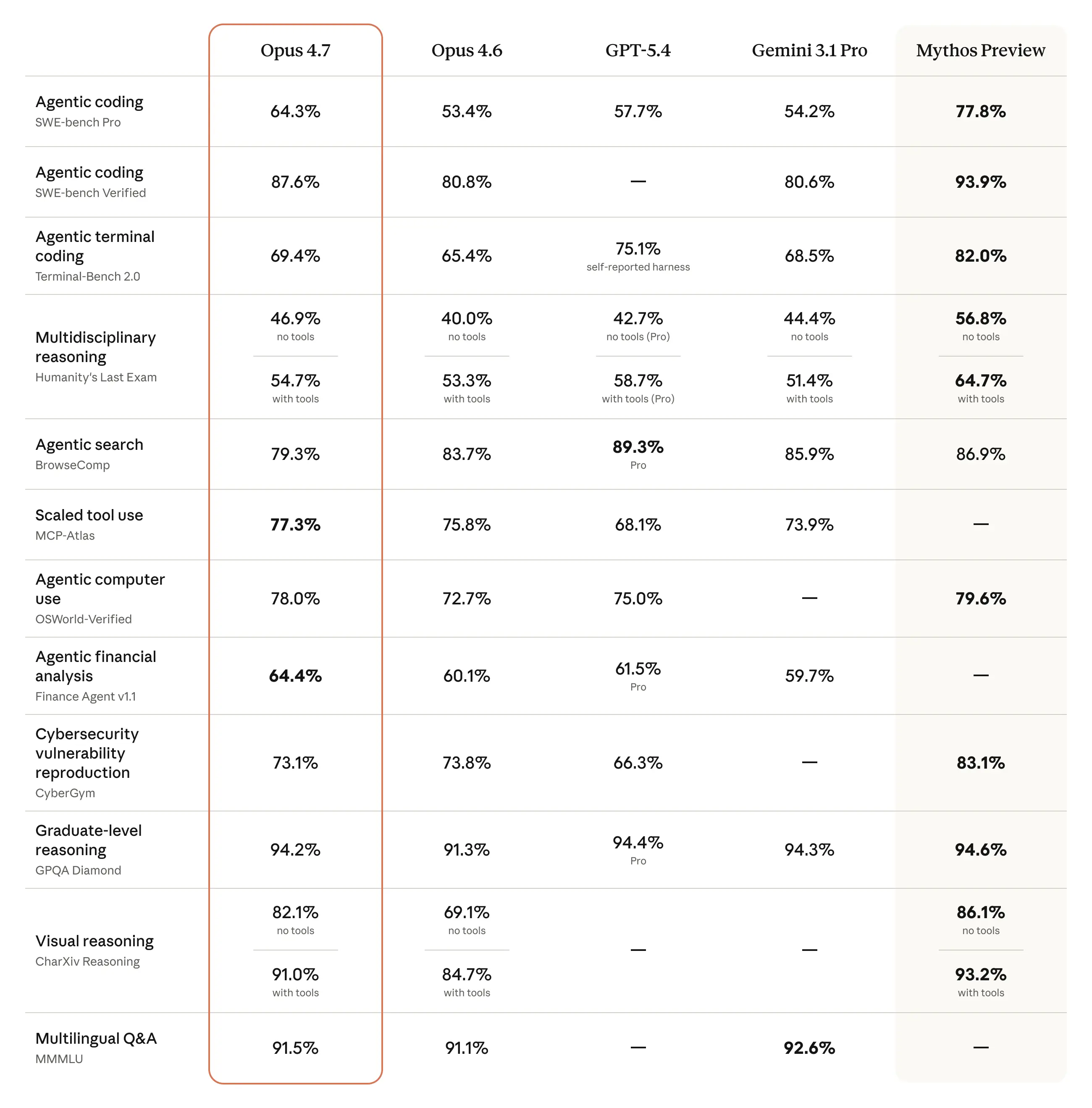
また、このモデルの視覚性能も大幅に向上しています。より高い解像度で画像を見ることができます。プロフェッショナルな作業を完了する際の出来は、より上品で創造的であり、より質の高いインターフェース、スライド、ドキュメントを生み出します。そして—当社が最も強力なモデルであるClaude Mythos Previewほど幅広い能力はないものの—複数のベンチマークにおいてOpus 4.6よりも良い結果を示しています:
先週、私たちはProject Glasswingを発表し、サイバーセキュリティにおけるAIモデルのリスク—そして利点—を示しました。私たちは、Claude Mythos Previewのリリースを限定し、より能力の低いモデルから先に新しいサイバー保護策をテストすると述べていました。Opus 4.7は、そのような最初のモデルです。サイバー面の能力はMythos Previewほど高度ではありません(実際、そのトレーニング中に、これらの能力を差分的に低減する取り組みを試しました)。私たちは、禁止されている、または高リスクなサイバーセキュリティ用途を示すリクエストを自動的に検出してブロックする保護策とともにOpus 4.7をリリースします。これらの保護策を実環境で展開した際に得られる学びは、最終的にはMythosクラスのモデルを幅広く提供するという目標に向けた取り組みに役立てます。
正当なサイバーセキュリティ目的(脆弱性調査、ペネトレーションテスト、レッドチーミングなど)でOpus 4.7を利用したいセキュリティ専門家の方は、当社の新しいCyber Verification Programに参加することを歓迎します。
Opus 4.7は本日、すべてのClaude製品と当社のAPI、Amazon Bedrock、Google CloudのVertex AI、Microsoft Foundryで利用可能です。価格はOpus 4.6と同じままです:入力トークン100万あたり5ドル、出力トークン100万あたり25ドル。開発者はClaude APIを通じてclaude-opus-4-7を利用できます。
Claude Opus 4.7をテスト
Claude Opus 4.7は、早期アクセスのテスターから強い反応を得ています:
初期のテストでは、Claude Opus 4.7によって開発者にとって大きな飛躍が期待できることが見えてきています。計画フェーズの段階で自分自身の論理的な不具合を見つけ出し、実行を加速します。これは、従来のClaudeモデルを大きく上回るほどです。数百万の消費者や企業に対して、重要な規模で金融テクノロジープラットフォームを提供している私たちにとって、この組み合わせはスピードと精度の両立によりゲームチェンジャーになり得ます。つまり、お客様が毎日頼りにしている信頼できる金融ソリューションを、より速い提供につなげるために、開発の進行速度を加速できるのです。
Anthropicはコーディング・モデルの標準をすでに確立しており、Claude Opus 4.7は市場で最先端のモデルとして、それを意味のある形でさらに押し進めています。私たちの社内評価では、単に生の能力だけで目立つのではなく、実際の環境での非同期ワークフロー—自動化、CI/CD、長時間実行されるタスク—をどれだけうまく扱えるかにおいて際立っています。また、問題をより深く考え、ユーザーに単に同意するのではなく、より踏み込んだ見解をもたらします。
Claude Opus 4.7は、Hexが評価した中で最も強力なモデルです。もっともらしいが誤ったフォールバックを提示するのではなく、データが欠けていることを正しく報告し、Opus 4.6でさえはまってしまうような、そぐわないデータの罠にも耐性があります。より知的で、より効率的なOpus 4.6です。低い工数のOpus 4.7は、中程度の工数のOpus 4.6とほぼ同等です。
当社の93タスクのコーディング・ベンチマークでは、Claude Opus 4.7がOpus 4.6に対して解決率を13%引き上げました。Opus 4.6もSonnet 4.6も解けなかった4つのタスクを含みます。さらに、より高速な中央値レイテンシと厳格な指示追従を組み合わせたことで、特に複雑で長時間にわたるコーディングのワークフローにおいて大きな意味を持ちます。これらの多段階タスクに伴う摩擦を減らし、開発者が流れに乗ったまま、構築に集中できるようにします。
社内のリサーチ・エージェント・ベンチマークに基づくと、Claude Opus 4.7は、複数ステップ作業における最も強力な効率性のベースラインです。6つのモジュールすべてにおける総合トップスコアで0.715を記録し、首位を分け合いました。さらに、当社がテストしたどのモデルよりも長いコンテキストでの性能が最も一貫していました。最大のモジュールであるGeneral Financeでは、Opus 4.6よりも有意義に改善し、0.767に対して0.813を獲得しました。また、グループ内で最も優れた開示とデータに関する規律(データ・ディシプリン)も示しました。推論ロジックの領域では、Opus 4.6が苦戦していたのに対し、Opus 4.7は堅実です。
Claude Opus 4.7は、モデルができることの限界を押し広げて、調査し、タスクを完了させるための可能性をさらに高めています。Anthropicは長時間の実行にわたる持続的な推論を明確に最適化しており、その成果は市場トップクラスの性能に表れています。エンジニアがエージェントと1対1で作業することから、並行してそれらを管理することへと移行していく中で、これはまさに新しいワークフローを切り開くフロンティアの能力です。
Claude Opus 4.7のマルチモーダル理解は大きく改善しているのを見ています。化学構造の読み取りから、複雑な技術図表の解釈まで幅広く対応しています。高解像度のサポートは、Solve Intelligenceがライフサイエンス分野の特許ワークフロー向けに、出願から審査対応、侵害検知、無効性チャーティングまでを含む、業界トップクラスのツールを構築するのに役立っています。
Claude Opus 4.7は、Devinにおける長期ホライゾンの自律性を新たなレベルへ引き上げます。数時間にわたって首尾一貫して動作し、あきらめずに難しい問題を突破し、これまで私たちが確実に実行できなかった種類の深い調査作業を可能にしました。
Replitにとって、Claude Opus 4.7へのアップグレードは簡単な判断でした。私たちのユーザーが毎日行っている作業において、同じ品質をより低コストで達成していることを観察しました。ログやトレースの分析、バグの発見、修正案の提案といったタスクでは、より効率的で、より正確でした。個人的には、技術的な議論の場で押し返してくれて、より良い判断を下せるようにしてくれるところがとても気に入っています。まさに、より良い同僚のように感じます。
Claude Opus 4.7は、Harvey向けのBigLaw Benchにおいて実体面の正確性が高いことを示しています。高い努力(high effort)で90.9%を達成し、レビュー用のテーブルにおける推論のキャリブレーションがより良く、曖昧なドキュメント編集タスクへの対応も明らかに賢くなりました。割当条項(assignment provisions)と支配権変更条項(change-of-control provisions)を正しく区別できたのは特筆すべき点で、これはこれまでフロンティアモデルにとっても歴史的に難しい課題でした。実体面は、私たちの評価全体を通じて一貫して強みとして評価されました。正確で、徹底的で、根拠が適切に示されていました。
Claude Opus 4.7 は、特に自律性と、より創造的な推論において、とても印象的なコーディングモデルです。CursorBench での Opus 4.7 は、能力の面で大きな進歩で、Opus 4.6 の 58% に対して 70% を達成しています。
複雑な多段階ワークフローでは、Claude Opus 4.7 は明確に一段上です。Opus 4.6 に比べてトークン数が少ないうえで +14%、さらにツールエラーは 3 分の 1 です。こちらの暗黙のニーズ(implicit-need)テストを初めて通過したモデルで、これまで Opus を完全に止めてしまっていたツールの失敗が起きても、実行を継続し続けます。まさに、この信頼性の跳躍があってこそ、Notion Agent は本当のチームメイトのように感じられるのです。
評価(eval)では、コア・オーケストレーター・エージェントにおいて、ツール呼び出しと計画の精度が2桁の大幅な向上を示しました。ユーザーがHebbiaを活用して、検索(retrieval)、スライド作成、ドキュメント生成のようなユースケースを計画し実行する中で、Claude Opus 4.7は、これらのワークフローにおけるエージェントの意思決定を改善できる可能性を示しています。
Rakuten-SWE-Benchでは、Claude Opus 4.7はOpus 4.6よりも生産(production)タスクを3倍多く解決し、コード品質(Code Quality)とテスト品質(Test Quality)で2桁の向上を記録しました。これは、私たちのチームが毎日送り出しているエンジニアリング業務に対する、意味のある底上げであり、明確なアップグレードです。
CodeRabbitのコードレビュー業務において、Claude Opus 4.7は私たちがテストした中で最も鋭いモデルです。リコールは10%超の改善を示し、より難しくて見落とされがちなバグを、最も複雑なPRでいくつか見つけています。一方で、カバレッジが増えているにもかかわらず、精度(precision)は安定したままでした。さらに、私たちのハーネス上ではGPT-5.4 xhighよりも少し高速です。そしてローンチ時には、最も重いレビュー作業に向けてこれを投入する予定です。
GensparkのSuper AgentであるClaude Opus 4.7は、最も重要な3つの制作上の差別化要因——ループ耐性、一貫性、そして優雅なエラー回復——をきっちり押さえています。ループ耐性は最重要です。1/18のクエリで無限ループしてしまうようなモデルは、計算リソースを無駄にし、ユーザーをブロックします。分散が低いほど、本番環境での「驚き」が減ります。そしてOpus 4.7は、私たちが測定した中で、ツール呼び出しあたりの最高の品質比を達成しています。
Claude Opus 4.7はWarpにとって、意味のあるレベルアップです。Opus 4.6は開発者向けの非常に優れたモデルの1つであり、このモデルはそれに加えて、測定可能なほど徹底しています。以前のClaudeモデルでは失敗していたTerminal Benchのタスクをクリアし、さらにOpus 4.6では解けなかった厄介な並行処理のバグも乗り越えました。私たちにとって、それがサインです。
Claude Opus 4.7 は、ダッシュボードやデータ量の多いインターフェースを作るのに最適なモデルです。デザインのセンスが本当に驚くべきもので、こちらが実際に出荷するであろう判断をしてくれます。今は私のデフォルトの毎日の相棒です。
Claude Opus 4.7 は、Quantium で私たちがテストした中で最も高い能力を持つモデルです。独自のベンチマークソリューションを使って主要な AI モデルと比較評価したところ、大きな伸びが見られたのは、最も重要なところでした。すなわち、推論の深さ、構造化された問題設定、そして複雑な技術作業です。修正回数は少なく、反復は速くなり、クライアントが持ち込む最難関の課題を解くための出力もより強力になりました。
Claude Opus 4.7 は、知能面で本物の飛躍を感じます。コードの品質が明らかに向上していて、以前は積み重なっていた意味のないラッパー関数やフォールバック用の足場(スキャフォールド)が削ぎ落とされ、しかも生成したコードを途中で自分で修正していきます。Sonnet 3.7 から Claude 4 シリーズに移ったとき以来、私たちが見てきた中で最もきれいなジャンプです。
XBOWの自律的な侵入テストの中核となる、コンピュータ利用ベースの作業において、新しい Claude Opus 4.7 は大きな進化です。視覚の識別力に関するベンチマークでは 98.5% で、Opus 4.6 の 54.5% を大きく上回っています。最大の Opus に関する課題が事実上解消され、その結果、これまでそれを使えなかった一連の作業における利用が可能になりました。
Claude Opus 4.7 は、Vercel 向けに後退(回帰)がない堅実なアップグレードです。ワンショットのコーディング課題において素晴らしい性能を発揮し、Opus 4.6 よりもより正確で、より完全です。また、自分の限界についても、明らかにより率直です。さらに、作業を始める前にシステムコード上で証明(プロオブ)を行うことさえあります。これは、これまでの Claude モデルでは見られなかった新しい挙動です。
Claude Opus 4.7は非常に強力で、工場用ドロイドのタスク成功率が10%〜15%向上するなどOpus 4.6を上回っており、ツールエラーも少なく、バリデーション手順の完了までの追随もより確実です。途中で止まるのではなく、仕事を最後までやり切ります。これはまさに、エンタープライズのエンジニアリングチームが必要としていることです。
Claude Opus 4.7は、自律的にゼロから完全なRustのテキスト読み上げ(TTS)エンジンを構築しました。すなわちニューラルモデル、SIMDカーネル、ブラウザデモを作ったうえで、自身の出力を音声認識器にかけて、Pythonの参照結果と一致していることを検証しました。上級エンジニアリングを数か月分、自律的に実現しています。Opus 4.6からのステップアップは明確で、コードベースは公開されています。
Claude Opus 4.7は、これまでのClaudeモデルでは達成できなかったTBenchの3つのタスクを通過しました。また、以前の最優秀モデルが見落としていたレースコンディションを含む修正も反映されました。実在する問題を見分ける上での高い精度が示されており、他のモデルが諦めてしまった、あるいは解決できなかった重要な発見を提示します。Qodoの実世界のコードレビュー・ベンチマークでは、トップクラスの精度が観測されました。
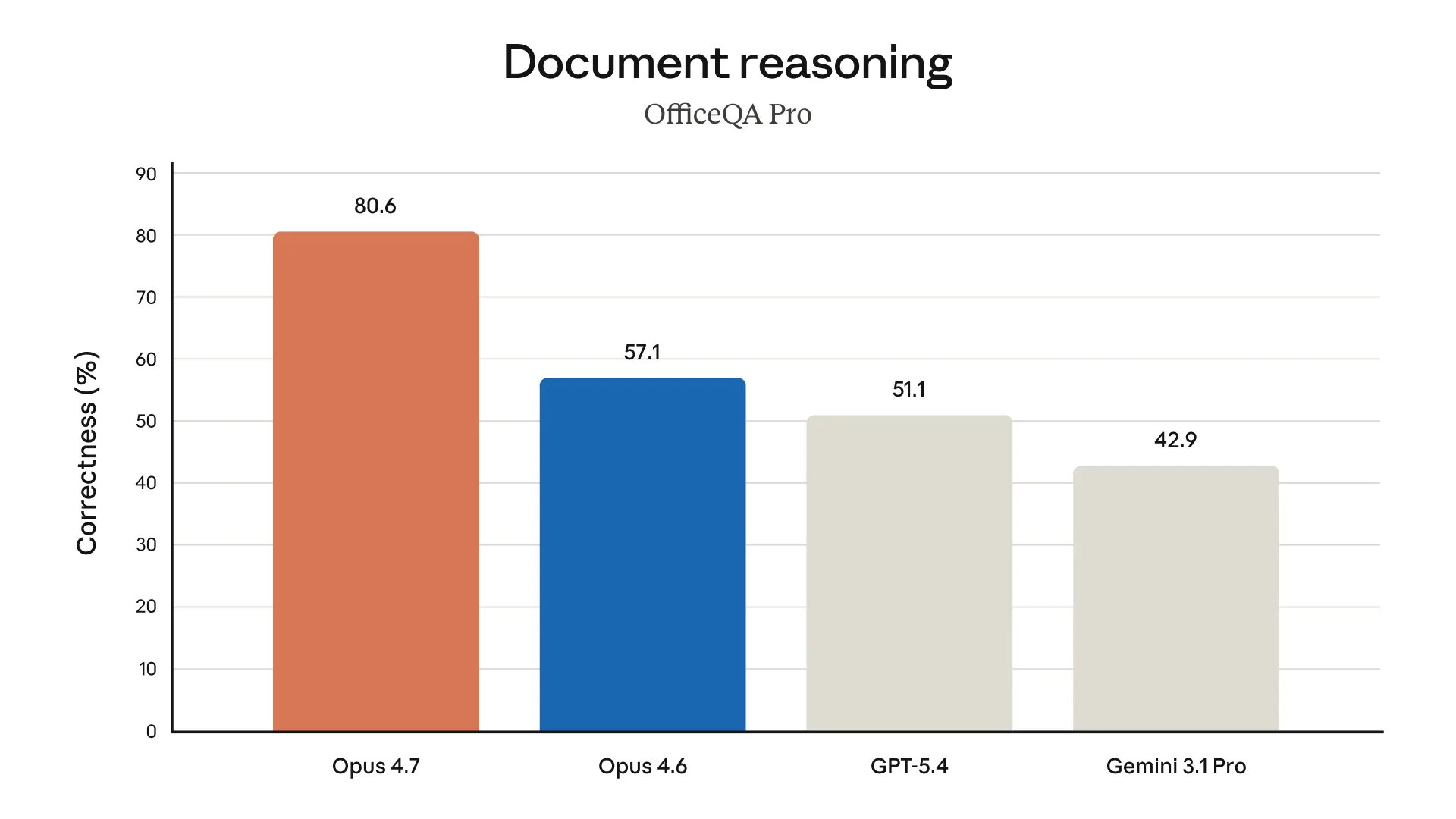
Databricks の OfficeQA Pro では、Claude Opus 4.7 がソース情報を扱う際に、Opus 4.6 よりも有意に強い文書推論を示し、誤りは 21% 少ないことが分かりました。データに関するエージェント的推論ベンチマーク全体で、エンタープライズ向けの文書分析において最も優れたパフォーマンスを発揮する Claude モデルです。
Ramp では、Claude Opus 4.7 がエージェントチームのワークフローで際立っています。役割の一貫性、指示への追従、連携、そして複雑な推論がより強く見られました。特に、ツール、コードベース、デバッグの文脈にまたがるエンジニアリングタスクで顕著です。Opus 4.6 と比べて、より少ないステップごとのガイダンスで済むため、エンジニアリングチームが実行している社内のエージェントワークフローを拡張しやすくなります。
Claude Opus 4.7は、Boltのより長時間にわたるアプリ構築の作業において、Opus 4.6よりも明確に優れています。最良の場合には最大10%良く、また、非常にエージェント的なモデルで私たちがこれまで期待してきた後退(回帰)もありません。ユーザーが1回のセッションで出荷できるものの天井を引き上げます。
以下は、Opus 4.7の事前テストに基づく主なポイントとメモです:
- 指示追従。Opus 4.7は、指示に従う点で大幅に優れています。興味深いことに、これはつまり、以前のモデル向けに書かれたプロンプトが、場合によっては今のモデルでは予期しない結果を生むことがあるということです。これまでのモデルが指示を曖昧に解釈したり、部分的にスキップしたりしていたのに対し、Opus 4.7は指示を文字通りに受け取ります。ユーザーはプロンプトや運用(ハーネス)を再調整し、それに合わせて活用する必要があります。
- マルチモーダル対応の改善。Opus 4.7は、高解像度画像に対する視認性が向上しています。長辺で最大2,576ピクセル(約3.75メガピクセル)の画像を受け付けられ、これは従来のClaudeモデルの3倍以上です。これにより、細かな視覚情報に依存する幅広いマルチモーダルの用途が開けます。例えば、密度の高いスクリーンショットを読むコンピュータ利用エージェント、複雑な図表からのデータ抽出、そしてピクセル単位で正確な参照が必要な作業です。1
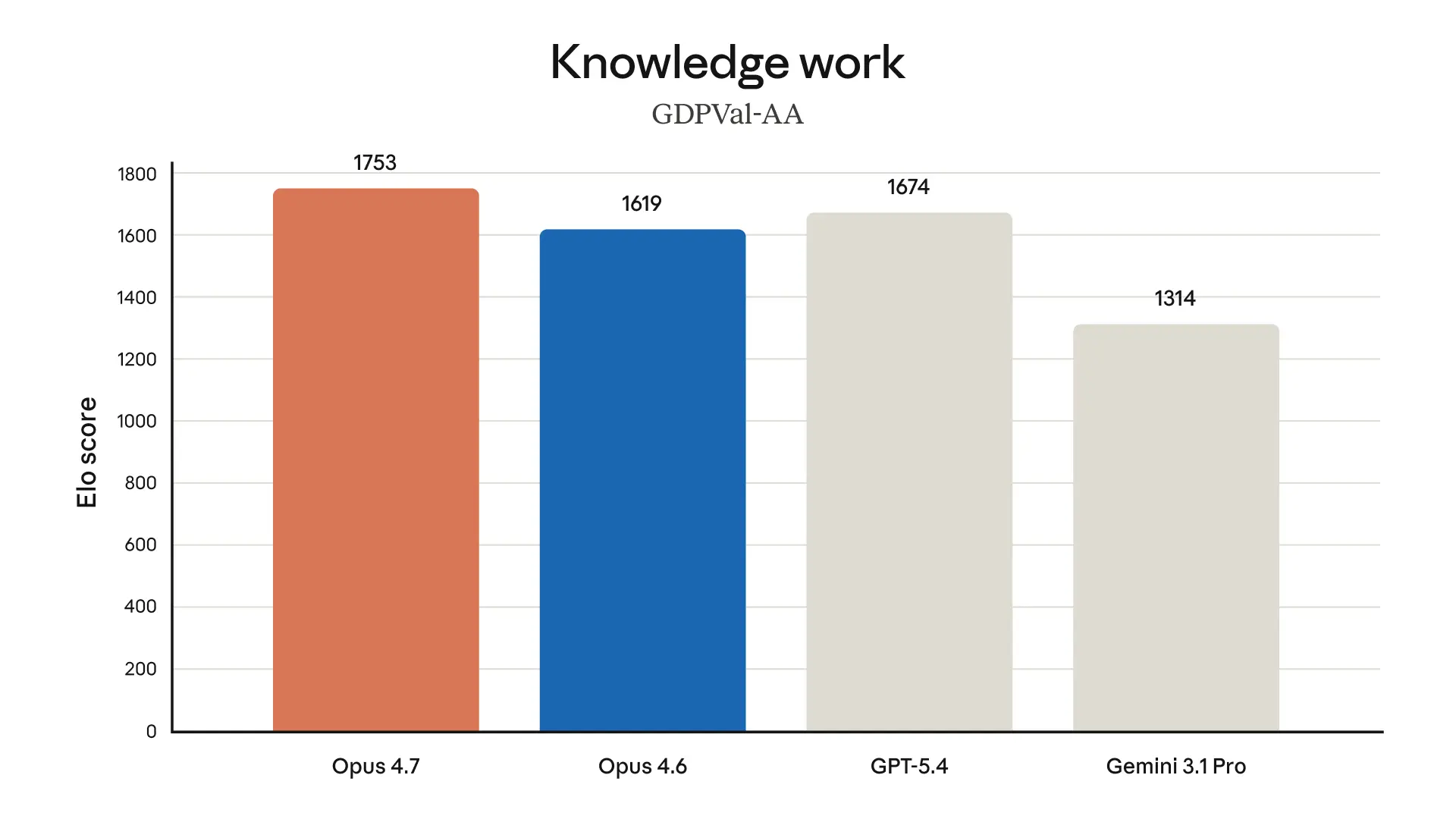
- 現実の業務。Finance Agent評価での最先端のスコアに加えて(上の表を参照)、社内テストではOpus 4.7がOpus 4.6よりも、より効果的なファイナンスアナリストであることが示されました。厳密な分析やモデル、よりプロフェッショナルなプレゼンテーション、そしてタスク間での連携の緊密さという点で優れています。さらにOpus 4.7は、GDPval-AAでも最先端です。これは、ファイナンス、法務、その他の領域にまたがって、経済的に価値のある知的作業を対象にした第三者評価です。
- メモリ。Opus 4.7は、ファイルシステムベースのメモリの活用がより得意です。長時間の複数セッションにわたる作業の中で重要なメモを覚え、それらを使って新しいタスクへ進みます。その結果、必要な事前の文脈(初期コンテキスト)が少なくて済みます。
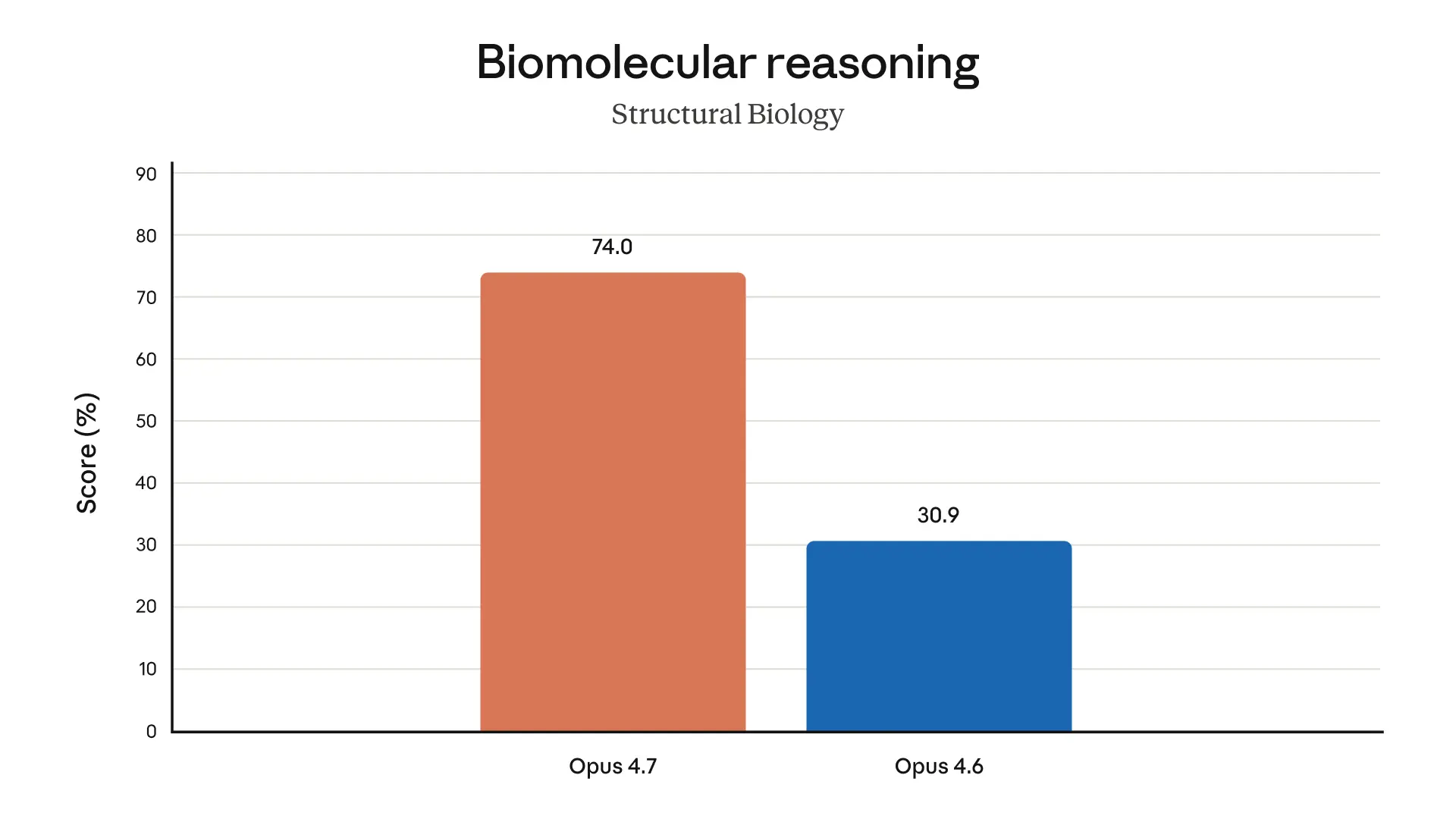
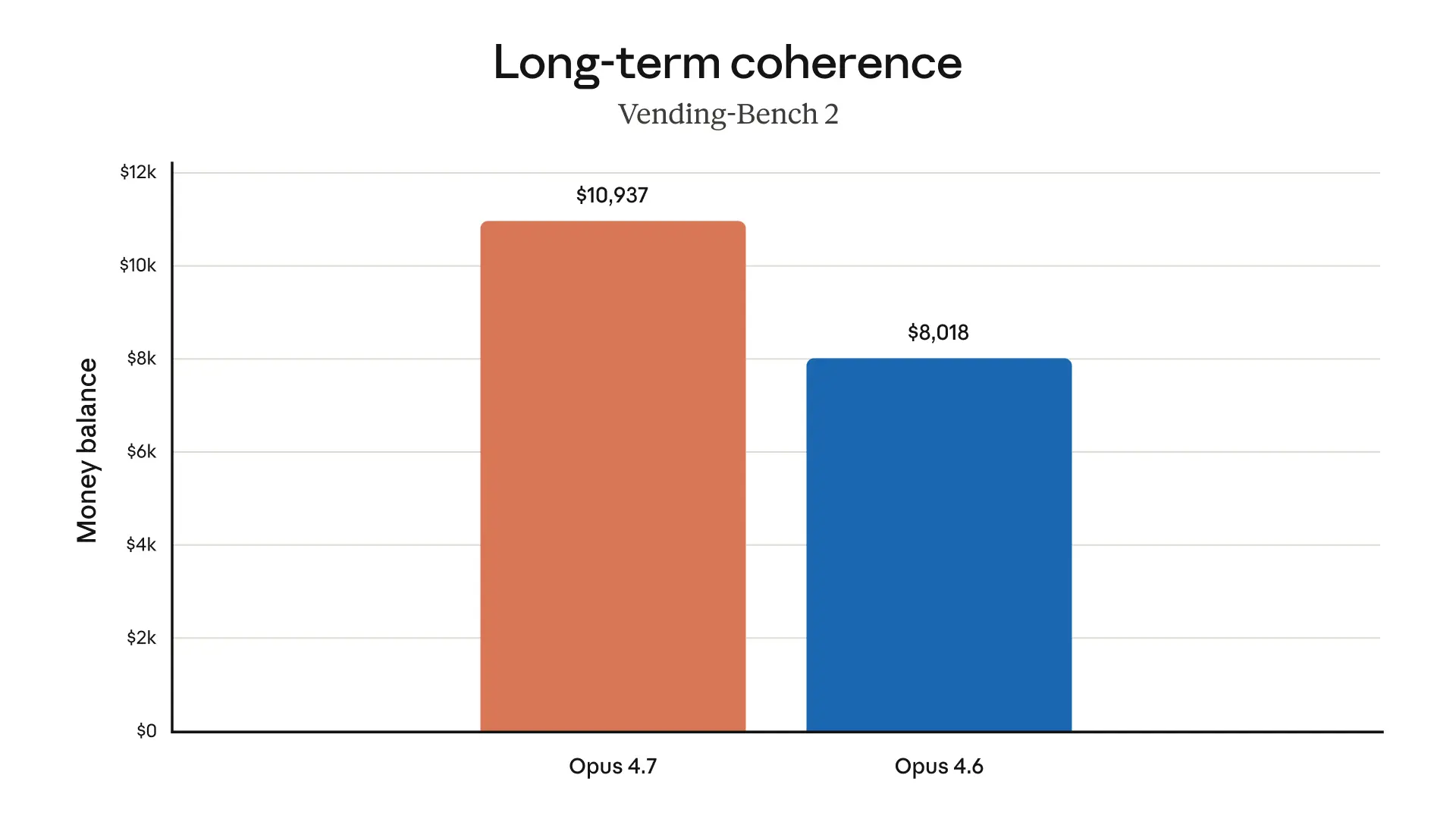
以下のチャートは、リリース前のテストで得られた、さまざまな領域にわたる追加の評価結果を示しています: