この記事の3つのポイント
- 文書や情報をAIで活用するシステムを提供し、企業の問題解決を図る
- 顧客企業内の情報を構造化してからAIエージェントを提供
- 構造化されていない情報はハルシネーションの原因になりがち

富士フイルムビジネスイノベーション(富士フイルムBI、旧富士ゼロックス)は、複合機事業に加えて文書関連システムやクラウドサービスの提供を強化している。業務効率化やセキュリティー向上といった顧客の課題解決に向き合う上で、AI(人工知能)の利用が比重を増しつつある。そのAIによって確実に成果を得るには、元になるデータが構造化され、整理された形になっている必要があるという。AI活用の取り組みや体制などについて、取締役常務執行役員CTO(最高技術責任者)の鍋田敏之氏に聞いた。
AI技術の展開に力を入れていると伺っています。AIを事業にどのように利用していく考えでしょうか。
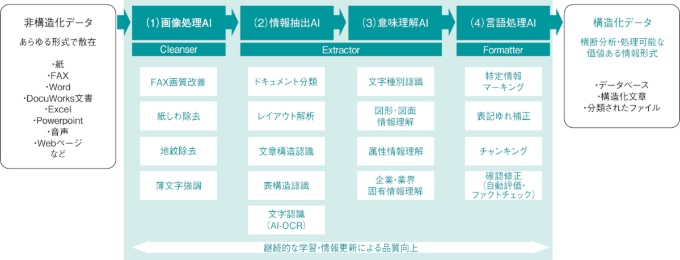
これまで紙文書を中心として企業に蓄積された情報を知として活用する、というのが富士フイルムBIの使命であり、それに向けてAI技術を積み上げている。われわれは1962年以来、コピー機や複合機を中心に文書や画像といった膨大なデータを扱ってきた。企業内に生成されるデータのほとんどは非構造化データ、つまり一定の構造に整理されていない情報であり、それが90%を占めるといわれている。
これを構造化して活用するための技術開発を長年進めてきており、そこへ生成AIの急激な発展が重なった。構造化を通した知の活用については、その重要性と実現性がどんどん高まっている、と考えている。
情報をきちんと構造化した先に、業務の効率化を図るAIエージェントや、付加価値の高い業務提案ができるAIエージェントなどを導入する、という階段状の発展ステップで顧客に価値を提供する。構造化のステップを踏まずに、いきなり効率化や付加価値化のAIエージェントを強引に実装しようとしてもデメリットがある。
その1つは、構造化されていないデータを直接AIエージェントが読むと、ハルシネーション(誤情報)が起こりやすくなること。構造化されたデータよりもノイズ情報が多かったり、ノイズが結果へ影響しやすくなったりする。
もう1つは、時間がかかることだ。われわれがある例で試行したとき、構造化されたデータを読ませるのと、構造化されていないデータをそのまま読ませるのだと、かかった時間が100倍も違った。100倍違うということは、費用が100倍かかるということで、もっと言えば電力も100倍かかる。これからAIエージェントの時代になって、数多くのAIエージェントを活用しようというときに、やはり効率よくデータを整理した上で活用を図るほうが効果的、という考え方が基本だ。
次のページ
AIには、構造化されていないデータでもいきなり扱...この記事は有料会員限定です




