Nvidia の Groq 搭載 LPX およびその新しいラックシステムの全貌を解読する
LPU から GPU、CPU、スイッチまで、Nvidia の最新機材について知っておくべきすべての情報
GTC 深掘り 今週の Nvidia の GTC カンファレンスで、CEO Jensen Huang は何ヶ月も避けてきた200億ドル規模の質問にようやく答えました。なぜ自社で作るよりも Groq の技術をライセンスし、同社のエンジニアを引き抜くためにこれほど多額を費やすのか。
前にも述べたように、Nvidia が SRAM 重の推論アクセラレータを作りたかったなら、それを実現するために Groq を買う必要はなかった。 同社が新たに発表した Groq 3 LPX racks, which pack 256 LP30 language processing units (LPUs) into a single system, show time-to-market was the reason Nvidia bought rather than built.
We\'re told the chip is based on Groq\'s second-gen LPU tech with a handful of last-minute tweaks made just before tapping out at Samsung\'s fabs.
The chip doesn\'t use Nvidia\'s proprietary NVLink interconnect, it lacks NVFP4 hardware support, and it isn\'t CUDA-compatible at launch.
したがって Groq の知的財産権とエンジニアリングスタッフを取得するために支払われた200億ドルは、今年中にチップを市場へ送り出し、顧客の手に渡すための機会費用だったと結論づけられる。
なぜ急いだのか?
Groq とそのライバル Cerebras の SRAM 重アーキテクチャの定義的特徴のひとつは、LLM 推論ワークロードを実行する際に非常に高速で、通常は1 秒あたり 500 以上、場合によっては 1000 トークンを超える生成レートを達成することです。
Nvidia がトークンをより速く生成できるほど、コードアシスタントやAIエージェントがより迅速に動作できます。しかし、この種のスピードは、黄氏が“テスト時スケーリング”と呼ぶ現象への扉も開くことになります。
「推論」モデルにより多くの「思考」トークンを生成させることによって、より賢く、より正確な結果を生み出すことができる、という考えです。したがって、トークンを生成できる速度が速いほど、テスト時スケーリングがもたらす待機遅延のペナルティは小さくなります。
GTCのステージで、黄氏はこの高性能で低遅延の推論提供が、最終的にはこの能力に対して百万トークンあたり150ドルほどの料金を請求することもあり得ると示唆しました。
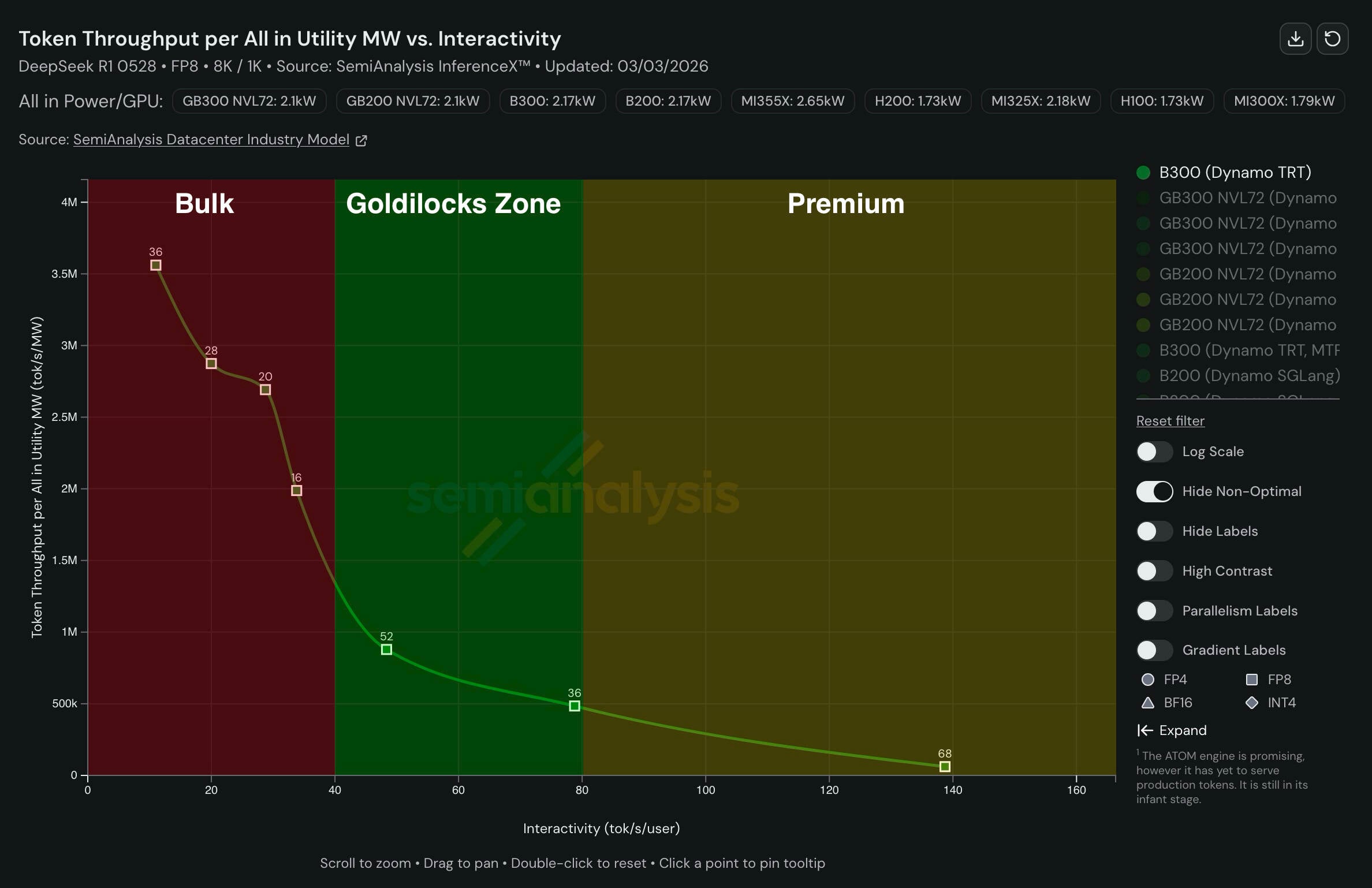
ご覧のとおり、NvidiaのGPUは大量のトークンを生成するには優れていますが、インタラクティビティが高まるにつれて効率が低下します。 - 拡大表示
Nvidia にとっては残念ながら、GPU はバッチ処理には優れているが、ユーザーごとの出力速度が上がるにつれてスケールする効率はそれほど高くならない。少なくとも単独では。
自社のGPUとGroqのLPU技術を組み合わせることで、Nvidia は両方の世界の良さを実現することを目指している。1人のユーザーあたりの秒あたりトークン数が高くなるほど、はるかに効率的にスケールする推論プラットフォーム。

Nvidia の Groq-3 LPU の概要 - 拡大表示

各 LPU 計算トレイには、8つの液体冷却式 Groq-3 LPU が搭載され、合計 4GB の SRAM - 拡大表示
Nvidia is also under some pressure to maintain its dominance of the AI infrastructure market as rival chip designers like AMD close the gap on hardware and software.
Last week, Amazon and Cerebras announced a collaboration to 組み合わせる AWS' Trainium-3 アクセラレータと後者のウェハスケール・アクセラレータを合わせることで、多くの同じ理由で Nvidia が LPX を構築した。もちろん、 AWS はさらに100万台を超える Nvidia GPU を展開する計画を発表しており、Nvidia-Groq LPUs の運用も予定されているため、クラウド大手が急にどちらかに肩入れしたわけではありません。
Groq-3 LPX
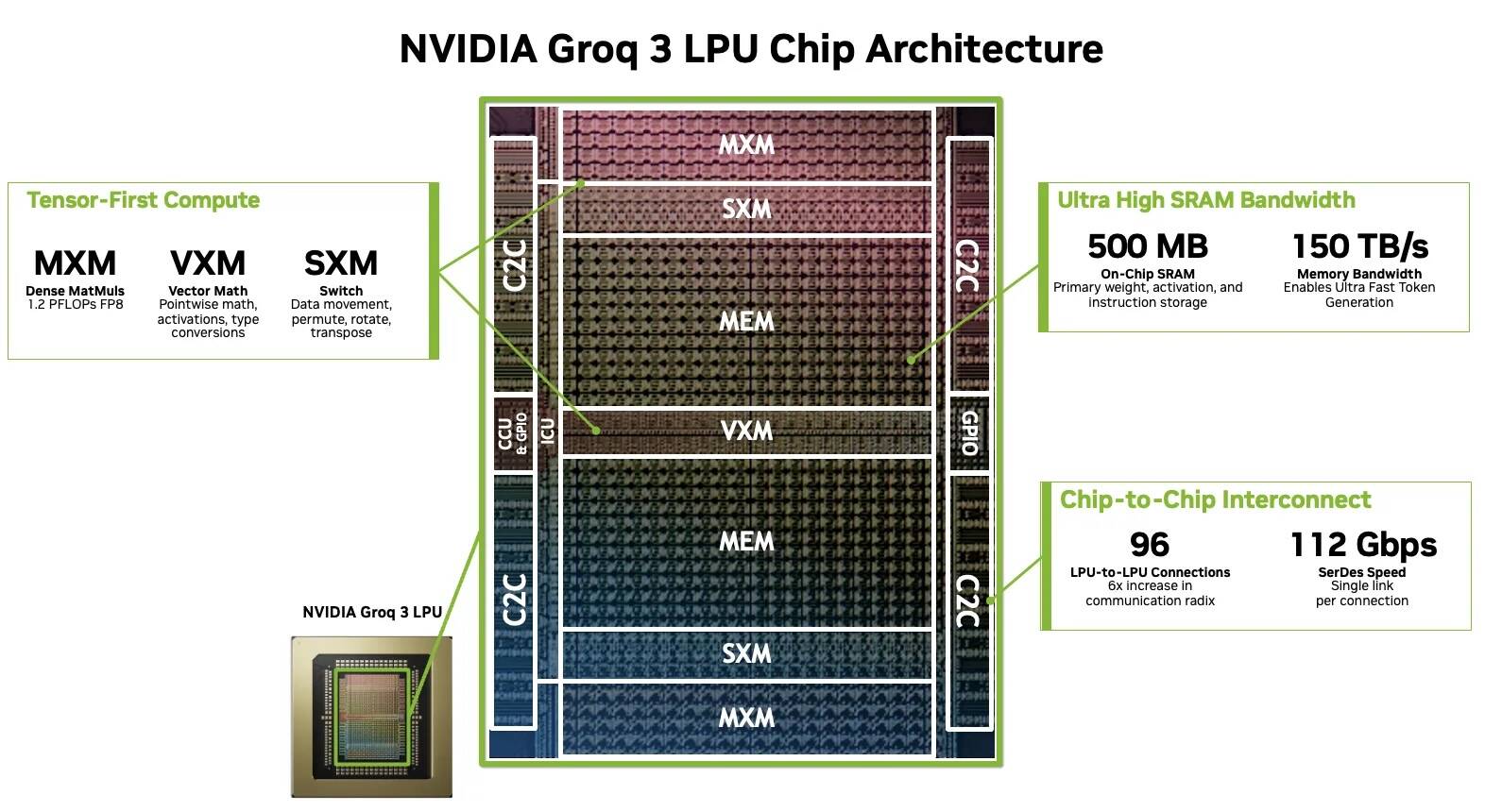
LP30 は Nvidia の GPU とは大きく異なります。TSMC ではなく Samsung Electronics によって作られ、オンチップ SRAM のみを使用します。また、従来の Von Neumann アーキテクチャを、データフローと呼ばれる別のアーキテクチャに置き換えています。
従来、メモリから命令を取得してデコードし、実行し、それをレジスタに書き戻す代わりに、データフロー・アーキテクチャはデータがチップを通過するときに処理します。プロセッサの計算ユニットは、データを回すためのロードとストアの多数の操作を待つ必要がなく、理論上はより高い利用率を達成します。
Nvidia の Groq-3 LPU の概要 - 拡大表示
Nvidia によれば、各 LP30 は FP8 計算を 1.2 petaFLOPS 提供できます。しかし、前述したように、MX や NV FP4 のような 4-bit ブロック浮動小数点データ型のサポートは、LP35 の到着時期まで実装されません。
その計算は、比較的大容量の SRAM メモリプールに結びついており、これは今日の GPU に搭載されている高帯域幅メモリ(HBM)よりも桁違いに高速ですが、必要とするスペースの点では非常に非効率的でもあります。
各 LPU はオンチップメモリとして 500 MB のダイ領域しか持たない。比較として、Nvidia の Rubin GPU の 8 つの HBM4 モジュールのうち 1 つには 36GB のメモリが搭載されている。LP30 が容量で欠けている分は、帯域幅で大いに補われ、最大で 150 TB/s の速度を実現する。これは Nvidia の Rubin アクセラレータの約7倍に相当する。
これは、推論パイプラインの自動回帰デコード段階において、生成される各トークンごとにモデルの全てのアクティブなパラメータをメモリからストリームする必要がある場面で、LPUが理想的に適していることを意味します。
もちろん、それを実現するには、Nvidia が狙う兆パラメータ級モデルをメモリに収める必要があり、それは決して容易な作業ではありません。この程度の大規模なモデルには複数のラックが必要です。そのため LPX には多数のインターコネクトが詰まっています。各チップには 96 本、具体的には 112 Gbps の SerDes が搭載され、双方向帯域幅は合計で 2.5 TB/s に及びます。
各 LPX ラックは 256 個の LPU を搭載しています。それらは 32 の計算トレイに分散され、それぞれ 8 個の LPU、いくつかのファブリック拡張ロジックと DRAM、そしてホストCPUとBlueField-4データ処理ユニット(DPU)を含みます。
各 LPU 計算トレイには、8つの液体冷却式 Groq-3 LPU が搭載され、合計 4GB の SRAM - 拡大表示
そのブレードの背面の一部は、新しい銅製の Ethernet バックプレーン Oberon ETL256 に導かれ、残りはシステムの前面へ向かって配線され、複数の NVL72 および LPX ラックを縫い合わせて統合できるようにします。
単独部品ではない
LPX クラスター上で大規模言語モデル(LLMs)を完全に動作させることは十分に可能ですが、それが Nvidia がこの製品を位置づけている方法ではありません。

この図は、推論ワークロードがGPUとLPUにどのように分散されるかを示しています。画像提供: Nvidia - 拡大するにはクリック
代わりに、1台以上のLPXラックが Vera-Rubin NVL72 と組み合わせられ、Nvidia が1月に披露した際に詳しく議論したように、推論スタックのさまざまな部分がGPUとLPUに分散されています。Nvidiaのリファレンス設計では、計算量の多いプロンプト処理(プリフィル)フェーズを担当するGPUの数は比較的少なく、帯域幅の広いデコードフェーズでトークンが生成される部分は、別のGPUプールとLPUの間で分割されます。
このデコードフェーズでは、NvidiaはGPUの比較的大きなメモリ容量と計算能力を活用してアテンション演算を処理します。一方、帯域幅に制約のあるフィードフォワード型ニューラルネットワーク演算は、Ethernet経由でLPXラックに搭載されたLPUにオフロードされます。
NvidiaのDynamo分散型推論プラットフォームが、これらすべてのオーケストレーションを担当します。
LPUは何個必要ですか?
システム全体には大量のLPUが必要です。
GPUとLPUの正確な比率はワークロード次第です。非常に大きな文脈、バッチサイズ、または同時実行を要するタスクは、より大きなGPUプールを必要とする場合があります。汎用的なチャットボットは、単一のラックでうまく動作することがあります。
これは、より長いコンテキストウィンドウが、モデル状態を格納するキーと値(KV)キャッシュ(短期記憶を想像してください)およびアテンション演算のために、より多くのメモリを必要とするためです。これらをGPU上に保持することで、NvidiaはLPUを少なく済ませることができます。
必要なLPUの実数は、モデルのサイズに直接比例します。パラメータが1兆個のモデルの場合、それは4ラックから8ラックのLPXラック、あるいは重みが4ビットまたは8ビットの精度でSRAMに格納されているかどうかによって、LPUは1,024個から2,048個になります。
LPXは誰のためのものですか?
もしあなたがハイパースケーラー、ネオクラウド、モデル開発者でない場合、LPXはおそらくあなた向けではありません。大規模なオープンモデルを提供するには大量のLPUが必要で、NvidiaのLPXプラットフォームを多くの企業には手の届かないものにする可能性が高いです。
今週の基調講演を前に記者団に語った Buck 氏は、Nvidiaが主に、トークン速度が1秒あたり500〜1,000を超える兆以上のパラメータを持つモデルを提供する必要があるモデルビルダーとサービスプロバイダーに焦点を当てていると述べました。
ただし、技術ブログでは、Nvidiaは LPUs の別の用途として推測デコードアクセラレータを提示しました。これは昨年12月に私たちが同社がやるかもしれないと示唆したものです。
推測デコードは、より小さく、より性能の高い「ドラフト」モデルを使用して大きなモデルの出力を予測することで、推論性能を高める方法です。うまく機能すると、この技術はトークン生成を2倍から3倍の速度に引き上げることができます。
そして、推測が間違っているときは常に大きなモデルに戻るので、品質や精度の低下はありません。
NvidiaはドラフトモデルをLPU上に、より大きなターゲットモデルを一連のGPU上に配置することを提案します。ドラフトモデルは比較的小さい傾向があるため、企業顧客にLPUを販売する機会を生むかもしれません。
Rubin CPX はどうなった?
頭をひねっているかもしれません。「大規模な文脈のプリフィル処理用の特別な Rubin チップがあるはずでは?」と。幻覚を見ているわけではありません。
Computex が開催された前年の春、Nvidia は Rubin CPX を発表しました。遅くて安いGDDR7メモリを使用して、初めのトークンまでの待機時間を短縮し、大きな入力を扱うときにユーザーやエージェントが出力を生成し始めるまでの時間を短くするものです。
このアイデアは、Rubin CPX が大量の文書処理を含むアプリケーションの待機時間を短縮し、非 CPX の Rubin を解放し、全体のデコード時間を短縮できる、というものでした。

Nvidiaの Vera Rubin NVL144 CPX 計算トレイは、現在16個のGPUを搭載します。HBMを搭載した8基と、GDDR7を用いたコンテキスト最適化型のもう8基。拡大するにはクリック
しかし、2026年初頭にはNvidiaはCPXについて言及を止めました。今週、LPXを優先させるためにこのプロジェクトを後回しにしたことが分かりました。
LPXはCPXの代替品ではないことに注意してください。両プラットフォームは推論パイプラインの反対側を加速するよう設計されています。LPUsはデコードフェーズでのトークン生成を高速化するよう設計されており、CPXはプリフィル時にモデルの応答を待つ時間を短縮することを意図していました。
Nvidiaもこの概念を諦めていません。NvidiaのハイパースケールとHPC担当副社長の Ian Buck は、CPX はまだ良いアイデアであり、将来の世代でこの概念が再浮上する可能性があると記者団に語りました。
- Nvidiaの中国でのH200販売、再開しました
- チップ... 宇宙へ – Nvidia提供
- Nvidiaは256個の Vera プロセッサを搭載した新しいラックシステムでCPU市場へ更なる一歩
- Nvidia、AI応答時間を短縮するため、200億ドル相当のGroq技術を巨大な新LPXラックに投入
ラック規模アーキテクチャのアルファベットスープ
LPX は Nvidia のラック規模ラインアップで最も興味深い追加ですが、唯一ではありません。
GTC では、Nvidia はネットワーキング、ストレージ、エージェント型計算のそれぞれに 1 つずつ、計 3 つのラック規模デザインを発表しました。
今週初めに Nvidia の新しい Vera CPUラックを詳しく見ましたが、このシステムは LPXラックおよび HGX システムと同じ ETL ネットワークバックプレーンを使用し、32 の計算ブレードを備え、それぞれに 88 コアの Vera CPU を 8 基搭載し、オンボードで最大 12 TB の LPDDR5X SOCAMM メモリモジュールを搭載しています。
Nvidia の最新世代製品のホストプロセッサとして機能するだけでなく、Vera CPUラックは Open Claw のようなエージェント型システムの実行環境として設計されており、高いメモリ帯域幅と単一スレッド性能を必要とします。
CPUラックの隣には、BlueField-4 STXと呼ばれる新しいストレージラックがあります。名前が示すとおり、リファレンス設計は Nvidia の BlueField-4 データ処理ユニット(DPU、別名 SmartNIC)を Vera CPU と ConnectX-9 NIC と組み合わせたものです。Nvidia はこの提供物を KV-cache のオフロード先として機能させることを意図しています。
LLM がプロンプトを処理するたび、モデル状態をベクトルとして格納する KV キャッシュを生成します。これらの事前計算済みベクターを GPU やシステムメモリ、またはフラッシュストレージに保持することで、新しいトークンのみを計算すればよく、繰り返し発生するトークンはキャッシュから再利用できます。
今年の初め、Nvidia 披露した そのコンテキストメモリストレージプラットフォームは、KVキャッシュを互換性のあるストレージターゲットへ自動オフロードすることを目的としています。AIインフラストラクチャ大手は、このアプローチにより推論パイプラインの他の要素を処理するために GPU リソースを解放することで、トークンレートを最大 5 倍まで引き上げられると主張しています。
最後に、Spectrum-6 SPX ネットワークラックがあり、Spectrum-X と Quantum-X スイッチのケーブリングを簡略化するために MGX ETL リファレンス設計を活用しています。
これらのラックシステムは、いわば組立ラインのようなものを形成します。次のように考えてください。Vera CPU ラックが AI エージェントを実行している間、Groq LPX デコード加速器を搭載した Vera-Rubin NVL72 システム上でモデ ルを実行します。これらのエージェントによって生成された KV キャッシュは STX ストレージへオフロードされ、すべては Spectrum または Quantum スイッチを搭載した SPX ラックで接続されます。そして、AI ブームが続く限り、Nvidia は引き続き巨額の収益を上げています。 ®