Google、Gemma 4で中国のオープン・ウェイト・モデルに対抗
より寛容なライセンス、マルチモーダル対応、140以上の言語へのサポートを追加
Googleは木曜、エージェント型AIとコーディング向けに最適化された新しいオープン・ウェイトのGemmaモデル群を解禁した。狙いは、より寛容なApache 2.0ライセンスによって企業の取り込みに勝つことだ。
今回の発表は、Moonshot AI、Alibaba、Z.AIから相次いで押し寄せているオープン・ウェイトの中国製大規模言語モデル(LLM)――その多くは、いまやOpenAIのGPT-5やAnthropicのClaudeに対抗できる水準にある――の波の真っただ中で行われた。
最新リリースでGoogleは、法人のお客様に国内向けの代替案を提供する。しかし、それは将来のモデルを作るために、機密を含む社内データをただ吸い上げるようなものではない。
GoogleのDeepMindチームによって開発された第4世代のGemmaモデルは、数々の改善をもたらす。数学や指示への従従の性能を高めるための「高度な推論」、140以上の言語対応、ネイティブな関数呼び出し、そして動画および音声の入力に対応している。
これまでのGemmaモデルと同様に、Googleは単一ボードコンピュータやスマートフォンからノートPC、そして企業のデータセンターまで幅広い用途に対応できるよう、複数のサイズで提供している。
スタックの最上位に位置するのは、310億パラメータのLLMで、Googleによれば出力品質を最大化するようチューニングされている。
サイズ的に見て、同モデルがGoogleのより大きな独自モデルを食い潰すリスクはない。しかし、企業がGPUサーバーを何十万ドルも投じて走らせたり微調整したりする必要がない程度には小さい。
Googleによれば、このモデルは単一の80 GB H100で、量子化なしの16ビットで動かせるとのこと。一方で4ビット精度では、このモデルは小さくなるため、Llama.cppやOllamaといったフレームワークを使えば、Nvidia RTX 4090やAMD RX 7900 XTXのような24 GB GPUに収まる。
より低いレイテンシ、つまりより速い応答が必要なアプリケーション向けに、Gemma 4ラインナップには、混合専門家(MoE)アーキテクチャを採用した260億パラメータのモデルも含まれている。
推論(inference)では、モデルの128の専門家のうちの一部が選ばれ、合計38億のアクティブパラメータで、各トークンの処理と生成が行われる。モデルをVRAMに収められる限り、同等規模の密(dense)モデルよりもはるかに高速にトークンを生成できる。
この高い速度は、出力の処理に使われるのがパラメータの一部だけであるため、その代わりに出力の品質が低下するというコストを伴う。とはいえ、ノートPCや家庭用のグラフィックスカードのように、メモリ速度が遅いデバイスで動かすなら、その価値があるかもしれない。
これら2つのモデルはいずれも256,000トークンのコンテキストウィンドウを備えており、ローカルのコードアシスタント用途に適している。これは、Googleがローンチ発表で強調した用途でもある。
これらのモデルに加えて、スマートフォンやラズベリーパイのようなシングルボードコンピュータといった、ローエンドのエッジハードウェア向けに最適化されたLLMが2本ある。これらのモデルは2つのサイズで提供されており、1つは20億の有効パラメータ、もう1つは40億。
ここでのキーワードは「有効(effective)」だ。実際のパラメータ数はそれぞれ51億と80億だが、層ごとの埋め込み(PLE)を使うことで、計算(compute)の観点からモデルの有効サイズを2.3億〜45億パラメータにまで減らし、計算量が限られたデバイスやバッテリー駆動環境でより効率よく動かせるようにしている。
サイズにもかかわらず、2つのモデルはいずれも128,000トークンのコンテキストウィンドウを備え、マルチモーダル対応だ。つまり、テキストに加えて、視覚データや音声データ(E2B/E4Bのみ)を入力として受け取れる。
ベンダーが提示するベンチマークである以上、これらの主張は割り引いて受け止めるべきだが、Gemma 3と比べて、GoogleはさまざまなAIベンチマークで大幅な性能向上を誇っている。
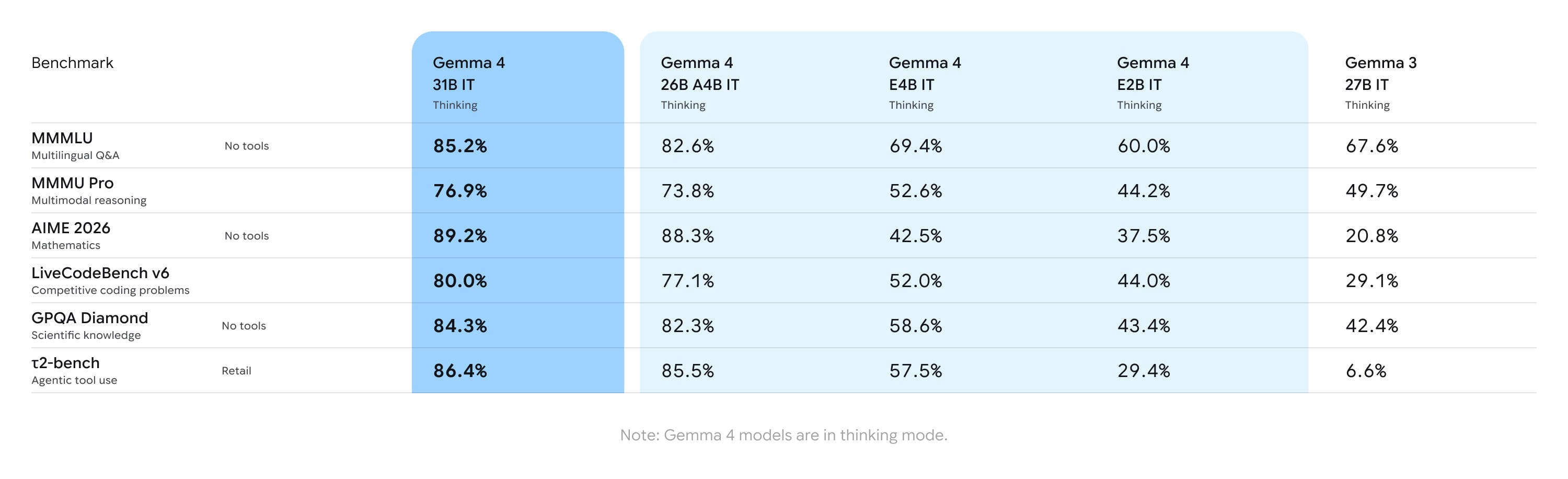
GoogleによるとGemma 4は前世代のオープンウェイトモデルと比べてどう違うのか:要点を素早くまとめました(クリックで拡大)
しかし、Gemma 4の最も重要な変更は、おそらく、より許容度の高いApache 2.0ライセンスへの切り替えだろう。これにより、企業はモデルをどのように、どこで使う/展開するかについて、より大きな柔軟性を得られる。
これまで、GoogleのGemmaライセンスでは、特定のシナリオにおけるモデルの使用が禁止されていたほか、ルールを守らなかった場合にユーザーのアクセスを停止する権利が留保されていた。
Apache 2.0への移行によって、企業はGoogleが土台から覆してくることを恐れることなく、モデルを展開できるようになる。
Gemma 4は、GoogleのAI StudioおよびAI Edge Galleryの各サービスに加え、Hugging Face、Kaggle、Ollamaのような人気のモデルリポジトリでも利用可能だ。
ローンチ時点でGoogleは、vLLM、SGLang、Llama.cpp、MLXなどを含む、10以上の推論フレームワークでの初日からのサポートを主張している。 ®
より掘り下げたトピック
- AIOps
- Amazon Bedrock
- アンソロピック
- ChatGPT
- 中国移動
- 中国電信
- 中国聯通
- 中国のサイバー空間管理
- DeepSeek
- ディザスタリカバリ(災害復旧)
- Gemini
- Google Brain
- GPT-3
- GPT-4
- 万里の長城ファイアウォール
- 香港
- 中国人民共和国の情報技術
- JD.com
- 機械学習
- MCubed
- ニューラルネットワーク
- NLP
- オープン・コンピュート・プロジェクト
- PUE
- リトリーバル・オーグメンテッド・ジェネレーション(RAG)
- 台湾積体電路製造
- シンセン
- ソフトウェア定義データセンター
- スター・ウォーズ
- テンソル処理装置
- TOPS
- ウイグル系ムスリム
関連するより広いトピック
このほかにも
より絞り込んだ話題
- AIOps
- Amazon Bedrock
- Anthropic
- ChatGPT
- 中国移動
- 中国電信
- 中国聯通
- 中国のサイバー空間管理局
- DeepSeek
- ディザスタリカバリ
- Gemini
- Google Brain
- GPT-3
- GPT-4
- 張り巡らされた偉大なファイアウォール
- 香港
- 中華人民共和国の情報技術
- JD.com
- 機械学習
- MCubed
- ニューラルネットワーク
- NLP
- Open Compute Project
- PUE
- リトリーバル拡張生成
- 半導体製造インターナショナル・コーポレーション
- 深圳
- ソフトウェア定義データセンター
- スター・ウォーズ
- テンソル処理装置
- TOPS
- ウイグル人のムスリム




