LLM 0.32a0 は、大きな後方互換性のあるリファクタリング
2026年4月29日
私は LLM 0.32a0 をリリースしたばかりです。これは、LLM にアクセスするための私の LLM Python ライブラリおよび CLI ツールのアルファ版で、かなり長い間取り組んできた結果として生まれた、いくつかの重要な変更が含まれています。
それまでの LLM のバージョンは、世界を「プロンプト」と「応答」の観点でモデル化していました。モデルにテキストのプロンプトを送ると、テキストの応答が返ってくる、という形です。
import llm model = llm.get_model("gpt-5.5") response = model.prompt("Capital of France?") print(response.text())
これは、私が 2023年4月にこのライブラリの開発を始めた当時は理にかなっていました。しかし、その後いろいろと変わりました!
LLM は、その プラグインシステム を通じて、何千もの異なるモデルを扱うための抽象化を提供します。最初の抽象化――「テキスト入力を受け取り、テキスト出力を返す」――では、私がそれに表現させたかったすべてを表しきれなくなっていました。
時間の経過とともに、LLM 自体が attachments を成長させ、画像・音声・動画の入力を扱えるようになり、次に schemas で構造化された JSON を出力できるようになり、さらに tools でツール呼び出しを実行できるようになりました。一方で、LLM は進化を続け、推論のサポートが追加されたり、画像を返せるようになったり、他にもいろいろと面白い能力が増えていきました。
LLM は、今日の最先端モデルで処理可能なさまざまな入力・出力タイプの多様性を、よりうまく扱うよう進化する必要があります。
0.32a0 のアルファには、2つの重要な変更があります。モデルの入力はメッセージのシーケンスとして表現でき、モデルの応答は、異なる型のパーツのストリームとして構成できるようになりました。
メッセージのシーケンスとしてのプロンプト
LLM は入力をテキストとして受け取りますが、ChatGPT が「双方向の会話インターフェイス」の価値を示して以来、プロンプトとして最も一般的なのは、この入力を会話のターンのシーケンスとして扱うことでした。
最初のターンは、たとえば次のようになります:
user: Capital of France?
assistant:
(その後、モデルはアシスタントからの返信を埋めることになります。)
しかし、その後の各ターンでは、ある種の脚本のように、そこまでの会話全体を最初からリプレイする必要があります:
user: Capital of France?
assistant: Paris
user: Germany?
assistant:
主要ベンダーの JSON API の多くは、このパターンに従っています。以下は、他のプロバイダによって広く模倣されている OpenAI の chat completions API で上記のものを表した例です:
curl https://api.openai.com/v1/chat/completions \ -H "Authorization: Bearer $OPENAI_API_KEY" \ -H "Content-Type: application/json" \ -d '{ "model": "gpt-5.5", "messages": [ { "role": "user", "content": "Capital of France?" }, { "role": "assistant", "content": "Paris" }, { "role": "user", "content": "Germany?" } ] }'
0.32 より前の LLM では、これらを会話としてモデル化していました:
model = llm.get_model("gpt-5.5") conversation = model.conversation() r1 = conversation.prompt("Capital of France?") print(r1.text()) # 出力は "Paris" r2 = conversation.prompt("Germany?") print(r2.text()) # 出力は "Berlin"
これは、モデルと会話を最初から作り上げるような場合にはうまく動きましたが、最初から過去の会話を投入する方法は提供されていませんでした。そのため OpenAI chat completions API のエミュレーションのようなタスクは、本来あるべきよりもはるかに難しくなっていました。
llm CLI ツールは、SQLite を使って会話を永続化し、膨張(復元)するための独自の仕組みによってこの問題を回避していました。しかし、それは LLM API の安定した一部にはなりませんでした――また、ストレージ層として SQLite をコミットせずに Python ライブラリを使いたい場面は多々あります。
新しいアルファでは、これに対応しました:
import llm from llm import user, assistant model = llm.get_model("gpt-5.5") response = model.prompt(messages=[ user("Capital of France?"), assistant("Paris"), user("Germany?"), ]) print(response.text())
llm.user() と llm.assistant() は、その messages=[] 配列の中で使うことを想定して設計された、新しいビルダ関数です。
以前の prompt= オプションも引き続き動作しますが、LLM 側が裏でそれを 1 要素の messages 配列にアップグレードします。
また、会話を構築する代わりに、レスポンスに対して 返信 することもできるようになりました:
response2 = response.reply("ハンガリーはどう?") print(response2) # デフォルトの __str__() は .text() を呼び出します
ストリーミングのパーツ
アルファ版で、プロンプトからの結果をストリーミングとして返す点に関するもうひとつの主要な新しいインターフェースがあります。
これまで、LLM は次のようなストリーミングをサポートしていました:
response = model.prompt("自転車に乗るペリカンのSVGを生成して") for chunk in response: print(chunk, end="")
あるいは、次のような非同期バリアント:
import asyncio import llm model = llm.get_async_model("gpt-5.5") response = model.prompt("自転車に乗るペリカンのSVGを生成して") async def run(): async for chunk in response: print(chunk, end="", flush=True) asyncio.run(run())
今日の多くのモデルは、混在する種類のコンテンツを返します。Claude に対してプロンプトを実行すると、推論出力が返され、その後にテキストが続き、さらにツール呼び出しのための JSON リクエストが返され、その後にテキストコンテンツが続く、といったことが起こり得ます。
中には、サーバー側でツールを実行できるモデルもあります。例えば OpenAI の code interpreter ツール や Anthropic の web search です。つまり、モデルの結果は、テキスト、ツール呼び出し、ツール出力、そしてその他の形式を組み合わせたものになり得ます。
また、マルチモーダル出力モデルも登場し始めており、そのストリーミング応答の中に画像や、さらには 音声の断片 が混在して返されることがあります。
新しい LLM アルファ版では、これらを「型付きのメッセージパーツのストリーム」として表現します。以下は、それを Python API の利用者の観点で見たときのイメージです:
import asyncio import llm model = llm.get_model("gpt-5.5") prompt = "かっこいい犬を3匹考えて。まずはあなたの動機について話して" def describe_dog(name: str, bio: str) -> str: """架空の犬の名前と伝記を記録する。""" return f"{name}: {bio}" def sync_example(): response = model.prompt( prompt, tools=[describe_dog], ) for event in response.stream_events(): if event.type == "text": print(event.chunk, end="", flush=True) elif event.type == "tool_call_name": print(f" ツール呼び出し: {event.chunk}(", end="", flush=True) elif event.type == "tool_call_args": print(event.chunk, end="", flush=True)async def async_example(): model = llm.get_async_model("gpt-5.5") response = model.prompt( prompt, tools=[describe_dog], ) async for event in response.astream_events(): if event.type == "text": print(event.chunk, end="", flush=True) elif event.type == "tool_call_name": print(f" ツール呼び出し: {event.chunk}", end="", flush=True) elif event.type == "tool_call_args": print(event.chunk, end="", flush=True) sync_example() asyncio.run(async_example())
サンプル出力(最初の同期例だけから):
私の動機: 個性のある「クール」なスタイルを持つ3匹の記憶に残る犬を作りたい――1匹は映画的に、1匹は冒険的に、そしてもう1匹は愛らしくてめちゃくちゃな感じに。そうすれば、それぞれが自分の物語に出演していそうに感じられるはずだから。
ツール呼び出し: describe_dog({"name": "Nova Jetpaw", "bio": "小さな飛行家ゴーグルを身につけていて、月明かりのビーチ沿いを全力で走るのが大好きな、スレンダーなシルバーグレーのウィペット。Novaは恐れを知らず、上品で、噂では楽しみのためだけにドローンより速く走れるらしい。"}
ツール呼び出し: describe_dog({"name": "Mochi Thunderbark", "bio": "ドラマチックなブラック&ゴールドのバンダナを巻いた、ふわふわのコーギー。ロックスターの自信を持っている。Mochiは背が低くて声が大きく、忠実で、リスだけで構成された近所の『セキュリティ・パトロール』を率いている。"}
ツール呼び出し: describe_dog({"name": "Atlas Snowfang", "bio": "氷のように青い目を持つ、大きな白いハスキー。バックパックにはトレイルのおやつが詰まっている。Atlasは落ち着いていて、英雄的で、吹雪や霧や紛らわしいキャンプの旅の最中でも、いつも帰り道を知っている。"}
応答の最後で、要求された関数を実際に実行するためにresponse.execute_tool_calls()を呼び出すことができます。または、ツールを呼び出してその戻り値をモデルに返すためにresponse.reply()を送信することもできます:
print(response.reply("犬について教えて"))
この新しいストリーミング用の仕組みにより、CLIツールは最終応答のテキストとは別の色で「考えている」テキストを表示できるようになりました。思考テキストはstderrに送られるため、他のツールへパイプされた結果には影響しません。
この例では、Claude Sonnet 4.6(llm-anthropicプラグインのストリーミングイベントのバージョンを更新したもの)を使っています。Anthropicのモデルは、応答の一部として推論テキストを返すためです:
llm -m claude-sonnet-4.6 'まずはクールな犬を3匹考えて、それらを説明して' \
-o thinking_display 1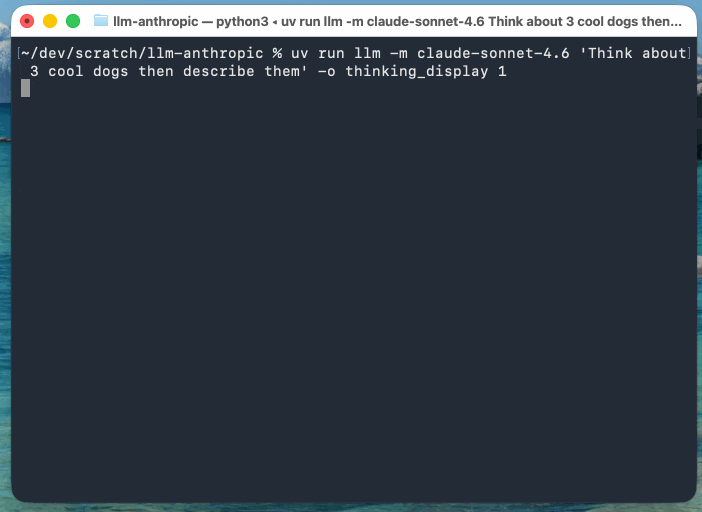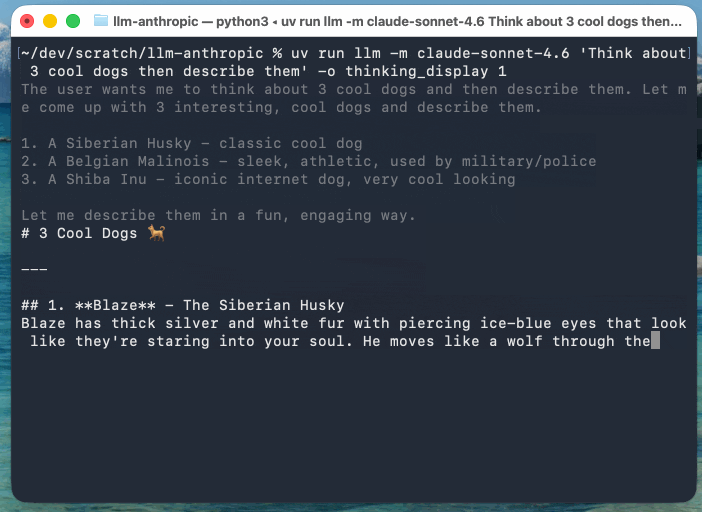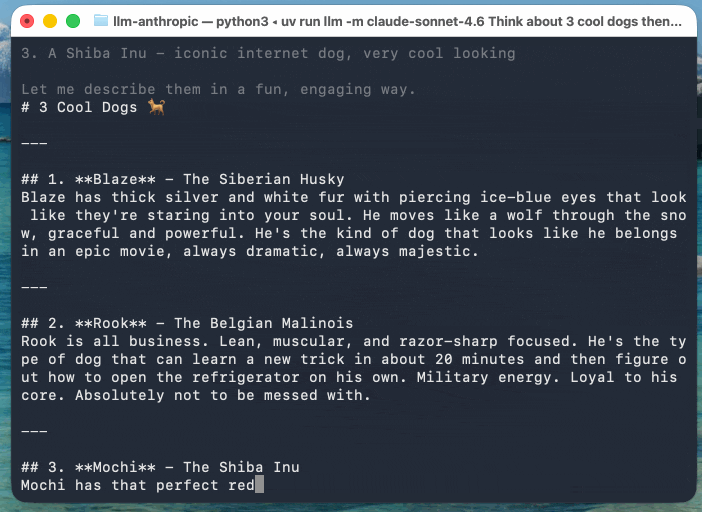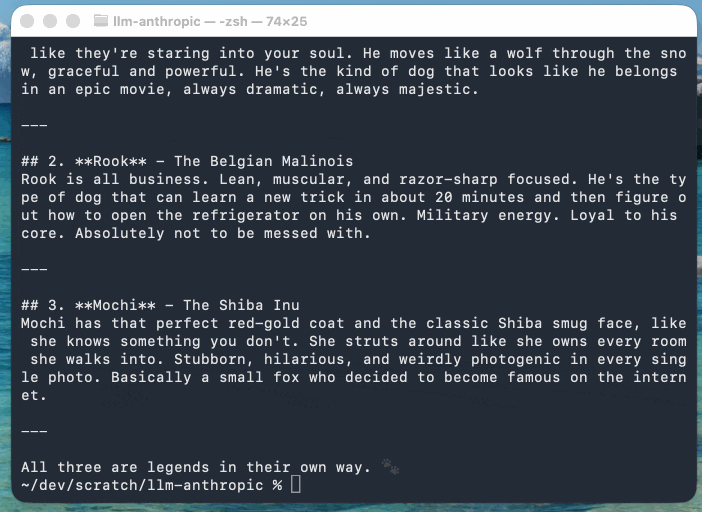
新しい -R/--no-reasoning フラグを使うことで、推論トークンの出力を抑制できます。驚くべきことに、このリリースでCLIに直接関係する変更はそれが唯一でした。
応答をシリアライズ/デシリアライズするための仕組み
先ほども述べたとおり、現時点のLLMは、SQLiteに会話を保存するためのコードがかなり柔軟性に欠けます。そこで、0.32a0で新しい仕組みを追加しました。これにより、Python APIのユーザーが自分用の代替を作れるようになるはずです:
serializable = response.to_dict() # serializableはJSONスタイルの辞書です # 好きな場所に保存してから膨らませる(復元する): response = Response.from_dict(serializable)
この辞書が返す内容は、実際には新しい llm/serialization.py モジュール内で定義された TypedDict です。
次は?
いくつかのプラグインをアップグレードし、この新しい設計を現実の環境で数日間テストしたいので、これをアルファとしてリリースします。アルファテストで、ここまで組み立てた過程のどこかに設計上の欠陥が見つからない限り、安定版0.32リリースは、このアルファと非常によく似たものになると見込んでいます。
残っている大きな作業が1つあります。新しいこの抽象化によって返される、より細かな粒度の詳細をうまく取り込めるように、SQLiteのログ記録システムを再設計したいです。
理想的には、グラフとしてモデル化したいです。そうすることで、同じ会話が絶えず拡張され、そしてプロンプトのたびに繰り返し実行されるようなOpenAI風のチャット補完APIのような状況に最もよく対応できます。
それらをデータベースに複製せずに保存できるようにしたいです。
それを0.32の機能にするのがいいのか、それとも0.33まで待つべきなのかはまだ決めていません。
さらに最近の記事
- 現在は亡くなったOpenAI Microsoft AGI条項の履歴を追跡する - 2026年4月27日
- DeepSeek V4 - フロンティアにかなり近い、しかも価格は一部 - 2026年4月24日
これは LLM 0.32a0 は主要な後方互換性を保つリファクタリング であり、サイモン・ウィリソンによって執筆され、2026年4月29日に公開されました。
シリーズ LLMの新リリース の一部
- CLIでJPEGフレームのシーケンスとしてビジョンLLMに動画を渡す(LLM 0.25も含む) - 2025年5月5日、午後5:38
- LLMはLLM 0.26で、ターミナル上でツールを実行できる - 2025年5月27日、午後8:35
- LLM 0.27、注釈付きリリースノート:GPT-5 と改良されたツール呼び出し - 2025年8月11日、午後11:57
- LLM 0.32a0 は主要な後方互換性を保つリファクタリング - 2026年4月29日、午後7:01
前: 現在は亡くなったOpenAI Microsoft AGI条項の履歴を追跡する
月次ブリーフィング
月10ドルで私をスポンサーして、今月の最も重要なLLMの動向を厳選したメールダイジェストを受け取ってください。
送る手間を減らすために、私にお金を払ってください!
スポンサー&購読



