親愛なる皆さんへ、
ビジネスはAIを単なる効率向上のために使うのを超え、どうすれば変革的なインパクトを生み出せるのでしょうか?私は今、スイス・ダボスの世界経済フォーラム(WEF)からこの手紙を書いています。ここで多くのCEOと成長のためのAI活用について話をしてきました。共通するテーマは、多くの実験的なボトムアップのAIプロジェクト―いわゆる「千の花を咲かせる」―は大きな成果に結びついていないということです。むしろ、大きな進歩を得るにはワークフローの再設計、つまりより広く、場合によってはトップダウンの視点でプロセスの複数のステップを見直し、端から端まで一体化する変革が必要です。
銀行のローン発行プロセスを考えてみましょう。ワークフローはいくつかの段階から成ります:マーケティング -> 申請 -> 仮承認 -> 最終審査 -> 実行
もし各ステップが手作業だったとします。仮承認はかつては人間が1時間かけて審査していましたが、新しいエージェントシステムはこれを10分で自動化できます。人による審査をAIに置き換え、他は変えなければ、小さな効率改善にとどまり、変革的ではありません。
変革的なのはこうです。申請者が人間の審査を1週間待つ代わりに、10分で決定が下るとします。すると、ローンはより魅力的な商品となり、その向上した顧客体験によって貸し手はより多くの申請を引き寄せ、最終的により多くのローンを発行できます。
しかし、この変化を起こすには技術的視点だけでなく、ビジネスや製品のより広い視点が必要です。また、ローン処理のワークフローも変わります。「10分でローン」という商品提供に切り替えるには、マーケティング戦略の変更や申請のデジタル化と効率的な振り分け、最終審査と実行の再設計が必要となり、より多くの処理量に対応しなければなりません。

AIを用いるのは仮承認の1ステップだけでも、我々は単なる局所解決策ではなく、商品の変革をもたらす広範なワークフローの再設計を実施しています。
私が共同主催するAIコンサルティング企業AI Aspireでは、以下のように考えています。ボトムアップのイノベーションは現場に近い人が解決策を最初に目にできるため重要です。しかし、これらのアイデアを拡大し変革的な効果を生み出すには、AIがプロセス全体を端から端まで変革できるように捉える必要があり、そこにトップダウンの戦略的指針とイノベーションが役立ちます。
今年のWEFの会議は、昨年までと同様に活気にあふれる場でした。技術者同士のよく話題に上るテーマは、エージェンシーAI(私がこの言葉を作った時は、まさか看板や建物中に打ち出されるとは思いませんでした!)、主権AI(各国がAIへのアクセスを制御する方法)、人材(新卒者の厳しい労働市場と国家の再スキル獲得)、データセンターインフラ(エネルギー、人材、GPUチップ、メモリのボトルネック解消)などです。今後の手紙でこれらの話題にも触れます。
増す地政学的な不安定さの中で、AIコミュニティ全員が国境を越えた架け橋を築き、オープンソースを通じた共有を進め、すべての国とすべての人々に利益をもたらすための構築を続けることを願っています。
引き続き頑張りましょう!
アンドリュー
DEEPLEARNING.AIからのメッセージ

Gemini CLIを使ってコマンドラインからマルチステップのワークフローを構築する方法を学びましょう。Gemini CLIはローカルファイル、開発者ツール、クラウドサービスを横断して動作するオープンソースのエージェントです。コーディングタスクの自動化、ソフトウェア機能の構築、ダッシュボード作成、コード以外へのエージェントワークフローの適用などが可能です。今すぐ登録
ニュース
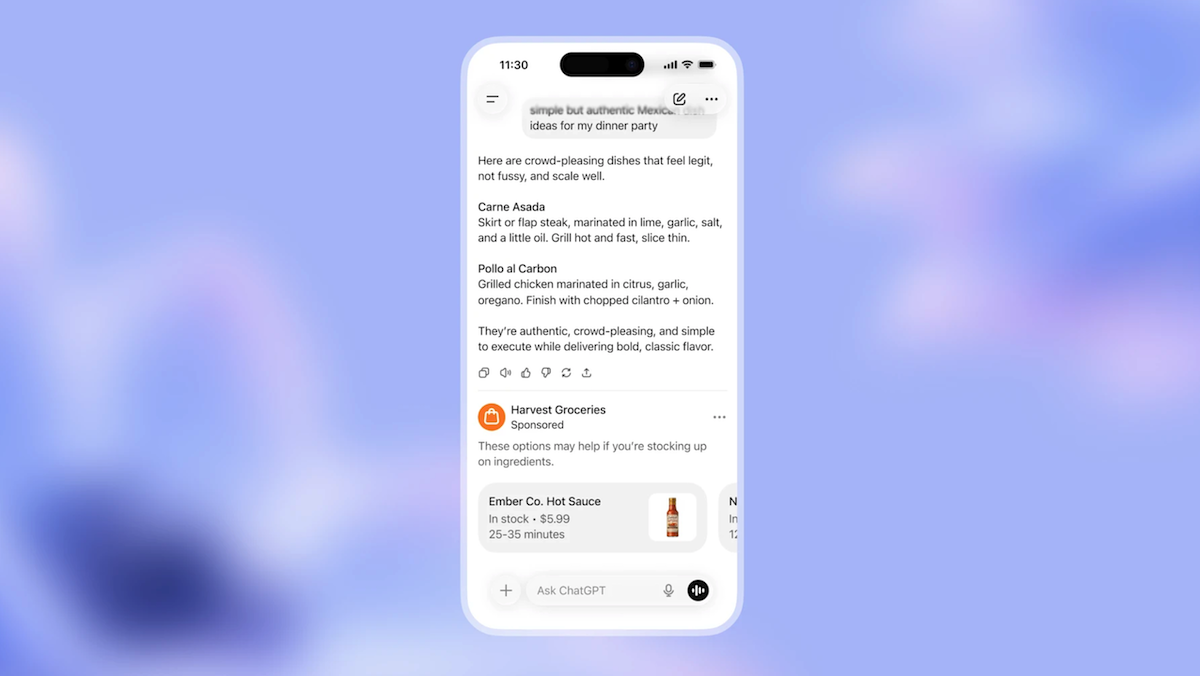
ChatGPTに広告表示開始
AIに新しい収益源が加わりました。形は昔ながらのウェブバナー広告に似ています。
新情報: OpenAIはChatGPTに広告のテストを開始しました。広告は米国のOpenAIの無料プランおよび最も低価格なプランのユーザーに表示され(ChatGPT Plus、Pro、Business、Enterpriseの有料層やAPIユーザーには表示されません)、今後他の地域やより会話的な広告の試験も予定されています。
仕組み: 会話に関連した広告がチャットの下部に短いメッセージ、画像、リンク付きで表示されます。チャットの応答には影響しません。広告は米国の成人でログイン中のChatGPTウェブサイトやアプリのデスクトップ・モバイル版利用者のみに表示されます。
- 見た目: 広告は明確にラベル付けされチャット応答から分離されています。ユーザーは広告を閉じたりフィードバックを送れます。
- プライバシー: 健康やメンタルヘルス、政治についてのチャットでは広告が表示されません。会話内容が広告主に共有されることもありません。
- 設定: 広告はチャット履歴、位置情報、ChatGPTに共有された個人情報に基づいてパーソナライズされています。ユーザーはパーソナライズのON/OFF切替、広告ターゲティングに使うデータのリセット、またはチャット履歴の全削除ができます。
- 今後の予定: 広告は将来的にさまざまなレイアウトや地域、利用プランに拡大する可能性があります。OpenAIはモバイルアプリの上部に表示されるディスプレイ広告のモックアップも公開しています。今後は広告内容についてユーザーが質問できる機能も検討中です。広告非表示プランは常に提供し続ける予定ですが、有料プランへの広告拡大は未定です。
背景: OpenAIは利益を生む十分な収入をどう確保するか模索中です。同社は2025年に200億ドルの収益と1.9ギガワットの計算資源を使用し、コストは90億ドル超と推定されています。(2023年以降、収益も処理能力も年率約3倍に成長)また2029年までに1150億ドルの資本支出を見込んでいるとThe Informationは報じています。広告はサブスクリプション、eコマース、API使用量に基づくモデルと並ぶ収益戦略の一部です。
- サブスクリプション: OpenAIはChatGPTの週間・月間アクティブユーザー数が過去最高を記録し続けていると述べましたが、具体的数値や無料・有料プランの内訳は公開していません。CEOサム・アルトマンは10月にChatGPTが8億の週間アクティブユーザー数に達したと発表しており、うち約3500万人がPlusまたはProプランの有料加入者と報じられています。
- 地域別価格: OpenAIはChatGPT Goという低価格制限付きプランをインドで試験開始し、世界展開を発表。米国では月8ドル、一部地域では安価(例:インドで月₹399=約4.40ドル)で利用可能です。
- eコマース: 9月からOpenAIはエージェント機能を活用したショッピングを導入。ログインしたユーザーはEtsy、Shopify、Walmartなど参加店舗の商品をChatGPT内で購入可能です。現在のテスト段階で広告商品が直接購入可能かは未確認です。
重要性: 急成長する世界市場にAIを提供するには莫大な費用がかかり、ビジネス戦略は依然流動的です。Googleなど他の大手企業は複数の事業により費用を補えますが、OpenAIはそうではありません(Googleもチャットボット広告の実験を行っています)。広告と低価格ChatGPTサブスクの組み合わせは新たな収益路を開きます。成功すれば有料プランが無料利用者を完全に補助する状況は変わり、有料ユーザーは少なくとも今のところ広告なし利用を維持できます。
所感: OpenAIは実績のあるディスプレイ広告で様子見していますが、本物のチャットボットネイティブ広告はもっと大きく異なる可能性があります。

自動運転車へ推論能力を訓練
チェーンオブソート(段階的推論)は自動運転車の次の行動決定に役立つ。
新情報: Nvidiaは推論を活用して衝突リスクを減らす認知言語行動モデルAlpamayo-R1を公開した。
- 入出力: 4台のカメラ映像2秒分、テキスト指示、位置と回転履歴を入力。推論テキストと車両将来の軌跡6.4秒分(位置と回転)を99ミリ秒で出力(Nvidia RTX Pro 6000[Blackwell]上)
- 構成: Transformerエンコーダ(82億パラメータ)、Transformerデコーダ(23億パラメータ)
- 性能: シミュレーション環境で他車との「ニアミス」が減少(距離は非公開)
- 公開: 学術利用・非商用利用可能な重みファイルはダウンロード可
- 非公開: 競合モデル比較、使用データセット、報酬モデル等
仕組み: Alpamayo-R1はCosmos-Reason1(行動記述学習済み視覚言語モデル)と車両軌跡生成のディフュージョントランスフォーマの組み合わせ。動画フレームや軌跡データ、テキスト指示を与え推論テキストを生成。推論テキストや映像特徴量を使い将来軌跡を出力。訓練は3段階:
- 医療、物流、小売、製造、自動運転含む多数分野での行動生成訓練。
- 8万時間の動画や人・機械作成推論ラベル付き車両動作を用いて推論および行動生成訓練。推論テキストは各動画フレームで最大2つの決定と複数の根拠を含む(例:横断歩道の歩行者、合流車線、工事中)。
- 強化学習により推論スキルおよび推論と行動整合性を向上。報酬は(i)非公開モデルによる推論整合度、(ii)ルールに基づく推論と行動整合度、(iii)行動の正確度、衝突回避、車両の滑らかさに基づく。
結果: 推論モデルは推論未使用モデルよりシミュレーションの75シナリオ中、ニアミス頻度が17%から11%へ減少。
重要性: チェーンオブソート推論はロボットに有効。以前の視覚言語行動モデルは性能向上のみを目指したが、Alpamayo-R1は推論と行動の調和も訓練し、より効果的かつ解釈しやすい推論を実現。問題が起きた場合も推論内容を調査可能で今後の改善に役立つ。
所感: 過去1年で数学、科学、コーディング、画像理解、ロボット領域で推論モデルが非推論モデルを上回る結果を示した。チェーンオブソートは非常に有用なアルゴリズムである。

Appleの基盤モデルはGeminiに
AppleはGoogleと数年契約を結び、Apple端末上のAIモデルの基盤にGeminiモデルを用いる。
新情報: 両社は共同声明で、AppleがGoogle技術を使ってSiriやその他AI機能を刷新すると発表。連携成果は2026年春から順次展開予定。具体的な契約内容は非公表。
仕組み: BloombergはSiri刷新計画と提携噂を報じている。情報の多くはこれらの報道および追加情報による:
- 契約はクラウドコンピューティング契約で、Appleは年間10億ドル支払うとBloombergが報告、Financial Timesも報じた。
- AppleはAppleサーバーで動作調整済みの1.2兆パラメータGeminiモデル(社内名Apple Foundation Models Version 10)にアクセス可能。より高性能なVersion 11も今年後半に提供予定で、Googleサーバー上で動作する可能性。AppleはGoogleモデルをファインチューニングし、ユーザーインターフェースを管理する。The Informationが報道。
- Siriの更新は二段階で進む。iOS 26.4にVersion 10を利用し画面画像解析やユーザーデータ基づく出力対応。iOS 27ではVersion 11を活用し、ウェブ検索、メディア生成、ファイル解析、メール・音楽・写真など各種アプリとの対話が可能な音声・テキストチャットボットに。
- 新Siriは画面画像とメール、メッセージ、カレンダー、過去の会話履歴を文脈として活用。写真検索・編集・送信など複数段階エージェント行動も実現。LLMやエージェントに共通な物語生成、感情サポート、旅行手配なども行う。
- Appleは12月にOSに統合したChatGPT利用も続行する。Siriの問い合わせが自社モデルで答えられない場合、OpenAIモデルにルーティング可。SiriはユーザーにChatGPT利用希望を尋ねることも可能。ただしOpenAIはAppleのAI機能の中核にはならない。CEOサム・アルトマンはAppleから巨額収益を期待しGoogleに代わる検索パートナーになる望みを持っていたが、Appleは独自の戦略を優先(元iPhone設計責任者ジョニー・アイブ率いる新モバイル端末開発)しているとFinancial Times。
背景: この提携は、Appleが先進的AIソフトウェアとインフラの自社構築から撤退しつつあることを示す。状況は過去何度も報じられており、昨年BloombergはAppleがAnthropic、Google、OpenAIのモデルを評価していると報告した。
- 6月にはSiri更新が社内品質基準未達で遅延と報告されている。
- 2023年には内部利用のみのApple GPTチャットボットを開発、LLMフレームワークも構築した。
- 競合のGoogle、Microsoft、OpenAIらが大きく先行し、SiriはAI分野で後れを取ったと見なされている。
意義: AppleはGoogleとの提携で多大なコストをかけた最先端AIの内製競争から降りる一方、売上の半分を占める主力製品iPhoneのAI競争力を短期的に確保。競合がGoogleという皮肉もあるが、iOS端末のAI機能強化に道を拓く。
所感: GoogleはiPhoneのデフォルト検索エンジン提供権で年間200億ドル支出。AppleがGoogleへ10億ドル払い先端モデルを利用するのは割安に見え、Google、OpenAI、Anthropicを巧みに競合させている可能性も高い。iPhone支配力の強大さがうかがえる。

詳細なテキストまたは画像からの高速3D生成
現行のテキストや画像から3Dシーンを生成する手法は遅く、一貫性に欠ける。研究者らは、高品質で整合性のある3Dシーンを数秒で生成する技術を開発した。
新情報: 厦門大学、Tencent、復旦大学の共同研究チームはFlashWorldを発表。テキスト記述または画像入力からガウススプラット(色付きの半透明楕円体)という表現で高品質3Dシーンを生成可能。コードはApache 2.0で商用・非商用利用可能、モデルは非商用利用可でダウンロード可能。
着眼点: 3D生成には主に2つのアプローチがある。1つは2Dファースト方式で、多角度からの2D画像を多数生成し3Dを構築。詳細な表面を得られるが整合性に課題。もう1つは3D直接生成方式で、一貫性を保てるが詳細やフォトリアリズムが乏しい。両者の長所を合わせ、学習により詳細表現と3D整合性を両立させる。高速化のために、教師モデルの多段階洗練を1ステップで模倣する能力を習得させる。
仕組み: FlashWorldは事前学習済みビデオディフュージョンモデル(WAN2.2-5B-IT2V)とその3D出力対応修正版デコーダから構成。動画、多視点画像、物体マスク、カメラパラメータ、3D点群を含む複数の公開データセットと独自の3Dシーン対応テキスト・多視点画像を用いて学習。手順:
- 既存3Dシーン画像にノイズ付加し、数十段階でノイズ除去できるよう事前学習。ノイズ除去に加え、レンダリング画像と実際の画像との誤差最小化も習得。
- 3つの損失関数で微調整。まず、教師モデルが数段階のノイズ除去で生成する画像特性を学生モデルが模倣することを促進。
- 次に、畳み込みニューラルネットワークを持つ別教師を識別器として用い、学生モデルの画像が自然に見えるよう学習。
- 最後に、画像生成デコーダ出力と3D生成デコーダからレンダリングした画像間の類似を促進。
結果: FlashWorldは以前の最先端法より低計算コストで高品質3Dシーンを生成。
- 単一Nvidia H20 GPUで9秒で3Dシーン生成。対照的に、Wonderlandなど画像から3Dの最先端モデルはそれぞれ5分、77分かかる(より高性能GPU上)。
- テキストから3D生成ベンチマークWorldScoreでは、FlashWorldが68.72点で競合Wonderworld(66.43)やLucidDreamer(66.32)を上回る。
- 質的には草の葉や動物の毛など細部描写に優れるが、細かい構造や鏡面反射は苦手。
重要性: 3D生成は高速かつ高品質を同時に実現しつつある。複数アプローチの組み合わせが最良解をもたらし、事前学習済みディフュージョンモデル教師の活用が短時間で詳細かつ一貫した3D表現を可能にした。
所感: 数秒で3Dシーン生成できることはリアルタイム生成への大きな一歩。ゲームやVRのコンテンツ制作が事前作業から動的かつ実行時体験へと変わる可能性を秘める。
