2026年4月2日 - リンク・ブログ
Gemma 4: バイト単位で、最も能力の高いオープンモデル。Google DeepMindによる、視覚対応の新しいApache 2.0ライセンスの推論LLMが4つ登場しました。サイズは2B、4B、31B。そして26B-A4BのMixture-of-Expertsです。
Googleは「パラメータあたりの知能の前例のないレベル」を強調しており、小さくて役に立つモデルを作ることが、まさに今もっとも熱い研究分野の一つであることを裏付けるさらなる証拠が示されています。
彼らは実際に、2つの小さいモデルを「Effective(有効)な」パラメータサイズのためにE2BとE4Bと名付けています。システムカードにはこう書かれています:
小型モデルは、オンデバイスの展開におけるパラメータ効率を最大化するためにPer-Layer Embeddings(PLE)を取り入れています。モデルにさらに層やパラメータを追加するのではなく、PLEは各デコーダ層に対して、すべてのトークンごとにそれ自身の小さな埋め込み(embedding)を与えます。これらの埋め込みテーブルは大きいものの、すぐに参照するためにだけ使われます。そのため、総パラメータ数に比べて有効なパラメータ数はずっと小さくなります。
私はそれを完全には理解できていませんが、どうやらE2Bの「E」がそういう意味だということです!
LM Studioで、このGGUFを使って試してみました。2B(4.41GB)、4B(6.33GB)、26B-A4B(17.99GB)モデルはいずれも完全に動作しましたが、31B(19.89GB)モデルは壊れていて、試したすべてのプロンプトに対して"---
"をループで吐き出しました。
2Bから4Bから26B-A4Bへと続くpelican品質の上昇が注目に値します:
E2B:
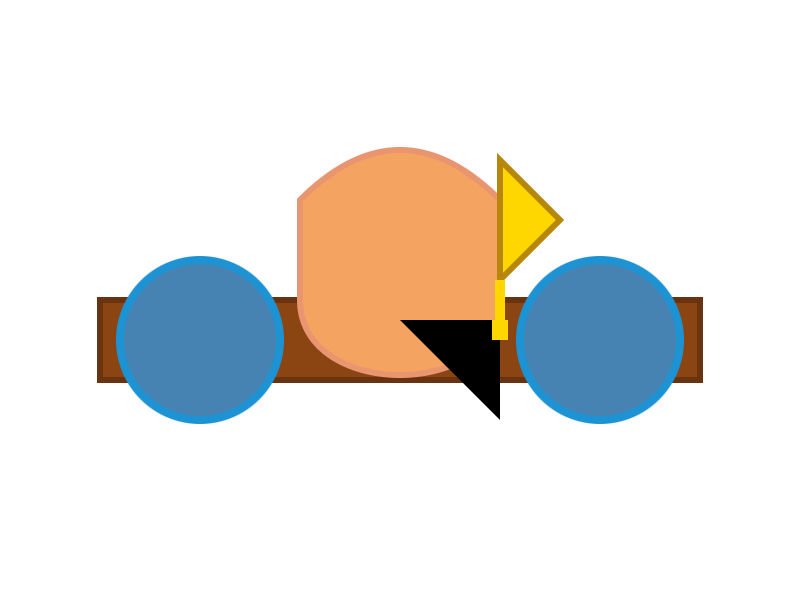
E4B:
26B-A4B:

(このモデルは実際にSVGエラーがありました――「18行目、88列目でAttribute x1が再定義されています」――が、それを直した後、ノートPCで動くモデルとしては、これまで見た中でたぶん最良のペリカンが出ました。)
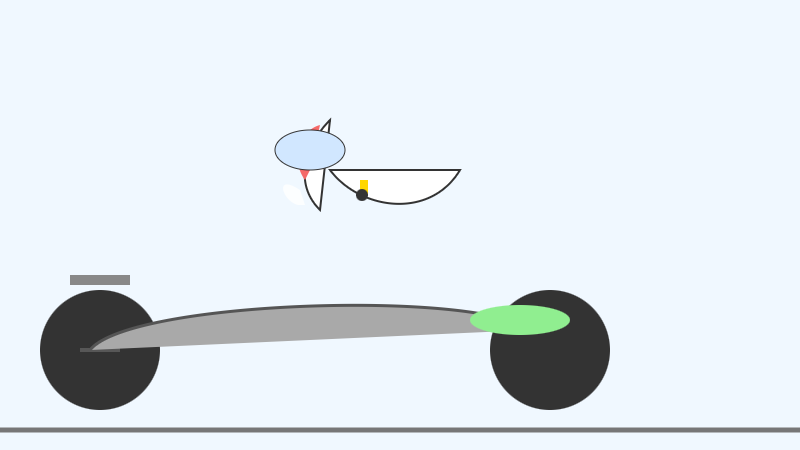
Googleは、2つのより大きいGemmaモデルについて、AI Studio経由でAPIアクセスを提供しています。私はllm-geminiに対応を追加し、その後、同じ方法で31Bモデルを使ってpelicanを実行しました:
llm -m gemini/gemma-4-31b-it '自転車に乗っているペリカンのSVGを生成する'
かなり良いです。ただし自転車のフレーム前部が欠けています:

最近の記事
- LennyのPodcastでの、エージェント的エンジニアリングについての会話のハイライト - 2026年4月2日
- Mr. Chatterboxは、自分のPCで動かせる(弱い)ビクトリア朝時代の倫理教育済みモデルです - 2026年3月30日
- Vibe codingでSwiftUIアプリを作るのはとても楽しい - 2026年3月27日
これはSimon Willisonによるリンク投稿で、2026年4月2日に公開されました。
google 400 ai 1942 generative-ai 1723 local-llms 152 llms 1689 llm 583 vision-llms 85 pelican-riding-a-bicycle 102 llm-reasoning 96 gemma 13 llm-release 186 lm-studio 18月間ブリーフィング
$10/月で私をスポンサーし、今月の最重要なLLMの動向を厳選したメールダイジェストを受け取ってください。
あなたに送る手間を、減らすためにお金を払ってください!
スポンサー&購読



