太陽フレアの効果的な監視と特性評価には、複数のエネルギースペクトルにわたるX線放射の高度な解析が必要です。機械学習に基づく異常検出は、顕著な太陽活動を示唆し得る重要なパターンを特定するための強力なツールとして機能します。異なる放射のシグネチャを特定することで、主要な太陽イベントの特性を検出し、解析し、包括的に理解できます。検出されたこれらのパターンは、宇宙天気予報、太陽物理学の調査、衛星運用の計画など、さまざまな用途にとって不可欠です。近年、太陽監視の機能は大幅に拡張し、かつてない量のX線計測データが生成されています。データが増え続ける中で、分析手法は進化し、太陽行動の最も微細な変化まで捉えつつ、これらの巨大なデータセットを効率的に処理できるようにする必要があります。高度な深層学習アーキテクチャ、特にLong Short-Term Memory(LSTM)ネットワークは、こうした課題に対する非常に有力な解決策として登場しています。
本記事では、Spectrometer/Telescope for Imaging X-rays(STIX)によって収集されたマルチチャネルX線データに対する異常検出のためのLSTMニューラルネットワークの実装を紹介します。分析では、低(4–10 keV)、中(10–25 keV)、高(25+ keV)の各エネルギーバンドにわたるさまざまなエネルギー範囲での異常パターンの検出に重点を置きます。このマルチチャネルアプローチにより、太陽活動を包括的に監視でき、洗練されたX線放射データのパターン解析によって潜在的なフレアイベントを堅牢に特定することが可能になります。本記事では、欧州宇宙機関(European Space Agency)のSTIX計測器のデータを用いて、太陽フレアを検出する深層学習モデルを構築しデプロイする方法を、Amazon SageMaker AIでどのように行うかを示します。SageMaker AIは、非監督学習アルゴリズムであるRandom Cut Forest(RCF)を使用します。これは、データ点の密度と疎度に基づいて異常スコアを割り当てることで、異常なデータ点を検出します。さらに、マルチチャネルX線データを処理して潜在的な太陽フレアイベントを特定するLong Short-Term Memory(LSTM)ニューラルネットワークを実装する方法を学びます。
主要コンセプト
このセクションでは、本ソリューションにおける太陽放射解析と機械学習(ML)のいくつかの重要なコンセプトについて説明します。
太陽観測におけるX線エネルギーチャンネル
STIXデータに含まれるX線放射は、低(4–10 keV)、中(10–25 keV)、高(25+ keV)というエネルギーチャンネルに分類され、複数のエネルギーバンドにわたって測定されます。このマルチチャネルアプローチにより、異なるエネルギーレベルで太陽活動を包括的に監視できます。エネルギーバンドは、フレアの開始から最大の強度に至るまで、太陽フレアのさまざまな側面に関する重要な情報を提供します。これらのチャネルにまたがるパターンを解析することで、太陽フレアの進展のさまざまな段階を特定し、その強度を特徴づけることができます。
複数のエネルギーチャンネルのデータを組み合わせることで、太陽フレアの特性に関する詳細な洞察が得られます。高エネルギーチャンネルは通常、より強いフレア活動を示します。一方、低エネルギーチャンネルは前駆イベントやフレア後の現象を捉えることができます。このマルチスペクトルアプローチにより、フレアの立ち上がりを早期に検出し、フレアの大きさや継続時間を正確に評価できます。
宇宙機ダイナミクスにおけるクォータニオン
LSTMネットワークは、従来のニューラルネットワークとは異なり、時系列データにおける長期的な依存関係を捉えることができる内部メモリ状態を維持します。この独自の特性により、反復型ニューラルネットワーク(RNN)に位置づけられ、variantです。LSTMの能力は、パターンが長い時間スパンで発展する可能性がある太陽フレア検出に特に有用です。
LSTMアーキテクチャは、ゲートと状態のための洗練された仕組みを通じて動作します。中核となる入力ゲートは、新しい情報がネットワークへ流れ込む経路を制御し、どのデータ点が保存するに値するほど重要かを決定します。協調して動作する忘却ゲートは、既存の情報を評価し、破棄すべき要素を判断して、無関係なデータが蓄積されるのを防ぎます。これらの判断は、ネットワークの長期メモリとして機能し、シーケンス処理を通じて重要な情報を保持するセル状態に反映されます。その後、出力ゲートが、このセル状態のどの情報を各時刻ステップの出力として提示すべきかを調整します。
この洗練されたアーキテクチャにより、解析の時間的整合性を維持しながら、モデルは異なるエネルギーチャンネル間の複雑な関係を学習できます。マルチレイヤーのアプローチによりネットワークはデータのより抽象的な表現を段階的に構築でき、正則化手法は新しい観測に対して信頼性の高い性能を維持します。予測値と実際の値の間の再構成誤差を継続的に監視することで、システムは太陽フレアイベントを示唆し得る異常パターンを効果的に特定します。
時系列解析と異常検出
異常検出システムは、多次元の時系列データを処理し、各次元は異なるエネルギーチャンネルに対応します。LSTMモデルはX線放射データにおける通常のパターンを学習し、太陽フレアイベントを示す可能性のある逸脱を特定します。これらの異常は、強度の急激な増加、珍しいスペクトルパターン、あるいは太陽活動を示すその他のシグネチャを表すことがあります。
信頼性の高いフレア検出のために、LSTMはクロスチャネルX線データの時間的特徴とスペクトル的特徴の両方を解析します。時間的解析では、放射強度が時間とともに急変したり、異常なパターンが現れたりすることを特定します。スペクトル解析では、異なるエネルギーチャンネル間の関係を調べます。太陽フレアは複数のエネルギーバンドにわたって特徴的なパターンを生み出すことが多いためです。LSTMに基づくパターン認識とマルチチャネル解析を組み合わせることで、自動化された太陽フレア検出のための堅牢な枠組みが構築されます。このアプローチは、微細な前駆パターンを特定し、フレアの進展を追跡し、さまざまなエネルギー範囲におけるフレア強度を特徴づけることを可能にし、宇宙天気予報や太陽物理学の研究に向けた価値ある洞察を提供します。
ソリューションアーキテクチャ
このソリューションアーキテクチャは、以下の図に示すように、LSTMアルゴリズムを使用して、ESAのSolar Orbiter Solar STIXデータに対する異常検出を実装します。このソリューションでは、Amazon SageMaker AIにBring Your Own Script(BYOS)を用いるため、SageMaker AIのマネージドインフラストラクチャを利用しながら、独自のトレーニングスクリプトを使用できます。BYOSでは、次のことが可能です。
- 好みのMLフレームワーク(このケースではPyTorch)を使用する
- トレーニングロジックを制御したまま運用する
- SageMaker AIのトレーニングインフラストラクチャおよびスケーリング機能を引き続き利用する
- コンテナを管理することなく、独自のLSTMモデルをデプロイする
このアプローチを使うには、PythonスクリプトをSageMaker AIにアップロードし、トレーニングジョブを作成する際にエントリポイントとして指定します。このブログ投稿で使用しているPythonは、参照しているGitHubリポジトリ内にあります。
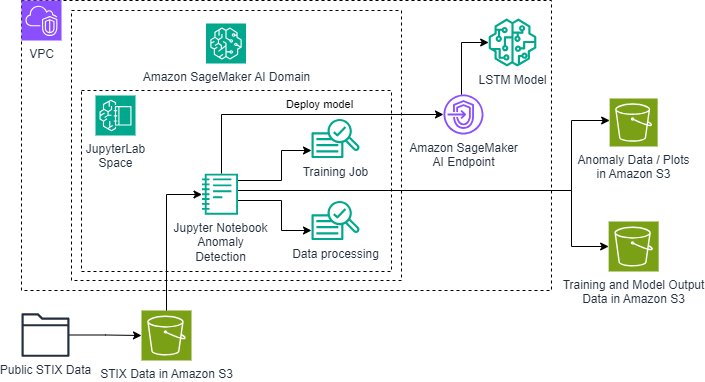
データパイプラインは、FITS 形式で保存された生の STIX(X 線イメージング用分光器/望遠鏡)計測から始まります。これらの観測は JupyterLab 環境で初期処理を受け、当社の主要な開発・解析プラットフォームとして機能します。この環境には、FITS データを CSV 形式に変換し、先進的な検出アルゴリズムを実行するカスタム Python ノートブックがホストされています。システムの中核には、ニューラルネットワーク処理パイプラインがあります。ワークフローは JupyterLab でのデータ準備から始まり、その後 PyTorch で実装した専用の CrossChannelLSTM モデルを学習させます。このモデルは複数のエネルギーレンジ(4〜10 keV、10〜25 keV、25 keV 以上)にわたる X 線放射を処理します。学習フェーズの後、システムは異常検出によって、時系列シーケンスを解析し、潜在的な太陽フレアのシグネチャを特定します。パイプラインの最後には、時間解析プロット、エネルギーの変遷を示す図、チャンネル間の相関表示を含む包括的な可視化の生成で締めくくられます。
システムは、特定された異常、詳細なチャンネル統計、時系列パターン解析など、膨大な分析アウトプットを生成します。可視化スイートは、エネルギーバンド全体における異常なパターンを強調する複雑なプロットを生成し、あわせて時間変化のチャートやモデルの性能指標も表示します。すべての結果は構造化された CSV ファイルとして文書化され、異常指標と再構成誤差の測定値が含まれます。これにより、検出された太陽イベントを深く分析することが可能になります。プロセス全体を通じて、厳格なデータ取り扱いプロトコルにより、解析の整合性と再現性が維持されます。
ソリューション概要
このソリューションは、深層学習手法を用いた太陽フレア検出の包括的なアプローチを示しています。まず、STIX クイックルックのライトカーブデータを含む FITS ファイル形式を、扱いやすい CSV 形式へ変換することでデータ前処理を行います。次に、解析のための入力品質を維持するために、データの正規化とシーケンス準備を実施します。PyTorch を用いて、マルチチャネルの X 線データにおける異常を検出するために特別に設計したカスタム CrossChannelLSTM モデルを実装します。システムは、複数のエネルギーバンドにわたってデータを処理し、太陽フレア活動を示唆する可能性のあるパターンを特定します。ドロップアウト正則化を含む複数の LSTM 層を用いてモデルを学習した後、このソリューションは豊富な可視化機能を提供します。これには、異常を強調した時系列プロット、エネルギーと時間の変遷を可視化する図、結果を明確に解釈するためのチャンネル間分析プロットが含まれます。システムは、チャンネル別の統計、異常の時間的変遷、異常フラグおよび再構成誤差を含む包括的な CSV ファイルなど、詳細なアウトプットを生成します。
この深層学習アーキテクチャと可視化ツールの組み合わせにより、自動化された太陽フレア検出のための堅牢な基盤が構築されます。この組み合わせは、迅速な検出と正確な解析が不可欠な宇宙天気モニタリングの用途に特に適しています。微細な放射パターンを特定しながら大規模な STIX データを処理できることは、太陽物理学の研究および宇宙天気予報における有効性を示しています。
前提条件
太陽フレア検出システムを実装する前に、以下のツールと依存関係がインストールされていることを確認してください。
- AWS の要件:
- 適切な権限を持つ AWS アカウント
- SageMaker AI および Amazon Simple Storage Service(Amazon S3)へのアクセス権限を含む適切な IAM ロール
- データとモデル成果物を保存するための Amazon S3 バケット
- 必要な AWS サービス:
- Amazon SageMaker AI(ml.m5.2xlarge の JupyterLab インスタンス推奨)
- Amazon S3
- AWS IAM Identity Center
- 開発環境では、Python 3.7 以上が必要です。さらに、提供される Python スクリプトおよび requirements ファイルに含まれる必須の Python パッケージが必要です。
- JupyterLab 環境の場合:
- Amazon SageMaker AI Studio のノートブック
- 追加要件:
- STIX データ(FITS 形式)へのアクセス
- 大規模データセットの処理に十分な RAM(推奨最小 16GB)
- より速いモデル学習のための GPU サポート推奨
- Python プログラミングおよび深層学習の概念に関する基本的な理解
- 概算コスト:
- SageMaker AI ml.m5.4xlarge インスタンス: 約 $0.922/時間
- S3 ストレージ: 約 $0.023/GB/月
- このソリューションの実行にかかる総概算コスト: 約 $10〜15(数時間の実験)
ソリューションをセットアップする
セットアップ手順では、すべてのデータ解析とモデル学習が実行される Amazon SageMaker AI の Python 環境を設定します。
- Amazon SageMaker AI コンソールで、SageMaker AI ドメインの詳細ページを開きます。
- JupyterLab を開き、このプロジェクト用に新しい Python ノートブックインスタンスを作成します。
- 環境が準備できたら、Amazon SageMaker AI JupyterLab でターミナルを開き、以下のコマンドを使用して プロジェクトリポジトリ をクローンします。
git clone https://github.com/aws-samples/sample-SageMaker-ai-lstm-anomaly-detection-solar-orbiter.git
cd sample-SageMaker-ai-lstm-anomaly-detection-solar-orbiter- 必要な Python ライブラリをインストールします。
pip install -r requirements.txt
このプロセスにより、Solar Orbiter のセンサー・データに対する異常検出解析を実行するために必要な依存関係がセットアップされます。
異常検出を実行する
スクリプト内の bucket_name および file_name の変数を、あなたの S3 バケット名とデータファイル名に更新してください。
JupyterLab で Jupyter ノートブックとしてスクリプトを実行するか、Python スクリプトとして実行します。
python ESA_SolOrb_AD.py
実行すると、ノートブックまたはスクリプトは太陽の X 線データを解析するための一連の自動タスクを実行します。まず FITS ファイルを読み込み、前処理を行います。FITS を CSV 形式へ変換し、エネルギーチャンネル間でデータを正規化します。次に、PyTorch を用いて CrossChannelLSTM モデルを学習し、当社の異常検出システムの基盤を確立します。モデルが稼働可能になると、システムはマルチチャネルの X 線データを処理し、さまざまなエネルギーバンド(4〜10 keV、10〜25 keV、25 keV 以上)にわたるパターン解析によって、潜在的な太陽フレアイベントを特定します。
コード構造
Python の実装は、ソーラーフレア検出パイプラインを中心に構成されており、メインスクリプト を軸としています。中核となるのは 2 つの主要クラス、CrossChannelLSTM と CrossChannelDataset です。これらが連携して、データの取り込みから可視化までのワークフローを統括します。これらのクラスは協調して STIX の X 線データを処理し、潜在的なソーラーフレアイベントを特定します。
explore_ql_lightcurve メソッドは、最初のデータ取り込みと前処理を担当し、FITS ファイルを CSV 形式に変換するとともに、X 線計測が解析用に適切に整形されていることを確認します。plot_lightcurve メソッドは、異なるエネルギーチャンネルにまたがるデータの初期可視化を作成します。print_channel_stats メソッドは、各エネルギーバンドに対する統計解析を提供します。
CrossChannelLSTM クラスは、複数の LSTM 層とドロップアウトによる正則化を備えたニューラルネットワーク構造を実装します。CrossChannelDataset クラスは、モデルのためのデータ準備とシーケンス化を管理します。続いて detect_cross_channel_anomalies メソッドは、この学習済みモデルを使用して、異なるエネルギーバンド間の X 線放射における異常なパターンを検出します。
可視化のために、plot_cross_channel_anomalies および plot_flare_anomalies メソッドは、検出された異常を強調する詳細なグラフを作成します。これらは、時間的な変化のパターンやエネルギーバンドの分布を含みます。これらの可視化には、時系列解析、エネルギーと時間の進化ダイアグラム、チャンネル間の相関プロットが含まれます。
これらのコンポーネントを組み合わせることで、多チャンネルの X 線データを処理し、さらなる調査が必要となる可能性のあるソーラーフレアイベントを特定する、包括的なパイプラインが構築されます。システムのモジュール設計により、分析ニーズに合わせてモデルパラメータや可視化オプションを変更できます。
設定
精度、性能、計算時間、その他のニーズに合わせて、必要に応じてスクリプト内の以下のパラメータを調整してください。LSTM モデルのアーキテクチャと学習パラメータは、ソーラーフレアイベントの検出に大きく影響します。
以下のパラメータを変更できます:
モデルアーキテクチャパラメータ:
hidden_size: LSTM 隠れ層のサイズ(デフォルト: 128〜256)num_layers: LSTM 層の数(デフォルト: 2〜3)dropout_rate: ドロップアウトによる正則化率(デフォルト: 0.2)sequence_length: 入力シーケンスの長さ(デフォルト: 30〜50)
学習パラメータ:
batch_size: 学習バッチあたりのシーケンス数(デフォルト: 32)num_epochs: 学習の反復回数(デフォルト: 15〜20)learning_rate: モデルパラメータの更新率(デフォルト: 0.001)threshold_multiplier: 異常検出の感度(デフォルト: 1.5)
標準的なハードウェア構成での性能向上のために、次を推奨します:
hidden_size=256num_layers=3dropout_rate=0.2sequence_length=30batch_size=32num_epochs=20
ハードウェア要件は、学習時間やモデル性能に大きく影響します。より高速な学習のために GPU 加速が推奨されますが、CPU のみでの実行もサポートされています。最低限の推奨システム要件として、16 GB の RAM と 4 つの CPU コアがあります。
システムは、可視化パラメータおよび出力形式のカスタマイズをサポートします。結果は、各エネルギーチャンネルに対する詳細な異常フラグと再構成誤差を含む CSV ファイルとして保存できます。可視化スイートは、時系列プロットからエネルギーバンドの分布まで、分析のさまざまな側面を表示するように構成できます。
データ
このスクリプトでは、公開されている ESA の Solar Orbiter STIX(X 線イメージングのための分光計/望遠鏡)データを、FITS ファイル形式で使用します。このデータには、4 keV から 25 keV 超までの複数のエネルギーチャンネルにわたる X 線計測が含まれています。FITS ファイルには以下が含まれます:
- 各エネルギーチャンネルの時系列データ
- エネルギーバンド情報(4〜10 keV、10〜25 keV、25+ keV)
- 制御インデックスとタイミング情報
- 計測誤差データ
- チャンネル間のトリガーカウント
データは FITS ファイル内で階層構造として整理されており、測定のさまざまな側面を含む別々の HDU(Header Data Unit)があります。このスクリプトは、このデータを CSV 形式に変換し、タイムスタンプ、エネルギーチャンネルごとのカウント、関連する誤差計測の列を作成します。
解析のために自身のデータを準備するときは、STIX データのフォーマット仕様に従い、すべてのエネルギーチャンネルに対する完全な計測が含まれていることを確認してください。システムは、信頼できる異常検出のために、サンプリング率が一定の連続した時系列データを想定しています。
結果
LSTM ベースの異常検出システムは、図に示されるように、複数のエネルギーチャンネルにまたがって包括的な可視化を生成します。解析は 4.0 keV から 84.0 keV までの 5 つの明確なエネルギーバンドを対象としており、各チャンネルが太陽活動の異なる側面を明らかにします。
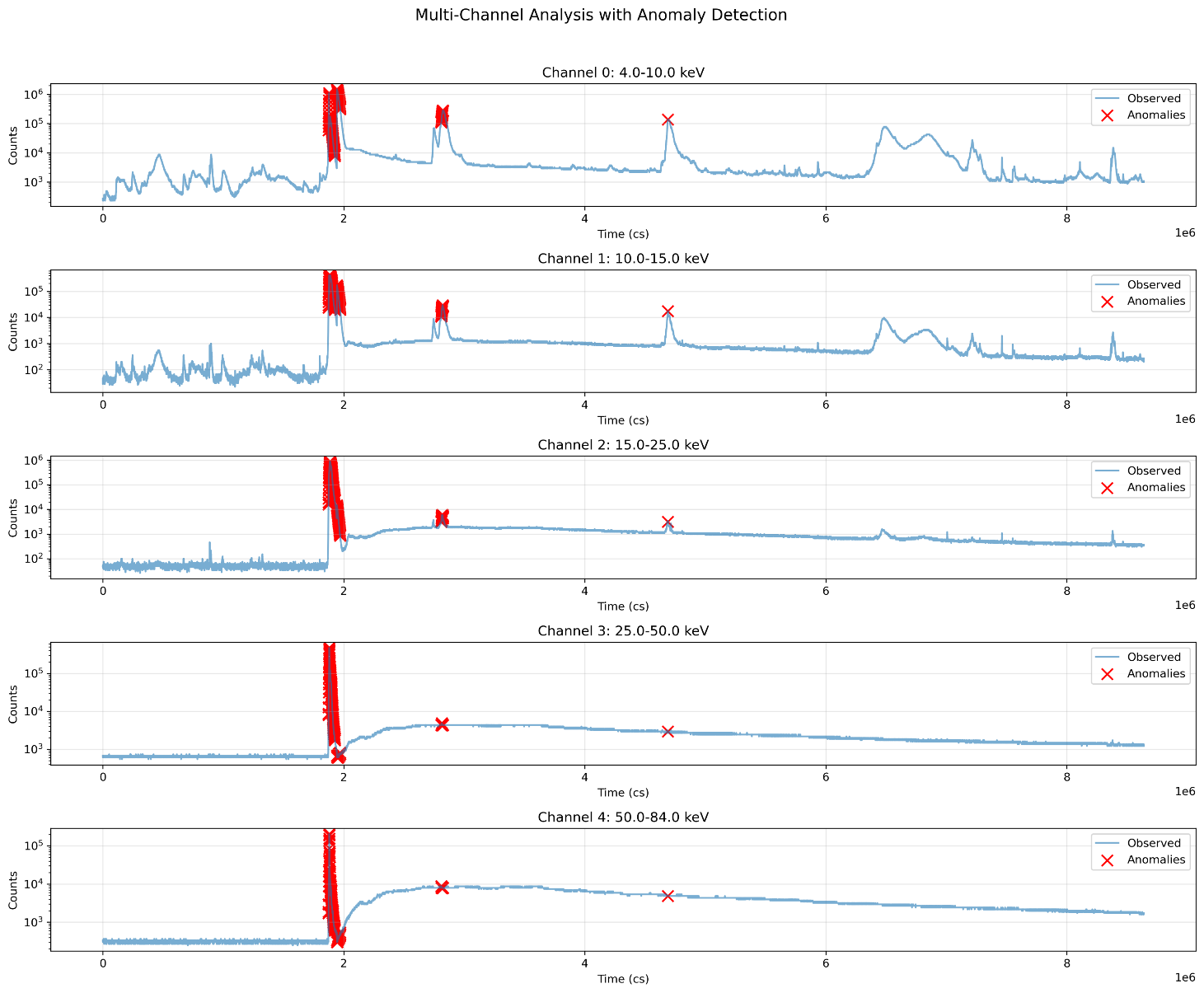
- チャンネル 0(4.0〜10.0 keV)は、約 10³ センチ秒のベースライン活動を示し、大きなスパイクが 10⁶ センチ秒に達します
- チャンネル 1(10.0〜15.0 keV)は同様のパターンを示しますが、ベースラインカウントはわずかに低くなります
- チャンネル 2(15.0〜25.0 keV)は、背景とイベント期間の違いがより明確に現れます
- チャンネル 3(25.0〜50.0 keV)は、背景雑音が低い状態で強いイベントのシグネチャを示します
- チャンネル 4(50.0〜84.0 keV)は、最も高エネルギーの放出を捉え、非常に明確な信号対雑音比を示します
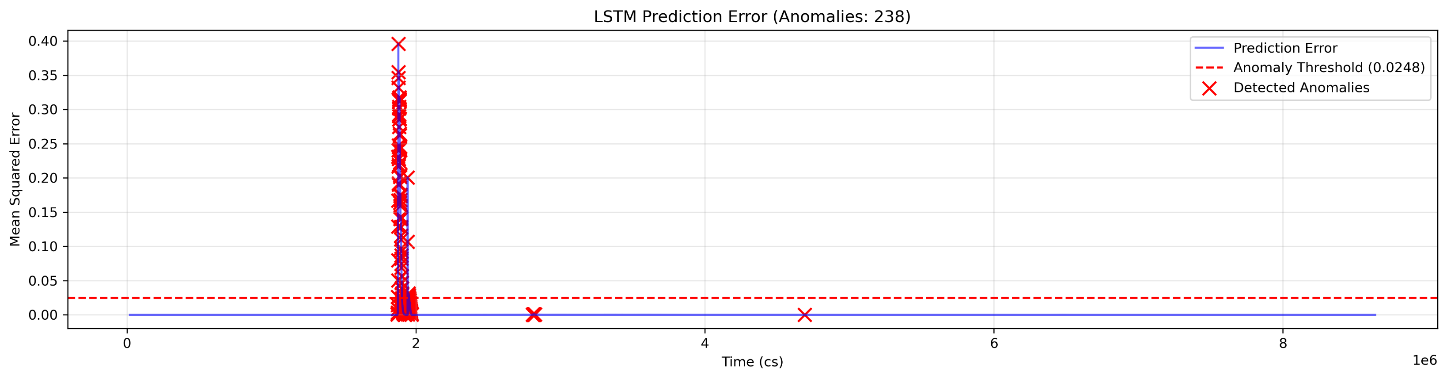
システムは、データセット全体で 238 個の異常点を検出しました。これらは主に、時系列において約 200 万、300 万、500 万センチ秒(cs)の 3 つの大きなイベントの周辺に固まっていました。これらのイベントは特に注目に値します。というのも、複数のエネルギーチャンネルに同時に現れており、重大なソーラーフレア活動を示唆しているためです。下段のパネルは、異常閾値が 0.0112 の LSTM の予測誤差を示しています。この閾値を超える点(赤で表示)は、複数のチャンネルにおける突発的な強度変化に対応します。最も大きな予測誤差は、大きなイベントの開始と一致しており、モデルが X 線放射における急速な変化を検出していることがわかります。
カウントの対数スケール表現により、背景放射の微かな変動とフレア事象の際の劇的な強度上昇の両方が明らかになり、モデルが太陽活動における主要な異常だけでなく軽微な異常も検出できることを示しています。
クリーンアップ
分析を実行し、プロットをS3に保存した後、システムリソースを管理するために次のクリーンアップ手順を実行してください。開いているmatplotlibの図を閉じてメモリを解放します。plt.close('all')プロット生成中に作成された一時ファイルを削除します:
import os
for file in os.listdir('/tmp'):
if file.endswith('.png'):
os.remove(os.path.join('/tmp', file))JupyterLabで実行している場合は、Running Terminals and Kernelsパネルから未使用のカーネルを停止してシステムリソースを解放できます。さらに、CSVに変換した大きなFITSファイルが分析に不要になっているのであれば、それらを削除することも検討してください。これらのクリーンアップ手順は、リソース使用を効率的に維持し、不要なストレージ消費を防ぐのに役立ちます。中間結果を保存するようにコードを変更している場合は、それらの一時ファイルも不要になった時点で削除してください。
JupyterLabを使用して今後の課金を避けたい場合は、LSTM JupyterLab Pythonノートブックを実行しているAmazon SageMaker AIノートブックインスタンスのリソースをクリーンアップし、作成したSageMaker AIエンドポイントは削除してください。また、S3データも削除できます。以下にそのためのPythonコマンドを示します。
SageMaker AIエンドポイントを削除:
import boto3
sagemaker = boto3.client('sagemaker')
sagemaker.delete_endpoint(EndpointName='solar-flare-endpoint')SageMakerノートブックインスタンスを停止:
sagemaker.stop_notebook_instance(NotebookInstanceName='solar-flare-notebook')S3から学習データと成果物を削除:
s3 = boto3.client('s3')
s3.delete_object(Bucket='your-bucket', Key='solar-flare-data/')見積もりのコスト削減額:ml.m5.4xlargeインスタンスを停止することで1日あたり約$22。
結論
この投稿では、LSTMニューラルネットワークを用いてESAのSolar Orbiter STIX計測器による太陽X線データの異常を効果的に検出できることを示しました。4.0〜84.0 keVの範囲にある複数のエネルギーチャンネルにまたがるパターンを分析することで、深層学習が太陽フレアイベントとその特徴に対する理解をどのように高められるかを明らかにしました。カスタムのCrossChannelLSTMモデルは、複雑で多次元のX線データを正常に処理し、異なるエネルギーバンドにまたがって405件の異常イベントを特定することに成功しました。
私たちの結果は、主要な太陽イベントの明確な検出を示しており、特に200万センチ秒付近で、すべてのエネルギーチャンネルにおいて大きな強度上昇が観測されます。複数のチャンネルに同時にわたって異常を検出できることは、計測器由来のアーティファクトやノイズではなく、信頼できる本物の太陽フレアイベントであることを強く裏づけます。効率的なバッチ処理と正規化されたデータ取り扱いにより、大規模な太陽観測データを効果的に分析でき、可視化のアプローチによって太陽フレアイベントの可能性を迅速に特定できます。
このソリューションはSTIXデータの解析に焦点を当てていますが、同様のアプローチは太陽物理学や宇宙天気予報の分野全体に幅広い応用が可能です。同じアーキテクチャは、さまざまな種類の太陽観測、宇宙天気のモニタリング、その他の時系列天文学データ解析に適応できます。深層学習と太陽物理学を統合することで、宇宙天気アナリティクスのための堅牢で拡張可能なプラットフォームが構築でき、宇宙空間ベースの技術への依存が高まるにつれて、その価値はますます高まっています。今後の展望として、このソリューションは強化と拡張のための多くの可能性を開きます。リアルタイムのフレア検出を導入して、ライブの太陽モニタリングを行い、重要な事象が発生した際に即時のアラートを提供できます。追加の波長帯やセンサーデータを組み込むことでシステムを強化でき、検出した太陽フレアをすぐに通知する自動アラートサービスも開発できます。さらに発展させるなら、太陽フレア予測のための予測能力を分析に拡張し、特定の宇宙天気モニタリング要件に合わせたカスタム指標を作成することも考えられます。
このコードと実装の詳細は、私たちのGitHubリポジトリで公開されているため、太陽物理学の研究ニーズに合わせてソリューションを適応し、強化できます。宇宙天気運用においては、深層学習とマルチチャンネル分析の組み合わせが、太陽活動の理解と予測においてますます重要な役割を果たす可能性を強く秘めています。
このソリューションで使用しているAWSサービスについて詳しく知りたい場合は、Amazon SageMaker AIのセットアップ方法ガイド、Amazon SageMakerでモデルを学習させる、およびAmazon SageMaker AI Developer Guideを参照してください。




