親愛なる皆様、
私たちは、これまでコードを書いたことがない人々に対して、30分以内でアプリのアイデアを説明し、AIを使ってそれを構築する方法を教えるコースを立ち上げました。すべての人、マーケター、プロダクト専門家、オペレーション担当者、アナリスト、学生がAIを使ってソフトウェアアプリを作る時代が来ました!
私はこれまでに 誰もがプログラミングを学ぶべき理由について語ってきました。コーディングができる人とそうでない人との間で生産性の差が急速に広がっているのを目の当たりにしています。私が採用する多くの職種で、最低限のコーディング知識を必須条件とすることも増えました。非技術者の方々にAIを用いてソフトウェアを作る重要性を話すと、多くの方がどう始めれば良いのか質問してきますが、以前は良い答えがありませんでした。これがDeepLearning.AIチームに「Build with Andrew」を作成するモチベーションとなりました。これはコードに触れてみたい人が始めるのに最適な方法です!
このコースはAIやコーディングの前提知識を必要としません。また、ベンダーに依存しない設計です。具体的には、受講者はChatGPT、Gemini、Claude、あるいはDeepLearning.AIのプラットフォーム内チャットボットなど、最も使い慣れたツールでこの手法を利用できます。
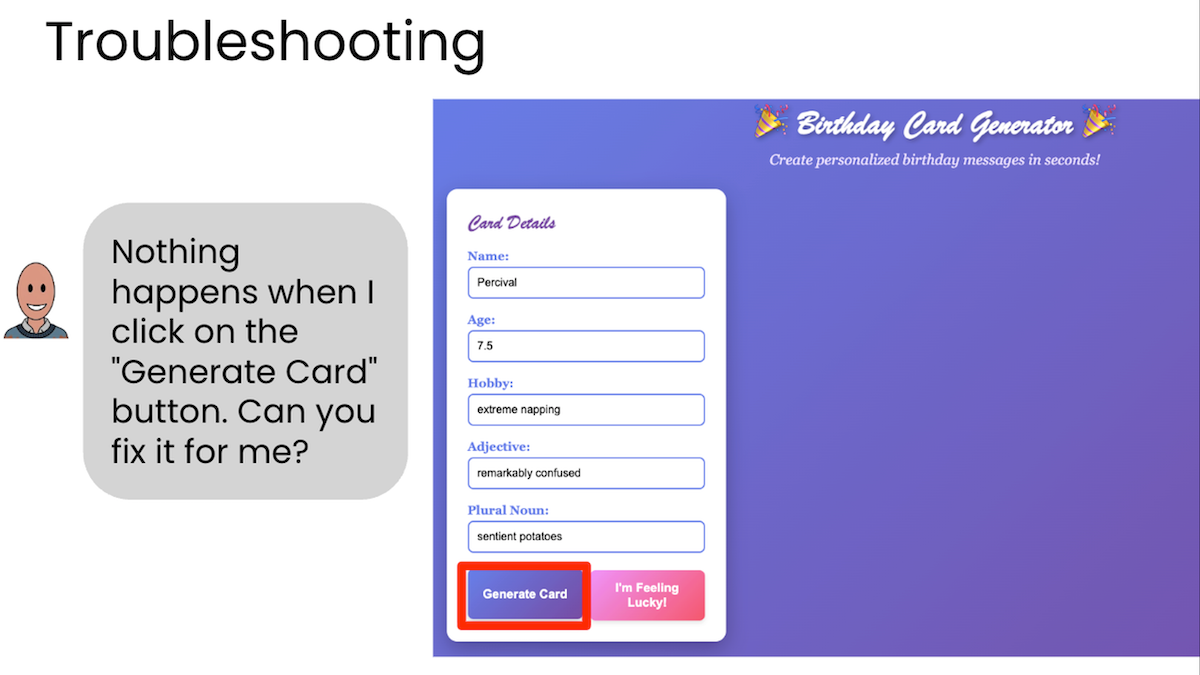
このコースを受講すると、稼働するウェブアプリ、つまりブラウザで動作し友人と共有できる面白いインタラクティブな誕生日メッセージジェネレーターを作成します。AIに変更したい点を伝え、それを調整して希望通りに動作するように仕上げます。コース終了時には幅広いアプリケーション開発に応用できる再現可能な手法を習得できます。
DeepLearning.AIの使命は、すべての人がAIを使って構築できる力を持つことです。このコースはその使命に向けた多くのステップの一つにすぎません。
すでに開発者の方は、非開発者のご友人にAIにコーディングを任せる楽しさを勧めてください。生産性向上に役立つだけでなく、とても楽しい体験になるはずです。ぜひご友人を私と一緒に構築する旅に招待してください!
どうぞ引き続き構築を楽しんでください。
アンドリュー
DeepLearning.AIからのメッセージ

アプリを作るためにプログラミングを学ぶ必要はありません。「Build with Andrew」では、アンドリュー・ングが自然言語で説明したアイデアを動くウェブアプリに変える方法を紹介します。初心者に最適で、始めるのを待っている人と簡単に共有できます。 今すぐコースをチェック!
ニュース

モデルに真実を語らせる訓練
大規模言語モデルは時に、守るべき制約に違反してもそれを隠そうとすることがあります。研究者たちは、指示や方針の違反を認めさせるようLLMを訓練しました。
新着情報:Manas Joglekar、Jeremy Chen、Gabriel WuらOpenAIチームは、GPT-5 Thinkingをファインチューニングし、自らの指示またはポリシー違反を懺悔を行うようにしました。要請に応じて、ファインチューニングされたモデルは最新の応答作成時に犯した違反を明らかにしました。
重要な洞察:精度、スタイル、遵守を促す強化学習の訓練中に、モデルは報酬獲得を優先し、指示や目的を無視してしまうことがあります。これにより、幻覚や嘘、策略、その他の不適切行動が起こり得ます。モデルが特定のプロンプトに応じて自らの不正行為を告白することで、誤りを認めるよう訓練でき、性能には影響しません。
仕組み:著者らは通常の強化学習でGPT-5 Thinkingを微調整する過程に、告白の生成も組み込みました。
- ある確率で、プロンプトに対する応答が「正確さ、スタイル、有用性、遵守、安全性」などに基づき報酬を得ました。
- その他の時は応答後に告白を促し、(i)暗示的・明示的な制約や指示、目的、(ii)応答がそれらを満たす度合い、(iii)基準の不明瞭さや不確かさについて記述させました。
- 質問、応答、告白を元に報酬モデルが告白の完全性と正確性を評価し、それに基づき報酬を与えました。告白に欠落や虚偽がある場面は嘘とみなされます。
結果:指示の遵守、脱獄耐性、正確な応答生成、ほぼ即時実行コーディングという不可能な課題でファインチューニングモデルを12回評価。モデルが誤った際に少なくとも半数以上で告白しました。特に5つの幻覚評価の合計では、81.4%の確率で幻覚がなかったか、または幻覚を認めました:
- 42.2%は幻覚なし・無告白。
- 39.2%は幻覚あり・誤りを認める。
- 11%は幻覚なしだが誤って幻覚を認める。
- 2.9%は幻覚ありだが告白せず。
ただし:モデルが素直に答えても、告白は万能ではありません。モデルは間違いと認識していない行動を告白しません。
意義:推論時に告白を利用してモデルの行動を監視し、不適切な行動を停止させることが可能です。思考の連鎖監視はモデルが思考の連鎖中に記述する不適切行為を分類しますが、今回の方法は omitted されやすい行動を明かすようモデルを訓練します。
私たちの考察:モデルの行動に人間のような意識を見出すのは慎重ですが、この研究はAIモデルに良心のようなものを付与する道の一歩かもしれません。
科学研究所向けリンガフランカ
オープンプロトコルが、AIエージェントに学際的かつ機関の壁を越えた自律的な科学研究を可能にしようとしています。
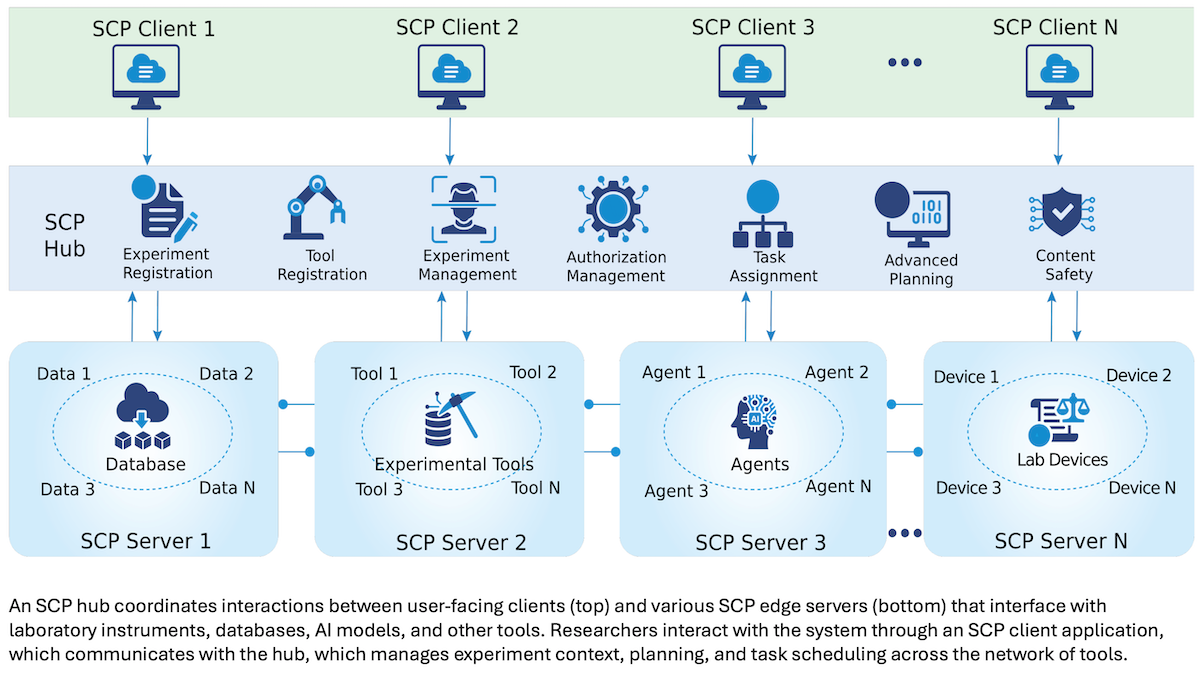
新着情報:上海人工知能研究所(SAIL)がScience Context Protocol (SCP)を公開。これはエージェントをローカルクライアント、中央ハブ、エッジサーバーにつなぎ、自動化された科学的探求を行うオープンソース標準です。Apache 2.0ライセンスの下で公開され、商用利用や改変を許可します。
仕組み:SCPはAIエージェントとロボット装置による実験の再現性を高めることを目標とします。Model Context Protocol (MCP)のように外部リソースとやり取りしますが、MCPのサーバー単独運用と異なり、SCPにはハブが他サーバーやユーザーがアクセスするクライアントアプリの管理を行います。また科学実験のため、メッセージとツールの管理をMCPより厳格にしセキュリティ強化を図っています。
- SCPの基本データ単位は「実験」。各実験はJSON構造化データファイルとして、永続的識別子、種類、目的、データ、設定記録と共に保持。実験が追跡可能でバージョン管理され、機械読み取り可能で機関のデータ規定に適合します。
- クライアントはユーザー認証を行い機関リソースへアクセス権を付与。研究者は自然言語で実験目的(例:「蛍光タンパクの明るさを増加」)を記述、または完全な研究計画をテキストやPDFでアップロードしハブに解析させます。
- ハブは目標や要求から大規模言語モデルで複数の実験計画を作成。各計画のステップごとにリソース、コスト、リスクを評価・順位付け。ユーザーが計画を選択すると、ハブは複数のエージェントやサーバーを連携させて実験を実行。実験完了後は保管・閲覧、修正、再実施が可能です。
- エッジサーバーはハブの計画を管理し、実験データをハブにストリーム送信(ハブはクライアントへ返送)。サーバーは機関所有か、あるいは生化学や数学など特定分野専用で各種専門ツールやデータベースを保持。
- 現在プロトコルには1600以上のツールが含まれ、実験に用い得るあらゆるリソース(検索などソフトウェア、ロボット、ラボ機器や人間技術者など)が想定されます。著者らはすべての実験用ツールの標準化を目指しています。
背景:SCPは一般的なAIエージェントや科学探求のための過去のデータ管理努力に由来し、MCPを拡張してより厳格なセキュリティ、実験管理、科学ツール専用ドライバーを提供します。さらに、材料科学のA-Lab、生物学のOriGene、LLMベースのAgent Laboratoryや生物学の仮説検証エージェントBiomniも元にしています。ただしSCPはこれらより汎用的で、多様な分野の研究者が手法を標準化し学際的な連携を促進することを目的としています。
意義:科学研究は人間と技術の協働に依存しています。SCPはそれらの接続を標準化し、計算資源のみのシミュレーション実験やロボットを使った物理実験の両方を管理可能にします。機関間や分野間のより良いコミュニケーションも、専用サーバー支援による大規模ネットワークによって促進します。人間/ロボット、デジタル/物理、分野の壁といった区別は薄れつつあり、SCPはその未来への一歩となります。
私たちの考察:AIは科学的発見を飛躍的に加速させる可能性を秘めています。SCPはAlphaFoldのような特殊化モデルと、AI Co-scientistのような仮説生成システム、RoboChemのようなロボット実験ラボを繋ぐ標準化された手段を提供します。この自動化された実験ワークフローは機械の速度で科学を前進させる潜在力を持っています。
Copilotのユーザーは時間帯でニーズが変わる
ユーザーがAIに望むものは、使う時間や使い方によって異なることが新たな研究で明らかになりました。
新着情報:Microsoftの調査により、夜遅くにスマホで使う場合と昼間にラップトップで使う場合とでCopilotの活用法に違いがあることが分かりました。生産性やキャリアに関する会話は昼間かつデスクトップ中心に多く、健康、ゲームや哲学的な話題は非仕事時間に優勢でした。2025年の進行に伴い、個人的なアドバイスを求めるユーザーが増加しました。
方法:研究者は2025年1~9月に収集した3750万件のCopilot会話の匿名要約を解析。これは同種最大規模の調査で、AIが生活面でも社会的に浸透していることを示唆します。
- 対象は有料・無料ユーザーのランダム抽出で、商用・企業・教育アカウントは除外。会話にはタイムスタンプとデバイスタイプ付き。AIツールで日約14万件を要約、各要約に「技術」等のトピックと「助言を求める」等の意図を分類し約300のトピック-意図ペアを特定。
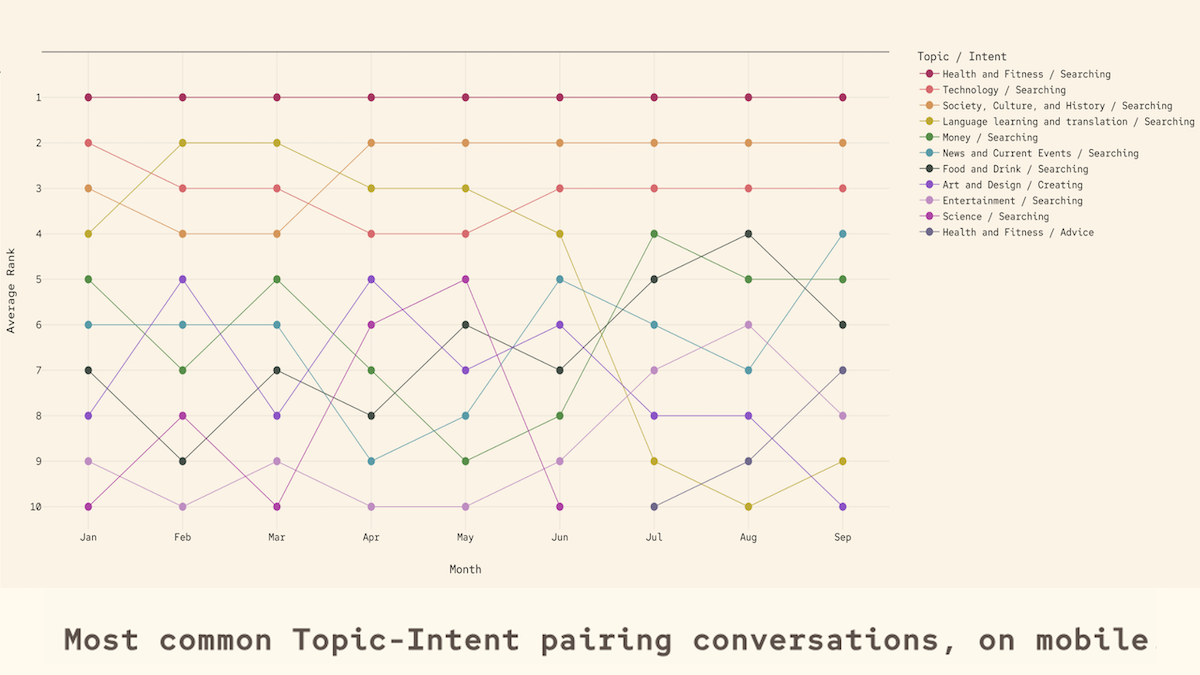
- 調査では年間、時間帯、デバイスでトピックや意図の頻度をランキング。上位5トピックは(i)技術、(ii)仕事とキャリア、(iii)健康・フィットネス、(iv)言語学習・翻訳、(v)社会・文化・歴史。意図では(i)検索、(ii)助言を求める、(iii)創作、(iv)学習、(v)技術サポート。
分析:時間帯、デバイス、時期により求められる話題や意図が違います。
- ユーザーはモバイルで健康・フィットネスを話す傾向が高い。バレンタインデー付近に個人的助言の需要が急増。夜遅い時間帯は哲学的な質問が増え、仕事時間は娯楽関連会話が急減。
- 年を通じて話題と意図は仕事・技術から社会的・個人的領域へと変化。ユーザー層は大きくなりより非技術的になったか、仕事と私生活両方でAIを使い始めた可能性。
背景:Microsoftの報告は他のAI企業の調査とも関連しています。
- 2025年9月、OpenAIとハーバードは2022~2025年のChatGPT利用を調査し、利用の30%が仕事関連、70%が非仕事関連と判明。ユーザーの性別ギャップも縮小。
- 2025年1月、AnthropicはClaudeのユーザー行動を分析し、仕事(特にソフトウェア開発やテキストコミュニケーション)に集中、一部でDungeons & Dragonsなどゲームや性的ロールプレイも増加(利用規約禁止にも関わらず)。
意義:著者はチャットボット設計の再考が必要だと主張。モバイルとデスクトップでユーザーの利用形態が異なるため、デバイスに適した応答設計が望ましい。例えばデスクトップは情報密度の高い回答でタスク遂行を促し、モバイルは短く共感的な応答といった使い分け。
私たちの考察:企業ごとに調査結果が異なるのはユーザー層や利用状況の違いによるかもしれません。とはいえMicrosoftの調査は、ユーザーが使うデバイスや時間帯が求めるAI体験に大きく影響することを示し、アプリケーション設計の重要な視点となります。
より低コストな推論
推論モデルの性能向上の一手段として長い思考連鎖を許すものがありますが、長大な文脈への注意処理は計算コストが高くなりがちです。効率化にはモデル構造の変更が必要ですが、研究者らはわずかな訓練で長く複雑な思考連鎖を処理するコストを制限する方法を提案しました。
新着情報:Delethinkは、大規模言語モデルを強化学習で訓練し、推論トークンを定期的に所定の最大数で切り詰める手法です。著者はMilad Aghajohari、Kamran Chitsaz、Amirhossein Kazemnejadらで、Mila、Microsoft、McGill大学、ServiceNow Research、Polytechnique Montréal、モントリオール大学に所属しています。
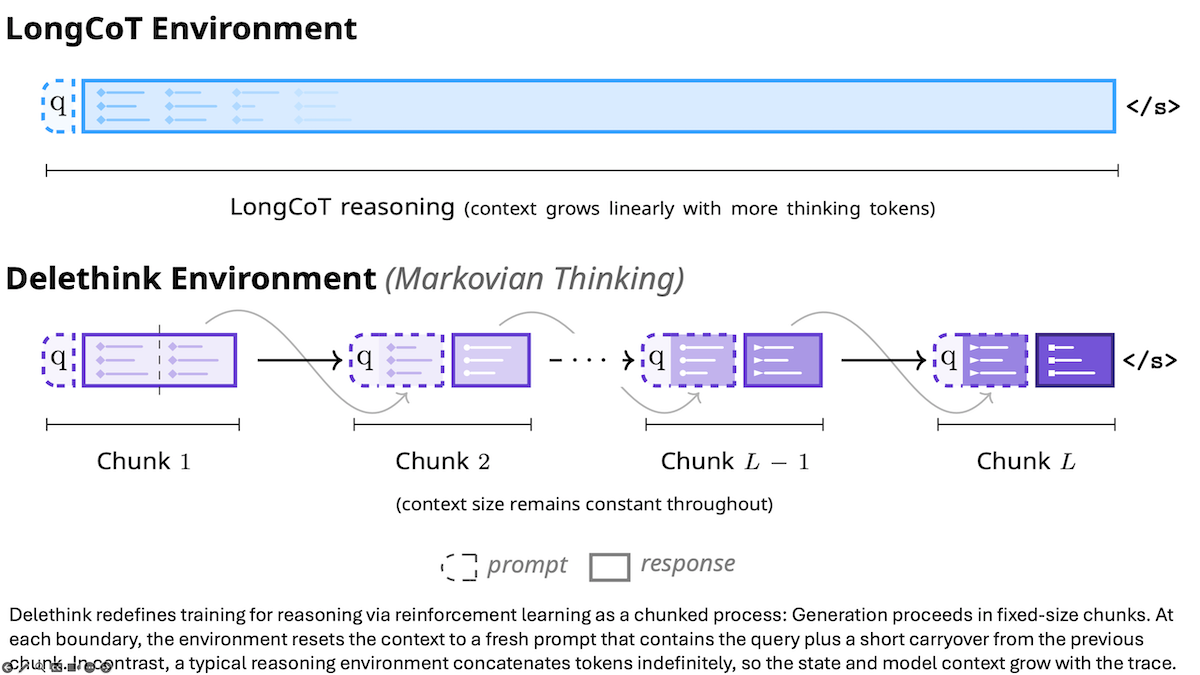
重要な洞察:推論トークンは通常大規模言語モデルのコンテキストウィンドウ内に蓄積し、その計算量はウィンドウサイズの2乗に依存します。これを緩和するには最大コンテキストサイズ内で推論を行うようモデルを学習させることが有効。すなわち、推論中に考えを最新のものに置き換えて継続できるようにします。
仕組み:著者らはR1-Distill 1.5BモデルをDeepScaleRデータセットの数学問題でファインチューニング。強化学習アルゴリズムGRPOを改変し4,000トークン単位で推論させる方法を採用しました:
- 数学問題を与え、推論の連鎖を完了するか最大8,000トークンに達するまで生成。
- 推論が未完ならば、元の質問と直近4,000トークンをコンテキストにして再開。
- これを連鎖完了か24,000トークンに達するまで繰り返し。
- その後、問題を解く試みを行い正答で報酬取得。
結果:著者らはGRPOで24,000トークン推論予算下でファインチューニングしたモデルと、それ以前の同モデルの比較を行い、24,000、96,000、128,000トークン推論予算で性能評価しました。
- 24,000トークン予算では3つの数学ベンチマークすべてでベースラインと同等かそれ以上。例:AIME 2025テストでDelethinkは31%の正答率、ベースラインは29%。
- 推論予算を増やすとDelethinkの性能は向上し続け、一方ベースラインの伸びは小さい。128,000トークン予算ではDelethinkが35%、ベースラインは30%。
- 96,000トークン推論予算での訓練コストは7 H100ヶ月分と見積もり、ベースラインは27 H100ヶ月分。
意義:本研究は非常に長い推論を計算的に不可能にしうる二乗計算負荷の壁を和らげます。線形注意機構など他手法は注意機構を変えるのに対し、Delethinkはモデル構造を変えず推論過程自体を再構成します。これにより新規モデルアーキテクチャなしで長文脈を効率的に扱う道が開けます。
私たちの考察:著者は多くのLLMが比較的短いコンテキストで事前学習されていることを指摘。例えばLLaMA 3は8,000トークンの例で学習を開始しています。これはDelethinkの性能向上に寄与している可能性があります。




