親愛なる皆さん、
AIによる職業の黙示録(ジョブパocalypse)は起こりません。
AIが大規模な失業を招くという話が、根拠のない不必要な恐怖をあおっています。AIは、他のどんな技術と同様に雇用に影響は与えますが、大規模な失業を煽り立てる誇張された物語を語るのは無責任で、害になります。ここで止めましょう。
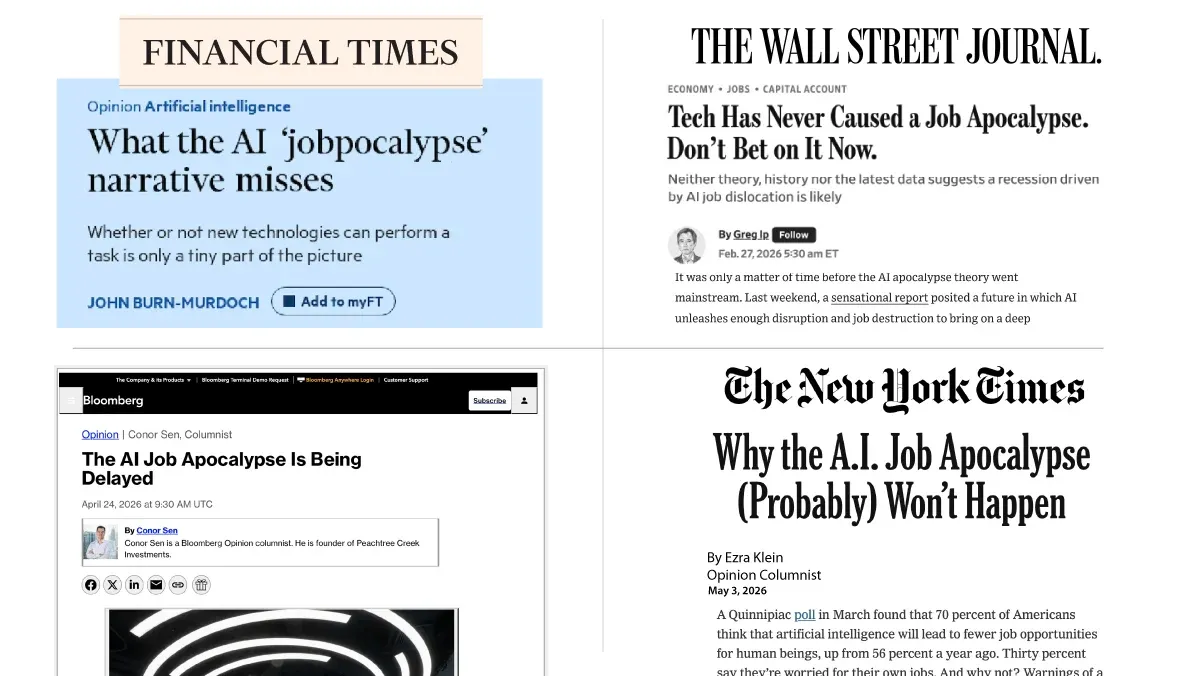
前回までの手紙でも、ジョブパocalypseについて懐疑的だと述べてきました。いま大衆紙が、この物語に押し返しをかけているのを見てうれしく思います。以下の画像には、最近の見出しの一部を掲載しています。
ソフトウェアエンジニアリングは、コーディングエージェントが先行しているため、AIツールの影響を最も受けている分野です。それでも、ソフトウェアエンジニアの採用は依然として 強い! つまり、AIが仕事を奪う例は確かにあるものの、傾向としては、雇用破壊をはるかに上回って純増が起きていることが強く示唆されています。これは、これまでの技術の波と同じです。さらに、AIのあらゆる刺激的な進歩にもかかわらず、米国の失業率は依然として健全な4.3%です。
なぜAIによるジョブパocalypseという物語はそんなに人気なのでしょうか?ひとつには、最前線のAIラボには、AI技術をより強力に見せる物語を語る強い動機があります。最も極端な場合、AIが「支配する」ことでAIが人類を絶滅させるといったSF的なシナリオを推しています。もし技術が多くの従業員を置き換えられるのなら、その技術はとても価値があるはずですよね!
また、多くのSaaSソフトウェア企業は、1ユーザーあたり年間約$100〜$1000を請求しています。しかし、AI企業が年収$100,000の従業員を置き換えられる、あるいはその従業員の生産性を50%高められるなら、仮に$10,000を請求しても十分に合理的に見えてきます。SaaSの一般的な価格ではなく、従業員の給与を基準(アンカー)にすることで、AI企業はより高い料金を請求できるのです。
さらに、企業には、レイオフ(解雇)がAIによって引き起こされたかのように語る強い動機があります。結局のところ、少ない人数でより生産性を高めるためにAIを使っていると話せば、賢そうに見えるからです。これは、金利が低く、政府による大規模な資金刺激策があったため資本が豊富だったパンデミック期に、企業が人員を過剰に採用していたことを認めるよりも、よいメッセージです。
はっきり言うと、AIによって多くの人の仕事が変わっていることは理解しています。これは大変です。ストレスでもあります。(人によっては楽しいと感じることもあるでしょう。)影響を受けるすべての人に共感しています。同時に、これは雇用市場の崩壊を予測するのとはまったく別の話です。
社会は、現実にほとんど根拠がない物語を何年も語り続け、その結果、社会全体としての意思決定が貧弱になることがあります。たとえば、原子力発電所の安全性に対する不安が、原子力への投資不足につながりました。1960年代の「人口爆弾」への恐れが、人口を減らすための厳しい政策を各国に実施させました。そして食事中の脂肪への懸念が、何十年もの間、政府に不健康な高糖質の食生活を推進させました。
いま主流メディアがジョブパocalypseに対して公然と懐疑的になっている今、これらの物語が(AIによる人類絶滅への恐れのように)だんだん効力を失っていくことを願っています。
AIによるジョブパocalypseの予測とは逆を、私は予想します。つまり、AIジョブ大盛会(アパロオザ)です!AIは、より多くの良いAIエンジニアリングの仕事を生み出します。また、雇用市場全体の未来についても前向きです。AIエンジニアがやる仕事は、従来のソフトウェアエンジニアリングとは異なり、これらの仕事の多くは、従来の“開発者を多く抱える大企業”以外の事業者の中で行われるでしょう。AI以外の職種でも、AIのせいで必要なスキルは変わります。だからこそ、より多くの人がAIに精通するよう後押しするのに良い時期です。 そして、将来のさまざまにあるけれど種類の違う仕事に、備えておくべきです!
引き続き作り続けてください、
Andrew
DEEPLEARNING.AIからのメッセージ DEEPLEARNING.AI

ほとんどのエージェントはテキストで応答します。チャート、フォーム、インタラクティブなユーザーインターフェースを描画するエージェントを作る方法を学びましょう。このコースでは、LangChainエージェントをReactのフロントエンドに接続し、生成UIのあらゆる領域にわたって構築します。そして、ユーザーとエージェントが共有ステートで作業できるフルスタックアプリで締めくくります。 無料で登録!
News

ByteDance、動画リーダーシップに入札
OpenAIがSoraの運営終了に向けて準備するなか、ByteDanceは自社の動画生成モデルを数億人のユーザーに提供可能にしました。
新着情報: ByteDanceは、その人気の動画編集アプリ CapCutに、多様なモダリティ(マルチモーダル)対応の動画生成器である Seedance 2.0を追加しました。今年初めに中国で公開されたこのモデルは、現在、東南アジア、ラテンアメリカ、アフリカ、中東、ヨーロッパの一部、日本、そして米国の、CapCutの有料ユーザーに提供されています。
- 入出力: 入力: テキスト、画像、音声、動画(最大3つの動画クリップ、9つの画像、3つの音声クリップ)。出力: 同期された動画と音声(6つのアスペクト比: 21:9、16:9、4:3、1:1、3:4、9:16で、短辺480または720ピクセル、4〜15秒)
- 機能: 複数言語でのリップシンク対話、環境音、音楽、1つのクリップ内でカットを伴う複数のカメラショット、プロンプトによって制御されるカメラと照明、目に見えない透かしで示された出力、実在の人物の顔または著作権で保護されたキャラクターを含む入力画像のブロック(CapCut経由)
- 性能: Arena AIおよびArtificial Analysisの動画リーダーボードで上位2位以内
- 提供/価格: CapCut経由(中国ではJianying)の有料ティア、DreaminaのWebインターフェース、ByteDanceのサービスであるBytePlusおよびVolcengine経由のAPI、ならびに第三者プロバイダー。例として、 Higgsfield.ai では、出力1秒あたり0.30ドル(720ピクセル、音声込み)またはSeeDance 2.0 Fastによる高速処理で1秒あたり0.24ドル
- 非公開: アーキテクチャ、パラメータ数、学習データ、手法
仕組み: Seedance 2.0は ByteDanceの先行研究を 拡張したものです。従来は、オーディオビジュアルストリームの同期生成を並列で行っていましたが、今回は統一されたシステム内での共同生成へと発展させています。ByteDanceは 発表 で、このアーキテクチャを「スパース(疎な)」と表現しています。
- このモデルは4つのタスクに対して、動画-音声の参照入力を受け付けます。(i)参照ベース生成は、被写体、動き、視覚効果、および/またはスタイルの手がかりを新しい出力へ適用します。(ii)編集は、既存の動画内で指定した領域、キャラクター、アクション、および/または音声を変更します。(iii)拡張は、既存の動画の前または後に続く出力を生成します。(iv)組み合わせモードでは、これらを組み合わせます(例: 参照画像にある被写体を、既存動画の被写体と入れ替える)。
- 音声は動画と同時に生成され、ステレオの対話、効果音、背景音が作られます。
- モデルは、個別のクリップを生成して組み立てるのではなく、1回のパスで連続するショットとカットを生成するため、キャラクターとシーンの一貫性を保ちやすくなります。
性能: Seedance 2.0は、2つの独立したリーダーボードでそれぞれ1位と2位にランクインしています。これらのボードは、人間の嗜好を用いたブラインド投票による一対一の勝負でモデルを評価します。AlibabaのHappyHorse-1.0は、両方のリーダーボードで最も近い挑戦者です。
- arena.aiでは、Seedance 2.0はテキストから動画への性能で1,460 Elo、 画像から動画への 性能で1,454 Eloを達成し、HappyHorse-1.0を両カテゴリでわずかに上回りました(各1,444 Elo)。ただし、リーダーボードではSeedance 2.0とHappyHorse-1.0の結果が暫定(preliminary)としてラベル付けされています。
- Artificial Analysisでは、AlibabaのHappyHorse-1.0が4つの動画カテゴリのうち3つをリードしています(音声なしの画像から動画、音声あり/なしのテキストから動画)。一方でSeedance 2.0は2位です。Seedance 2.0は同期された音声での画像から動画への性能をリードし、1,182 Eloを達成。HappyHorse-1.0(1,168 Elo)およびSky Work AIのSkyReels V4(1,091 Elo)よりも上です。
- ByteDanceは、細部の安定性、「ハイパーリアリズム」、音声の歪み、複数被写体の一貫性、テキストの描画精度、そして「複雑な」編集効果に限界があることを指摘しています。
そうだが: ByteDanceが中国でSeedance 2.0をリリースした直後、トム・クルーズとブラッド・ピットの俳優の似姿が含まれた生成クリップがきっかけとなり、トップ6つのハリウッド・スタジオが、同社に対して、著作権で保護された素材でモデルを学習し続けることをやめるよう求めるとともに、著作権で保護された素材に基づいてクリップを生成するユーザーをブロックするよう要求しました。紛争は現在も解決していません。ByteDanceは CapCutにセーフガードを追加 しましたが、それが第三者のAPI経由で生成された出力にも適用されるかどうかは依然として不明です。
背景: 動画生成市場は、過去1カ月の間に急速に勢力図が塗り替えられました。米国の開発者は消費者向け市場から後退し、中国の開発者は加速するペースで新しいモデルを投入しています。
- 3月にOpenAIが SoraアプリとAPIを終了する と発表しました。報道によると、Soraの1日のアクティブユーザー数が、ローンチ時の約100万人から50万人未満に落ち込んだ後、同社は計算資源をコーディングやビジネス向けのプロダクトに振り向けたとのことです。一方で、サービスの運用には推定で1日あたり100万ドルのコストがかかるとされています。
- AlibabaのHappyHorse-1.0は、4月上旬に独立した動画リーダーボードでデビューしました。その時点でもクローズドベータテストの最中でしたが、複数のカテゴリで1位まで上昇しました。
- その直後、Alibabaが HappyOysterを発表 しました。HappyOysterは、ゲームや映画の開発向けに3D環境を生成するAIシステムです。ユーザーはテキストまたは画像から3D環境を生成でき、リアルタイムでそれを誘導(操作)できます。
- Tencentは、同日、更新版の Hunyuan 3D をオープンソース化しました。
重要な理由: 競合はビデオ生成か編集アプリのどちらかを提供していますが、ByteDanceはその両方を所有しています。さらに、その編集ツールは驚くほどの到達力を持っているようです。 CapCut とされるところによれば モバイルで月間アクティブユーザーが7億3600万人あり、消費者向けAIプロダクトとしてはChatGPTに次ぐ第2位です。CapCutへのSeedance 2.0の登場が示すのは、1社が両方を支配していると何ができるのか、ということです。
私たちの見立て: OpenAIがSoraを撤退したことは、厳しい現実を示しています。現在の計算コストを考えると、AI生成の動画は高価な“消費者向け”プロダクトです。
NvidiaがAIを使ってチップを設計する方法
Nvidiaのチーフサイエンティストは、AIモデルに新しいGPUを設計させた上で、システムが仕事をしている間に数日スキーに行くことを夢見ています。彼は、その目標に向けたNvidiaの進展と、さらにどこまで進む必要があるのかを説明しました。
新しい動き: >Nvidiaで約300人の研究者を率いるBill Dallyは、3月中旬にNvidiaのGTCカンファレンスで、ステージ上で自分のGoogle側の同僚であるJeff Deanと対話しながら、会社のチップ設計におけるAIの役割が拡大していることを described しました。彼の例(動画では約24分から始まる)では、チップの構成要素を配置する強化学習システムから、数十年分の社内にある独自文書で訓練された大規模言語モデルまで、幅広いものが挙げられました。
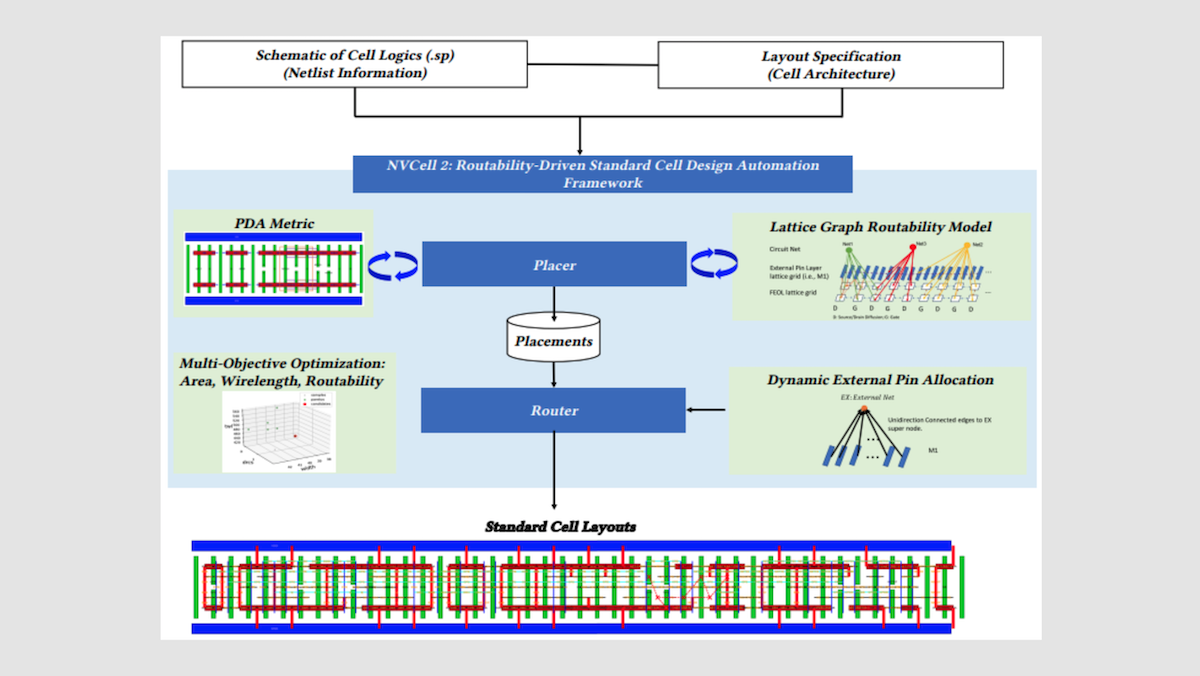
仕組み: Nvidiaは、チップ設計の5つの段階でAIを適用しています。部品の配置、算術回路の設計(アダーやカウンタのように2進数の数値に対して計算を行う構成要素)、一般的なエンジニアリング支援、完成設計の検証、そして新しいレイアウトの探索です。
- Nvidiaが新しい半導体の製造プロセスを活用するたびに——一般には、部品サイズを縮小し、その結果、シリコン1エリアあたりにより多くの部品を詰め込めるようにするため——、ロジックゲートやメモリラッチといった論理回路の部品を含む、約2,500〜3,000個の小さく再利用可能なレイアウトブロック、つまりセルを新たに作り直さなければなりません。こうした作業を行うAIシステムが NVCell です。NVCellは、候補となるレイアウトを提案する遺伝的アルゴリズムと、設計ルール違反を段階的に修正する強化学習エージェントを組み合わせます(例えば、配線同士が近すぎるケース)。エージェントは、違反を解消するたびに報酬を受け、さらに各ステップごとに小さなペナルティを受けます。これは、クリーンな設計に至る最短経路を見つけるためのインセンティブです。ルールチェッカーが違反を検出し、エージェントがそれを直すことを学習します。NVCellは、従来8人のエンジニアが約10か月かけていた作業を、1台のGPUで一晩の実行にまで圧縮しました。結果は、各セルが占有する面積、消費電力、そしてそこを通して信号がどれだけ速く伝搬するかの点で、人間の設計と同等、あるいはそれを上回りました。
- 別の強化学習システムである PrefixRL は、GPUの算術ユニットの中心にある微視的な回路を設計します。エージェントは、その回路設計がタイミング制約を満たしつつ、チップが占める面積と消費電力を最小化できた場合に報酬を受け取ります。こうして得られた部品は、「bizarre(奇妙な)」構成で、人間の設計より20%〜30%優れているとDallyは述べています。例えば、PrefixRLが設計した64ビット加算器(2つの2進数を合計する回路)は、業界標準のチップ設計ツールで作られた同等の設計に比べて、チップ面積を25%少なく占有します。
- Nvidiaは社内利用のために2つの大規模言語モデル、ChipNeMoとBugNeMoを構築しました。チームは、オープンウェイトのLLaMA 2ベースモデル(パラメータ数70億および130億)をNvidiaの社内ドキュメントでファインチューニングしました。そこには、同社がこれまでに製造してきたすべてのGPUに対応する低レベルの設計コードや、それに付随するハードウェア仕様が含まれています。2023年の 論文 では、3つの用途が説明されています。(i) Nvidiaのハードウェアに関するエンジニアの質問に答える、(ii) 専用のチップ設計言語でコード断片を生成する、(iii) バグ報告を要約する、です。この研究において、ドメイン適応されたモデルは、規模が5倍も大きい汎用ベースモデルに対して、幅広いチップ設計タスクで同等以上の、あるいは上回る性能を示しました。
- 完成した設計が意図したとおりに動作することを確認する検証は、最も長い段階です。Dallyのチームは、AIを使ってこれを圧縮しようと取り組んでいます。
そう、しかし: プロンプトに基づいてエンドツーエンドでGPUを設計することは、依然として遠い目標だとDallyは述べました。
今回の背景: AIはまだゼロからチップを設計しているわけではありませんが、その目標に向けて着実に前進しています。
- AIチップ設計スタートアップのVerkoranが4月に発表した 論文 では、219語の仕様が与えられると、エージェント型AIシステムが自律的に1.48ギガヘルツのRISC-V CPUチップを設計し、これは2011年頃のIntel Celeron SU2300とほぼ同等のものだと述べられています。著者らはシミュレーションで設計を検証しましたが、それを実際に製造はしていません。
- 昨年、プリンストン大学およびインド工科大学マドラス校の研究者たちは、深層学習と進化的アルゴリズムを用いて、 ワイヤレス通信回路を設計するために 行いました。その結果、従来の経験則では説明できない高性能な設計が得られました。
- 2023年、Googleは 強化学習 を用いて、Tensor Processing Units(TPU)の表面上にあるコンポーネントを配置することに関する活用を説明しました。
- Nvidiaはまず2021年に NVCell を強調しました。続いて2022年にPrefixRLアダー、そして2023年にChipNeMoが登場しました。
重要な理由: 半導体設計では探索空間が非常に巨大で、人間の直感ではごく薄くしかカバーできません。強化学習エージェントによって生み出された回路は、珍しいものの、測定可能な形で優れているというNvidiaの報告は、AIが人間のエンジニアが思いつかないような解決策を見つけることで問題を解く、というより広い傾向を裏付けています。さらに同社は、次世代GPUの設計を行うAIシステムの学習にGPUを使っているため、世代ごとに次の設計を加速させるだけでなく、それを設計に役立てたツールを実行するのにより適したチップも生み出すことになります。
私たちの見立て: 「AIが若手エンジニアの会社の技術理解を助ける」ことと、「AIが次のGPUを設計する」ことの間には、かなりの距離があります。期待値をうまく調整しようとするDallyの姿勢は、さわやかです。
仕事の現場におけるAI、定量化してみる
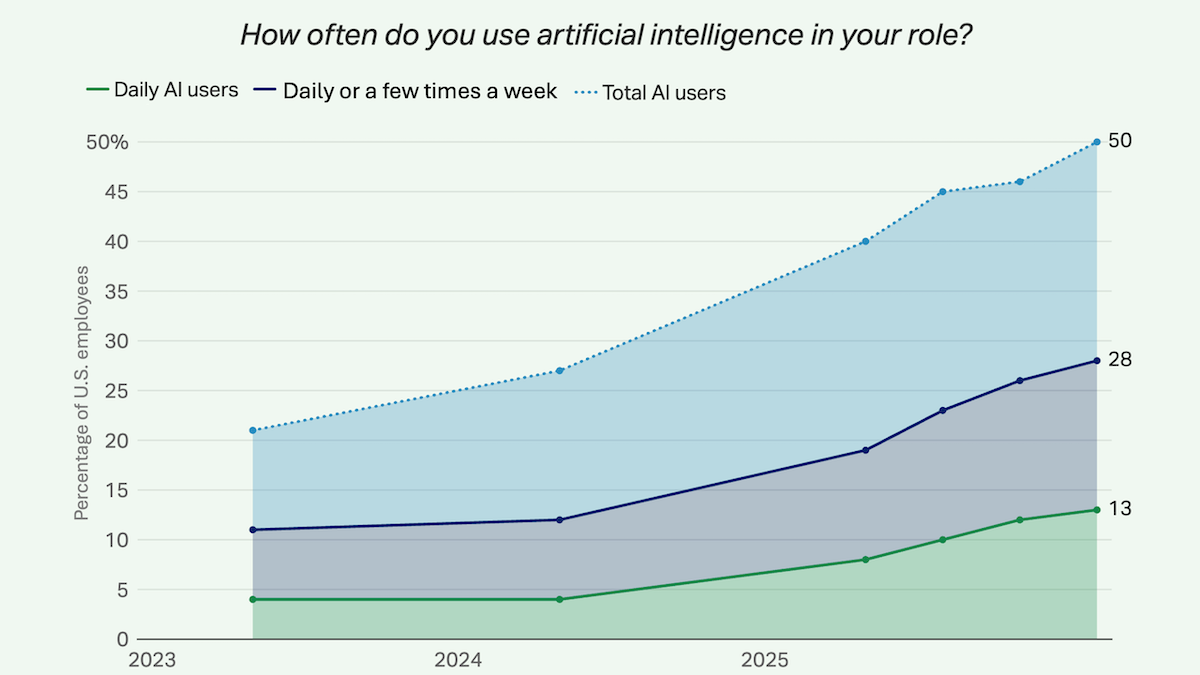
米国では、昨年に仕事の場で少なくとも数回AIを使った労働者が半数いました。これは、米国の職場におけるAI導入が着実に増えていることを示しています。
新しい動き: Gallupが実施した 調査 によると、AIを使ったことのある米国の労働者の大半は、AIが生産性を高めたと感じていました。Gallupは、幅広いテーマについて世論を調査する組織です。回答者が最もAIを使う可能性が高かったのは、AIが自分たちの働き方にうまく組み込まれ、雇用主がそれを後押ししている場合でした。それでもなお、多くの従業員と雇用主は足踏みしています。
仕組み: Gallupは2月4日から2月19日にかけて、AIと仕事に関連するさまざまな質問について、米国の従業員23,700人を対象に調査を行いました。生産性への影響、業務フローが変わっているかどうか、組織がそれを支援し導入しているかどうかを検討しました。一部の従業員はAIに懐疑的ですが、調査結果は、AIが 生産性を向上させ、また、導入を支援し適切なツールを提供している組織でより大きな役割を果たすことを示唆しています。
- 定期的なAIの利用は着実に増えています。たとえば、回答者の13%はAIを毎日使っており、28%は週に数回使っていると答えました。これらの数値は、それぞれ2023年の4%および11%から増加しています。組織単位では、5人に2人の労働者が「雇用主が職場にAIツールを導入した」と答え、4分の1の企業ではAIの明確な戦略があると回答しました。
- AIは 生産性を高めていますが、現時点では確立されたプロセスの代わりにはなっていません。AIが使われている企業の従業員のうち65%は生産性が向上したと答えましたが、31%は自分たちの働き方が変わったと答えました。AIが使われている組織で働いていた回答者のうち、AIが自分たちの働き方に影響したことに「反対」したのはわずか7%でした。
- 管理職の支援が従業員の行動と見通しに影響します。AIを使っている組織で、強く支援的な上司がいる従業員ほど、AIを使う可能性が高く、AIが自分の仕事を変えたことにも同意しやすくなっていました。
- 利用が少ない人や利用していない人は、現状の仕事を続けたいという希望を幅広く示しました。AI導入の障壁としては、倫理面の懸念、データプライバシー、そしてAIが役に立たないという信念または経験があることも、よく挙げられました。
ニュースの背景: 一部の 報告 によれば、AIの影響は、テックの熱狂的な支持者たちが約束してきたものに比べて失望を招く結果になっています。「AIはどこにでもある――しかし雇用・生産性・インフレなどの指標といった、これからのマクロ経済データには現れていない」と、投資会社ApolloのチーフエコノミストであるTorsten Slokは 書いています 。別の見方では、AIが雇用市場に影響を与えているという証拠が積み上がっているとも言われます。 スタンフォード大学の経済学者によって昨年公表された研究 では、ソフトウェア開発者や顧客対応の担当者など、AIによって影響を受ける可能性がある仕事に就いている労働者の雇用が減少していることが分かったとされています。
重要な理由: Gallupの結果は、労働者がAIを、自分の仕事を代わりにしてもらうためではなく、仕事をよりうまくこなすために使っていることを示しています。これは、単調な作業から解放される可能性がある労働者にとっても、そして生産性を得られる可能性がある雇用主にとっても良いことになり得ます。しかしAIには、一部の職種を完全に自動化してしまう可能性もあります。AI主導の生産性向上が、雇用全体を減らすのか増やすのかについては、まだ結論が出ていません。
私たちの見立て: AIによる大規模な雇用喪失を予測するのは一部の界隈では流行っていますが、現状のシグナルは相反しており、中にはAIが雇用を押し上げていることを示すものもあります。たとえば、2025年の Brookingsの研究 では、AIに投資した企業はより多くの労働者を採用していることが分かりました。労働者が、想像力に富んだ生産的なやり方でAIを活用することで目立つための機会は尽きません。

新しいタスクに適応するロボット
ニューラルネットワークは、新しいタスクを学習するにつれて、以前のタスクを遂行する方法を忘れてしまうことがあります。シンプルなレシピにより、この問題に対処できます。特に視覚-言語モデルを、ロボティクス用途に適用する場合の問題です。
新規性: Jiaheng Hu、Jay Shim、およびテキサス大学オースティン校、カリフォルニア大学ロサンゼルス校、ナンヤン工科大学、ソニーの同僚らは、強化学習と低ランク適応(LoRA)の組み合わせを用いて、大規模な視覚-言語-行動モデルを訓練し、シミュレーションにおけるロボティクス訓練で既存手法を上回りました。彼らのレシピは、モデルがタスクを順に学習するときに起こり得る壊滅的忘却(catastrophic forgetting)を抑えました。
重要な洞察: 大規模な事前学習済みモデル、LoRA、そしてオンポリシー強化学習を組み合わせることで、学習中にモデルが忘れ得る情報量を減らせます。
- 大規模な事前学習済みモデルへの流れは、ポストトレーニング中にモデルがどれだけ忘れ得るかを制限します。パラメータ数が非常に多いモデルでは、小さな更新が既存の知識に干渉しにくい可能性があります。
- LoRAは、小さな2つの行列の積をモデルに追加することでモデルの重みを調整し、モデルがどれだけ変化できるかを制限します。したがって、それを推論時に適用すると、どれだけ忘れ得るかも制限されます。
- GRPOなどのオンポリシー強化学習手法も更新を抑えます。なぜなら、モデル自身が生成した行動に報酬を与えるからです。つまり、これらも新しいことを学習している間に、どれだけ忘れ得るかを制限します。対照的に、教師ありのファインチューニングやオフポリシー強化学習では、別のポリシーによって選ばれた行動を取ったことに対してモデルへ報酬が与えられるため、モデルが以前には行っていなかった可能性のある行動を学習すると、大きな更新につながることがあります。
仕組み: 著者らは、大規模な事前学習済みの視覚-言語-行動(VLA)モデル(OpenVLA-OFT)を、シミュレーションされたロボットアームによって実行されるLIBEROベンチマークの3つのタスクスイートそれぞれに対してファインチューニングしました。各スイートには、引き出しを開ける、物体を目標位置へ移動する、といった5つのタスクが含まれていました。著者らは、各タスクを順番にファインチューニングしてモデルを学習させました。
- 各ステップで、モデルは画像と指示を入力として受け取り、ロボットアームとグリッパーを制御するための連続的な行動の列を予測しました。
- 著者らは、以前のタスクのデータを再利用せずに、新しいタスクを学習するために、GRPOとLoRAを用いてモデルをファインチューニングしました。GRPOの間、モデルは各タスクの完了に対して報酬を受け取りました。
結果: 著者らの方法は、逐次的にロボティクスタスクを反復学習する先行手法に対して、同等または上回る性能を達成しました。フェアな比較のために、著者らはその先行手法にGRPOとLoRAを組み合わせました。その結果、忘却はほとんど起こらず、さらにファインチューニング中にモデルが遭遇していないタスクでもわずかな改善が見られました。個々の構成要素を取り除くと、性能が崩れ、強い忘却につながりました。
- libero-spatialタスクにおいて、著者らの方法は平均成功率81.2%に到達しました。この結果は、データを再利用するアプローチであるDark Experience Replay(73.4)を上回り、また、出力層では学習率を高くし、初期層では学習率を低くすることで、学習中に初期層があまり変化しないようにするSLCA(69.9)も上回りました。さらに、前のタスクで重要だった重みへの変更にペナルティを与えることで知識を保持しようとするElastic Weight Consolidation(66.1)も上回りました。
- 著者らの方法は、libero-spatialにおいて、ほぼゼロの忘却を示しました(以前に学習したタスクでの成功率の平均低下が0.3パーセンテージポイント)。これは、Elastic Weight Consolidation(0.7)やDark Experience Replay(4.7)より低く、SLCAと同程度でした(-0.6。つまり、以前のタスクにおける性能がわずかに改善したことを意味します)。
- トレーニング中にモデルが遭遇しなかった5つの追加のlibero-spatialタスクにおいて、著者らの方法は平均成功率57.1%に到達し、Elastic Weight Consolidation(52.6)およびDark Experience Replay(55.2)を上回りました。
はい、しかし: 比較において著者らは、LIBEROデータセットを用いて、先行手法にLoRAとGRPOを追加しました。しかし先行手法は、これらの技術と組み合わせることや、そのデータを使うことを想定して設計されていません。また、意図どおりに厳密に適用した場合に同程度の比較になったかは明確ではありません。例えばDark Experience Replayは、新しいタスクでモデルをファインチューニングしつつ、以前のタスクのファインチューニングで使われた例を再導入することで忘却を避けることを目的としています。そこにLoRAを追加すると、新しいタスクの学習に影響が出る可能性があります。
なぜ重要か: すべてのタスクを同時にロボットに学習させることは有効になり得ますが、その場合、すべてのタスクを事前に洗い出しておく必要があります。タスクが変わるなら、1つずつタスクを学習したほうが有益です。そして多くの場合、以前の訓練を保持することが価値になります。既存の手法と比べると、著者らの逐次的なファインチューニング手法は、より単純で理解しやすく、また著者らが検証した条件下ではより効果的でした。(著者らは、ロボティクス以外でも有効かどうかは調べていません。)
私たちの見立て: ロボットは新しい環境や状況へ急速に入りつつあります。機敏な動作は、新しいタスクにその場で適応できるロボットによって恩恵を受けるでしょう。




