本特集では、書籍『AIエージェント 設計&実装 完全ガイド』(日経BP)から抜粋した内容を基に、AIエージェントを実装および活用するための基礎知識を解説します。第5回では、「RAG」と「マルチモーダル」を取り上げます。
今回は、大規模言語モデル(LLM)の応用的な機能であるRAG(Retrieval Augmented Generation:検索拡張生成)とマルチモーダルについて説明します。従来の生成AIは入力されたテキストに対して、事前に学習されたデータをもとにテキストで回答するものでした。ですがRAGによってWebや社内の情報を参照できるようになりました。
さらにマルチモーダルによって、入力されたテキストに対して画像・動画を出力する、あるいは入力された画像や動画に対してテキストを出力することができるようになりました。いずれも生成AIのビジネス活用に大きく寄与した機能といえるでしょう。

外部の情報を組み合わせる
RAGとは、「外部または独自の情報を組み合わせることで、より正確な回答を得られるフレームワーク」です。RAGは「Retrieve」「Augment」「Generate」で構成されます。
・Retrieve
質問の回答に必要な情報を、Webや社内データベースなどから検索・取得します。
・Augment
取得した情報と質問を組み合わせてLLM に入力するプロンプトを作成します。検索した情報をユーザープロンプトに反映させてプロンプトを再構築する点が特徴です。
・Generate
Augmentで生成したプロンプトに対して、LLMが回答を生成します。
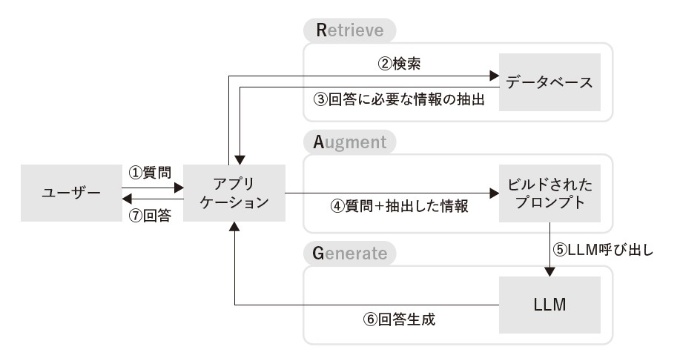
具体的な流れを見てみましょう。ユーザーはまず、アプリケーションに質問を入力します(上図(1))。するとアプリケーションはデータベースなどを検索して(同(2))、回答に必要な情報を抽出・取得します(同(3))。
次にアプリケーションはユーザーからの質問を抽出・取得した情報を使ってプロンプトをビルド(作成)します(同(4))。そしてLLMを呼び出してそのプロンプトを入力(同(5))。LLM が生成した回答をアプリケーションが受け取り(同(6))、ユーザーに回答として出力します(同(7))。
RAGが注目される理由は、事前に学習したデータだけでは答えられなかった質問にも、外部情報を参照することで回答できるようになったからです。例えば、従来のLLMに社内の費用申請方法を聞いても、社内マニュアル等の情報は一般的に公開されていないため回答できませんでした。しかし、RAGによって社内マニュアルを参照させることで回答できるようになりました。
また事前学習されたデータが古いと、必然的に回答の内容も古いといった問題もありました。ですがRAGならWeb上で最新情報を検索するため、その問題も解消できるようになりました。
なお、LLMに外部または独自の情報を活用させる方法としては「ファインチューニング」という手法もあります。これは追加したい情報をLLMに直接学習させる手法です。ただ、大量のデータや高性能なGPUが必要になるため、ハードルが高いのが現状です。その点RAGは、LLMに追加学習させることなく外部情報を参照できるため、導入するハードルが低い点も注目されています。
次のページ
多様なデータを一度に取り扱うこの記事は有料会員限定です

