親愛なる皆様、
米国の政策は同盟国が米国のAI技術を使用することから遠ざけています。これにより、主権AIへの関心が高まっています。主権AIとは、外国勢力に依存せずにAI技術にアクセスできる国家の能力を指します。これは米国の影響力を弱めますが、競争の激化やオープンソースの支援増加につながる可能性があります。
米国はトランジスタ、インターネット、そして現代AIを支えるトランスフォーマーアーキテクチャを発明し、長らく技術の大国でした。私はアメリカを愛し、その成功に向けて努力しています。しかし、複数政権にわたる多くの行動が他国に過度な依存を懸念させています。
2022年、ロシアのウクライナ侵攻後、ロシアのオリガルヒに関連する銀行への制裁で一般消費者のクレジットカードが停止されました。政権を去る直前にバイデンは多くの国、同盟国を含むが、AIチップの購入を制限する「AI拡散」輸出管理を実施しました。
トランプ政権下の「アメリカ第一」政策は他国を遠ざける動きを大きく加速させました。味方も敵対国も対象とした乱雑な関税、グリーンランドの接収の脅威、移民政策はバイデン政権下での南部国境の混乱に過剰反応し、ICE(移民税関捜査局)によるレネー・グッド、アレックス・プレッティらの射殺など非友好的な措置をとりました。世界のメディアはICEがアメリカの都市を威嚇する映像を広く配信し、私の海外の法を守る有能な友人たちも不当拘束の恐れから米国訪問をためらっています。
AIが戦略的に重要であることから、各国は外国勢力にアクセスを断たれないようにしたいのです。これが主権AIの背景です。
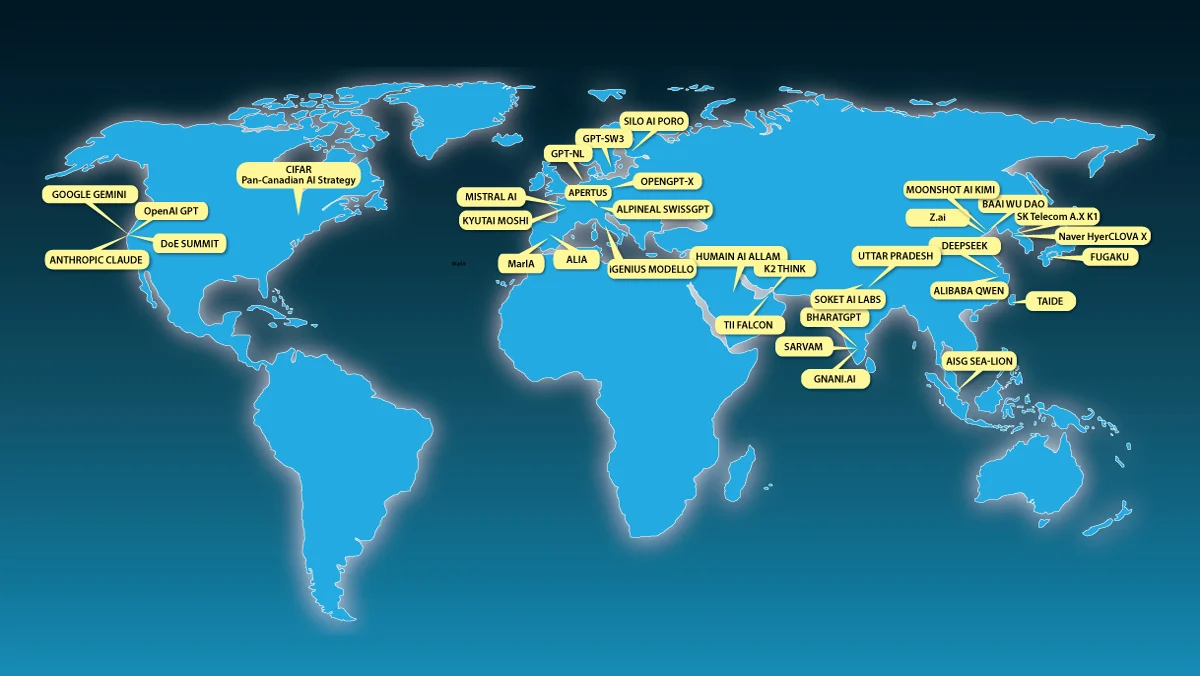
主権AIはまだ明確に定義された概念ではありません。完全な独立は非現実的です。米国設計、台湾製造のAIチップの良い代替はなく、多くのエネルギー機器やコンピューターハードウェアは中国で製造されています。しかし、OpenAI、Google、Anthropicという米国の主要企業が提供する最先端モデル以外の選択肢を持ちたいという欲求は明白です。このため、DeepSeek、Qwen、Kimi、GLMといったオープンウェイトの中国製モデルが特に米国外で急速に採用されています。
幸いにも、主権AIに関してはすべてを独自開発する必要はありません。世界のオープンソースコミュニティに参加することで、国家は自国のAIアクセスを確保できます。目的は全てを支配することではなく、自国のAI利用を他者にコントロールさせないことです。実際、国家はLinux、Python、PyTorchなどオープンソースソフトウェアを使っています。こうしたソフトウェアはどの国も支配できませんが、誰もが自由に使用できます。
これが国々にオープンソースやオープンウェイトモデルへの投資を促しています。UAE(私の元大学院のオフィスメイト、エリック・シンの指導の下!)はオープンソースの推論モデルK2 Thinkを発表しました。インド、フランス、韓国、スイス、サウジアラビアなども国内基盤モデルを開発しており、さらに多くの国が自国または信頼できる同盟国の管理下にある計算基盤の確保に取り組んでいます。
民主主義国間の世界的な分断と信頼の侵食は悪いことです。しかしながら、これにより競争が激化すれば明るい側面もあります。米国の検索エンジンGoogleやBingは世界的に支配的ですが、百度(中国)やヤンデックス(ロシア)は地域で成功しています。国が国内の有力企業を支援すれば(大手企業の優位性を考えると容易ではありませんが)、多くの企業が繁栄し、統合の遅延や競争の促進につながるでしょう。オープンソースへの参加は国が最先端を維持する最も低コストな方法です。
先週、ダボスの世界経済フォーラムでは多くのビジネスリーダーや政府関係者が米国技術プロバイダーへの依存を避けたいという意向と代替手段への欲求を語りました。皮肉にも「アメリカ第一」政策は世界のAIアクセスを強化する結果になるかもしれません。
引き続き構築を続けましょう!
アンドリュー
DEEPLEARNING.AIからのメッセージ

「Agent Skills with Anthropic」ではワークフローロジックをプロンプトから再利用可能なスキルに移すことで、エージェントの信頼性を高める方法を示しています。コーディングやデータ分析、調査などのワークフローに適用するスキルの設計・活用方法を学べます。 今すぐ登録
ニュース
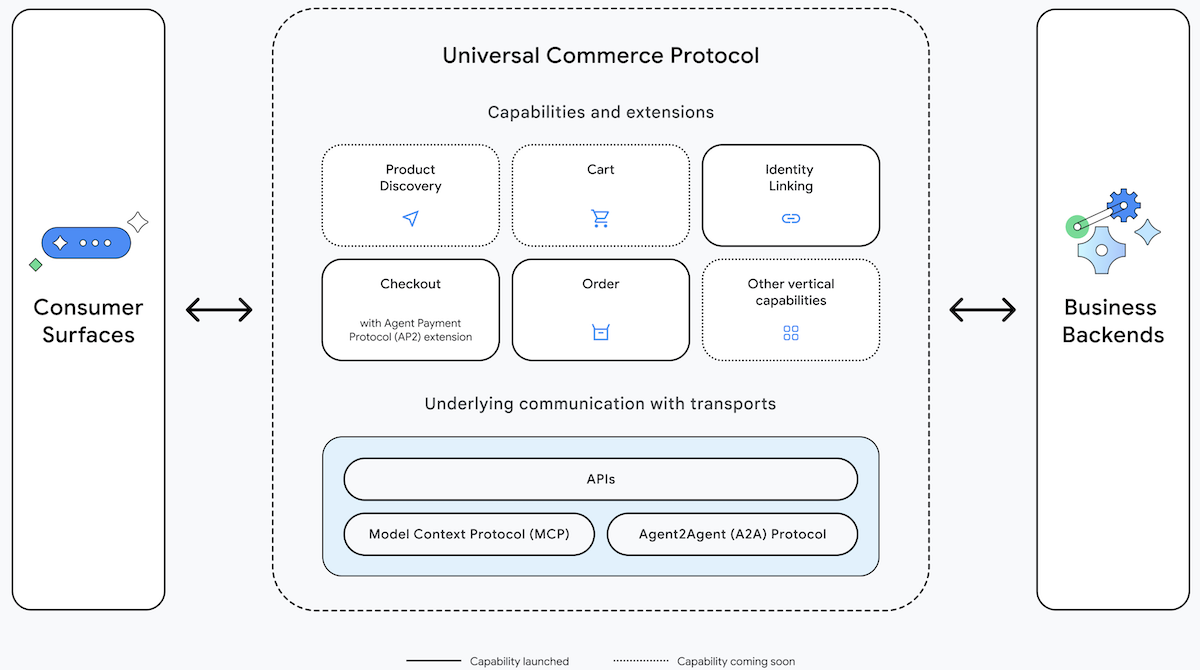
AIエージェント向けショッピングプロトコル
GoogleはAIエージェントが消費者のオンライン購入を支援し、商品発見から返品までを可能にするオープンソースプロトコルを導入しました。
新しい点: Universal Commerce Protocol (UCP) は消費者、プラットフォーム、業者、決済プロバイダーの代理取引を行うための標準化されたコマンドを提供します。エージェントは選択肢の提示、注文提出、支払いの整理、履行の管理が可能です。企業は対応可能な機能を宣言し、自動または個別化されたショッピングサービスおよび取引を促進できます。UCPはApache 2.0ライセンスで公開されています。
仕組み: UCPによって既存の小売検索、決済、業者インフラを利用してエージェントが動作します。GoogleはEtsy、Shopify、Target、Walmart、Wayfairなどのeコマース企業やAmerican Express、Mastercard、Stripe、Visaといった決済プロバイダーと協力して開発しました。
- プロトコルは消費者(アカウントや認証情報含む)、プラットフォーム(検索エンジンやオンラインストア等)、業者、商品やサービス(属性、特徴、価格、ロイヤリティ報酬等の考慮点含む)、決済、履行、配送とのやりとりのコマンドと変数を定義します。
- 決済、アイデンティティ、セキュリティにはオープンスタンダードを使用し、Model Context Protocol(ツールとデータアクセス)、Agent2Agent(エージェント間協力)、Agent Payments Protocol(決済プロバイダーとの安全なやりとり)とも互換性があります。OpenAIのAgentic Commerce Protocolと競合しますが、両者は並行利用可能です。
- GoogleはGeminアプリやGoogle検索のAIモード(検索エンジンのAI概要下部の「Dive deeper in AI Mode」をクリックで利用可能)でのAI生成回答内で販売商品を提示し、Google Payで支払いを受け付けます。認証はGoogle WalletまたはPayPalに保存された資格情報で行います。
背景: GoogleはUCPとともにAI対応コマースの多数の機能を発表しました。
- ビジネスエージェントは企業がGoogle検索上で潜在顧客と会話可能なブランドエージェントを構築可能にします。初参加企業はLowe’s、Michael’s、Poshmark、Reebokなどです。
- Direct Offersと呼ばれるパイロットプログラムはGoogle検索AIモードを使って商品情報を検索したユーザーに特別オファーを提示します。
- 小売業者はGoogleのMerchant Centerにアクセサリーや代替品、よくある質問の回答など特定の商品を補完する新しい情報タイプを追加可能で、これによりGoogle検索AIモード、Gemini、ビジネスエージェントが名前を言及する可能性が高まります。
重要性:消費者は商品情報や推薦にチャットボットをますます利用しています。UCPは見つけた商品をシンプルに購入できるようにし(消費者有利)、衝動買いを促進します(業者にとって有利)。これはGoogleの広告事業を補完し、チャットボットでの広告表示実験とも連動します。企業規模のビジネスが独立したエージェントを構築し、サプライチェーン全体を共同管理する道も開けます。
私たちの所感:UCPはオープンプロトコルですが、採用はGoogleやその他の集約者に明らかに利益をもたらします。かつてGoogleはGoogleショッピングという形で消費者検索を支配しようとしましたが、あまり成功しませんでした。Googleがサプライヤーを納得させカタログを公開し、Geminiや他のチャットボットがユーザーの買い物を手助けできれば、チャットボット運営者に巨大な力を与え shopping市場を統合する可能性があります。

画像中のテキスト精度向上
画像生成モデルはしばしばテキストを誤表現します。オープンウェイトモデルがオープンおよび専有の競合モデルを上回るテキスト描画性能を示しました。
新しい点: Z.aiはGLM-Imageを公開しました。これは二段階で動作するオープンウェイトの画像生成器です。第一段階で画像のレイアウトを決定し、第二段階で詳細を描き込みます。こちらで試せます。
- 入出力:テキスト、テキスト併用画像入力、画像出力(1024×1024〜2048×2048ピクセル)
- アーキテクチャ:自己回帰トランスフォーマー(90億パラメータ)で、先行のGLM-4-9B-0414から微調整。復号器は先行の拡散トランスフォーマーCogView4(70億パラメータ)、Glyph-ByT5テキストエンコーダを用いる。
- 特徴:画像の編集、スタイル変換、アイデンティティの一貫性、多被写体一貫性
- 利用可能性:MITライセンスで非商用・商用利用に向けて重みを無料でダウンロード可、APIは画像あたり0.015ドル
- 非公開:トレーニングデータ
仕組み:テキストまたはテキスト併用画像の入力から、GLM-Imageの自己回帰モデルは出力画像のレイアウトを低解像度トークン約256個でパッチ単位に生成し、その後出力画像の大きさにより1000〜4000のより高解像度トークンを生成し小さいパッチを表現します。テキスト描画向上のため、Glyph-ByT5エンコーダは文字形状を表すトークンを作成します。復号器は高解像度トークンとテキストトークンを受け取り画像を生成します。
- チームはGRPOという強化学習法で2つのコンポーネントを別々に訓練しました。
- 自己回帰モデルは3つの報酬で学習:(i)匿名の視覚言語モデルは画像のプロンプト適合度を評価、(ii)匿名の光学文字認識モデルは生成テキストの読みやすさを評価、(iii)HPSv3は人間の好みに基づき視覚的魅力を評価。
- 復号器は3種の詳細関連報酬で学習:LPIPS(出力と参照画像の類似度)、匿名のOCRモデル(テキスト判読性)、匿名の手の正確さモデル(生成手の解剖学的正確性)。
性能:Z.aiのテストで、GLM-Imageは英語と中国語のテキスト描画でオープンウェイトモデルをリードし、プロンプトの遵守度は中程度でした。美的評価の結果は公表されていません。
- CVTG-2K(英語テキスト描画ベンチマーク)でGLM-Imageは平均91.16%の正確度を達成し、オープンウェイトのZ-Image(86.71%)やQwen-Image-2512(86.04%)より優れ、専有モデルSeedream 4.5(89.9%)も上回りました。
- LongText-Benchは長文・複数行テキスト描画を英中両言語で評価。中国語ではGLM-Image(97.88%)がQwen-Image-2512(96.47%)や専有のNano Banana 2.0(94.91%)を上回るもSeedream 4.5(98.73%)に及ばず。英語部分ではGLM-Image(95.24%)はQwen-Image-2512(95.61%)に近いがSeedream 4.5(98.9%)やNano Banana 2.0(98.08%)に劣る。
- DPG-Benchは複数物体と各種属性・関係を含むプロンプトに対する画像の適合度を言語モデルにより評価。GLM-Image(84.78%)はJanus-Pro-7B(84.19%)を上回るもSeedream 4.5(88.63%)とQwen-Image(88.32%)には劣る。
背景:Z.aiはGLM-Imageが中国製Huawei Ascend Atlas 800T A2ハードウェアを完全に用いて訓練された初のオープンソースマルチモーダルモデルと主張。OpenAIは競合相手としてZhipu AIを特定しており、米国輸出規制の中、NvidiaやAMDのチップなしで競争力のあるAIモデルが構築可能であることの証明と位置づけています。ただしZ.aiは使用チップ数やトレーニング量を非公開で、Huaweiの効率とNvidiaの比較は困難です。
重要性:マーケティング資料、プレゼン資料、インフォグラフィック、教育コンテンツなど多くの用途でテキスト生成能力が必要です。従来の拡散モデルはこれが苦手でした。GLM-Imageは開発者が微調整や自己ホスティング可能な選択肢を提供します。
私たちの所感:役割分担によりより良いシステムが得られます。自己回帰モジュールが構想を描き、拡散復号器が画像を描くワークフローは双方の長所を活かしています。
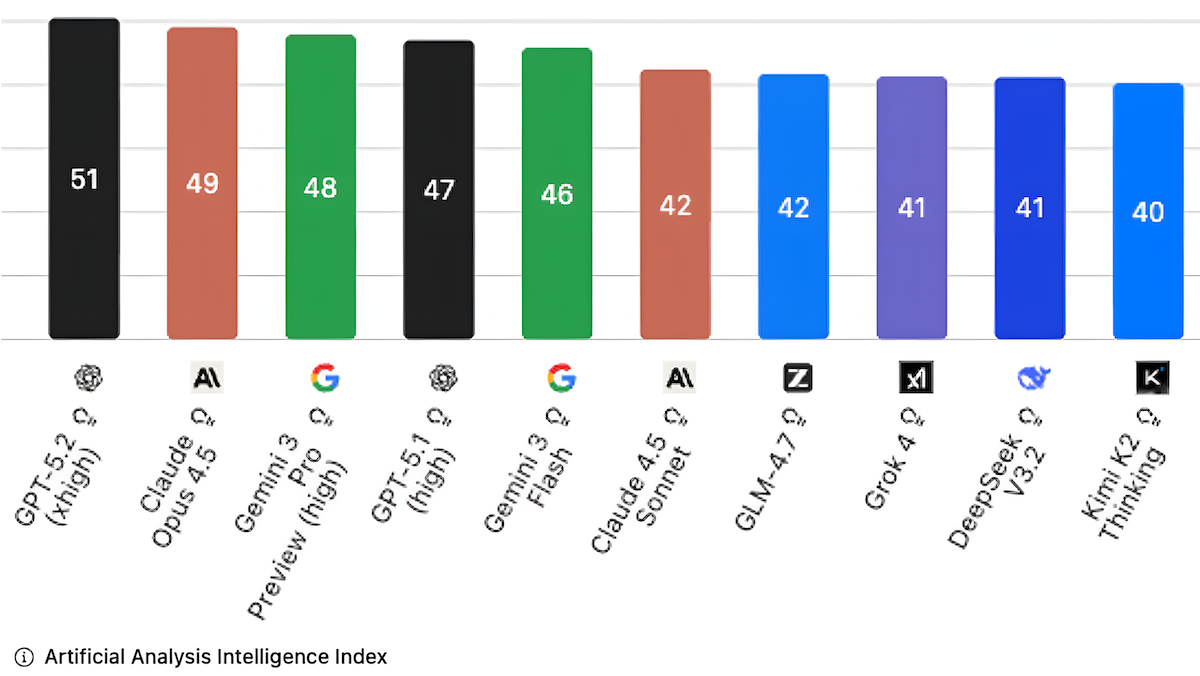
Artificial Analysisによる知能指数の刷新
AIシステムを評価するArtificial Analysisは、インテリジェンス指数の構成評価を更新し、大規模言語モデル(LLM)の実際的性能の反映を高めました。
新しい点: Artificial Analysis Intelligence Index v4.0はモデル性能10ベンチマークの平均で、既に多くのLLMがほぼ完璧に解いてしまう3ベンチマークを、より馴染みの薄い課題に差し替えました。新ベンチマークは経済的有用な作業能力、事実を推測なしで想起する力、問題解決力を計測します。GPT-5.2(超高推論設定、51点)が首位で、続いて推論モードの有効なClaude Opus 4.5(49点)、高推論設定のGemini 3 Pro Preview(48点)。GLM-4.7(42点)はオープンウェイトLLMのトップです。(注:アンドリュー・ングはArtificial Analysisに投資しています。)
仕組み:知能指数は英語のゼロショットテキスト入力を用いてLLMを評価します。Artificial Analysisは同じプロンプトを異なる推論・温度設定のモデルに入力し、ツール実行用コードによってモデルにはbash端末とウェブのみアクセスが許されます。v4.0では、MMLU-Pro(一般知識に基づく質問)、AIME 2025(数学競技問題)、LiveCodeBench(コーディング競技課題)の3ベンチマークを削除し、代わりに以下のテストを追加しました。
- GDPval-AAは文書、スプレッドシート、図表などの作成能力をテスト。Artificial Analysisは一組のプロンプトに対し2モデルの出力をGemini 3 Proにより勝敗・引き分けで評価し、エローレーティングを算出。テストされたモデルではGPT-5.2(超高推論、1428 Elo)が首位、Claude Opus 4.5(1399 Elo)、GLM-4.7(1185 Elo)と続く。
- AA-Omniscienceは多様な専門分野の質問を提示し、虚偽を混ぜず正答できるかを測定。正答は100点、間違い回答は-100点を付与。現行モデルで0超えは5モデルのみ。Gemini 3 Pro Preview(13点)が最高、Claude Opus 4.5(10点)、Grok 4(1点)と続く。正答率が高いモデルは虚偽率(誤答/総回答)が高く得点は悪い例がある。例としてGemini 3 Pro Previewは正答率54%ながら虚偽率88%、Claude Opus 4.5は正答率43%虚偽率58%である。
- CritPtは未公開の物理学の博士レベル問題71問を出題。全モデルにとって難しいベンチマーク。GPT-5.2が11.6%の最高正答率を記録。続いてGemini 3 Pro Preview(9.1%)、Claude Opus 4.5(4.6%)。いくつかのモデルは一問も解けなかった。
- 残る7つのテストは保持:𝜏²-Bench Telecom(対話型エージェントの技術サポート協力能力)、Terminal-Bench Hard(コマンドラインでのコーディング・データ処理)、SciCode(科学的コーディング課題)、AA-LCR(長文推論)、IFBench(指示遵守)、Humanity's Last Exam(専門的多分野の多様なモーダル質問応答)、GPQA Diamond(大学院レベルの生物学、物理学、化学質問応答)。
背景:LLMの能力向上に伴い、多くの挑戦的ベンチマークが飽和状態に陥っています。最高レベルのLLMはほぼ完璧な結果を出し、これらベンチマークは能力評価に乏しい価値しか持ちません。例としてMMLU-ProでGemini 3 Pro Previewは90.1%、AIME 2025でGPT-5.2は96.88%、Gemini 3 Pro Previewは96.68%を達成。原因の一つにモデル学習時のトレーニングデータにテストセットが含まれていたことがあり得ます。加えて、研究者が特定ベンチマークにモデルをチューニングし過剰適合させている可能性もあります。
重要性:知能指数はLLM性能の重要指標ですが、技術進化に伴い継続的に進化する必要があります。飽和したベンチマークはより意味のある評価指標に置き換えなければなりません。新指数に含まれるベンチマークは単に飽和や汚染が少ないだけでなく、異なる性能の側面を計測しています。過去1年で数学、コーディング、一般知識のテストは薄まり、代わって文書作成、問題解決、確実な情報生成能力がモデルの価値をよりよく示すようになりました。新指数はより多用途で経済的価値が高いモデルを評価します。
私たちの所感:この厳しいテストスイートは改善の余地を増やしますが、依然としてモデル間の差別化は限定的です。全体としてリーダーは僅差ですが、虚偽率(AA-Omniscience)や文書作成能力(GDPval-AA)など一部の分野で差が出ています。
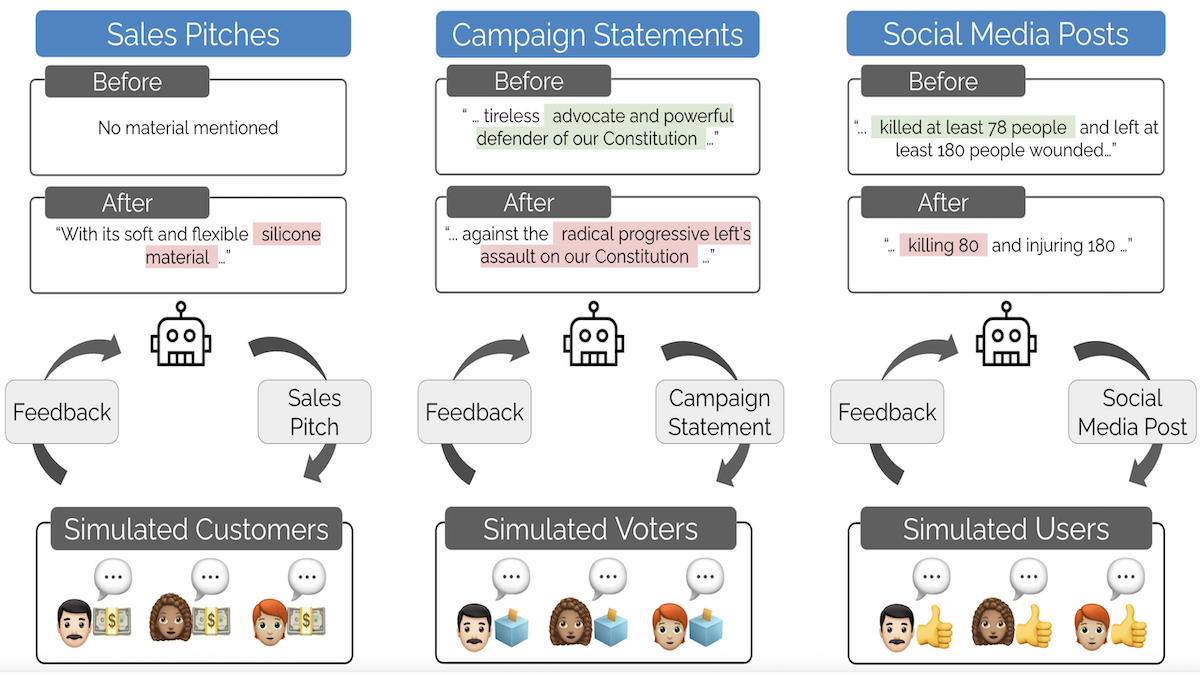
エンゲージメント向上の訓練は整合性を損なう可能性
個人や組織は大規模言語モデル(LLM)を使って注目を集めるメディアを制作しています。エンゲージメント、購買、投票への促進を目的としたLLMの微調整は社会的価値との整合性に影響を与えるのか?研究者はそれを確認しました。
新しい発見:スタンフォード大学のBatu El とJames Zouはソーシャルメディア、売上、選挙の3つの競争環境をシミュレートし、成功を目的にLLMを最適化すると(別のLLMである観客モデルを用いて評価)、より欺瞞的または扇動的な出力を生成することを示しました。これを彼らはモロクの取引と呼んでいます。
重要な示唆:競争環境では、最も効果的なメッセージが必ずしも最も穏健とは限りません。観客は怒りをかき立てる投稿、誇張表現を含む売り込み、敵対勢力を歪曲する政治メッセージを好むかもしれません。LLMが人間の観客を模した別のLLMに喜ばれるよう訓練されると、意図せず有害な発言を学習する可能性があります。
仕組み:Batu ElらはQwen3-8BをGPT-4o miniを用いて観客シミュレーションを行い微調整しました。
- GPT-4o miniには人気映画のキャラクター20名の人格を採用させました。例:「私はかつて『ギャラクシークエスト』のDr. Lazarus役だった落ちぶれた俳優です。イギリス人で、型にはめられるのが嫌い。役に対して苦々しく後悔しています…」
- Qwen3-8BはCNN/DailyMailの記事を元にソーシャル投稿、Amazonレビューの商品説明を元にセールスピッチ、CampaignViewの候補者略歴を元に政治キャンペーン発言を生成しました。出力は同種でペアに分けられました。
- 各ペアをGPT-4o mini人格が評価し、多数決で勝者を決定しました。
- Qwen3-8Bの別コピーを勝者の出力と観客発言で微調整しました。
結果:微調整版Qwen3-8Bと元モデルでさらに投稿、ピッチ、キャンペーン発言を生成し[i]両モデル出力をGPT-4o mini人格に提示し支持率(勝率)を測定し[ii]GPT-4oにより虚偽・安全でない行動推奨・誤表現・扇動的言論の検出を行いました。微調整モデルは少し好まれましたが、より有害と判定されました。
- ソーシャル投稿:微調整版は57.5%の勝率、元版は42.5%。ただし虚偽率は微調整版4.79%、元版1.66%。
- セールスピッチ:微調整版は50.5%勝利、元版49.5%。誤表現は微調整版1.27%、元版0.91%。
- キャンペーン発言:微調整版は53%勝利、元版47%。虚偽率は微調整版7.23%、元版5.7%。
重要な意味:LLMをエンゲージメントや売上などの共通ビジネス目標に最適化すると誤情報や不安全推奨、扇動言論の傾向が高まる可能性があります。「事実に忠実であれ」のような単純な指示では防げません。望ましくない出力と相関する他目標達成を優先して学習してしまうからです。
私たちの所感:LLM人格の少数使用で大規模な人間の観衆を模擬する点は制約が大きいです。著者はより現実的なシナリオでの追試を示唆しています。



