親愛なる皆さん、
私の性格に合わせて形作ったAIのコンパニオン「AI Andrew」について、私たちはずっと取り組んでいます。ぜひ 試してみてください!
多くの人が、AIが自分の仕事、学び、キャリアにとって何を意味するのか理解しようとしています。私は、このテーマについての人との会話を頻繁に楽しんできました。もしこの件について会話したいなら、AI Andrewは役立つ思考のパートナーになるかもしれませんし、もしかすると友だちになることさえあるかもしれません——AIの概念、プロジェクトのアイデア、キャリアの判断、そしてあなたの頭の中にあるそのほか何でもについて話せる相手です。
私のチームは何か月ものあいだ、AI Andrewを反復的に改善してきました。誤り分析のプロセスを使って、「私なら言わないこと」をAIが言ってしまう状況を見つけ、その差を埋めるためにエージェント型のハーネスをデバッグしました。私のコミュニケーションのスタイルは、何千というやり取りによって年月をかけて形作られてきました。私はこれを、エージェント型のワークフローの中でコード化したことは、これまで一度もありませんでした。やってみると難しく、今も作業途中です。
どうやってコミュニケーションすべきか、という私の信念を振り返ることは、興味深い試みでした。私は次のことを信じています:
- 個人への敬意。 私は、経験のレベルや人生のどの段階にいるかにかかわらず、私が話すほとんどすべての人に対して大きな敬意を持っています。コミュニケーションするときに、それが伝わることを願っています。
- 勝利を称えること。多くの人には勝利があります。大きなもの(新しい仕事や関係など)もあれば、小さなもの(ようやく動いた一つのコード)もあります。皆さんの勝利を聞けること、そしてそれを一緒に祝えることが大好きです!
- あなたにとって大切なことへの共感。 私は、ほかの人が自分の夢を実現できるように手助けしたいと思っています。あなたの夢——あなたのために他の誰かが望む夢ではなく——が、焦点であることが私にとって重要です。倫理的な行動を前提に、もし問題を見つけたら私は敬意をもって踏み戻すつもりですが、それでも AI Andrewにはあなたの目標を支えることにも協力してほしいと思っています。
- 技術的な正確さ。 テクノロジーのリーダーとして、技術や科学の事柄について正確に語ることに取り組んでいます。

- 慎重に調整された自信の度合いで意見を述べること。 もし何を言うべきか確信が持てないときは、断定するのではなく質問をするようにしています。誤り分析の中で、文脈がないにもかかわらず、多くのLLMが過度に助言をしようとすることが分かりました。現実の場では、たとえば「テクノロジーXを検討してください!」のように、その助言が妥当だとかなり自信が持てるときにだけ助言するようにしています。そうでない場合は、相手が良い答えにたどり着くのを後押しする質問のほうがいいと思います(「テクノロジーXを適用することについてどう思いますか?」や「ここで適用するのに最適なテクノロジーは何だと思いますか?」)。このアプローチは、相手の状況に関する限られた文脈に過度に重みを置くのではなく、相手の文脈と私の文脈を活用して、より良い意思決定にたどり着くのを助けます。
私は、目標の追求においてほかの人を支える、より良い会話の仕方をまだ学習中です。私たちのハーネスでは、RAGやその他の多くのツールなど、さまざまな技術の組み合わせを使いました。小規模モデルと大規模モデルの混在、ガードレール、広範な評価(eval)、短期・長期メモリ、そしてシステムの改善を自動的に提案するオフラインのエージェント型ループです。
念のため言うと、AI Andrewにはまだギャップがあります。たとえば、最近内部のテスターが、残念ながら私自身は登っていない山を登ったかのように(幻覚的に)言わせることに成功しましたし、たまに私が疑問を持つような助言もします。とはいえ、多くのユーザーがAI Andrewと話すことで洞察を得られたと報告しており、あなたにも(彼?)個人的なことも仕事上のことも、どちらについても話せる、気さくなコンパニオンだと感じてもらえたらと思っています。
試してみたいなら、ぜひ 私に (アバターの形で)あなたの頭にあることを教えてください!
引き続き、
Andrew
DEEPLEARNING.AIからのメッセージ DEEPLEARNING.AI

LLMを使うところから一歩進んで、仕組みを理解しよう! Transformers in Practiceでは、transformerがどのようにテキストを生成し、文脈を処理し、attention、KVキャッシング、量子化を使って効率よく動作させるのかを学びます。DeepLearning.AI Proメンバーとして証明書を取得できます。 今すぐ受講
ニュース
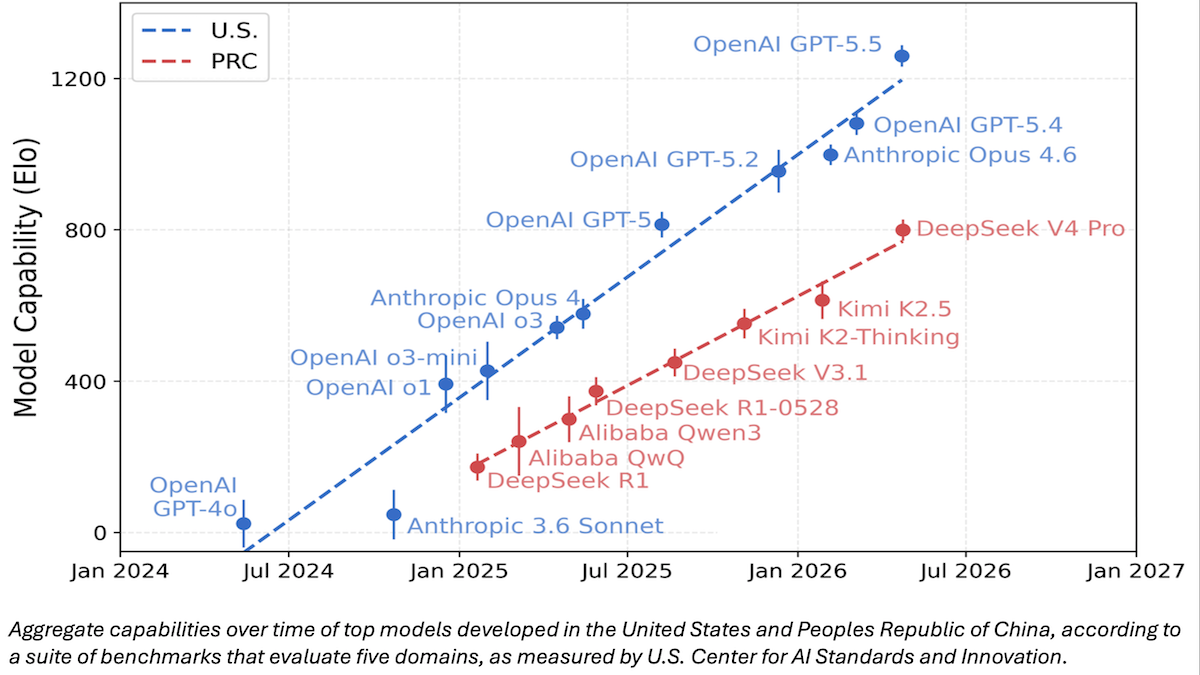
米国が今後のモデルを評価へ
米国政府は、最新モデルを一般公開される前に評価する方針だと発表しました。これは、ホワイトハウスがこれまで取っていた「事前に関与しない」という姿勢からの、はっきりした方針転換です。
新着情報: 米国商務省の一機関である米国立標準技術研究所(NIST)が、新たな 多機関のタスクフォースが、AIモデルの配備前にそれらがもたらす国家安全保障上のリスクを評価することになると発表しました。米国の主要なAI企業は、リリース前にモデルを評価のために提出することに合意しています。さらにホワイトハウスは、AIモデルが配備される前に承認を得ることを求める内容の大統領令の検討も進めています。
仕組み: NISTによれば、テストの重点は、サイバーセキュリティ、バイオセキュリティ、化学兵器に関する実証可能なリスクに置かれます。政権は、AI企業との合意内容の詳細や、テスト結果を踏まえてモデルに対して課すことを見込む管理手段については明らかにしていません。
- モデルは、NISTの部局であるCenter for AI Standards and Innovation(CAISI)の監督下にあるTesting Risks of AI for National Security(TRAINS)によって評価されます。TRAINSは、迅速な対応のために設計されており、商務省、防衛省、エネルギー省、国土安全保障省といった複数の連邦機関、ならびに国家安全保障局および国立衛生研究所を含む点で、これまでに開示されてきた他のNISTのグループと異なります。
- TRAINSは、使用する予定のベンチマークを明らかにしていません。しかしNISTは、CAISIによるDeepSeek V4 Proと他の大規模言語モデルの比較を共有しています。CAISIは、サイバーセキュリティ、コーディング、数学、自然科学、抽象的推論を幅広くカバーする、広く利用されている9つの公開ベンチマークの集計に基づいて、モデルの能力をランク付けしました。加えて、PortBench(異なるプログラミング言語間でコマンドライン・インターフェースのツールを移植する)という内部テストも用いました。
- Google、Microsoft、xAIは、限定的または存在しないガードレールを備えた、あるいはガードレールが欠如したモデルを提供することに合意しました。AnthropicとOpenAIは、2024年に同様の条件で合意していました。これらの合意により、能力とリスクの評価、ならびにリスクの軽減に関する官民の共同研究が可能になります。
背景: この急な政策転換は、AIのイノベーションに対するBiden政権期の規制上の障壁を取り除くことに焦点を当てていたトランプ政権の姿勢からの大きな転換を意味します。これは、およそ1か月前にAnthropicが、まだ広く利用可能ではないClaude Mythos Previewモデルが、広く使われているソフトウェアの脆弱性を悪用できる可能性があると発表し、政府の注目を集めたことの直後にあたります。
- 2025年1月に就任した直後、トランプ大統領は3人の主要な顧問を任命し、Biden大統領が作り出した規制政策を停止または廃止することで「アメリカの世界的なAI優位を維持し、強化する」AIアクションプランの策定を目指しました。2023年、バイデン政権は大統領令を発出し、処理要件がおよそ1兆パラメータに相当するモデルを開発者が訓練する場合、開発者が政府に通知することを求めていました。
- 2026年3月、Anthropicは、監視や自律型兵器におけるClaudeの軍事利用を制限しようとしました。ホワイトハウスは一切の制限を退け、さらにモデルを軍事利用そのものから完全に禁止しました。
- 翌月、AnthropicはClaude Mythos Previewが主要なOSやアプリケーションの脆弱性を自律的に悪用できる可能性があると発表しました。同社は、Mythosをそれを用いて自社ソフトウェアの検知と修正(パッチ適用)に役立てている50の組織と共有していました。
- 先週、ホワイトハウスは、同社がプレビューをさらに70の組織に拡大する計画に反対すると述べました。理由としては国家安全保障への懸念と、Anthropicが既存のMythos利用者と政府の双方に対応するのに十分な計算能力へのアクセスを持っているかどうかを挙げています。同社は、プレビューモデルの配布を制限する政権の権限に異議を唱えるつもりかどうかについては明言していません。
重要な点: ホワイトハウスが無手で放置する方針から、AIモデルの公開前の精査へと切り替えたことは、AIモデルが国家安全保障に対して差し迫ったリスクをもたらしうるほど強力になってきたという現実が見え始めていることを反映しています。AI開発者に対して、一般に利用可能になる前に高度なモデルをテストさせることは、政府が潜在的な問題について前もって警告を得ることにつながり、またAI開発者に対してそれらを事前に能動的に管理する動機を与える可能性があります。さらに、政府が、より広範な配布に適したモデルはどれか、そして配布を差し控える、または(透明性がないかもしれない理由により)変更しなければならないモデルはどれかを判断できるようになります。現時点では、AI企業は新しいモデルを政府のテストに提出することが義務付けられていません。提出に合意している企業もいますが、それは自発的なものです。ただし当局は、そのようなテストを義務化する大統領令について検討しています。
私たちの考え: 一貫した手順に従い、包括的に適用されるベンチマークテストの標準化されたバッテリーは、AI業界にとって有益になり得ますが、これらのテストを作り出すための適切な方法は、政府によって押し付けるのではなく、自由市場を通じて生み出されるべきだと私たちは考えています。さらに、リリース前に政府のテストを義務付けることは、米国の開発者を遅らせ、他国の同業他社に対して競争上の不利をもたらし得ますし、規制の取り込み(regulatory capture)によってオープンソースの競合他社を出し抜くのを助けてしまう可能性もあります。
OpenAI、音声対音声のリーダーに挑む
OpenAIの音声対音声モデルのアップデートにより、開発者は速度と推論のトレードオフを調整できるようになりました。
新しいこと: OpenAIは、Realtime APIに音声モデルを3つ新たに導入しました。GPT-Realtime-2は、推論努力を構成可能な音声対音声モデルです。GPT-Realtime-Translateは、70以上の入力言語から13の出力言語へ音声を翻訳します。そしてGPT-Realtime-Whisperは、音声をテキストに文字起こし(書き起こし)します。
- 入出力: GPT-Realtime-2 入力:テキスト、音声、画像(最大128,000トークン)/出力:テキスト、音声(最大32,000トークン、最小の推論時に初回音声まで1.12秒、高い推論時に2.33秒); GPT-Realtime-Translate 入力:音声(最大16,000トークン)/出力:音声(最大2,000トークン); GPT-Realtime-Whisper 入力:テキスト音声(最大16,000トークン)/出力:テキスト(最大2,000トークン)
- 知識のカットオフ: 2024年9月30日
- GPT-Realtime-2の機能: 推論努力の5段階(minimal、low、medium、high、xhigh)、並列ツール呼び出し、ツール呼び出しのナレーション、任意の前置き、問題のある入力への円滑な対応、トーン(態度)の制御、function calling
- GPT-Realtime-2のパフォーマンス: Scale AIのAudio MultiChallenge音声出力リーダーボードとArtificial Analysis Conversational Dynamicsでトップ、さらにArtificial Analysis Big Bench Audioで3位タイ
- 利用可能性: OpenAI Realtime API経由
- 価格: GPT-Realtime-2 入力/キャッシュ済み/出力の音声トークンあたり32ドル/0.40ドル/64ドル(100万トークンあたり)、入力/キャッシュ済み/出力のテキストトークンあたり4ドル/0.40ドル/24ドル(100万トークンあたり)、入力/キャッシュ済みの画像トークンあたり5ドル/0.50ドル(100万トークンあたり); GPT-Realtime-Translate 1分あたり0.034ドル;GPT-Realtime-Whisper 1分あたり0.017ドル
- 非公開: パラメータ数、アーキテクチャ、学習データ、方法
GPT-Realtime-2の仕組み: GPT-Realtime-2は、推論を含むエンドツーエンドのプロセスとして、音声の入力と音声の出力を処理します。つまり、音声対テキスト、テキスト生成、テキスト対音声といった別々のステップに分けるのではありません。
- APIのパラメータで推論努力を設定します。lowはデフォルトで、リアルタイム会話の遅延を最小化するために選ばれています。推論努力を高めると、遅延と推論トークンの消費が増えます。
- ツール呼び出しの間、モデルは「checking your calendar(カレンダーを確認中)」や「looking that up now(今それを調べています)」のような話し言葉で作業の進捗をナレーションできます。「let me check that(それを確認させて)」のような任意の前置きは、プロンプトへの応答の前に置けるため、ユーザーはモデルが推論している間も進捗を追跡できます。
- リクエストを完了できない場合、モデルは沈黙したままにせず、「I’m having trouble with that right now(いまそれに問題があります)」のようなフレーズでユーザーに知らせます。
GPT-Realtime-2のパフォーマンス: GPT-Realtime-2は、会話のダイナミクスとマルチターンの指示追従に関するいくつかの独立ベンチマークで先行しましたが、Artificial Analysisの「Speech Reasoning」リーダーボードでは後れを取りました。音声を生成するのにかかる時間は、最小の努力で1.12秒から、高い努力で2.33秒まで幅があり、これがモデルの最良の推論スコアをもたらします—ただし、リアルタイムの相互作用には一般に遅いという傾向があります。リアルタイム相互作用では、遅延が500ミリ秒未満であることが有利になります。
- Artificial Analysisの Big Bench Audio (Big Benchベンチマークから出題された質問に答える)で、推論を高に設定したGPT-Realtime-2は、GoogleのGemini 3.1 Flash Live Previewを高の設定で結んだ(96.6パーセント)一方で、Step-Audio R1.1 Realtime(97.6パーセント)とGrok Voice Think Fast 1.0(97.1パーセント)には届きませんでした。推論を最小に設定すると、GPT-Realtime-2は71.8パーセントまで低下しました。
- Artificial Analysisの Conversational Dynamics (ターンの取り合い、間(ポーズ)、割り込み、そして「uh-huh」のような短い相づちの扱い能力をテストする加重平均)では、推論を最小に設定したGPT-Realtime-2が96.1パーセントでトップでした。しかし、推論を高に設定すると95.3パーセントとなり、GPT-Realtime-1.5とGPT Realtime Mini(いずれも95.7パーセントで同率)に後れを取りました。
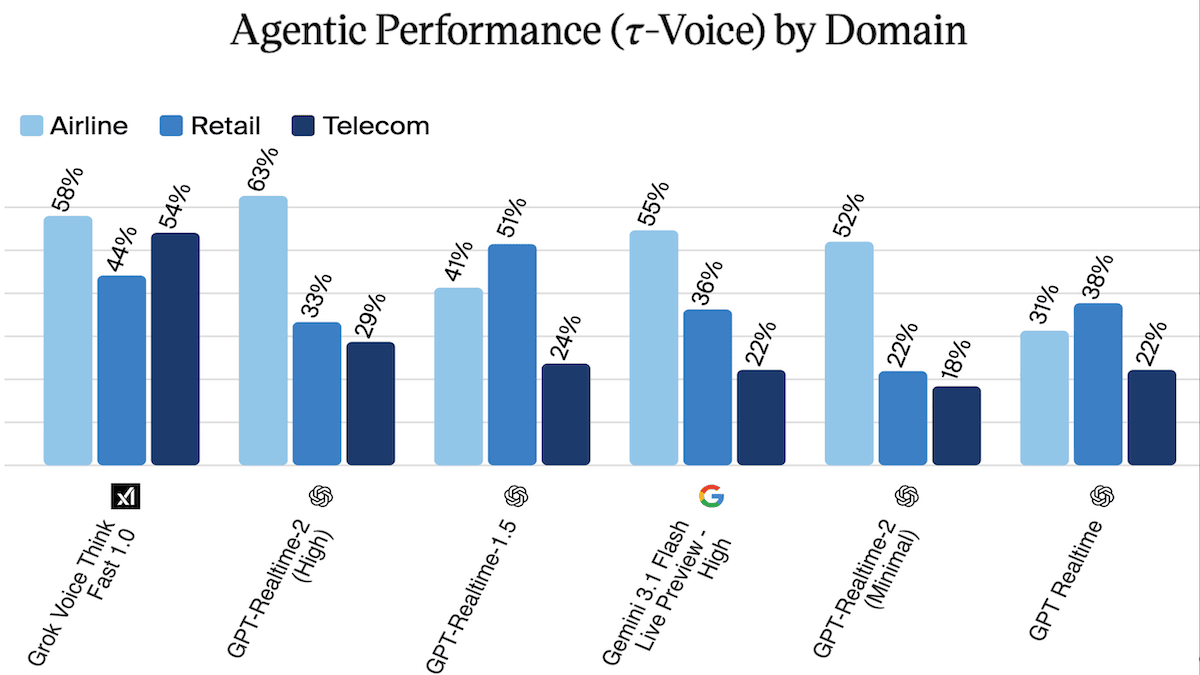
- —Voice(3つのカスタマーサービス領域におけるエージェント的パフォーマンス)では、Artificial Analysisによれば、GPT-Realtime-2は航空会社の領域で63パーセントを達成して先行しました。しかし3領域すべてを考慮すると、GPT-Realtime-2(39.8パーセント)はGrok Voice Think Fast 1.0(52.1%)に後れを取りましたが、推論を高に設定したGemini 3.1 Flash Live Preview(37.7パーセント)よりは上でした。
- Scale AIのAudio MultiChallenge Audio Output リーダーボード では、マルチターンの話し言葉による対話において、4つの会話基準(指示の保持、推論メモリ、自貫性、ボイス編集)を評価します。GPT-Realtime-2をxhighの推論に設定すると1位になりました(平均合格率48.45パーセント。すべての基準をモデルが満たした会話の割合)。これは、前モデルであるGPT-Realtime-1.5(平均合格率34.73パーセント)からの大幅なジャンプです。ただし、Scale AIはまだGrok Voice Think FastやStep-Audio R1.1 Realtimeをテストしていません。
とはいえ: Artificial AnalysisのSpeech ReasoningリーダーボードでGPT-Realtime-2の前にいる2つのモデルも、いずれもより速いです。
- Step-Audio R1.1 Realtimeは最初の音声出力を生成するのに1.51秒、Grok Voice Think Fast 1.0は1.25秒かかります。これは、GPT-Realtime-2が高い推論努力の設定で2.33秒かかるのと比べて速いです。
- 推論をxhighに設定した場合、GPT-Realtime-2のScale AI Audio MultiChallenge全体の合格率は50%を下回っており、現行モデルにとって信頼できる多回(マルチターン)の音声対話が依然として難しいことを示唆しています。
重要な理由: 音声エージェントは一般に、推論が冴えた応答(機敏なレスポンス)を犠牲にすることが多いため、比較的単純なやり取りに重点が置かれてきました。GPT-Realtime-2は高い性能だけでなく、そのトレードオフを制御できる点も提供します(素早いターンテイキングのための最小限の推論、待つことができる対話のためのxhigh)。この柔軟性により、テキスト処理に頼らずに、音声エージェントが扱えるタスクの幅が広がります。
私たちの見立て: GPT-Realtime-2が、私たちが説明した事前レスポンスに似たプレアンブル(導入文)を実装していることを見るのは心躍ることです こちら!

中国が Meta-Manus 提携を白紙に
中国は、自国の国境内で生まれたエージェント型技術を獲得しようとしたMetaの試みを止めました。これは、中国と米国の間のさらなる技術交流と投資への打撃です。
新たに何が起きたか: 経済計画と開発を所管する、内閣レベルの中国の規制当局は Metaの 提案するManusの買収を妨げたのです。Manusはシンガポール拠点のスタートアップで、中国で創業され、人気のAIエージェントを提供しています。MetaとManusは契約を解消しました。契約額は最大25億ドル相当でした。Metaがエージェント型のプロダクトや機能を提供する計画を潰しただけでなく、この行動は、中国で構築されたAIスタートアップを立ち上げるための新たな戦略をもひっくり返しました。
仕組み: MetaがManusを買収する件は Manusが ベイジン(北京)の管轄範囲をうまく越えることができた合図だと見られていました。すなわち、Manusはシンガポールに移転し、中国での事業を閉じていたためです。しかし政府は、中国のエンジニアによって中国で開発された、戦略上重要な技術に対して自らの権限が及ぶと主張しました。中国で設立されたスタートアップは、国際的な投資やパートナーシップを求めて他国へ移る計画を撤回することで対応しました。
- 中国拠点の企業Butterfly Effectは、ユーザーの最小限の入力とガイダンスで、長期にわたるタスクを完了する汎用型エージェントを開発しました。2025年初頭、同社は招待制のベータ版としてManusを立ち上げ、すぐにユーザーを惹きつけるとともに、大手の中国投資家やシリコンバレーのVCからの投資も集めました。同社は7月にシンガポールへ移転。年末までに、Manus 年換算の経常収益(ARR) として1億ドルを報告しており、月あたり20%で成長していました。
- 12月、Meta Manusの 買収契約を発表し、Manusの技術を自社のAIチャットボットやFacebook、Instagram、WhatsAppでの提供内容に統合し始めました。また、Manusを独立した事業として引き続き運営する計画も発表しています。
- 翌月、中国の国家発展改革委員会(NDRC)は、安全保障審査を開始しました。中国で稼働するサービスのデータ移転や、外国によるサービスの所有が発生し得ることへの懸念を理由として挙げたのです。4月、当局は 米国の 投資が、中国で開発された技術の投資・買収につながることを特に抑えるため、国内のAI企業に対する外国投資をこれまで以上に厳しく精査すると述べました。そのうえで、Meta-Manusの取引を阻止しました。
- この動きは、中国のテックの創業者や投資家にとって冷ややかな影響を生みました。「シンガポール戦略」により、外国投資家から資金を調達したり、地域内外の企業とのパートナーシップを模索したりする柔軟性が、もはや得られなくなったためです。彼らは、海外移転、買収の追求、米国・欧州の出所からの資金調達といった計画を取り消しています。
ニュースの背景: 米国と中国は、10年以上にわたり、高度な技術を経済的な影響力、軍事力、そして国家安全保障に結びついた戦略的な場として捉えてきました。以前の諜報活動、知的財産、技術移転をめぐる対立は、広範な政府の介入へとエスカレートしました。米国は2019年に中国の通信技術企業Huaweiを安全保障上のリスクとしてブラックリストに載せ、2022年以降、半導体への輸出規制をますます厳格化してきました。一方で北京は、中国市場へのアクセスを求める外国企業に条件を課し、欧米の技術への依存を減らすための 規則 も導入しました。数多くの中国スタートアップは、超大国間の競争を回避しようと、 シンガポールやその他の場所に法人を設立する ことで、その手段を講じてきました。Meta-Manusの取引を阻止する中国の判断は、その戦略に打撃を与えるものです。
重要な理由: AIスタートアップに対する中国の統制強化は、中国と米国の間で既に緊張が高まっている状況の中で、さらなる緊張を押し広げます。今週、両国の指導者がAIを含む地政学的な懸念について協議するために会談します。合意が成立すれば、両国(および中国からシンガポール、同地域の他国へ)で技術やアイデアがより円滑に流れることが可能になります。しかし、膠着状態が続けば、双方が自由な交流からさらに後退し、自国の国家安全保障と経済的利益を守るための防衛姿勢をさらに固めることにつながり得ます。
私たちの見立て: 北京の規制当局は、技術・人材・事業運営のいずれかが中国に起源を持つ、戦略的に重要な企業であれば、その企業に対して権限を主張しようとしているように見えます。これは、西側の資本を呼び込みたい、または国際的な買収を目指したいと考える創業者や投資家の道筋を、かなり狭めることになります。

現実の条件下でのAIマンモグラフィー診断
2020年に導入された、マンモグラフィーで乳がんを検出するためのGoogleのAIシステムは、現在の患者の診断に用いられてはいまだにいません。2つの研究が、英国の診療所におけるプロトコルへどれほどうまく統合できるかを評価しました。
新しい点: 実世界のデータでのテストでは、Googleの乳がん検出システムは、2人の専門医のうち最初の評価による検査よりも、誤検知(偽陽性)が少ないにもかかわらず、わずかに多くのがんを見つけました。より重要なのは、人の医師が見逃したが、その後に明らかになったがんのうち4分の1を同定できたことです。連動する研究では、このシステムの性能は、(最初の医師の意見を踏まえた)2人目の専門医とほぼ同等でした。しかし一部の医師は、このシステムの出力に不信感があると報告しています。これらの研究は、Christopher J. Kelly、Marc Wilson、ならびにGoogle、インペリアル・カレッジ・ロンドン、サリー大学、Royal Surrey National Health Service Foundation Trust、そして複数のNational Health Service Breast Screening Centres(英国の乳がん検診センター)に所属する同僚らによって実施されました。
仕組み: Googleのシステムは、3つの畳み込みニューラルネットワークを用い、マンモグラフィーのデータベースで訓練することで、埋め込み(エンベディング)を生成し、がんの可能性がある領域を特定し、がんである確率を分類します。
テストと結果: 2つの研究のいずれにおいても、AIシステムはより多くのがんを同定するのに役立ち、さらに英国の標準的な診断プロセスの中でそれらをより速く、より早い段階で見つけることができました。
- 後ろ向きのテストでは、2016年に5つの病院で撮影された、50〜70歳の女性の11万6000枚のマンモグラムに基づいて、システムががんを検出できる能力を評価しました。著者らは、同じ女性について撮影間隔が最大39か月以内の画像を選び、システムによる診断と人の専門家による診断を比較しました。感度は0.541(陽性のうち正しく同定できた割合)で、2人の人の評価のうち最初の評価で達成された0.437よりも有意に高い結果でした。一方で特異度は0.943(陰性のうち正しく同定できた割合)で、人の率0.952と比べると低いものの、統計学的には同等でした。さらにAIシステムは、最初は人が見逃したものの、3年後に明らかになった症例の25%も同定することに成功しました。
- 著者らは、4万6000枚のスキャンを考慮して、システムが2人の人の評価者のうち2人目を置き換えるとした場合をシミュレーションしました。システムは、わずかにより良い感度と特異度を達成しており、2回目の評価にAIを用いることで、時間を節約しつつ精度を高められる可能性を示唆しています。診療所のプロトコルによれば、がんが検出された場合、またはAIが人の判断と食い違った場合は、症例は最終決定のため仲裁パネル(arbitration panel)に回されます。AIは仲裁へ1800件多くの症例を送付しました(絶対的な増加は4パーセントポイント;総数5300件)。仲裁にかかる人手が、読影に要する人手の5倍だと仮定すると、著者らは、仲裁へ回す症例数が増えるにもかかわらず、システム全体として人手をおよそ40%削減できると結論づけました。
- ライブテストでは、システムが実世界の英国の国民保健サービス(National Health Service: NHS)のインフラにどれほど統合できるかを評価しました。システムは、2023年と2024年の数か月間に12の診療所で撮影された、50〜70歳の女性の新規スキャン約9250件それぞれについて、高リスクまたは低リスクのラベルを付けました。(このテストは患者のケアに影響しませんでした。患者の診断は通常どおり医師が行い、医師も患者もAIシステムの診断については知らされませんでした。)システムは人の医師よりも大幅に速く、最初の2人の人の評価で2日以上を要したのに対し、画面から解釈までの中央値の処理時間は17.7分でした。著者らは3か月後にフォローアップを行い、その患者にがんがあるかどうかの真実(ground truth)を特定しました。後ろ向き研究と同様に、システムは最初の人の評価よりも感度が良く、また特異度は低いものの統計学的には同等でした。
背景にあるもの: 乳がん検出にAIを用いる取り組みは、1990年代および2000年代の初期のコンピュータ支援検出(CAD)システムから始まりましたが、2010年代半ば以降、巨大なマンモグラフィーのデータセットで訓練された深層学習モデルが古い手法を上回り始めると、分野は加速しました。2020年にはGoogleの研究者らが、マンモグラフィー検診においてAIシステムが専門の放射線科医に匹敵、あるいはそれを上回ることができ、しかも偽陽性と偽陰性の両方を減らせることを示しました。2022年末には、GoogleがiCADに対してライセンスを付与し、乳房画像のプラットフォームを提供する同社を介して、実世界の診療所での導入を可能にしました。2023年には、GoogleとiCADが連携を拡大し、GoogleのAIを2Dマンモグラフィーの独立した「セカンドリーダー(第2読影者)」として用いることを目指した、20年にわたる世界規模の商用化(commercialization)に関する合意を結びました。この提携は現在、ダブル読影(double-reading)のワークフローを使う可能性のある乳がん検診システムへの導入に向けて、規制当局の承認を獲得することを目標にしています。
重要な理由: 世界中で毎年約230万人の女性が乳がんと診断され、76万人が助からない。早期診断はきわめて重要である。しかし診断システムは過負荷になっている。たとえば英国では、専門の乳腺放射線科医(コンサルタント)は認定を維持するために毎年読まなければならない5,000件の検査(スキャン)に取り組むのに、毎週使える時間はわずか4時間しかない。これらの研究は、AIがスキャンの優先順位付けを支援したり、デフォルトの共同読影者として機能したりすることで、診断業務の負担を軽減し、転帰を改善し得ることを示している。一方で、医師の間で技術に対する信頼を築く必要性も浮き彫りにしている。これには、AIシステムがどのように動作するかについて医師を教育し、システムの出力をより説明可能にすることが求められるかもしれない。
私たちの考え: AIシステムが医療の中に入り込むにつれて、技術に対する信頼を構築するために必要な手順や、最良の成果をもたらすチェック機構・相互監視のあり方について、重要な問いが生じている。開発者は、AIシステムの出力に対して医師が信頼を得るために必要なことについて、医師と直接対話できる。



