
「記事の質を上げろ」は最悪のアドバイス。なぜあなたのnoteは読まれないのか?AI全盛期に「読まれる記事」の正体。不気味の谷と予測誤差の科学とは? #生成AI #ChatGPT #Gemini #Claude #AI活用 #マーケティング #ライティング #毎日更新 #コンテンツビジネス #アルゴリズム

こんにちは、ポス鳥です。
窓を少し開けたら、湿った土のにおいが入ってきました。
ベランダの鉢植えが、知らない間に小さな芽を出しています。
こういうのは不思議なもので、水をやった日ではなく、忘れていた日に伸びている。
最近も多くの方々に記事を見ていただいており、DMの数も増えています。
そんな中、1通のDMをもらっています。
📨 【読者からの質問】
ポス鳥さん、質問です。
最近noteを始めたんですが、どの記事を見ても「とにかく量じゃなく、記事の質を上げろ」と書かれています。
でも正直、何をどうしたら「質が上がった」ことになるのか分かりません。
文章を整えればいいんですか? もっと調べればいいんですか?
「質を上げろ」って、具体的に何をすればいいんでしょうか。
ポス鳥さんは、記事の質って何を指していると思いますか?
良い質問です。実はこの質問の答えは、私自身がずっと考え続けてきたことだからです。
12年、貿易商というビジネスをやりつづけて、創業当初からSNSやブログ。
もちろんnoteでもそうです。
情報発信をやりつづけた結論から申し上げましょう。
「記事の質を上げろ」というアドバイスには、中身がありません 。
その辺のドブにでも捨てておいてください。
いえ、正確に言い直します。
「質を上げろ」は、 答えを持たない人が、答えを持っているフリをするために使う便利な言葉 だと思っています。
「記事の質」とは何か。
この問いに理論的に、なおかつそれを真正面から実行して、試行錯誤して、自分なりの答えを正面から答えられる人を、
私は12年の間ほとんど見たことがない。
なのに、答えられないものを「上げろ」と指示している 。
冷静に考えると、これ相当おかしいですよ。
今日は、この「質」の正体を、脳科学から自然界から美術史まで、いろいろな角度から解剖してみます。
あなたの 「質を上げなきゃ」という思い込み が、ひっくり返るかもしれません。
🔥 第1章 ラーメン屋の頑固親父は「質」を語れるか──全員が違う「正解」を持っている
湯気が立ち上る光景を、想像してみてください。
スープの香りが、のれんの隙間から通りに漏れている。
脂のにおい。
醤油が焦げる、あの 鼻の奥をつく感じ 。
ある頑固親父がラーメン屋を開いています。
「俺のラーメンは質(味)重視だ」と胸を張っている。
でもラーメンの世界には、こってり派がいます。
あっさり派がいます。
他にも醤油系がいて、豚骨系がいて、煮干し系がいて、つけ麺派もいる。
こってり派は「こってりこそ至高」と言い、あっさり派は「邪道だ」と返す。
ある派閥は「のりが足りない」と言い、別の派閥は「野菜が少ない」と首を振る。
全員が違う「質」を持っている 。
ここからです。
親父がどれだけ自分の味に自信を持っていても、
客が来なければ店は潰れます 。
「質が高い」「技術が高い」と自称しながら閉店した飲食店や工場は、日本中に山ほどある。
あなたの近所にもあったでしょう。
味は悪くないのに、いつの間にか シャッターが下りていた店 。
あるいは、正直「そこまでおいしくないよな」と思っていたのに、 いつも行列ができている店 。
ところが。
これはラーメンといった飲食店の話だけではありません。
情報発信の世界でも、まったく同じことが起きています 。
「量より質だよ」──この言葉、noteでも、Xでも、本でも、セミナーでも、あなたも一度は聞いたことがあるはずです。
「質の高い記事を書け」「質を意識しろ」と。
じゃあ聞きますが、
その「質」って、具体的に何ですか ?
今すぐに私に教えてください。
文字数が多いこと?
データが豊富なこと?
文章が美しいこと?
構成がロジカルなこと?
こってり派とあっさり派が永遠にかみ合わないのと同じで、 「質」の定義は人によって完全にバラバラ なのです。
ある読者は「データが多い記事が質が高い」と思っている。
別の読者は 「感情を揺さぶる記事が質が高い」 と感じている。
また別の読者は「短くて要点だけまとめてくれる記事が一番ありがたい」と思っている。
全員が違う「質」を求めている 。
なのに発信者は「質を上げよう」と、
ひとつの正解があるかのように努力する。
これを今日は持ち帰って、心に刻み込んでください。
「質が1つなわけがないだろ。」
という考えです。
これ、あなたの職場に置き換えてみてください。
上司が「もっといい仕事をしろ」とだけ言って、何が「いい仕事」なのか一切説明しない。
……どうですか。困りますよね。
何をすればいいか分からないまま、がむしゃらに残業する。
それで評価されるかどうかは、 上司の気分次第 。
「質を上げろ」は、これと同じ構造です。
定義がないまま「上げろ」と言っている 。
あなたの財布に翻訳するとこうです。
「何を買えばいいか分からないのに、"もっといい買い物をしろ"と言われている状態」
そんなの、 お金も時間も無駄にするに決まっています 。
ただの雑談程度なら良いのですが、どの分野でもアドバイスで「質を上げろ」という言葉だけを「本気で言っている」のだとしたら、不親切極まりないのです。
✅ 第1章の小まとめ
🍜 「質」の定義は受け手によって完全にバラバラ ──豚骨派とあっさり派が永遠にかみ合わないのと同じ構造
🏪 「質が高い」と自称しながら潰れた店は山ほどある ──自己評価と市場評価はまったくの別物
💼 「質を上げろ」は定義なきアドバイス ──「もっといい仕事をしろ」と言いながら基準を示さない上司と同じ
🔍 最大の問いは「質とは何か」を言語化すること ──答えを持たない人が答えを持っているフリをする便利な言葉に騙されない
🌸 第2章 花は自分を美しいと思っていない──自然界が証明する「質」の正体
少しコーヒーのおかわりを淹れてきます。
豆を挽く音が、カリカリと部屋に響く。
こういう音は不思議なもので、静かな朝に聞くと、 頭の中まで整理される 気がします。
ラーメンの話だけだと「それは飲食業の話でしょ」と思った方もいるでしょう。
じゃあ、もっと根本的な話をします。
自然界の話 です。
花が美しいのは、花が「美しくなろう」と努力したからではありません。
虫が寄ってきた色や形が、生き残っただけ です。
かのダーウィンの進化論で、有名なチャールズ・ダーウィンが『種の起源』で示した自然選択。
赤い花が残ったのは、赤が「質が高い」からではなく、 その地域の虫が赤に反応したから 。
別の地域では青が生き残る。
白が生き残る場所もある。
花と虫の関係を、もう少し踏み込みます。
あなたの通勤路に咲いている花を思い浮かべてください。
あの花は、「私はきれいでしょう」と自己アピールしているわけではない。
虫が「おっ、あの色、気になるな」と反応した結果、 その色の花が世代を超えて残っているだけ です。
……お分かりでしょうか。よく考えてみてください。
「質」は花の側には存在しません 。
虫の側── 受け手の側にしか存在しない 。
花が「俺は赤が最高だ」と主張しても、虫が来なければ受粉できず、 枯れて終わる 。
何万年もの時間をかけて、自然はこの原理を証明してきました。
あなたの台所に直すとこうなります。
あなたがどれだけ手間をかけて料理を作っても、食べる人が「おいしい」と思わなければ、それは「質が高い料理」とは呼ばれません。
塩加減が絶妙でも、辛いものが苦手な人に出したら「しょっぱい」と言われる 。
盛り付けが美しくても、空腹の人は「早く食べたいのに」と思っている。
ラーメンも、花も、記事も、 全部同じ原理で動いています 。
「質が高い」は、発信者が名乗るものではありません。
受け手が、結果的にそう判断するものです 。
しかし。
「じゃあ発信者には何もできないのか」と思いますよね。
全部が受け手次第なら、 努力は無意味なのか 。
その疑問に答えるのが、次の章です。
ここから先に、発信者が唯一コントロールできる 「2割」 の話があります。
✅ 第2章の小まとめ
🌺 花の美しさは花自身が決めたものではない ──虫が反応した色と形が生き残っただけ
🐝 「質」は受け手の側にしか存在しない ──発信者が名乗るものではなく、受け手が結果的にそう判断するもの
🍳 料理の「おいしさ」と同じ構造 ──どんなに手間をかけても、食べる人の舌に合わなければ「質が高い」とは呼ばれない
❓ では発信者にできることはゼロなのか ──次章で「唯一の突破口」を語る
⚡ 第3章 脳の予測誤差という唯一の突破口──「おっ」の正体を科学する
ベランダのほうから、春の陽射しが部屋に差し込んできました。
床に落ちた光の四角が、ゆっくりと移動していく。
指先を光の中に入れると、 ほんのり温かい 。
この「予想外の温もり」に、手が勝手に反応する。
これから話すことの、そのものです。
ここまで読んで「じゃあ全部運ゲーじゃないか」と思った方もいるでしょう。
正直に言えば、 8割はそうだ と私は思っています。
でも残り2割、発信者が操作できる部分があります。
それが 予測誤差 という脳の仕組みです。
(※予測誤差(Prediction Error)とは、平たく言えば「予想と現実のズレ」のこと。脳科学者ウォルフラム・シュルツらが1990年代から実証してきた、メカニズムです)
人間の脳は、常に 「次に何が来るか」を予測しています 。
文章を読んでいるときも、無意識に「次はこういう話だろうな」と先読みしながら読んでいる。
で、予測通りだと脳は簡単に反応しません。
「知ってた」で終わる 。
ところが。
予測と違ったとき、 脳はドーパミンを放出します 。
「おっ」となる。
これが 「面白い」「刺さった」「なるほど」の正体 の1つです。
あなたの通勤電車で考えてみてください。
毎日同じルートで、同じ時間に、同じ車両に乗る。
景色も音もすべて予測通り。
脳はほとんど反応していません 。
でも、ある日突然、ドアが開かなかった。
その瞬間、あなたの脳は一気に覚醒する。
「え? 何?」と。
あの「え?」の瞬間にドーパミンが出ている。
あの感覚を、文章の中で意図的に起こすことが、発信者が唯一コントロールできる 「質」のパーツ です。
記事において、それは 読者の予測をどこで、どうズラすか という設計になります。
同じテーマを扱っても、他の発信者と同じ角度で書けば予測通り。
脳は反応しない。
でも「そういう見方があったのか」と思わせる切り口を入れた瞬間、 予測誤差が発生して、ドーパミンが出る 。
たとえば、この記事自体がそうです。
「質を上げろ」というテーマを扱うとき、あなたは 「文章術のコツが来るだろうな」と予測していたかもしれません。
ところが花と虫の話が始まった。
「え?」と思うかもしれません。
あの瞬間に、あなたの脳は 予測誤差を検知して、ドーパミンを出している 。
私の記事の構成は「圧倒的なズラシ」です。
脳科学、マーケティング、生物学、心理学に、哲学や歴史など、一気に路線を変えて予想できなくするスタンス。
そしてそれを1本の道につなげる。これが私にとっての質です。
「これと同じことを、あなたがしろ。」と言っても難しいでしょうが、「読者の予想を外す」というワードは覚えて損はないはずです。
そして、この「外し方」には型がいくつかあります。
少しだけ紹介させてください。
比較的、この手法は上級者向けだと私は思っています。
全員が使える手法では無いのですが、せっかくですから知識だけは持ち帰ってくださいね。
⚡ 予測を外す「ズラし」──5つの型
1つ目は、 スケールのズラし 。
読者が「個人の話」を予測しているところに、いきなり国家レベルの話を持ってくる。
逆もまた然り。
たとえば「noteのPVが伸びない」という悩みに対して、突然アメリカの大統領選の広告戦略の話を始める。
読者の脳は一瞬揺さぶられます。
「え、なんでそこ?」と。
そこから「実は選挙広告も情報発信も、ターゲットの絞り込みという点ではまったく同じ構造です」と繋げる。
マクロとミクロのギャップが、予測誤差を生む 。
逆パターンもあります。
世界経済の話をしている最中に、急に「あなたの冷蔵庫の中身」に着地させる。
私の記事などで「○○に直すとこうです」とやっているのが、まさにこれです。
2つ目は、 時間軸のズラし 。
読者が「今」の話を予測しているところに、500年前の話や100年後の話を差し込む。
「AIライティングの未来」を語っている最中に、突然ギリシャ神話の話を始める。
あるいは江戸時代の瓦版の話を持ち出す。
読者は「え、なんで紀元前?」と思う。
あの瞬間に予測誤差が発生している。
そこから「あの時代も"誰に届けるか"を考えた人だけが生き残った」と繋げると、読者の脳は 古い話と今の話が1本の線で繋がる快感 を得ます。
未来方向のズラしもある。
「2050年、あなたの孫がnoteを読んだとき」と始めると、読者は一瞬「え?」となる。
その「え?」がドーパミンのトリガーです。
これも私の得意分野の1つですね。
3つ目は、 分野のズラし 。
読者が「同じジャンル内の話」を予測しているところに、まったく別の分野の事例を持ってくる。
これが 私の記事で一番多用しているパターン です。
情報発信の話をしているのに、突然「花と虫の進化の話」が始まる。
「ラーメン屋の親父」が出てくる。
読者の脳は「ライティングの話を読んでいたはずなのに、なぜ生物学?」と混乱する。
その混乱が、ドーパミンのトリガーになる 。
コツは、「異分野の事例」と「本題」の構造が同じであること。
構造が同じだから「なるほど、そういうことか」という着地が成立する。
構造が違うと、ただの脱線で終わります 。
4つ目は、 立場のズラし 。
読者が「賛成意見」を予測しているところに、あえて反対側の視点を差し込む。
あるいは、読者が「批判」を予測しているところに、突然擁護に回る。
この記事でも使っている手法です。
読者は「え、さっきまで否定してたのに?」と思う。
この反転が予測誤差になります。
ポイントは、 反転した先でさらにもう一段掘ること 。
最終章でのワードを、今ちょっとだけ切り取ると、
「でも私たちは芸術家ではなく情報発信者だ」と着地させているところがあります。
読者は「批判→擁護→さらに深い結論」という三段構造に連れていかれる。
単純な賛否の二項対立ではなく、三段目を用意する。
三段目があるから刺さるのです 。
これも結構、上級者向けだと思います。
5つ目は、 感情のズラし 。
読者が「論理的な解説」を予測しているところに、突然感情や五感の描写を差し込む。
逆に、感情的な文脈の中に急にデータを放り込む。
データや理論をずっと並べてきた直後に、「……窓の外で、雀が鳴いています」とポツリと書く。
読者の脳は「え、急にどうした?」となる。
あの一瞬の 「間」が予測誤差 です。
そしてその静寂のあとに核心のメッセージを置くと、読者の脳はそのメッセージを 「特別なもの」として受け取りがちになる。
逆パターンもあります。
感情的なエピソードで読者の胸が熱くなっているところに、急に冷徹な数字を叩きつける。
「感動→データ」のギャップが、数字の重みを増幅させる 。
ずっと感情、ずっとデータの話とかばかりだと、文章として「つまらなく」なりがちです。
この5つに共通しているのは、 読者が次に来ると思っている「種類」を裏切る という構造です。
スケール、時間軸、分野、立場、感情。
読者は無意識に「次もだいたい同じ種類の話が来るだろう」と予測している。
その予測を、別の種類で壊す。
ただし。
壊したあとに必ず「繋げる」
壊しっぱなしはただの脱線 です。
壊して繋げるから「なるほど」になる。
……と、ここまで話してしまいましたが、正直に言うと、 この「5つのズラし」の話だけで1本の記事が書けるくらい奥が深い テーマです。
まだ他にもテクニックありますしね。
AIとかにこの辺覚えさせたら、人間らしい良い文章が書けるんでしょうね。事実、私の文章もそうですからね。
それぞれのパターンを、実際の記事の中でどう設計するか。
どの順番で組み合わせると読者の脳が最も反応するか。
「壊して繋げる」の「繋げ方」に、どんな技術があるか。
このあたりは、今後あらためて1本の記事として書きます 。
楽しみにしていてください。
フォローしておいていただければ、お届けできます。。
メンバーシップでは、こうした「発信の設計図」をさらに具体的に、数字と事例つきで掘り下げています。
興味がある方は、ぜひ覗いてみてください。
さて、宣伝は一旦ここまでにして、
──ここで大事なことを言います。
これはテクニックであって
本質ではありません 。
最初に言いましたね?
これは全体の2割だと。
残り8割の話は後でします。
まず、この予測誤差の話を使って、 今の時代で一番大きな問題 を語らせてください。
✅ 第3章の小まとめ
🧠 脳は常に「次に何が来るか」を予測している ──予測通りだと反応せず、ズレたときにドーパミンが出る
🚃 通勤電車で急にドアが開かない瞬間と同じ構造 ──「え?」の感覚が「面白い」「刺さった」の正体
✍️ 発信者が唯一コントロールできるのは「予測のズラし方」 ──同じテーマでも切り口次第で読者の脳の反応が変わる
⚠️ ただしこれは全体の2割にすぎない ──テクニックであって本質ではない。残り8割は別にある
💡 第4章 あの文章「なんか違う」──平坦さの正体と不気味の谷
ほうじ茶に切り替えました。
カップを両手で包むと、じんわりと手のひらが温まる。
こういう 「ちょっとした温度の変化」 に、人間の体は敏感に反応します。
さて、ここまでの話で、発信者がコントロールできる「質」は 読者の予測をズラすこと だとお伝えしました。
じゃあ、逆のことを考えてみてください。
もし 予測誤差がゼロの文章 があったら、どうなるか。
全部が予測通りに来る。
脳はドーパミンを出さない。
「読めるけど面白くない」「正しいけど刺さらない」
そんな文章、あなたも最近よく目にしていませんか。
……そう。AIが書いた文章です。
文章とAIの話は切っても切り離せませんよね。私も今まで散々してきました。
ChatGPTやその他のAIが書いた文章を読んで、 「なんか違うな」 と感じたことがある人は多いはず。
AIっぽいな。
と。そうなると急に読みたくなくなって、離脱する人もいる。
AIの文章には無いのです。
「その人間らしい揺らぎが」
だからAIの文章が避けられて、スキやいいねが付きづらい、AI臭がすると言われ避けられている要因の1つでもあるわけです。
あの「なんか違う」の正体が、まさに今話した 予測誤差の欠如 が一因です。
そしてここからが、今の時代の発信者にとって一番怖い話になります。
「質を上げよう」と思って文章を丁寧に整えれば整えるほど、実はAIの文章に近づいていく 。
生成AIの活用もまったく同じです。AIのプロンプトを組めば組むほど「テンプレート化してしまう。」
つまり、 良かれと思ってやっていることが、読者の脳を退屈にさせている可能性がある 。
もう少し踏みこんでみましょう。
⚡ パープレキシティとバースティネス──AI文章の「のっぺり感」の正体
あなたは「AI検出ツール」というものをご存じでしょうか。
GPTZeroやOriginality.aiといったサービスで、 文章を入力すると「これはAIが書いたか、人間が書いたか」を判定してくれるツール です。
大学のレポートや、メディアの記事、企業のプレスリリース──「これ、本当に人間が書いたの?」を見破るために使われています。
で、このツールが判定に使っている指標が面白い。
パープレキシティ と バースティネス という2つの概念です。
(※パープレキシティ(perplexity)とは、噛み砕くと「次に来る単語がどれだけ予測しやすいか」を示す数値です。AI検出ツールのGPTZeroなどが採用しています)
(※バースティネス(burstiness)とは、要するに「文の長さや構造がどれだけバラついているか」を示す数値です)
AIの文章は、統計的に
「一番確率が高い次の単語」を選び続けます 。
だからパープレキシティが低い。
ようは予測しやすい 、ということです。
ここ、もう少し噛み砕きますね。
AIが文章を書くとき、何が起きているか。
AIは「この単語の次に来る確率が最も高い単語」を、ひたすら選び続けている。
いわば、 カーナビが「最短ルート」しか表示しない状態 です。
人間なら「今日は気分で裏道を通ろう」と寄り道する。
AIにはその「気分」がない。
だから文章が ずっと大通りの道路を走り続けている感じ になる。
一方、人間の文章は自然とバースティネスが高くなります。
長い文と短い文が混在する。
急に話が飛んだり、思い出したように戻ったりする。
ときどき一言だけの文がポンと入る。
ときどき一つの文が何行にもわたって走る。
AIの文章はこの逆です。
バースティネスが極端に低い。
文の長さが均一で、構造が整然としていて、段落の作りが教科書的に一貫している 。
あなたの家計簿で言い換えますね。
人間の家計簿は、月によって出費がバラバラでしょう。
3月は引っ越しで30万飛んだけど、4月は8万で収まった。
普通こういう 「バラつき」 がある。
AIの家計簿は、毎月きっちり15万。
15万。
15万。
15万。
……気持ち悪くないですか。
生活感がまるで無い。
あの気持ち悪さが、AI文章を読んだときの 「なんか違う」の正体 です。
AIの文章には、 予測誤差がほぼ存在しない 。
全部が予測通りに来る。
だから脳がドーパミンを出さない。
むしろ避けたくなる。
「読めるけど面白くない」
「正しいけど刺さらない」
この感覚の正体の1つが、まさにこれです。
面白いのは、AI文章が「AI臭い」と感じられる理由が、文法ミスや語彙の不自然さではないということ。
むしろ 文法が完璧すぎる ことが問題になっている。
人間はリズムの崩れ、脱線、突然の短文、感情の揺れ──こういう 「ノイズ」に反応する生き物 です。
AIはそのノイズを訓練の段階で平均化して消してしまう。
整えれば整えるほど、予測誤差が消える 。
残念ながら。
ここに皮肉があります。
「質が高い文章を書こう」と思って文章を整えれば整えるほど、 AIと同じ罠にハマる 。
整然とした文章=質が高い 、という思い込みが、むしろ読者の脳を退屈にさせているのです。
💀 不気味の谷は文章にも存在する──AIだと気づいた瞬間、読者は静かに去る
もう一つ、知っておくべき概念があります。
不気味の谷 です。
(※不気味の谷(Uncanny Valley)とは、もっと身近に言えば「人間にそっくりなロボットだけど何かが違う」ときに感じる、あの背筋がゾワッとする感覚のことです。1970年、日本のロボット工学者・森政弘が提唱しました)
ロボットが人間に似れば似るほど好感度が上がる。
でも 「かなり似ているけど微妙に違う」 という領域に入ると、
好感度が急激に落ちて不快感に変わる。
完全に人間と区別がつかなくなれば、また好感度は回復する。
この 急落する領域が「谷」 です。
あなたもゲームや映画のCG、もしくはテレビニュースで経験したことがあるでしょう。
「うわ、リアルだな」と思った次の瞬間、 目の動きだけが妙に不自然で、ゾッとする 。
あの感覚です。
この概念は元々ロボットの見た目の話でした。
では。
最近の研究では、テキスト・文章にも同じ現象が起きることが示唆されています 。
1つ、興味深い研究を紹介させてください。
📰 MIT DSpace / エムアイティー・ディースペース(2025年)
「An Empirical Study on Human Perceptions of AI-Generated Text and Images in the Context of the Uncanny Valley」
※ AIが生成したテキストや画像に対して、人間が「不気味の谷」と同じ反応を示すかどうかを実験で調べたMITの修士論文
📍 メディア傾向:MIT DSpace(エムアイティー・ディースペース)はマサチューセッツ工科大学の学術リポジトリ。修士論文であり査読済み学術論文ではないが、MITの審査を通過した学位論文
URL:
査読前の学術論文(チェック・評価前ということ)ですが、面白い結果になっています。
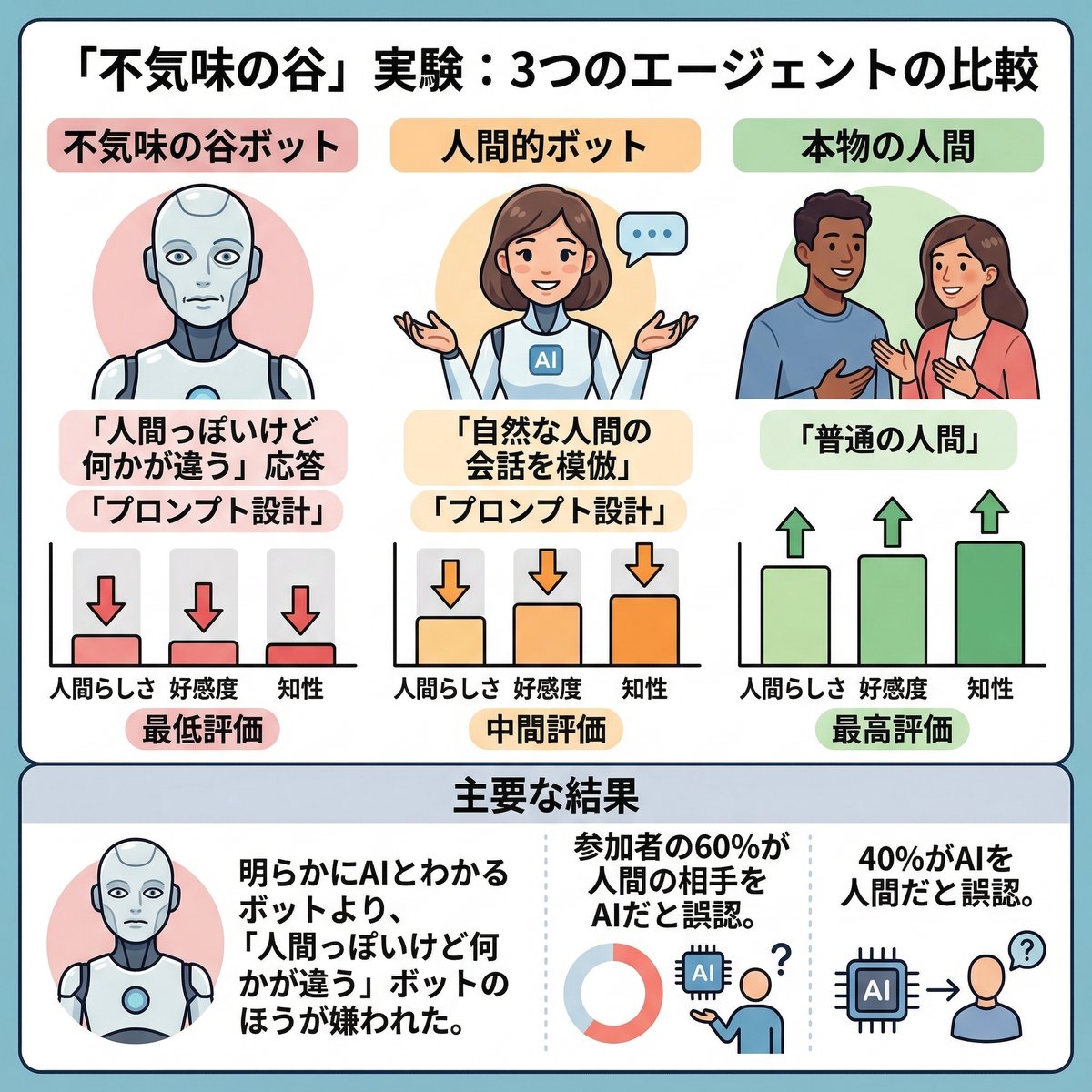
MIT(マサチューセッツ工科大学)のディーパリ・キシュナニの修士研究(2025年)では、 60名の参加者が3種類のチャット相手と会話する実験 を行いました。
1つ目は「不気味の谷ボット」
意図的に「人間っぽいが微妙にズレた」応答をするようプロンプト設計されたAIです。
2つ目は「人間的ボット」
自然な人間の会話を模倣するようプロンプト設計されたAI。
3つ目は、本物の人間。
普通の人間です。
結果、「不気味の谷ボット」は人間らしさ、好感度、知性の全指標で
最低評価 を受けました。
明らかにAIとわかるボットより、 「人間っぽいけど何かが違う」ボットのほうが嫌われた 。
さらに興味深い結果があります。
参加者の60%が人間の相手をAIだと誤認 しました。
そして40%がAIを人間だと誤認 した。
何が起きているかと言うと、こういうことです。
人間とAIの区別自体がすでに曖昧になってきている。
その中で 「中途半端に人間に寄せたもの」が、最も嫌悪感を引き起こす 。
(※注意:この研究は査読前であり、サンプル数60名と小規模です。論文自身も限界を認めています。ただし、不気味の谷がテキストにも存在する可能性を示した点で、示唆に富む研究です)
この知見を情報発信に当てはめると、ちょっと恐ろしいことが見えてきます。
AIで「そこそこ人間っぽい記事」を量産している発信者は、
読者の不気味の谷に落ちている可能性がある。
読者は言語化できないけれど「なんか違う」と感じて、静かに去る。
クレームは来ません。
ただ読まなくなる 。
おそらくそういう文章は、SNSでも今後規制されます。
AIを活用して記事を作るなら、不気味の谷を抜けるほど振り切って、好感度高め続ける努力が必要になってくる時代です。
AIの活用が手ぬるいと、「最近PVが落ちた」「メンバーが減った」──そう思ったとき、コンテンツの内容が悪いのではなく、
読者の無意識が「この文章は人間じゃない」と判定して離脱しているだけ かもしれません。
あなたが飲食店に入って、出てきた料理が コンビニの弁当を皿に盛り直したもの だったら。
味はそこそこでも、二度と行かないでしょう。
文句も言わずに。
ただ、行かなくなるだけ 。
それと同じことが、AI文章で起きている可能性があります。
そしてこの研究でもう一つ重要だったのは、参加者が全体として 自然さ、人間の不完全さ、弱さ を強く好んだこと。
人間の欠点が親しみやすさを生み、 完璧さからのズレが不気味の谷を回避する 。
人間の痕跡を消さないこと 。
これが不気味の谷を越える最も確実な方法です。
AIを使うなとは言いません。
ただ、最終的に人間のフィルターを通して、 ノイズを意図的に残す 。
リズムの崩れ、脱線、突然の短文、「ちょっと待ってくれ」──こういう 「不完全さ」が、実は読者の信頼を繋ぎ止めている 。
そういう工夫が必要なのです。
✅ 第4章の小まとめ
📊 AI文章はパープレキシティが低くバースティネスが低い ──予測通りの単語が均一なリズムで並ぶから、脳がドーパミンを出さない
🏠 「毎月きっちり15万円の家計簿」の気持ち悪さ ──整いすぎた文章は人間の脳に違和感を与える
👤 不気味の谷は文章にも存在する可能性がある ──「人間っぽいけど何かが違う」ボットが最も嫌われた(MIT修士研究、60名対象)
🔑 人間の痕跡を消さないことが読者の信頼を繋ぎ止める ──リズムの崩れ、脱線、不完全さこそが「人間の証明」
🎯 第5章 残り8割は何か──「誰に向けて書くか」という地味な問い
窓の外に目をやると、向かいの屋根に猫がいます。
じっとこちらを見ている。
目が合った瞬間、猫は フイッとそっぽを向いた 。
こういう「見られている」と「無視される」の落差が、不思議と頭に残るものです。
ここまで予測誤差の話とAI文章の話をしてきました。
「予測誤差を意識して、切り口を工夫すればいいんだな」で終わりかというと、 そうじゃありません 。
予測誤差を作るには、 大前提 がいります。
読者が何を予測しているかを知らなければ、
ズラしようがない 。
当たり前のことを言っているようですが、
ここが 「質を上げろ」という
アドバイスの最大の罠と思っています。
「質を上げろ」と聞くと、みんなテクニックの話だと思う。
文章術、構成術、タイトルの付け方、画像の選び方。
予測誤差の話だって、 テクニックの範疇 に入ります。
でも、それは全体の2割の話です。
残り8割は何か。
自分の読者が誰で、何を期待していて、何に反応するかを観察し続けること 。
これだけ。
地味でしょう。でもこれが出来ないと、ズラシようがないですからね。
あなたの給料日の通帳で考えてみてください。
毎月の支出を管理するとき、「節約術を学ぼう」と本を買う人は多い。
でも本当にお金が貯まる人は、 「自分が何にいくら使っているか」をまず把握している人 です。
テクニックの前に、現状把握。
情報発信もまったく同じ構造をしています 。
たとえば、私の記事を読んでいる人の多くは地政学や国際ビジネスに関心がある層だと思います。
この層が「予測している」ことと、料理レシピを読んでいる層が「予測している」ことは全然違う。
地政学に関心がある読者は、「次はこの地域の話が来るだろうな」と予測しながら読んでいる。
だから、まったく別の全体層の話を急に差し込むと 「おっ」 となる。
「予測誤差」を狙うにしても、 相手が見えていなければ的外れな方向にズラしてしまう 。
ここからです。
発信者が唯一コントロールできるのは、 誰に向けて書くかを選ぶこと 。
ターゲットが決まれば、その人たちがどんな情報を日常的に見ていて、何を「当たり前」だと思っていて、 どこを突けば「おっ」となるかが見えてくる 。
そこで初めて、予測誤差という2割のテクニックが機能する。
順番が逆なのです 。
「いい記事を書こう」→「切り口を工夫しよう」→「読者に届くかな」ではなく、
「読者は誰だ」→「何を予測しているか」→「どこをズラすか」
この順番。
私は、この順番こそ「質」だと思っています。
整理するとこうなります。
❌ テクニック先行型:自分の書きたいこと → 切り口の工夫 → 読者に届くか祈る
⭕ 読者理解先行型:読者は誰か → 何を予測しているか → どこをズラすか設計する
テクニックから入ると永遠に迷子になります 。
読者が何を面白いと思っているかを観察してから、書く 。
そのうえで、前回も言いましたが、書きたいものを徒然書けば良いのです。
✅ 第5章の小まとめ
📋 「質」の8割は読者理解 ──自分の読者が誰で、何を予測していて、何に反応するかを知ること
🎯 予測誤差を作る前提は「読者の予測を知ること」 ──相手が見えていなければ的外れにズラしてしまう
🔄 順番が逆になっている人が多い ──「いい記事→切り口→祈る」ではなく「読者→予測→設計」の順番
👧 上手な習い事の先生と同じ構造 ──技術の前に「その子が何を面白いと思っているか」を観察する




