親愛なる友人の皆さん、
あらゆるレベルの人々から雇用の不安を感じているという声を耳にしています。高校生は自分に仕事があるのかと心配し、エンジニアは追いつけるかを心配し、Cレベルの役員はAIによる自社の変革を支援できるかを心配します。その他にも多くの人が同様に感じています。AIの急速な進展と複数の地政学的不確実性の要因の中で、未来は今私が記憶している中でこれまでで最も不確かに感じられます。このような瞬間には、前途の興味深い可能性を活かすために私たちが何を作れるかを考えます。しかし、私が頼りにできる安定したもの、たとえばコミュニティやスキルといったものにも目を向けます。不確かな環境を進む皆さんには、これが少しでも安らぎになることを願っています。
AIの急速な進展は、雇用の未来や多くの企業の未来を不透明にします。ビジネスの面では、ベンチャー投資家の Chamath Palihapitiya は、AIによる混乱に直面した際の株価の影響について思慮深い記事を書きました。要約すると、多くの企業の価値は長期にわたって生み出されると期待されるキャッシュフローにあり、AIによる混乱でキャッシュフローが損なわれる可能性があれば、価値は大幅に低下します。
さらに、最前線のAI研究機関の代表者たちが未来について自信ありそうな予測をすることが多い一方で、私が彼らの話を非公開で聞いたときには、数年後に本当に何が起こるかは彼らにも分からないと伝えています。ソフトウェアの分野では、いくつかの傾向は明らかです。高いエージェント性を持つコーディングシステムは今後も改善を続け、すでに深刻な製品管理のボトルネックは悪化し、多くの人がコードを書くでしょう。そしてこれらの傾向にもかかわらず、将来のソフトウェア工学がどのようなものになるか、ソフトウェア工学チームがどのように組織されるかは、まだ徐々にしか明確になってきていません。
AIの進展のペースとは別に、将来にリスクを加える重大な転換点が多く存在します。イラン戦争は民間人の死者を増やしており、ホルムズ海峡の封鎖を引き起こしています。台湾の平和の将来と半導体供給への影響の不確実性、AIインフラへの過剰投資の可能性、そして希少金属を巡る中国の支配。私たちが相互につながった世界に生きているため、これらのどれも世界のどこかの人々に大きな影響を及ぼす可能性があり、結果として誰にとってもリスクが高まります。
ジェフ・ベゾスは、今後の10年間で変わらないものを知ることが、事業を構築するうえで安定した基盤を作ると有名な言葉で述べました。世界の多くの事柄は、10年後も現在と同じであり続けるでしょう。しかし、雇用の安定性を心配している個人にとって、その期間に安定すると私が思う2つのものは、コミュニティとスキルです。

まず、今から10年後には、私の友人や家族は私のそばにいてくれると知っています。何が起こっても私が彼らのそばにいることも知っています。人間関係は非常に長く持続することがあります。コロナ禍の間、多くのコミュニティが結束し、お互いを支え合いました。だからこそ、不確かな時には、コミュニティ――人間関係のネットワーク――を持つことが、誰にとっても役立ちます。だからこそ、人間関係を築く機会は非常に価値があり、より多くのことを成し遂げ、リスクの下振れから身を守るのに役立ちます。これが、対面での集まり――新しい友人を作り、既存の関係をリフレッシュできる場所――が特に価値がある理由です。イベントに参加したい場合は、AI開発 にお越しください。これは4月28-29日にサンフランシスコで開催されます。
さらに、特定の企業がうまくいくかどうかに関係なく、多くのスキルは引き続き価値があります。あなたのスキルは常に持ち出せるもので、獲得したスキルを失うようなことは誰にも起こりません。どのスキルが価値があるかは変化しますので、さまざまなスキルに投資して自分の選択肢を増やす価値があります。さらに、スキルは積み重なるのです(例:プロンプトの理解はコード書きエージェントを使う際に重要で、AIの構築ブロックの理解は特定のアプリケーションの設計方法を理解するのに重要です)。したがって、スキルを身につけることは追加の知識を得るのを容易にし、今この時点でさまざまなスキルを身につける投資をすることで、何が起ころうと、さまざまな有益なことを成し遂げられる可能性を高めます。
私は、見えている多くのリスクが上手くいくと楽観視しており、私たちの集団的なAIの未来は今日よりはるかに明るいものになると信じています。皆さんを支援し、AIコミュニティを支援するために、私はここにいると信じてください。急速に動く不確かな世界をともに進む中で、お互いを助け合い、コミュニティを築き、貴重なスキルを獲得する手助けをし続けましょう。
これからも作り続けよう!
アンドリュー
DEEPLEARNING.AIからのメッセージ

In our latest course, made in collaboration with Oracle, you’ll build a complete agent memory system that lets an LLM store, retrieve, and refine knowledge across sessions — turning a stateless agent into one that learns and improves over time. ここに登録
ニュース
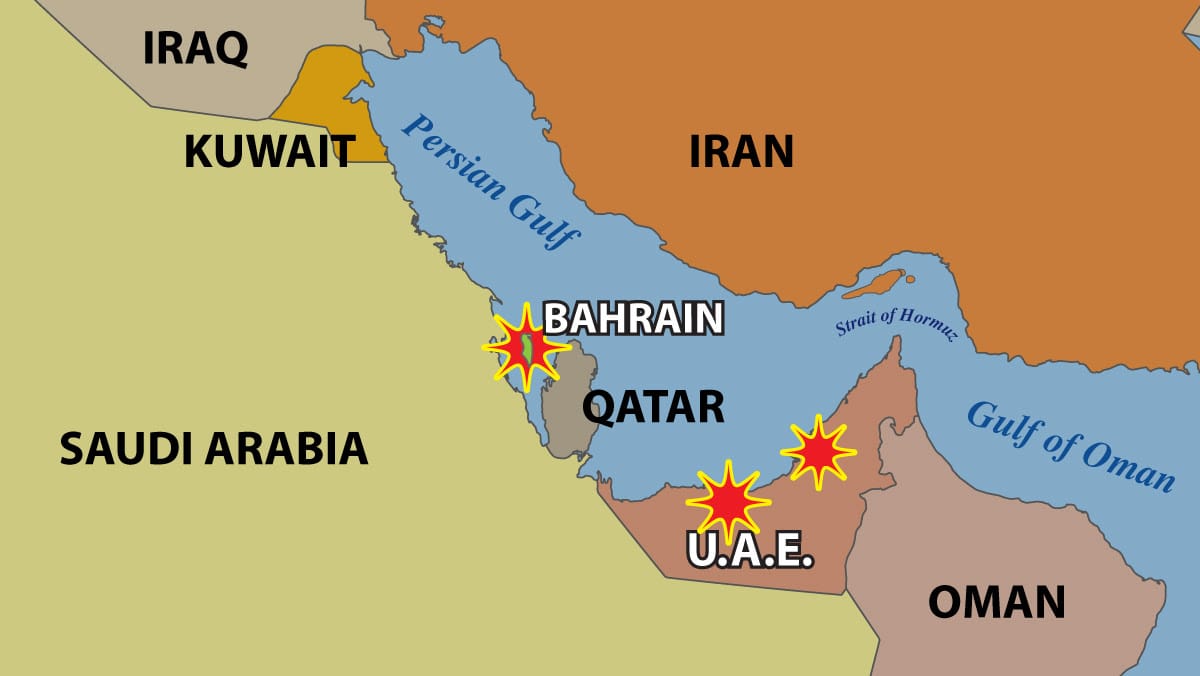
ペルシャ湾のデータセンターをドローンが襲撃
イランは中東の少なくとも3つのAmazonデータセンターを攻撃しました。これはAIが米国のイラン戦争における重要な役割を果たしていることの指標であり、戦争中にこのような施設が標的にされた初めての事例である可能性があります。
何が起きたか: イランのドローン 損傷を受けた バーレーンの AWS 施設と UAE の二つの施設が、銀行、決済、ライドシェア、フードデリバリー、業務用ソフトウェアなどのオンラインサービスを混乱させました。米国軍は 使用 AWS で未分類版の Anthropic Claude および他の計算系を動かしていますが、攻撃が作戦に影響を与えたかは公表されていません。
- データセンターは、構造的な損傷、電力障害、水害を消防士によって引き起こされ、サービスの停止と通常より高い誤り率を招きました。3月3日現在、Amazon はクラウド・コンピューティング顧客に対し、データをバックアップし、AWS 中東リージョンから米国、欧州、またはアジア太平洋へワークロードを移すことを推奨 してデータをバックアップし、AWS Middle East Region から米国、欧州、またはアジア太平洋へワークロードを移すこと。
- この攻撃は、ペルシャ湾地域に AI ハブを構築するための何兆ドルにも及ぶ投資を危機にさらす可能性がある。The New York Times 報じられた。
- 湾岸協力会議(GCC)加盟国は、バーレーン、クウェート、オマーン、カタール、サウジアラビア、アラブ首長国連邦を含む、データセンター容量が2.0ギガワットを有しており、追加で0.4ギガワットが計画されているとされ、Business Insider 報じられた。
Behind the news: データセンターのリスクは、戦争における AI の役割の高まりを映している。米国軍が最近、Anthropic の Claude 大規模言語モデルの防衛用途を ban 防衛用途の使用を禁止するという最近の決定にもかかわらず、米軍は Claude や他のシステムをイランやその他の場所でさまざまな目的で日常的に使用しています。 一方、イランはある程度の自律性を持つ兵器化ドローンを使用しています。
- Claudeは、米国がイランに対する戦争を開始した最初の24時間で1000件を超える標的を選定するのを支援したシステムの一部であり、米軍が攻撃のペースを大幅に加速できるようにしていたと The Washington Post 報じた。 ClaudeはPalantirが構築した標的指定と物流のシステムであるMaven Smart System(MSS)と統合されている。誤りを避けるため、人間のアナリストが命に関わる状況でシステムの出力を確認する。訓練では、MSSは標的選定プロセスを12時間から1分未満に短縮し、以前は2,000名を要したスタッフで成果を挙げたと Army Times 報じた。 Claude/MSSは、1月の作戦でベネズエラの大統領ニコラス・マドゥーロを拘束した役割を果たしたが、イランでの行動は“本格的な戦争作戦”として初の使用である。
- 安価なドローンの使用は、最近の米・イラン戦争の特徴となっている。イランは、初期の米国の爆撃作戦に対して、地域のインフラ、軍事拠点、米国資産を標的とする多数の低コストの“カミカゼ”設計を含む大量の攻撃ドローンで応じた。米国はその後、自国の一方的な攻撃ドローンを解き放ち、イランのShahed-136をモデルとしたLUCASシステムを含んでいる。この戦闘様式は、ソフトウェアとAIと連携して動作することが多いドローンの群れが、戦車、砲兵、物流ターゲットを破壊したロシア・ウクライナ戦争におけるウクライナの革新に大きく依拠している。
Yes, but: AIが軍事意思決定のペースを高めるにつれ、致命的な誤りのリスクも高まる。例えば、イランへの初動空爆の最初の波の間に、爆弾が学校を破壊し、170人以上が死亡し、ほとんどが子どもだった。後の調査では、初期の所見は米軍がその爆弾を落とした可能性が高いことを示している。標的データが古いことが建物の標的化に影響した可能性がある。学校は近くの海軍基地の約15年前の一部だった。
なぜ重要か: AI対応兵器の急速な発展は、戦闘のペースを人間の速度から機械の速度へと移す変化を示している。AIは、成功につながる可能性が最も高い行動を識別するために膨大な数のシミュレーションを回して任務を計画することを現実的にしている。戦場の意思決定と行動を加速させつつ、戦場の現実を覆い隠すいわゆる「戦場の霧」を低減する可能性がある。かつては人間の注意不足で分析されてきた戦場の通信、画像、その他の情報の洪水を分析する任務が現実的となる。加速は紛争のいくつかの段階を短縮する可能性がある一方で、壊滅的な結果を招く可能性のある即断を迫る圧力を高める。
私たちは考えています: AIが生成する推奨は、情報の検証、仮定の検証、武力行使の倫理的・戦略的影響を検討する必要性を取り除くものではありません。
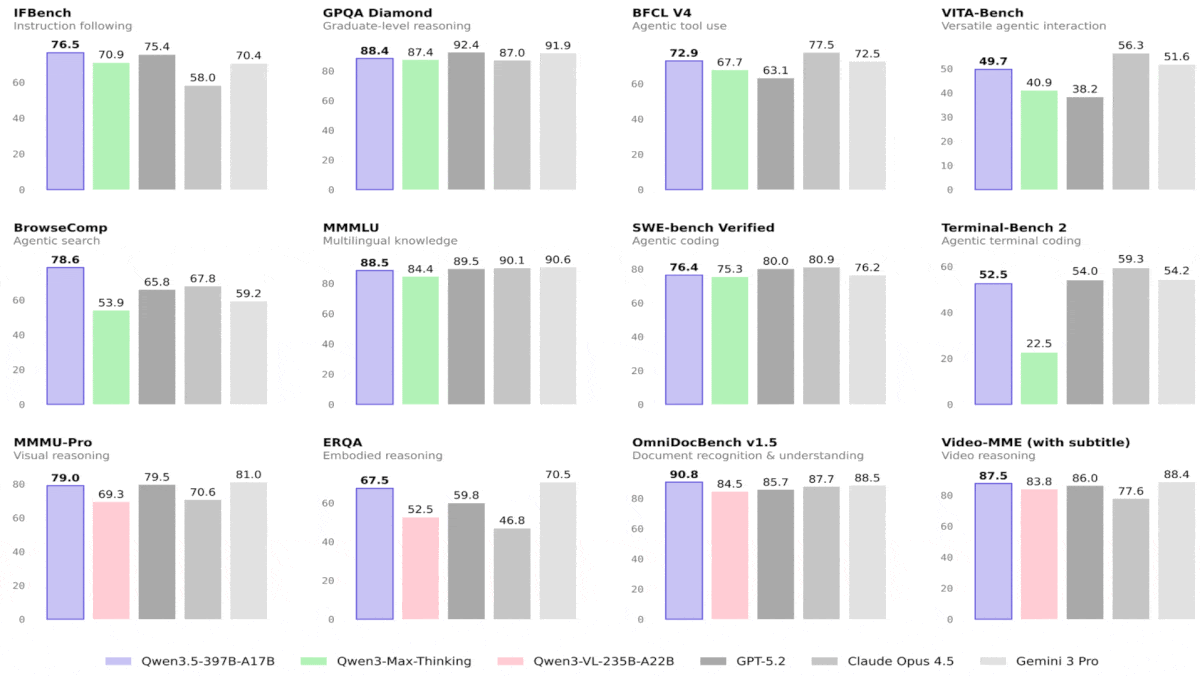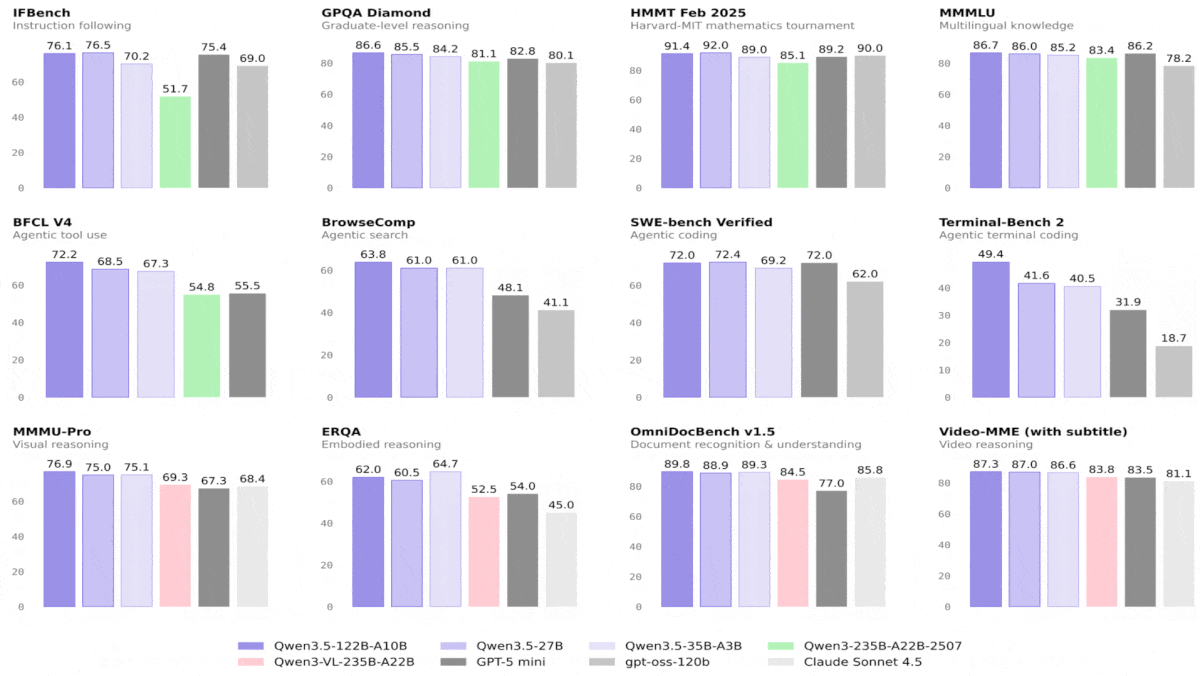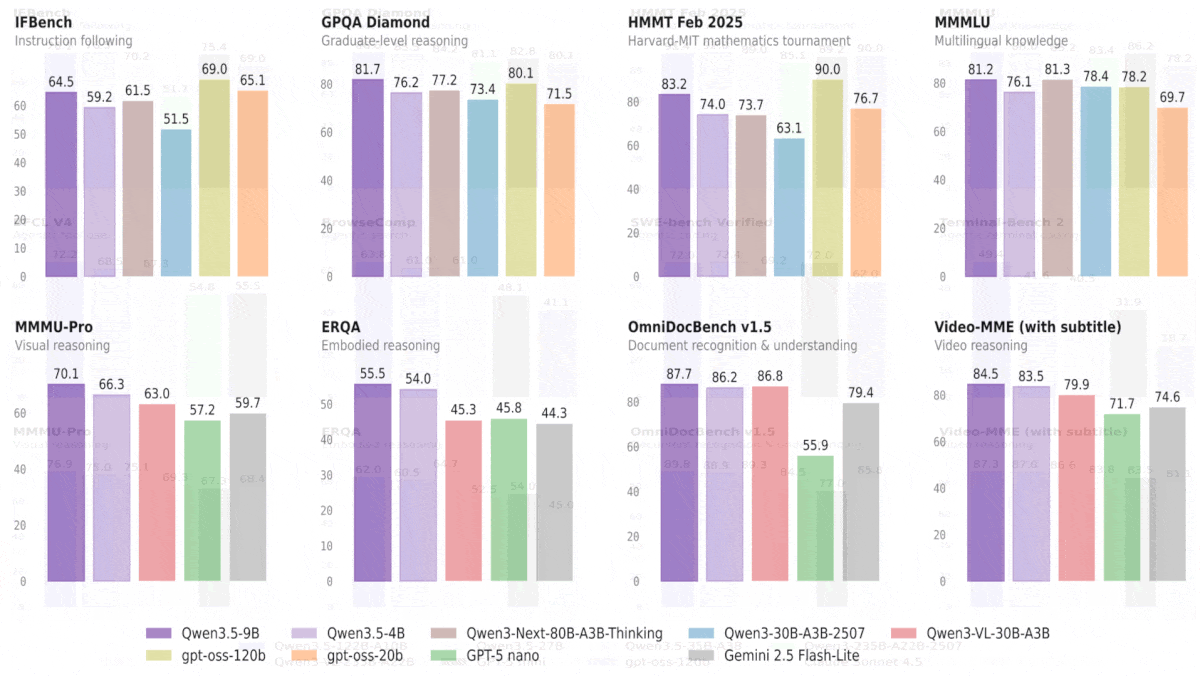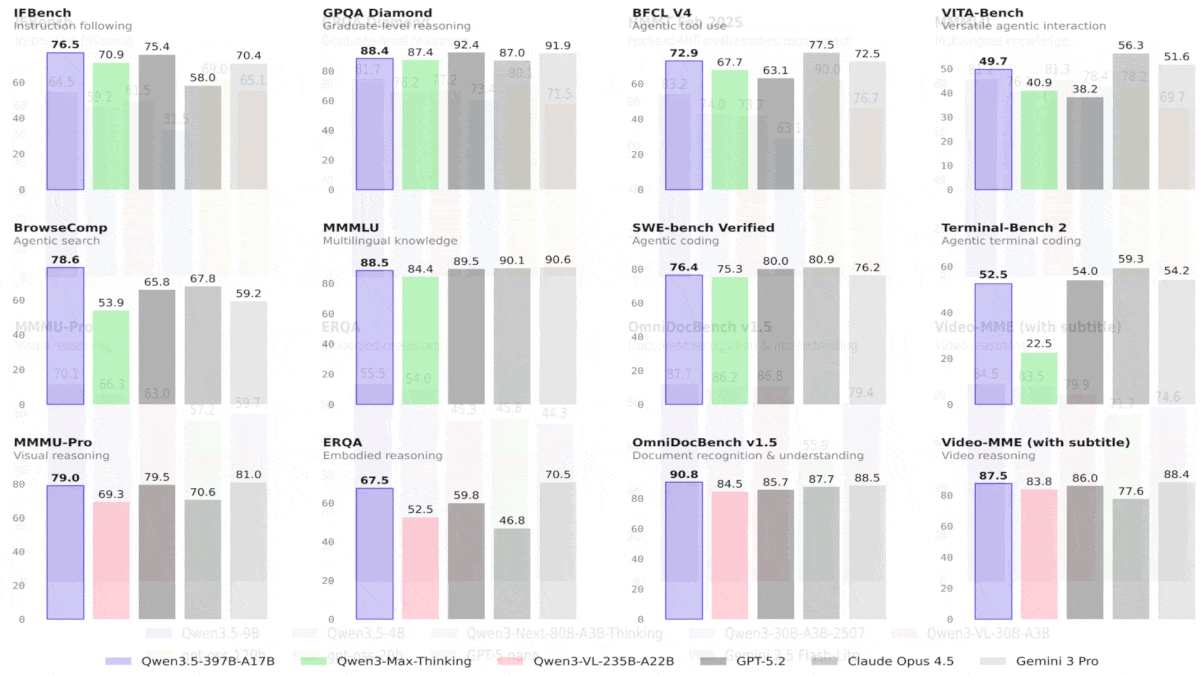
Qwen3.5 は大型モデルを上回り、視覚ベンチマークを牽引
Qwen3.5ファミリーのオープンウェイトのビジョン-言語モデルには、印象的な大型モデルだけでなく、サイズの10倍にもなるOpenAIのオープンウェイトモデルを上回る小型モデルも含まれている。
最新情報: Alibabaは、Qwen3.5 ファミリーの8つの公開ウェイト視覚言語モデルです。最大のものは、Qwen3.5-397B-A17B(3,970億パラメータ、1トークンあたり170億アクティブ)で、公開ウェイトを提供します。またQwen3.5-Plusは、より大きな入力コンテキストと自律的に選択できる組み込みツールを提供することで、エージェント型アプリケーションをサポートするQwen3.5-397B-A17Bのホスト版です。中型の4モデルには、公開ウェイトのQwen3.5-122B-A10B、Qwen3.5-35B-A3B、Qwen3.5-27B、さらにQwen3.5-Flash(Qwen3.5-53B-A3Bのホスト版で、エージェント型アプリケーション向けに装備)があります。ファミリーの中でより小型のQwen3.5のメンバー――Qwen3.5-9B、Qwen3.5-4B、Qwen3.5-2B、Qwen3.5-0.8B――のうち、9Bと4Bの変種は、はるかに大きなモデルの性能に匹敵します。
- 入力/出力: テキスト、画像、動画の入力(オープンウェイトモデルは254,000トークン、最大1,000,000トークンへ拡張可能、ホストモデルはデフォルトで最大1,000,000トークンまで)、テキスト出力(最大64,000トークン)
- アーキテクチャ: 専門家の混成モデル(Mixture-of-experts)または混合アテンションとGated DeltaNet層を備えた密結合トランスフォーマー、未指定のビジョンエンコーダ
- 性能: 全体的に優れた視覚性能を発揮;Qwen3.5-9B(90億パラメータ)は、多くの言語タスクでgpt-oss-120B(1200億パラメータ)を上回る。
- 提供形態: 公開ウェイトはApache 2.0ライセンスの下で自由に利用可能、Alibaba Cloud Model Studio経由の公開ウェイトモデルのホスト型API(モデルごとに価格が異なり、1百万入力/出力トークンあたり$0.20-$0.60、または$2-$3.6の範囲); Qwen3.5-PlusのAPIは$0.4/$0.04/$2.4、Qwen3.5-FlashのAPIは$0.1/$0.01/$0.4/1百万の入力/キャッシュ/出力トークンごと。
- 機能: 201言語、ツールの利用、ウェブ検索、思考過程による推論
- 非公開: 視覚エンコーダ、訓練データ、手法
仕組み: AlibabaはQwen3.5ファミリーの構築方法について、ほとんど情報を公開していませんでした。
- Qwen3.5はQwen3-Next architecture、Qwen3-30B-A3Bアーキテクチャとトレーニング手法の変種で、トレーニングの効率と安定性を高めるよう改良されています。
- Qwen3.5は、Qwen3よりも“視覚とテキストのトークン規模が著しく大きい”規模で訓練されました。
結果: アリババによる試験では、すべてのQwen3.5モデルが視覚タスクで優れた成果を示し、はるかに大きいモデルを上回り、一部は言語タスクでも競争力のある結果を出しました。全体的に最も印象的な性能を示したのはQwen3.5-9BとQwen3.5-4Bで、視覚と言語の両タスクで輝きを放ち、はるかに大きいモデルと比較しても優れた結果を出しています。最も小さい2つのバリエーションには比較指標が欠如しています。
- 44の視覚ベンチマークのうち28件で、Qwen3.5-397B-A17BはGPT-5.2、Claude 4.5 Opus、Gemini-3 Pro(いずれもパラメータ数は公表されていませんが、はるかに大きいと見られる)を上回りました。多様な言語タスクでは、Qwen3.5-397B-A17BはGPT-5.2、Claude 4.5 Opus、Gemini-3 Proのいずれかを上回りましたが、三者すべてを上回ることは一般的にはありませんでした。
- ほとんどの言語および視覚ベンチマークで、Qwen3.5-122B-A10BとQwen3.5-27BはGPT-5-miniを上回りました(パラメータ数は公表されていません)。通常、1トークンあたり100億パラメータを活性化するMixture-of-ExpertsアーキテクチャのQwen3.5-122B-A10Bは、密結合アーキテクチャの27BであるQwen3.5-27Bを上回りました。Qwen3.5-35B-A3Bは、一般的には小型のQwen3.5-27BおよびQwen3.5-122B-A10Bを下回りましたが、それでも74件中58件でGPT-5-miniを上回りました。
- Qwen3.5-9Bは、推論とコーディングタスクを除く大半の言語ベンチマークで、OpenAIの言語モデルgpt-oss-120Bよりも上回りました(サイズは10倍以上大きいとされる)。同様に、Qwen3.5-4BはOpenAIのgpt-oss-20Bを、推論とコーディングタスクを除く大半の言語ベンチマークで上回りました。視覚ベンチマークの大半では、Qwen3.5-9BおよびQwen3.5-4Bの双方が、視覚言語モデルGPT-5-nanoおよびGemini-2.5-Flash-Liteを上回りました。
ニュースの裏側: Qwen3ファミリーの展開直後、チームの技術リードでありモデルの主要設計者の林俊陽は、Xソーシャルネットワークに「Bye my beloved qwen」という投稿を残して突然辞任しました。中国のテックニュースサイト36kr.comは、その後、チームの他の4名が林の辞任を受けて辞任したと伝えました。1月の公開イベントで、林は「私たちは薄く引っ張られている――納品要求を満たすだけで資源の大半を消費している」と述べており、Bloombergreported. AlibabaはQwenプロジェクトを上層部のより厳格な監視のもとに置き、AI開発へのinvest further in AI development.
Why it matters: All Qwen3.5 models deliver stellar vision performance for their sizes, but the smaller models — especially Qwen3.5-9B — are small enough to run on consumer laptops while delivering performance that previously required an 80GB GPU like a Nvidia H100.
We’re thinking: Vision-language models with reasoning capability that are small enough to run locally means reduced cost, better privacy, and new vistas for vision-language applications.

DeepSeek、NvidiaをHuawei向けに冷遇
Open-weightモデルの優れた中国系開発者であるDeepSeekは、旗艦モデルの今後のアップデートを米国のチップメーカーに提供していないことを明らかにしており、米中のAI競争を一段と激化させている。
What’s new: DeepSeekは、開発の最終段階にあるDeepSeek-V4が自社のチップ上で円滑に動作することをNvidiaまたはAMDに確認させる機会をまだ与えていない。これは大規模モデル更新前の通常の慣行からの逸脱である。しかし、Huaweiにはプレリリース版を共有しており、中国のチップメーカーが自社のハードウェアに合わせてソフトウェアを最適化するための数週間を与えた。Reutersがreported, although it did not report DeepSeek’s reasoning for the decision.
How it works: According to Reuters, chip makers typically examine new models to make sure they run inference efficiently on their hardware. In the past, DeepSeek has worked closely with Nvidia to train its models.
- 匿名の上級トランプ政権関係者は、DeepSeek-V4が中国でNVIDIAの高度なチップを用いて訓練されたと述べたが、米国の輸出規制にもかかわらず、Reutersはreported、公式がこの情報をどう取得したかを学べなかった。
- Nvidiaは、DeepSeek-V3の訓練時にDeepSeekへ広範な技術支援を提供し、訓練の効率を大幅に向上させたと、米国下院の中国委員会の委員長が1月に述べた。
- 昨年、中国政府はNvidiaのH20チップを中国市場向けに設計された製品として安全審査を義務づけた。一方、中国のAI企業には、必要な場合に限り外国チップを購入するよう求めた。
Behind the news: For years, the U.S. has tried to slow China’s AI effort by restricting exports of advanced chips and the equipment needed to produce them. But that effort has largely backfired by spurring China to build its domestic chip industry, and China’s government has taken steps to encourage or require companies in that country to use domestic chips.
- Although chips produced in China do not yet rival those designed by Nvidia and manufactured by Taiwan Semiconductor Manufacturing Corporation, Chinese companies, notably Huawei, have made strides in recent years.
- After tightening restrictions progressively since 2022, in January, the U.S. government began permitting exports of top-of-the-line AI chips on a case-by-case basis, subject to a 25 percent charge on such sales. However, officials are considering new export limits.
- Last year, China’s government mandated a security review of Nvidia’s H20 chip, which was designed for the China market. Meanwhile, it asked Chinese AI companies to buy foreign chips only when necessary.
Why it matters: While DeepSeek’s decision to withhold prerelease access to DeepSeek-V4 from U.S. chip makers may be more symbolic than significant, it deepens the divide between the portions of the AI community that are based in the U.S. and in China. The decision aligns with China’s long-standing goals of technological self-sufficiency, so critical AI capabilities remain available regardless of adversaries’ efforts to block them.
We’re thinking: The possibility that DeepSeek trained its latest model using Nvidia chips is one among several indicators that export restrictions alone are not stopping international rivals from gaining access to U.S. chips. The world would benefit more from negotiated limits, mutual cooperation, and free exchange of ideas, technology, and trade.

視覚メディアのための単一トークナイザー
マルチモーダルモデルは通常、異なるメディアタイプを埋め込むために異なるトークナイザーを使用し、生成の訓練時には分類ではなくメディアを生成するために異なるエンコーダを用います。Appleのチームは、画像や動画だけでなく3Dオブジェクトも、これらの視覚メディアのいずれかに共通のトークン空間へマッピングする多次元トークナイザーを作成しました — そして、それらを識別するだけでなく生成するのにも優れた共通エンコーダを搭載しています。
新機能: Jiasen Lu、Liangchen Song、およびAppleの同僚は、AToken, 全用途視覚トークナイザーを備えたトランスフォーマーモデル。新しいモデルは、画像、動画、3Dの生成と分類の両方を行うことができ、各入力・出力タイプの特化モデルの性能に近づいています。
重要な洞察: 画像生成モデルは、視覚的ディテール(猫の表面やボールの表面がオレンジ色かどうか)を保持するエンコーダ(VAEやVQ‑VAEのようなもの)を使用しますが、意味情報(それが猫かボールか)は捨ててしまうため、分類モデルほどオブジェクトを認識できません。一方、画像分類モデルは、物体の種類(例えば「猫」や「ボール」)を捉えるエンコーダ(CLIPやSigLIPのようなもの)を使用しますが、視覚的ディテールを見逃すため、生成には向きません。静止画像から動画や3Dへと移行すると、問題はさらに複雑になります。エンコードされる前に、動画と3Dは通常、エンコーダが処理できるデータに画像を分解するための別個のトークナイザーを必要とします。もし三つのメディアタイプが、同じ形式で同じトークナイザーを用いて分析されれば、ひとつのトランスフォーマーがそれらすべてと連携して学習できるようになります。さらに、これらのメディアタイプを再構成し、それらを対応するテキスト説明に合わせて埋め込みを保持するようモデルを訓練することで、埋め込みが細かな視覚的ディテールと意味的参照の両方を保持するようになり、別個の生成モデルと分類モデルの必要性を排除します。
仕組み: AToken は、事前学習済みの SigLIP2 視覚エンコーダ(4億パラメータ) — ここでは二次元から四次元へ拡張 — および同サイズの未訓練デコーダ。著者らは、AToken を、3つの画像セット(two 公開 と1つの非公開)、3つの セット of 動画、および2つの公開セットの3D を
返却形式: {objects、すべてが対応するテキストとペアになっています。彼らはこのデータを3段階で訓練しました。まず画像、次に動画、そして最後に3D。
- 著者らは、すべての入力を時間と空間の座標 (t, x, y, z) を用いてトークンに分割しました。画像は単一の2次元 (x,y) スライスとしてマッピングされ、t = z = 0 を設定しました。動画には時間の追加座標 (t, x, y, z) が含まれ、3D オブジェクトは (x, y, z) のグリッド上にマッピングされ、t = 0 としました。1つの線形層が各トークンを埋め込みへと変換しました。
- また、4D Rotary Position Embedding を使って、t, x, y, z に沿う角位置をエンコードしました。エンコーダは各線形埋め込みとその相対位置を組み合わせ、入力を表す埋め込みを生成しました。
- デコーダは、エンコーダの埋め込みから入力を再構成しました。画像と動画にはRGBピクセルを生成し、Gaussian splats—小さく色づけされた3Dブロブが、レンダリングされると一貫した3D形状を作り出す。3Dオブジェクト向け。AToken は、4つの損失関数を用いて入力を再構成することを学習しました: (i) 最初の損失は予測ピクセルと地上 truth ピクセルの差を最小化する、(ii) LPIPS(ランディングページは見つかりません)を最小化して、元の画像と再構成の間の距離を最小化します。 (iii) CLIP 知覚損失は、再構成のCLIP埋め込みと元の埋め込みの距離を最小化します。 (iv) グラム行列損失は、再構成と元の画像の埋め込み間の相関を最大化することで、スタイルと個々の特徴の差を最小化します。
- 視覚入力の埋め込みを、それに対応するキャプションの埋め込みと揃えるため、著者らはエンコーダのすべての埋め込みをアテンションを通じて結合し、入力を要約する1つのグローバル埋め込みを生成しました。これを attention pooling と呼ばれます。彼らは、グローバルな視覚埋め込みと一致するキャプションのSigLIP2テキスト埋め込みとの類似度を高め、一致しないキャプションの埋め込みとの類似度を減らす対照学習損失を用いました。
結果:AToken は、画像・動画・3Dを処理する最先端モデルと同等、あるいはそれに近い性能を示しました。
- 画像を分類する場合、AToken は ImageNet 分類精度 82.2% に達し、専用画像エンコーダである独立した SigLIP2(83.4%)に近づきました。画像を生成する場合、0.21 rFID(再構成品質の指標、低いほど良い)を達成しました。これは、UniTok のような統一トークナイザーを用いた従来のモデルより優れており、各入力タイプのエンコーダを専門とするUniTokに近づき、UniTok は、入力の種類ごとに特化したエンコーダを使用する方式で、FLUX.1 [dev] にも近づき、0.18 rFID を達成しました。
なぜ重要か: 大規模言語モデルの大きな革新の1つは、コード、対話、表、書籍など、すべての言語入力に対して単一のトークナイザーを使用する点です。これにより、トレーニング中に1つのデータソースから別のデータソースへ知識を転移するモデルの能力が高まります。テキストを理解したり生成したりする能力が向上すると、コードも向上します。ATokenは、特に2Dおよび3Dオブジェクトに関して、視覚モデルにも同様の汎用性を提供します。複数の視覚メディアタイプを生成・再構成する際のATokenの高い性能は、ここでも共通のトークナイザーとエンコーダが1つのモダリティから他のモダリティへ改善を波及させる可能性を示唆しています。
私たちが考えていること: ATokenのようなモデルは、合成的な3Dおよびビデオデータの生成に役立つ可能性があります。1つのメディアタイプから別のメディアタイプへ一般化するモデルは、各タスクの学習に必要な総データ量を通常減らします。例えば、高品質でよくラベル付けされた2次元画像データは豊富ですが、ビデオと3Dはロボット工学のアプリケーションには不可欠です。




