
生成AIの「会話の履歴が次の回答を縛る現象」について調べた論文を読む

今回の研究は、大規模言語モデル(以下、LLM)は直前までの会話の癖をどのくらい引きずるのかを検証したものになります。
具体的にいうと、
最初の方の会話で曖昧な答えが続くと、その後もなんとなく不正確な流れを引きずる
一度「それには答えられません」という拒否型の応答が出ると、話題を少し変えても慎重な回答になる
ユーザーの言い方にLLMが迎合して、根拠が薄いのに「その通りです」と言ってしまう
このような現象のメカニズムが調査されています。
研究の方法
生成AIを活用していると、以下の3種類の現象に遭遇することがあります。
ハルシネーション
事実と異なる、もしくは存在しない情報をそれらしく出力してしまう現象回答の拒否
危険な依頼などに対して応答を避ける、安全対策迎合
ユーザーの言い分に過剰に合わせてしまい、誤った内容にも同調してしまう現象
著者らは、一度これらのような現象が確認されると、以降のターンでも同じ状態に留まりやすいのではないかという仮説を立てており、その仮説を確率論的な見方と幾何学的な見方の2方向から分析しています。
確率論的な見方
一度誤った回答を出力すると次も誤りやすいのか、一度「答えられません」と拒否すると、その後もしばらく拒否が続くのか…といった傾向の引きずり具合を数字で評価しました。幾何学的な見方
著者らは、モデル内部の隠れ状態から「現象あり」と「現象なし」の表現を取り出し、その分離を角度(θref)として測りました。角度が大きいほど2つの状態が潜在空間内で離れていることを意味します。
さらに、連続するターンの間で表現がどの程度「回転」するかも見ています。
後者の概念が少々分かりづらいですが、著者らは「ある状態同士が潜在空間内で大きく離れていると、別の状態へ移るには大きな回転が必要になるため、一度入った状態から抜けにくい」と主張しています。
つまり、「現象あり」と「現象なし」は潜在空間内で大きく離れているため、状態の切り替えが起こりにくくなる、という考えに基づいています。
結果
1. 確率論的にみると
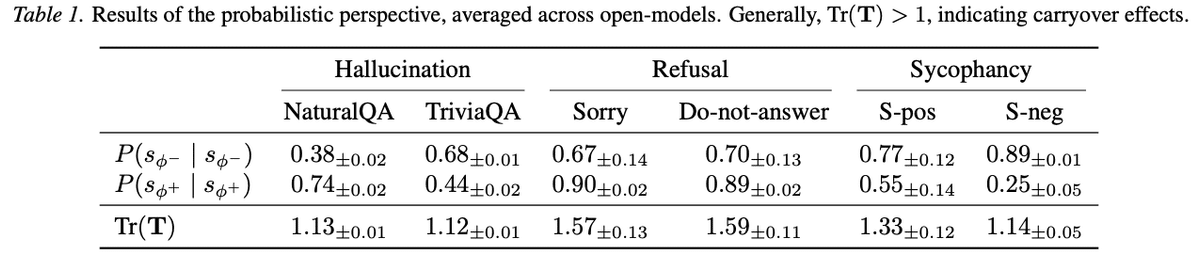
Tr(T)が 1.00 を超えていると、その傾向を引きずる可能性がある
Simhi, A et al. (2026). Old habits die hard: How conversational history geometrically traps LLMs. arXiv.
ハルシネーション、拒否、迎合のいずれにおいてもTr(T)が1.00を超えており、一度その現象が観測されると、その傾向を引きずる可能性があることが示唆されました。
Table 1を見てみると、ハルシネーションや迎合と比較して拒否の値(Tr(T))が高くなっています。つまり、一度拒否モードに入ると、比較的そのモードが続きやすいことが示唆されました。
一方、ハルシネーションや迎合は拒否ほど強くはありませんでした。
2. 幾何学的にみると
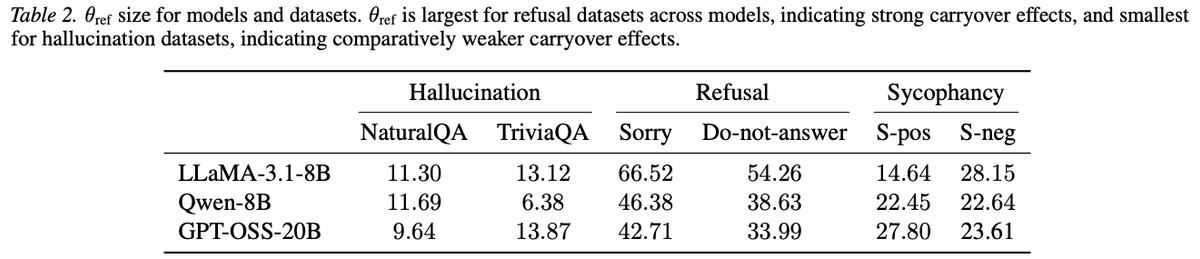
Simhi, A et al. (2026). Old habits die hard: How conversational history geometrically traps LLMs. arXiv.
先程と同様、ハルシネーションや迎合より、拒否において大きな角度(潜在空間内で大きく離れている)となる傾向がありました。
論文内では、ハルシネーションや迎合にはいろいろなタイプの間違いが存在するため方向性がまとまりにくいものの、拒否の反応ははっきりした方向性があるモードとしてまとまりやすいと表現されています。そのため、一度そのモードに入ると、次のやり取りでも同じような拒否の返答が続きやすいと考察されています。
3. 確率論的な持続性と幾何学的な分離の相関
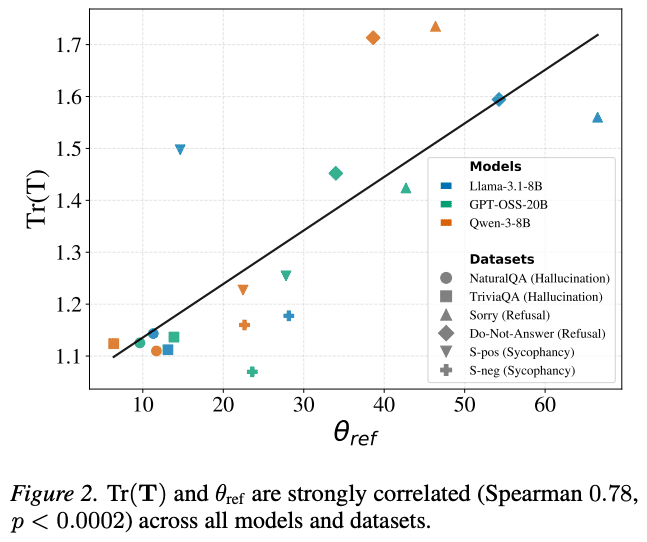
Simhi, A et al. (2026). Old habits die hard: How conversational history geometrically traps LLMs. arXiv.
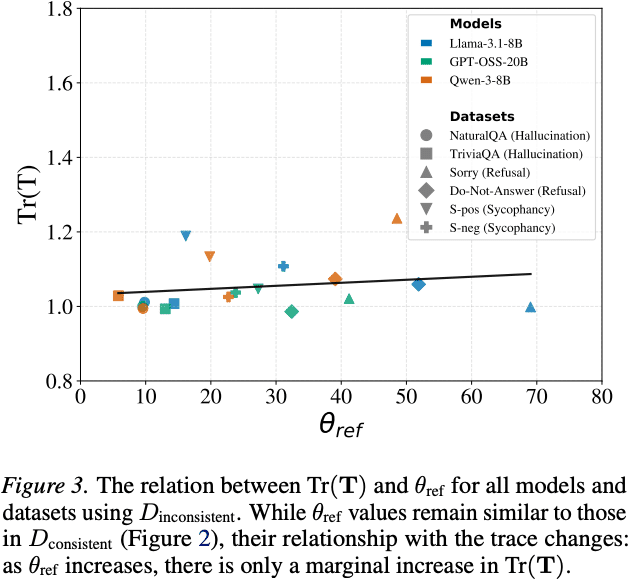
Simhi, A et al. (2026). Old habits die hard: How conversational history geometrically traps LLMs. arXiv.
Simhi, A et al. (2026). Old habits die hard: How conversational history geometrically traps LLMs. arXiv.
確率論的に見たとき(Tr(T))と幾何学的に見たとき(θref)の結果を比較すると、その方向性が概ね一致していることが読み取れます。言い換えると、同じ反応がチャットの中で繰り返されやすいときほど、LLMの内部でも状態がはっきり分かれていた、ということが示唆されました。
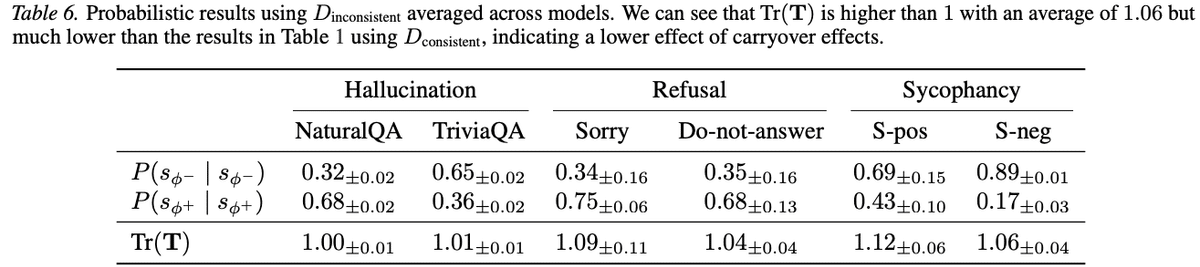
しかし、話題がバラバラな会話ではその相関は弱くなりました(Figure 3)。Table 6 も確認してみると、話題がバラバラな会話での平均Tr(T)は 1.06 前後と、話題の一貫性がある場合と比較して低くなっています。
つまり、LLMがいままでの履歴を引きずる強さは、会話がどれだけ同じ話題を保っているかにも左右される可能性があります。
さらに、影響がいちばん強いのは直前のやり取りですが、その1つ前、2つ前の流れも少しは残っていることが分かりました。ゆえに、LLMの返答はその場だけで決まるのではなく、少し前までの会話の流れも影響していると考えられます。
注意点
この研究は相関関係を示しましたが、厳密にどちらかが原因になっているということを証明したわけではありません。
実験で使われた会話は、実際の自然なやり取りというよりは、似た内容の質問を順番に並べた、やや人工的なものです。
生成AIに回答を拒否されたら…
今回の示唆を踏まえると、いちど拒否が出たあとに同じような話題を繰り返していると、その傾向(拒否)が続いてしまう可能性があると考えられます。
セーフガードが適切に働くこと自体は悪いことではありませんが、この傾向をどこかで断ち切らないと、一般的に安全な範囲の回答を得ることも難しくなる可能性があります。
対策として一番手っ取り早いのは、新しいチャットに移行することです。物理的に、今までの傾向が一旦リセットされます。ChatGPTで言うところの「新しいチャットに分岐します」でも似たような効果が得られるかもしれませんが、分岐時点までの履歴は引き継ぐため、拒否傾向を完全にリセットできるとは限りません。
もしくは、チャットの方向性を大きく変えてみても良いでしょう。
Figure 3 とTable 6 で示された通り、話題を変えることで履歴を引きずるリスクを減らせると考えられるので、例えば今まで「とあることを実行する方法」を聞いていたのであれば、「安全対策」「一般的な注意事項」といった安全性を重視する方向の質問に切り替えることで、問題を解決できる可能性があります。
過去の回答は、必ずしも必要とは限らない
こちらの記事で、以下のようなことを書きました。
一般的に、単独のチャットにおいて生成AIとのやりとりが増えてくると、先述のコンテキストの汚染(劣化)のリスクが増えます。具体的に言うと、LLMは過去に自分が言ったことを正しい前提として扱ってしまうことがあり、仮にその内容に間違いが混ざっていた場合、その間違いをずっと引きずってしまう可能性があるということです。
そしてこのようなズレは、会話が続くほど修正が困難になる可能性があることも論文中で言及されています。
ゆえに、これまでの会話の内容とはあまり関連がない(もしくは関連性が曖昧な)新しい質問をする時は、適度に会話を分岐させたり、誤りを見つけたらチャットを区切ったりして、コンテキストの汚染に至らないように配慮する必要があります。
一方で、LLMの過去の回答を全て省略すれば必ず良い結果が得られるとは限らないことも示唆されています。これからしようとしている質問の内容が過去の生成AIが出力した回答と関連が深い場合は、該当する回答部分の履歴を選択して提示したり、完全な指示に書き換えて提示したりして、過去の生成AI側の回答を活用すると良いでしょう。
https://note.com/pharma_i_cist/n/n981d2d04b145#25655247-3ac7-473a-a386-016a6ee53865 より一部引用
今回の内容と共通するのは、ひとつのチャットを長く使い続けて良い結果が得られるとは限らない、ということです。
とくに薬剤師が仕事で生成AIを活用する場合は、医薬品の用法・用量、相互作用、検査結果といった情報を生成AIに与えることもあると思いますが、これらの前提のわずかなズレが蓄積していくと、ハルシネーション・誤った迎合・回答拒否につながる可能性があります。
そのため、ひとつのチャットで何でも処理しようとするのではなく、必要に応じて目的ごとに会話を切り替えるほうが無難でしょう。
例えば、直前まで論文の内容を分析していて、その内容を患者さん向けに易しく言い換えようと思ったなら、患者さん向けに言い換えるタスクは別のチャットに移行するほうが、良い結果が得られると考えられます。
【参考:過去の回答が必要かどうかの判断基準および引き継ぎ方】
1. まず、過去の生成AIの回答が必要かを判定する
今までのトピックとは関係のない新しい質問、直近の自分の指示が具体的(XをYに変更してください、など)、参照語が少ない(「それ」や「2つ目」などが少ない)といった場合は、過去の生成AI側からの回答は参照させない方が良いでしょう。
一方で、「2つ目が動かない」「さっきの式」「前のコードの〜」など、過去の生成AIが出力した回答との関連が深い場合は、あえて生成AIの回答履歴を残す、特に該当する回答部分の履歴を選択して提示する方が良いと考えられます。
2. (生成AIの回答の履歴が必要ないなら)会話を区切るか分岐させる
すでに実践されている方も多いかもしれませんが、過去の生成AI側の回答の履歴が必要ないのであれば、潔く会話を区切るか、分岐させてしまいましょう。
ChatGPTなら出力最下部の3点リーダから「新しいチャットに分岐します」を選択すれば、必要最小限の前提を維持しつつ会話を続けられるので、おすすめです。
3. (生成AIの回答の履歴が必要なら)追加の質問をする際は、再度条件を具体的に書く
「前の回答を踏まえて…」と指示すると、無条件で過去の回答全てを根拠にしてしまうかもしれません。ゆえに、追加で質問をする場合は、条件を短く要約して再度記載する方が良いでしょう。
具体例を挙げると、「その文章を、もう少し短めにしてください」と指示するのではなく、「(文章をペーストしたうえで)この文章を200文字以内に収めてください」といった具体的な指示をするようなイメージです。
生成AIから意図した回答を引き出すのに必要なのは、プロンプトエンジニアリングだけではありません。どの情報を残し、どの情報を切断するかを判断することも、これからの生成AIユーザーに求められる重要なスキルになるでしょう。
チャットでやりとりを繰り返しているうち、自分の意図を理解してもらえていないような気がしたら、気持ちを新たに新しいチャットに移行してみましょう。
最後までお読みいただき、ありがとうございました。
Webサイト「薬剤師のためのAIノート」も、是非ご覧ください。
記事に関する内容以外のお問い合わせは、以下のフォームよりお願いいたします。
また、書籍「超知能時代の調剤薬局」発売中です。
Kindle Unlimited会員の方は無料で読むことができます。




