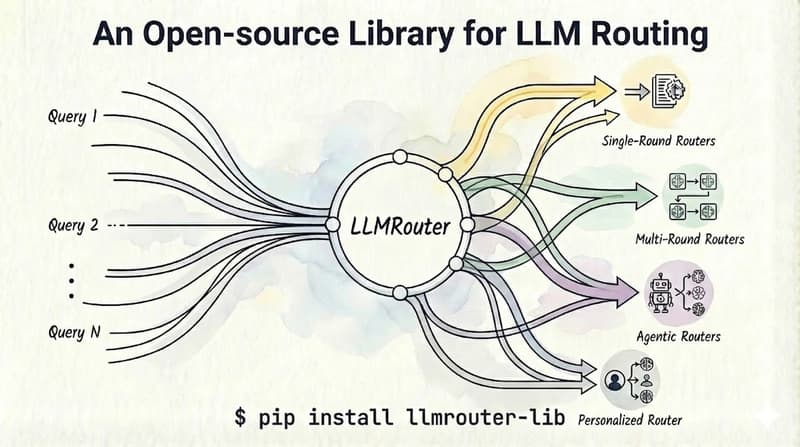
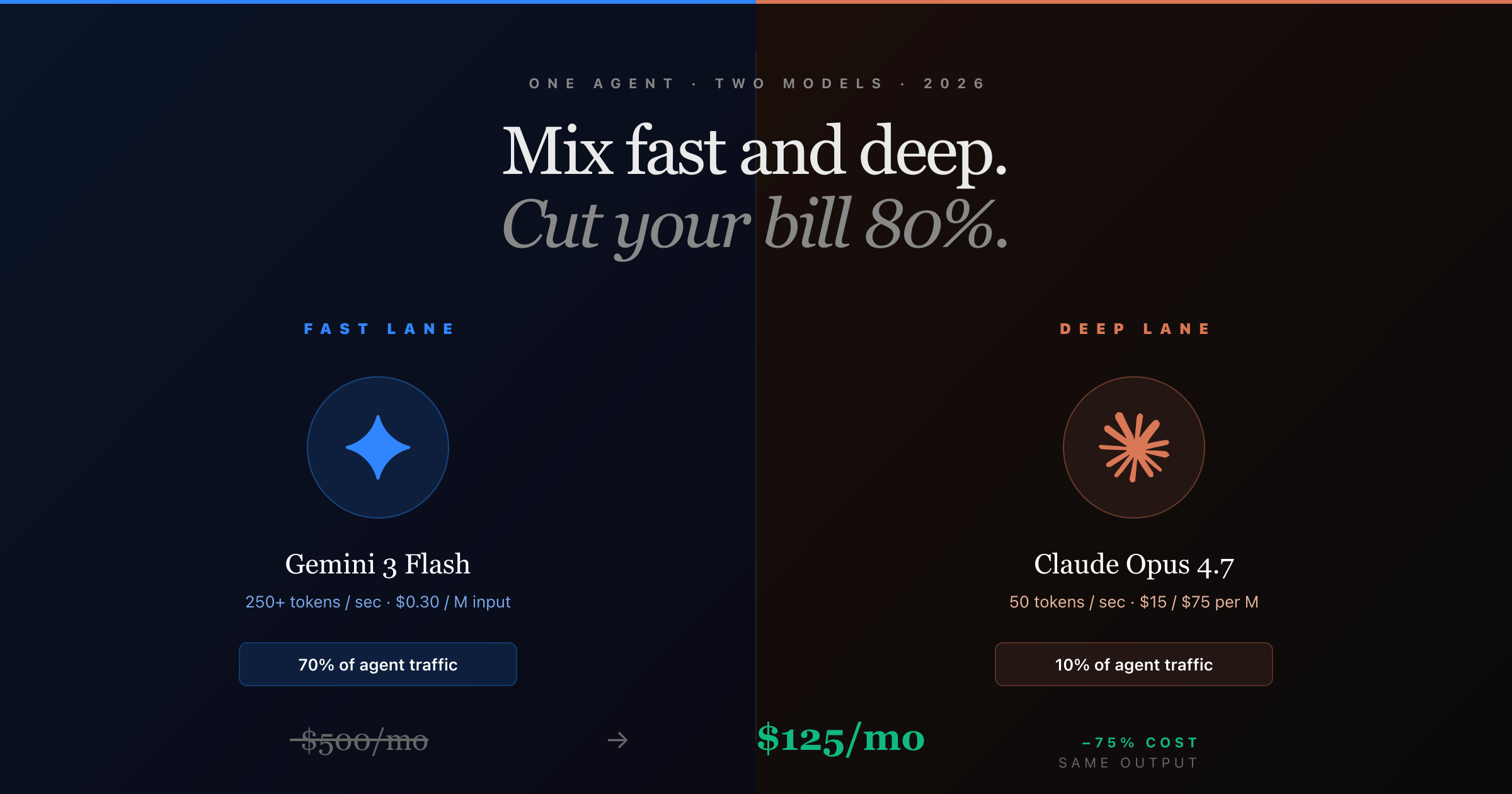
A new paper from NVIDIA Research integrates speculative decoding directly into NeMo RL with a vLLM backend, delivering lossless rollout acceleration at both 8B and projected 235B model scales.
The post A New NVIDIA Research Shows Speculative Decoding in NeMo RL Achieves 1.8× Rollout Generation Speedup at 8B and Projects 2.5× End-to-End Speedup at 235B appeared first on MarkTechPost.